インテル® VTune™ プロファイラーは、グラフィックス・アプリケーションをプロファイルして、CPU と GPU の両方のアクティビティーを関連付けることができます。
インテル® VTune™ プロファイラーによる GPU 解析は、次の手順に従ってください。
GPU 解析向けにシステムを設定します。
GPU オフロード解析を実行し、アプリケーションが GPU 依存であるか、そしてコードが GPU にどの程度効率良くオフロードされているか確認します。
SYCL*、インテル® メディア SDK および OpenCL* ソフトウェア・テクノロジーを使用する GPU 依存のアプリケーションを詳しく調査するため、GPU 計算/ホットスポット解析を実行します。
- SYCL* 計算タスクの実行を調査 (インテル® VTune™ プロファイラー 2021 でサポート)
注
カスタム解析を設定して、GPU 利用率データを収集することもできます。これには、[解析の設定] で [GPU 利用率] オプションを選択します。このオプションは、収集中のオーバーヘッドを軽減します。[プロセッサー・グラフィックス・ハードウェア・イベントを解析] を追加するとオーバーヘッドは中程度、[GPU プログラミング API をトレース] オプションを追加するとオーバーヘッドは最大となります。
GPU 依存のアプリケーションの GPU 利用率を解析
アプリケーションまたはその処理ステージが GPU 依存であることが判明している場合、[GPU 計算/メディア・ホットスポット] 解析を特性化モードで実行して、GPU エンジンが効率的に実行されているか、また改善の余地があるかを調査します。これは、インテル® VTune™ プロファイラーのインテル® グラフィックスのレンダーと GPGPU エンジン向けのハードウェア・メトリックの収集により解析できます。
GPU ハードウェア・メトリックを調査
GPU ハードウェア・メトリックは、GPU アクティビティーを解析して次のレベルに移行するための詳細情報を提供し、パフォーマンス改善の可能性を特定します。GPU 計算/メディア・ホットスポット解析を設定して、インテル® グラフィックス上のレンダーと GPGPU エンジンで、次のタイプの GPU イベントメトリックを収集することができます。
[概要] (デフォルト) グループでは、GPU 実行ユニット、サンプラー、汎用メモリー、およびキャッシュアクセスのアクティビティー全般を解析します。
[基本計算 (グローバル/ローカル・メモリー・アクセス)] グループは、異なるタイプの GPU メモリーのアクセスを解析します。
[計算拡張] (インテル® Core™ M プロセッサー以降)
[完全な計算] グループを選択して、[概要] と [基本計算] で事前定義されているメトリックの組み合わせを同じビューに表示することで、GPU 実行ユニットが待機している理由を調査するのに役立ちます。このイベント設定を使用するには、ターゲットのプロパティーで [複数実行を許可] が有効になっていることを確認してください。
[概要] イベントグループから始めて、[基本計算 (グローバル/ローカル・メモリー・アクセス)] グループに切り替えます。[基本計算] メトリックは、GPU ハードウェア・メトリックと実際の GPU 負荷の関連付けを可能にする、[GPU 利用率] イベントオプション (GPU 計算/メディア・ホットスポット解析のデフォルト) を有効にして GPU での計算ワークを解析する場合に最も効果的です。
データが収集されたら、[サマリー] ウィンドウの [EU アレイストール/アイドル] セクションを調査して、実行ユニットが待機している最も典型的な原因を特定します。
設定した事前定義イベントに応じて、インテル® VTune™ プロファイラーはストール/アイドル状態の実行ユニットのメトリックを解析します。デフォルトでは、GPU 計算/メディア・ホットスポット解析は、サンプラービジー、サンプラーがボトルネック、GPU L3 帯域幅などの一般的な GPU メモリーアクセスを追跡するメトリックを含む、[概要] で事前定義されているメトリックを収集します。これにより、[EU アレイストール/アイドル] セクションには、頻繁にサンプラーをアクセスする GPU 計算タスクのリストと、GPU L3 帯域幅に依存する最もホットな GPU 計算タスクが表示されます。

解析設定で [基本計算] を選択した場合、インテル® VTune™ プロファイラーは GPU 上の異なるデータタイプへのアクセスを特定するメトリックを解析し、[占有率] セクションを表示します。占有率が低い GPU タスクに関する情報を参照し、占有率のピークを達成する方法を理解してください。

ピーク占有率がアプリケーションの問題としてフラグが表示されている場合、GPU 上のすべてのスレッド を制限する要因を調査してください。該当するソリューションを適用してコードを変更することを検討してください。
| 低いピーク占有率の原因となる要因 | 解決方法 |
|---|---|
計算タスクでワークグループごとに要求される SLM サイズが大きすぎます |
SLM サイズを小さくするか、ローカルサイズを増やします |
グローバルサイズ (計算タスクによって処理されるワーク項目数) が小さすぎます |
グローバルサイズを増やします |
バリア同期 (GPU サブスライス上のハードウェア・バリア数が制限されているため、同期プリミティブによって占有率が低くなる可能性があります) |
バリア同期を削除するか、ローカルサイズを増やします |

占有率がアプリケーションの問題としてフラグが表示されている場合、コードを修正してハードウェア・スレッドのスケジュールを改善します。これは、スレッドのスケジュールが効率良く機能しない原因として考えられます。
- 小さな計算タスクは、タスクの実行時間と比較してオーバーヘッドが大きくなる可能性があります。
- 計算タスクを実行するスレッド間では、インバランスが発生する可能性があります。

[基本計算] 事前定義では、DRAM 帯域幅の解析も有効になります。GPU ワークロードが DRAM 帯域幅依存である場合、対応するメトリック値にフラグが示されます。実行中に DRAM 帯域幅を過度に使用する GPU 計算タスクをテーブルで調査します。
解析設定で、[完全な計算] と [複数実行を許可] が選択されている場合、インテル® VTune™ プロファイラーは、データ収集に [概要] と [基本計算] イベントグループの両方を使用し、同じビューに EU アレイストール/アイドルのすべての原因を表示します。
注
インテル® HD グラフィックスおよびインテル® Iris®グラフィックスのハードウェア・イベントを解析するには、GPU 解析のシステム設定が適切であることを確認してください。
経時的な HW メトリックごとの GPU パフォーマンス・データを解析するには、[グラフィックス] ウィンドウを開き、[タイムライン] ペインに注目します。[グラフィックス] ウィンドウに表示される GPU メトリックのリストは、解析設定で選択されたハードウェア・イベントの事前定義に依存します。
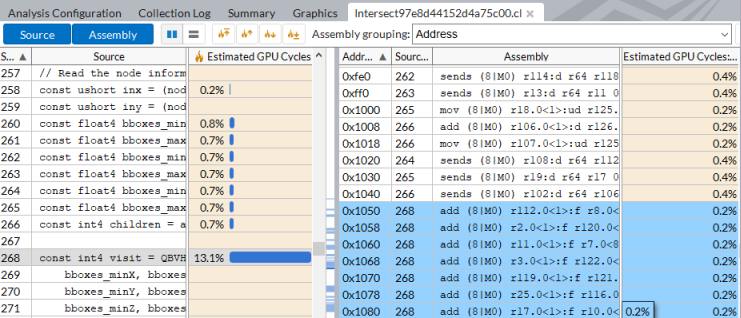
次の例は、GPU 依存のアプリケーションで収集された [概要] メトリックのグループです。
最初に [GPU 実行ユニット] > [EU アレイアイドル] メトリックを見てみましょう。アイドルサイクルは無駄なサイクルです。スケジュールされているスレッドがなく、EU の貴重な計算リソースが活用されていません。[EU アレイアイドル] がゼロの場合、GPU は効率良く活用されており、すべての EU にスレッドがスケジュールされています。
ほとんどの場合、最適化では [EU アレイストール] を最小にし、[EU アレイアクティブ] を最大にします。ただし、メモリー帯域幅に制約されるアルゴリズムは例外です。この場合、([EU アレイアクティブ] を最大にするのではなく) メモリー帯域幅を特定のプラットフォームのピークに近づけるように最適化します。
メモリーアクセスは、しばしばストールの原因になります。メモリーレイアウトと注意深く設計されたメモリーアクセスの重要性を軽視することはできません。[EU アレイストール] がゼロでなく [GPU L3 ミス] に関連しており、アルゴリズムがメモリー帯域幅に制約されていない場合は、メモリーアクセスとレイアウトの最適化を試してみるべきです。
サンプラーアクセスはコストが高く、容易にストールを引き起こします。サンプラーアクセスは、[サンプラーがボトルネック] と [サンプラービジー] メトリックによって測定できます。
OpenCL* カーネル実行の調査
アプリケーションが、OpenCL* ソフトウェア・テクノロジーを使用している場合、[グラフィックス] ウィンドウの [タイムライン] ペインで [GPU 計算スレッドのディスパッチ] メトリックを使用して、アプリケーションが GPU 上で多くのワークを計算していることを確認してから、解析を続行しインテル® グラフィックス上で実行されている OpenCL* カーネルの情報を取得します。この解析を行うには、[解析の設定] で [GPU プログラミング API をトレース] オプションを有効にします。GPU 計算/メディア・ホットスポット解析では、デフォルトでこのオプションが有効になっています。
[サマリー] ビューでは、[最もホットな GPU 計算タスク] セクションに GPU 上で実行される OpenCL* カーネルを表示してパフォーマンス上クリティカルなカーネルを通知します。カーネル名をクリックして、[計算タスク (GPU)/インスタンス] でグループ化された [グラフィックス] ウィンドウを開きます。また、グリッド内のデータは計算タスクでグループ化することもできます。インテル® VTune™ プロファイラーは、次の計算タスクの目的を識別します: 計算 (カーネル)、転送 (OpenCL* ルーチンがホストから GPU へのデータ転送を行います)、および 同期 (例えば、clEnqueueBarrierWithWaitList)。
対応するカラムに GPU でのカーネルの実行時間と 1 回の呼び出しの平均時間 (clEnqueueNDRangeKernel の 1 回の呼び出しに対応)、ワークグループのサイズ、カーネルの平均 GPU ハードウェア・メトリックが表示されます。カラムのヘッダー (メトリック) にカーソルを移動すると、メトリックの説明が表示されます。計算タスクのメトリック値が、インテルが設定しているしきい値を超えると、値はピンク色でハイライトされ、パフォーマンス上の問題があることを示します。ハイライトされた値にカーソルを移動すると、問題の説明が表示されます。

最初に、実行時間が最も長いホットなカーネルを解析し最適化します。ホットなカーネルには、平均実行時間が長い、あるいは平均実行時間は短くても頻繁に呼び出されるといった特徴があります。どちらの場合も注目すべきです。
OpenCL* カーネルへの転送の詳細を表示し、キュー内で費やされた時間を解析するには、[グラフィックス] または [プラットフォーム] ウィンドウの [タイムライン] ペインにある、[計算キュー] データを調査します。
インテル® メディア SDK タスクの実行を調査
[GPU 利用率] と [GPU プログラミング API をトレース] オプションの両方を有効にして、インテル® メディア SDK プログラム解析を行う場合、[グラフィックス] ウィンドウを使用してインテル® メディア SDK タスクの実行データと GPU ソフトウェア・キューのデータを関連付けます。
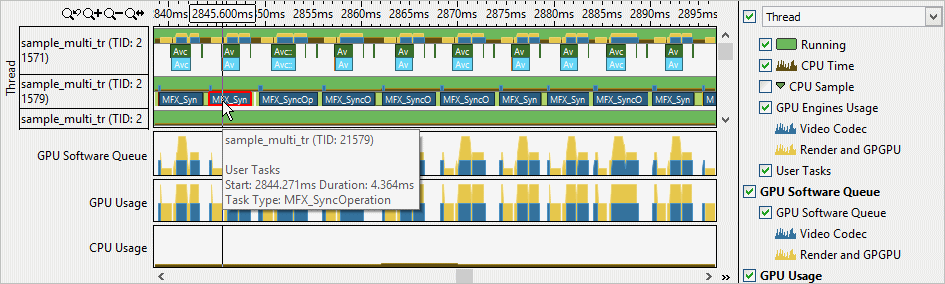
コード行ごとの GPU カーネルを解析
GPU オフロード解析で特定されたホットな GPU カーネルで GPU 解析を絞り込むため、コードレベル解析モードで GPU 計算/メディア・ホットスポット解析を実行します。この解析は、GPU カーネル内のメモリーアクセスによって引き起こされるパフォーマンスが重要な基本ブロックや問題の特定に役立ち、コード行/アセンブリー命令ごとのパフォーマンス統計を提供します。