リリースモードでビルドされたアプリケーションでインライン展開された関数ごとのパフォーマンス・データを表示するように、インテル® VTune™ プロファイラーを設定します。
必要条件
このオプションは、以下を使用してコードをコンパイルする際にサポートされます。
- Linux*:
- GCC* コンパイラー 4.1 以降
- インテル® oneAPI DPC++/C++ コンパイラー。Linux* では、最適化 (オプション -O2 以上) とデバッグ (オプション -g) を指定してコンパイルすると、デフォルトで -debug inline-debug-info オプションが有効になります。
- Windows*:
- インテル® C++ コンパイラー・クラシック・コンパイラーと /debug:inline-debug-info オプション。
- インテル® oneAPI DPC++/C++ コンパイラー、または Microsoft* Visual C++ と /Zo オプション。/Zi または /Z7 オプションでデバッグ情報を生成する場合、/Zo オプションはデフォルトで有効になります。
- Linux* では DWARF 形式、Windows* では Microsoft PDB* 形式でインライン関数のデバッグ情報を生成できるその他のコンパイラー。
- JIT プロファイル API は、JIT コンパイルされたコードのインライン関数に使用されます。
インライン関数を表示
インライン関数のデータを表示するには、解析結果ウィンドウで、フィルターバーの [インラインモード] オプションを [インライン関数を表示] に設定します。インテル® VTune™ プロファイラーは、インライン展開された関数 (仮想フレーム) を通常の関数として表示します。
インライン展開された関数を非表示にするには、[インライン関数を非表示] を選択します。
例 1: ホットスポット解析のインラインモード
この例では、ホットスポット解析の [インライン関数を表示] オプションを有効にします。このモードでは、GetModelParams インライン関数の完全なスタックが表示されます。
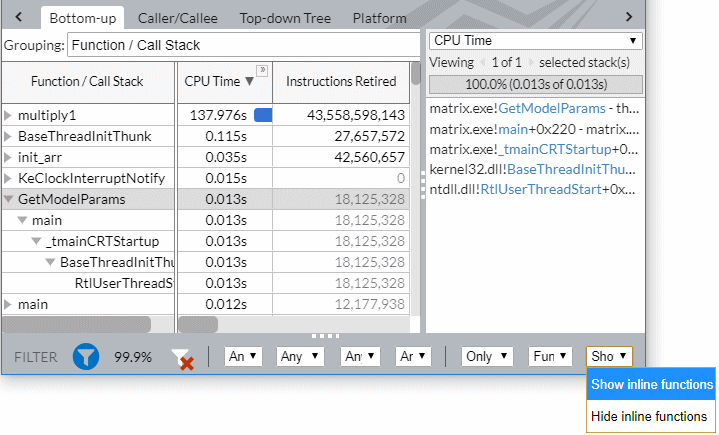
[グループ化] メニューで、[ソース関数/関数/コールスタック] レベルを選択して、インライン展開された関数のすべてのインスタンスを 1 行に表示できます。
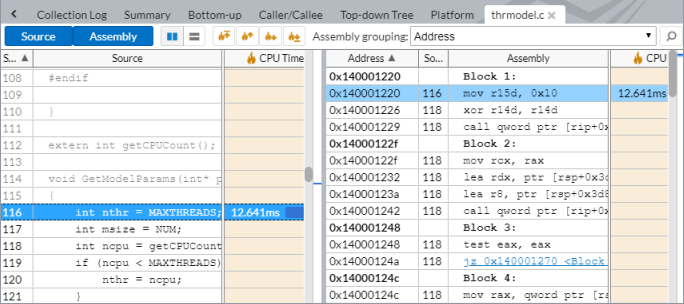
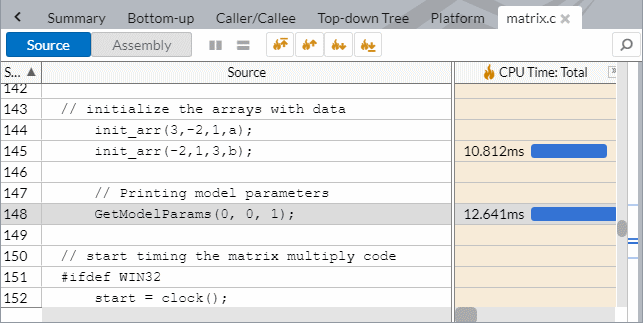
GetModelParams インライン関数をダブルクリックすると、最も CPU 時間を消費したコード行を特定して対応するアセンブリー・コードを解析できます。
例 2: ホットスポット解析のインラインモードを無効にする
同じサンプルでフィルターバーの [インライン関数を非表示] オプションを選択した場合、インテル® VTune™ プロファイラーは [ボトムアップ] ビューに GetModelParams 関数を表示しません。
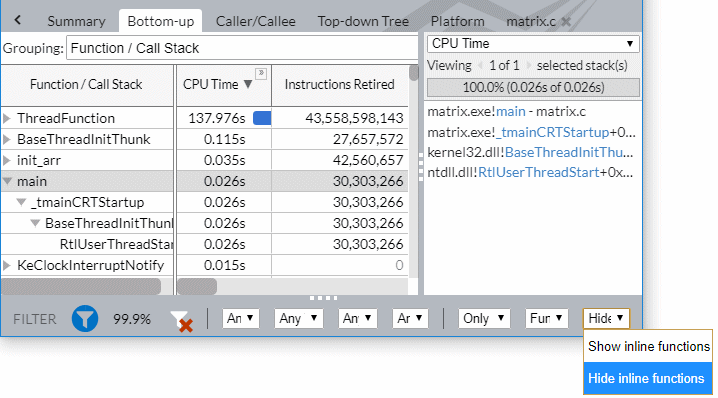
しかし、main 関数をダブルクリックしてソースコードを表示すると、すべての CPU 時間が GetModelParams インライン関数が呼び出されたコード行に属していることが分かります。
例 3: GPU 計算/メディア・ホットスポット向けのインラインモード
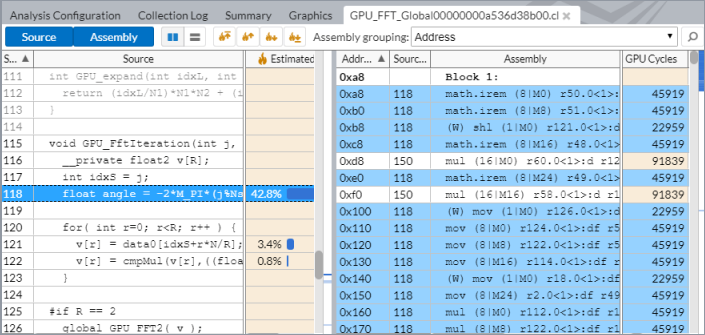
デフォルトでは、GPU 計算/メディア・ホットスポット解析のインラインモードは無効になっています。この例では、GPU サイクルの 100% が GPU_FFT_Global 関数によるものです。
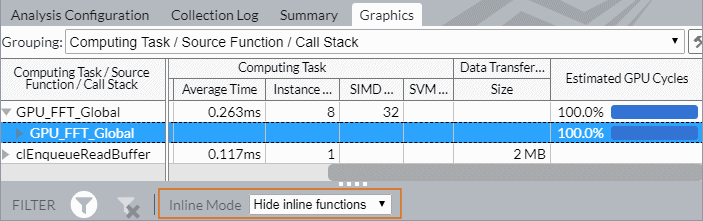
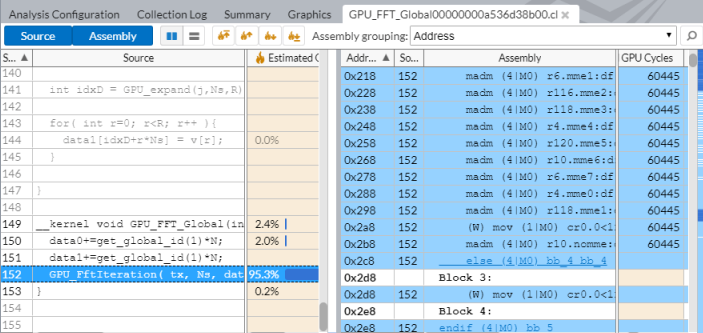
GPU_FFT_Global ソース関数をダブルクリックしてソースビューを表示します。予測 GPU サイクルの 95.3% を占めるこの関数を呼び出しているコード行が表示されます。
しかし、[計算タスク/関数/コールスタック] または [計算タスク/ソース関数/コールスタック] グループ化レベルを選択して、このビューでインラインモードを有効にすると、GPU_FFT_Global 関数は予測 GPU サイクルの 4.7% のみで、4 つのインライン関数が残りのサイクルを占めていることが分かります。
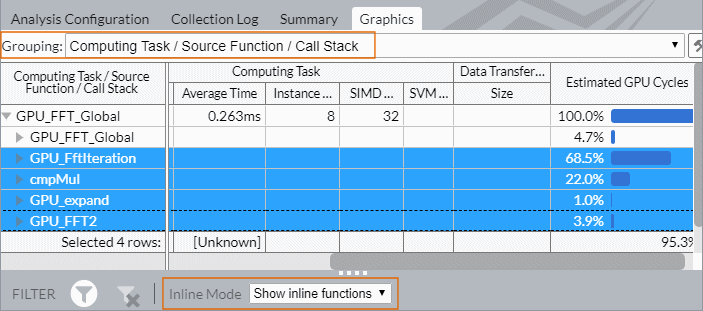
最もホットな GPU_FftIteration 関数をダブルクリックして、ソースとアセンブリー・コードを解析します。