インテル® VTune™ プロファイラーを使用して、Oracle* や OpenJDK* (Linux* のみ) で実行される Java* アプリケーションを解析します。
Java* コードの実行がマネージドランタイム環境で制御されたとしても、データ管理の点からはネイティブ言語を使用して記述されたプログラムほど効果はありません。例えば、データマイニング Java* アプリケーションのパフォーマンスを意識するのであれば、ターゲット・プラットフォームのメモリー・アーキテクチャー、キャッシュ階層、メモリーレベルへのアクセスのレイテンシーを考慮する必要があります。プラットフォームのマイクロアーキテクチャーという点で見ると、Java* アプリケーションのプロファイルはネイティブ・アプリケーションのプロファイルに似ていますが、大きな違いが 1 つあります。それは、プログラムのソースコードに対するパフォーマンス・メトリックを確認するには、プロファイル・ツールは JVM* でコンパイルまたは解釈されたバイナリーコードのメトリックを、オリジナルの Java* または C/C++ ソースコードにマップできなければならない点です。
インテル® VTune™ プロファイラーは、JIT コンパイル済みコードの低オーバーヘッド解析を実行できます。これは、ユーザーモード・サンプリングとトレース、およびハードウェア・イベントベース・サンプリング解析の両方のタイプでサポートされます。解釈された Java* メソッドの解析は制限されます。
インテル® VTune™ プロファイラーで Java* コード解析を有効にしてデータを解釈するには、次の操作を行います。
-
- アプリケーションを起動
- プロセスにアタッチ
- Linux* のみ: 低い権限アカウントで実行中のプロセスにアタッチ
Java* データ収集を設定する
Java* コード向けにパフォーマンス解析を設定するには、GUI またはコマンドライン (vtune) 設定のいずれかを使用します。次のモードを使用して Java* コード解析を行います。
[アプリケーションを起動] モードで Java* 解析を設定するには:
バッチファイルや実行可能なスクリプトで java* コマンドを指定します。
例えば、Windows* 上で run.bat ファイルまたは Linux* で run.sh ファイルを作成し、次のコマンドを埋め込みます。
Windows* :
> java.exe -Xcomp -Djava.library.path=native_lib\ia32 -cp C:\Design\Java\mixed_stacks MixedStacksTest 3 2Linux* :
$ java -Xcomp -Djava.library.path=native_lib/ia32 -cp /home/Design/Java/mixed_stacks MixedStacksTest 3 2プロジェクトを作成します。
[解析の設定] ウィンドウから、[どこを] ペインを選択し、解析システム (例えば、[ローカルホスト]) を指定します。
[何を] ペインで、[アプリケーションを起動] ターゲットタイプを選択します。
[アプリケーション] フィールドで run ファイルへのパスを指定します。
Linux* の例: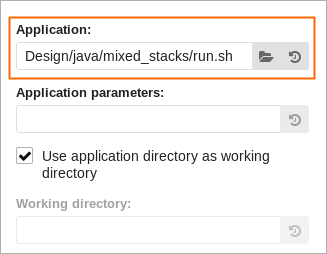
[高度] セクションの [マネージドコードのプロファイル・モード] で [自動] モードを選択し、 [子プロセスを解析] オプションを有効にします。
同様に、インテル® VTune™ プロファイラーのコマンドライン・インターフェイス vtune で解析を設定することもできます。例えば、Linux* のホットスポット解析では、次のコマンドを実行します。
$ vtune -collect hotspots -- run.shまたは
$ vtune -collect hotspots -- java -Xcomp -Djava.library.path=native_lib/ia32 -cp home/Design/Java/mixed_stacks MixedStacksTest 3 2[プロセスにアタッチ] モードで Java* 解析を設定するには:
Java* アプリケーションをしばらく実行する必要がある場合や、解析を開始するときに起動できない場合、インテル® VTune™ プロファイラーをスタンドアロンの Java* プロセスにアタッチすることができます。Linux* では、ハードウェア・イベントベース・サンプリング解析タイプの組込み JVM* インスタンスを使用して、インテル® VTune™ プロファイラーを C/C++ アプリケーションにアタッチできます。 これを有効にするには、[何を] ペインで [プロセスにアタッチ] ターゲットタイプを選択して、 java* プロセス名または PID を指定します。
コマンドライン・インターフェイスを使用して、解析を Java* プロセスにアタッチすることもできます。例えば、次のコマンドはホットスポット解析を Java* プロセスにアタッチします。
$ vtune -collect hotspots -target-process java次のコマンドラインの例は、ホットスポット解析を PID を使用して Java* プロセスにアタッチします。
$ vtune -collect hotspots -target-pid 1234注
動的なアタッチは、Java* 開発キット (JDK*) でのみサポートされます。低い権限のアカウントで [プロセスにアタッチ] モードの Java* 解析を設定するには (Linux* のみ):
ハードウェア・イベントベース・サンプリング解析タイプでは、スーパーユーザー権限で実行するインテル® VTune™ プロファイラーを、低い権限レベルのユーザーアカウントで実行される Java* プロセスや JVM* インスタンスが組込まれた C/C++ アプリケーションへアタッチすることができます。例えば、インテル® VTune™ プロファイラーを Java* ベースのデーモンやサービスにアタッチすることができます。
これを行うには、root アカウントでインテル® VTune™ プロファイラーを起動し、 [プロセスにアタッチ] ターゲットタイプを選択して、 java* プロセス名または PID を指定します。
最もホットなメソッドを特定する
ホットスポット解析を使用すると、最もホットなメソッドのリストとタイミングメトリックおよびコールスタックが表示されます。スレッドのワークロード分布も [タイムライン] ペインに表示されます。スレッドに名前を付けると、最もリソースを消費しているコードがどこで実行されたかを特定するのに便利です。以下に Linux* の例を示します。
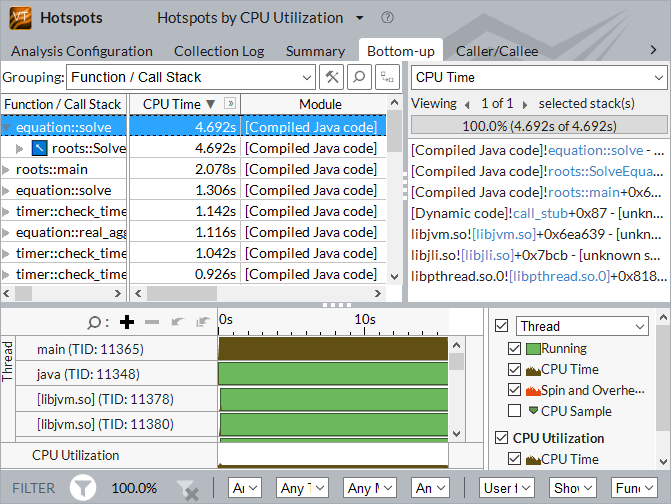
混在コードのスタックを解析する
プラットフォームにおける最高のパフォーマンスを目指すため、Java* プロジェクトのパフォーマンス・クリティカルなモジュールを、C やアセンブリーのようなネイティブ言語で記述してコンパイルする手法を用いることがあります。このプログラミング手法を用いることで、ベクトル・コンピューティング (SIMD ユニットと命令セットにより実装) のような強力な CPU リソースを使用することができます。この場合、大部分の処理を行うことが期待される、計算を多用する関数がホットスポットとしてプロファイル結果に表示されます。しかし、ホットスポット関数だけでなく、それらの関数が JNI インターフェイスで呼び出さ経由 Java* コードの位置を特定したいこともあります。言語が混在するアルゴリズム実装においてそのようなクロスランタイム呼び出しをトレースすることは課題の 1 つです。
混在コードのプロファイル結果を解析するため、インテル® VTune™ プロファイラーは、Java* のコールスタックと後続の C/C++ 関数のネイティブなコールスタックを「スティッチ」します (1 つにまとめます)。逆のコールスタックのスティッチも行われます。以下に Windows* の例を示します。
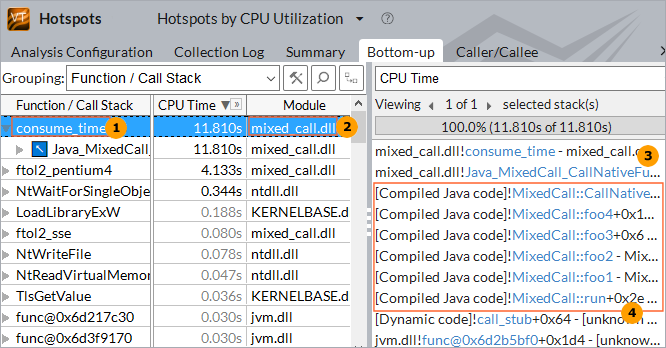
|
ネイティブ関数 |
|
ネイティブ/Java* 混在コールスタック |
|
ネイティブモジュール |
|
Java* コールスタックのコンパイル済みメソッド |




注
コンパイル時のインライン展開により、デフォルトでは一部の関数がスタックに表示されないことに注意してください。 フィルターバーの [インラインモード] で、[インライン関数を表示] オプションが選択されていることを確認してください。
ハードウェア・メトリックを解析する
インテル® VTune™ プロファイラーは、プラットフォームの CPU マイクロアーキテクチャー向けに Java* アプリケーションを最適化する高度なプロファイル・オプションを提供します。Java* や JVM* テクノロジーは、ハードウェア・アーキテクチャー固有のコーディングから開発者を解放するように意図されていますが、Java* コードを現在のインテル® アーキテクチャー向けに最適化すれば、将来の世代の CPU でも、おそらくこの利点は維持されます。 ハードウェア・イベントベース・サンプリングによるデータ収集を使用して、CPU のパイプラインのハードウェア・イベントをモニターし、CPU の効率良い命令実行を制限するコードの過ちを特定します。 CPU メトリック は、アプリケーションのモジュール、関数、Java* コードのソース行に対して表示することができます。また、ドライバーやシステムのミドルウェア層で呼び出された関数の呼び出しパスを調べる必要がある場合、 スタックを含むハードウェア・イベントベースのサンプリング収集を利用できます。
制限事項
インテル® VTune™ プロファイラーは、制限付きで Java* アプリケーションの解析をサポートします。
システム全体のプロファイルはマネージドコードではサポートされません。
JVM は、パフォーマンス上の理由により、ほとんど呼ばれなかったメソッドをコンパイルする代わりにインタープリターで翻訳されることがあります。インテル® VTune™ プロファイラーは翻訳された Java* メソッドを認識しないため、復元されたコールスタックではそのような呼び出しを [!インタープリター] としてマークします。
そのような関数を名前付きでスタックに表示する場合、-Xcomp オプションを使用して JVM* でコンパイルします (結果は、[コンパイル済み Java* コード] メソッドとして表示されます)。しかし、実行中に多くの小さな関数やほとんど使用されない関数が呼び出された場合、タイミング特性は顕著に変わります。
ホットスポットのソースコードを開く際に、インテル® VTune™ プロファイラーはイベントや時間統計を誤ったコードに割り当てることがあります。これは JDK* Java* VM 固有の現象です。ループの場合、パフォーマンス・メトリックが上にずれます。多くの場合、情報はホットなメソッドのソースコードの最初の行に表示されます。次の例では、最も CPU 時間を消費する実際のホットスポット行は 35 行目です。
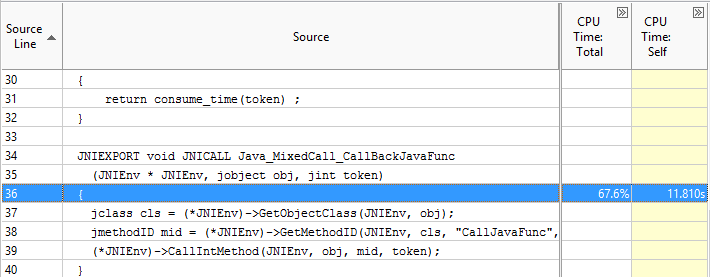
イベントと時間のソースコードへのマッピングはおおよそのものです。
ユーザーモード・サンプリング・モードのホットスポット解析タイプでは、インテル® VTune™ プロファイラーはコールスタックの一部のみを表示することがあります。Windows* 上で完全なスタックを表示するには、追加の -Xcomp JDK* Java* VM コマンドライン・オプションを使用し、JIT コンパイルを有効にしてスタック・ウォーキングの精度を高めます。
Linux* で完全なスタックを表示するには、Java* VM の動作を変更する追加の JDK* Java* VM コマンドライン・オプションを使用します。
-
より精度の高いスタック・ウォーキングの JIT コンパイルを有効にする、追加の -Xcomp JDK* Java* VM コマンドライン・オプションを使用します。
-
Linux* x86 では、サーバー Java* VM の代わりにクライアント JDK* Java* VM を使用します。つまり、JDK* Java* VM コマンドライン・オプションの -client を明示的に指定するか、-server を指定しません。
-
Linux* x64 では、インタープリターで解釈したメソッドとコンパイルバージョンのオンザフライ置換をオフにする -XX:-UseLoopCounter コマンドライン・オプションを指定します。
-
ホットスポットとマイクロアーキテクチャー解析タイプでは、Java* アプリケーションのプロファイルがサポートされます。一部の組込み Java* 同期プリミティブ (OS の同期オブジェクトを呼び出さない) は、インテル® VTune™ プロファイラーで認識できないため、スレッド化解析が制限されます。その結果、一部のタイミングメトリックがずれる可能性があります。
Java* ソースコードのコレクション制御用のユーザー API を提供する専用ライブラリーはありません。ただし、JNI 呼び出しで __itt 呼び出しをラップしてネイティブ API を適用することはできます。