関数のコールスタックを解析し、パフォーマンス、並列処理および消費電力を特定するように、イベントベース・サンプリング・コレクターを設定します。
注
Linux* ターゲットでは、カーネルがイベントベースのスタック・サンプリング収集をサポートするように設定されていることを確認します。
マルチタスク・オペレーティング・システムは、すべてのソフトウェア・スレッドをタイムスライスで実行します (スレッド実行クォンタム)。インテル® VTune™ プロファイラーは、スレッドクォンタム切り替えを処理し、スレッドクォンタムの配置と関連するすべての監視操作を実行します。
次の図は、スレッドごとのクォンタム監視の概念を示しています。
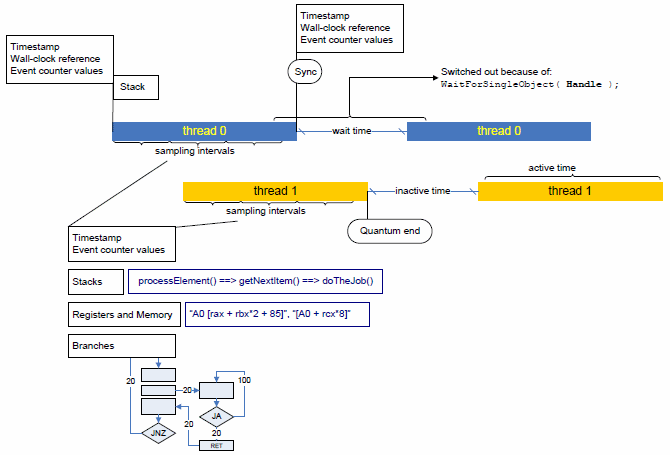
スレッドがプロセッサー上にスケジュールされ、プロセッサーからスケジュール・アウトされるたびに (スレッドクォンタム境界で) プロファイラーが制御を取得します。これにより、プロファイラーは、ハードウェア・パフォーマンス・イベントやタイムスタンプを正確に測定し、スレッドがアクティブまたはインアクティブになるまでコールスタックを収集できます。
プロファイラーはスレッドがインアクティブとなった原因を判断します。これは、明示的な同期要求、またはオペレーティング・システムのスケジューラーが現在のスレッドをプリエンプトして別の優先度の高いスレッドを実行する、いわゆるスレッドクォンタムの終了が原因です。
スレッドがインアクティブである期間も直接測定され、インアクティブの原因に基づいて区分されます。同期要求によるインアクティブ化は待機時間と呼ばれ、プリエンプションによるインアクティブはインアクティブ時間と呼ばれます。
プロセッサー上 (クォンタム内) でスレッドがアクティブである期間、プロファイラーはイベントベース・サンプリングによってプログラムロジックを再構築し、ハードウェア・イベントとプログラムコードを関連付けます。従来のイベントベース・サンプリングとは異なり、プロファイラーは各サンプリング割り込みで以下を収集します。
コールスタック情報
分岐情報 (設定されていれば)
プロセッサーのタイムスタンプ
プログラムの実行ロジック (呼び出しと制御フローグラフ) を統計的に再構築し、時間経過におけるスレッドがアクティブな時間を追跡して、ハードウェア利用率とパフォーマンスに関連する情報を収集します。
スタック収集を設定
インテル® VTune™ プロファイラー・ツールバーの
 [解析の設定] ボタンをクリックします。
[解析の設定] ボタンをクリックします。[解析の設定] ウィンドウが表示されます。
[どこを] ペインで解析システムを指定し、[何を] ペインで解析ターゲットを指定します。
[どのように] ペインで、必要なイベントベース・サンプリング解析タイプを選択します。通常は、ハードウェア・イベントベース・サンプリング・モードでホットスポット解析を始めることを推奨します。
必要に応じて、収集オプションを設定します。コールスタックを解析する場合、[スタックを収集] オプションを有効にすることを検討してください。
ウィンドウ下部の [開始] ボタンをクリックして、選択した解析タイプを実行します。
インテル® VTune™ プロファイラーは、実行パスの情報とハードウェア・イベントベースのサンプリング・データを収集します。ハードウェア・イベント・ビューポイントで収集された結果を参照して、検出された呼び出しパスに関するパフォーマンス、並列処理および消費電力データを確認します。
注
イベントベース・スタック・サンプリング収集は、システム全体の設定には使用できません。起動またはアタッチするアプリケーションを指定する必要があります。
デフォルトで、Linux* システムでは、インテル® VTune™ プロファイラーはスタックを含むハードウェア・イベントベース収集にドライバーを使用しない Perf* ベースのモードを使用します。ドライバーベースのモードを使用するには、[スタックサイズ] オプションを 0 (無制限) に設定します。
コールスタック解析ではデータ収集のオーバーヘッドが増えます。スタックサイズに関連するオーバーヘッドを最小限にするには、カスタム・ハードウェア・イベントベース・サンプリング設定の [スタックサイズ] オプション、または CLI の -stack-size knob を使用してスタックのサイズを制限します。Linux* では、デフォルトで、1024 バイトのスタックサイズが収集されます。Windows* では、デフォルトで、完全なスタックサイズが収集されます (サイズ値ゼロ)。このオプションを無効にすると、オーバーヘッドは減少しますがスタックデータは収集されません。
パフォーマンス解析
[ハードウェア・イベント] ビューポイントを選択し、[イベントカウント] タブをクリックします。デフォルトでは、グリッドのデータはクロックティック (CPU_CLK_UNHALTED) イベントでソートされ、上位のホットスポットが先頭に表示されます。
[+] 記号をクリックすると、各ホットスポット (デフォルトでは関数) を展開してホットスポットが実行された呼び出しパスを表示できます。インテル® VTune™ プロファイラーは、パスの実行頻度に応じて呼び出しパスごとにすべてのハードウェア・イベントを解析します。
![[ハードウェア・イベント] ビューポイント: 呼び出しパスごとのイベントカウント](GUID-0C492462-AFC9-4939-8D6C-3360E5B95BEF-low.gif)
サンプルされたノードに至るすべての実行パスのハードウェア・イベント・カウントが、ノードのイベント数に加算されます。例えば、アプリケーションの最上位のホットスポットである CpupSyscallStub 関数では、INST_RETIRED.ANY イベントカウントは、5 つの呼び出しシーケンスすべてのイベントの合計数 (25,700,419,203) と等しくなります。
ホットスポットが、コードを変更できないサードパーティーのライブラリー関数にある、または動作が入力パラメーターに依存する場合、このような解析が重要になります。これに対処する最適化の方法は、呼び出し側を解析して関数の呼び出し回数を減らすか、パフォーマンスの低下につながるパラメーターや条件を理解することです。
並行性を調査
コールスタック収集が有効である場合 (例えば、ハードウェア・イベントベース・サンプリング・モードのホットスポット解析での [スタックを収集] オプション)、インテル® VTune™ プロファイラーはコンテキスト・スイッチを解析し、コンテキスト・スイッチのパフォーマンス・メトリックを使用してスレッドのアクティビティーに関連するデータを表示します。
[コンテキスト・スイッチの原因] > [同期] カラムヘッダーをクリックして、このメトリックでデータをソートします。最大のコンテキスト・スイッチ数と高い待機時間値の同期ホットスポットは、通常このスタックでのスレッド競合を示します。
![[ハードウェア・イベント] ビューポイント: コンテキスト・スイッチ](GUID-BB825747-D050-406A-A48E-F05D39704FB7-low.gif)
[コールスタック] ペインのドロップダウン・メニューでスタックに関連したタイプ (例えば、[プリエンプション・コンテキスト・スイッチ・カウント] タイプ) を選択して、それぞれのスレッド実行クォンタムを示す [タイムライン] ペインを調査します。濃い緑のバーはアクティブなスレッドのクォンタムを、灰色と薄い緑のバーはスレッドがインアクティブな期間 (コンテキスト・スイッチ) を示します。[タイムライン] ペインのコンテキスト・スイッチ領域にカーソルを移動すると、スレッドがインアクティブであった期間、開始時間、および理由が示されます。
![[ハードウェア・イベント] ビューポイント: スレッド・アクティビティー](GUID-E193EBE7-AA70-4635-BB54-9F9D32FA7C4D-low.gif)
[タイムライン] ペインでコンテキスト・スイッチ領域を選択すると、[コールスタック] ペインには先行するクォンタムが中断された呼び出しシーケンスが表示されます。
また、[タイムライン] ドロップダウン・メニューからハードウェアまたはソフトウェア・イベントを選択して、イベントがスレッド・アクティビティー・クォンタム (またはインアクティブな期間) にどのようにマッピングされるか確認できます。
パフォーマンスと並列処理の解析で収集したデータを関連付けます。最大のイベントカウントを持つパフォーマンス・ホットスポットや同期ホットスポットとして示される実行パスが、最適化の候補となります。次のステップとして、電力の観点から同期などのコストを理解するため、電力メトリックを解析することが考えられます。
注
Perf* ベースのドライバーを使用しない収集を使用した解析で、バージョン 4.17 より古いカーネルでは、コンテキスト・スイッチのタイプ (プリエンプションや同期) は識別されないため、次のメトリックは使用できません: 待機時間、待機率、非アクティブ時間、プリエンプションや同期コンテキスト・スイッチ・カウント。
データが生成される速度 (サンプリング周波数とスレッドの同期/競合の割合に比例) は、データがトレースファイルに保存される速度よりも大きくなる可能性があるため、プロファイラーはプロファイルされるプログラムのスレッドが実行のためスケジュールされないようにすることで、受信データレートを送信データレートに合わせようとします。これにより、明示的にポーズが要求されていなくても、タイムラインにポーズ領域が表示されます。この方法で受信データレートを制御できなかった場合、プロファイラーはサンプルレコードを失いますがハードウェア・イベント・カウントは保持されます。このような状況では、失われたサンプルレコードのハードウェア・イベント・カウントは特殊なノード ([トレース・オーバーフローのためイベントを損失しました]) に分類されます。