GPU レンダリング解析を使用して、エンジンと GPU ハードウェア・メトリックごとの GPU 利用率に基づいてコードのパフォーマンスを予測します。
注
これは、プレビュー機能です。プレビュー機能は、正式リリースに含まれるかどうかは未定です。有用性に関する皆さんからのフィードバックが、将来の採用決定の判断に役立ちます。プレビュー機能で収集されたデータは、将来のリリースで下位互換性が保証されません。
どのように動作するか
GPU レンダリング解析は、次の使用モデルに注目します。
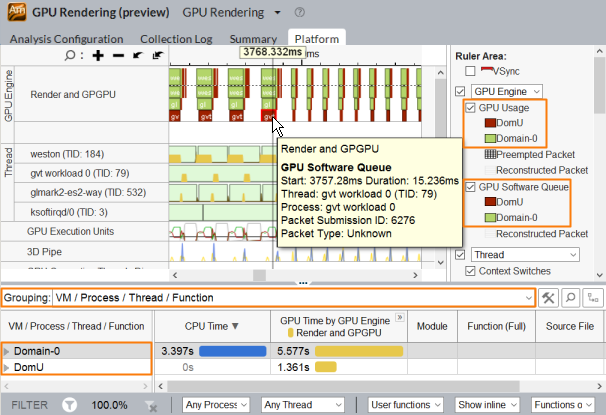
Xen* ハイパーバイザーで実行されるすべての仮想ドメイン (Dom0、DomUs) のシステム全体をプロファイルすることで、リソースを多く消費するドメインを特定し、プラットフォーム全体のボトルネックを明らかにします。
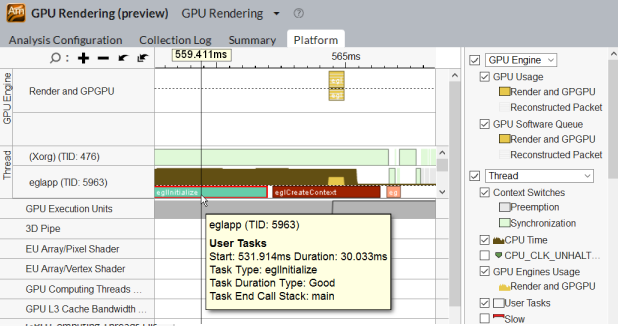
Linux* システム上で動作する OpenGL* ES アプリケーションをプロファイルして、パフォーマンス・クリティカルな API 呼び出しを特定します。
必要条件
解析を成功させるには、システムの次の設定を確認してください。
Xen* 仮想化プラットフォーム:
Xen* プラットフォームで CPU パフォーマンス・カウンターを仮想化して、完全なイベントベース・サンプリングを可能にします。
Xen* プラットフォームがインストールされているリモート・ターゲット・システムへのパスワードなしの SSH 接続を確立します。
インテル® HD グラフィックスおよびインテル® Iris® グラフィックスのハードウェア・イベントを解析するには、GPU 解析のシステム設定が適切であることを確認してください。
ターゲットを選択
GPU レンダリング解析向けのプロジェクト設定は、プロファイルするターゲットによって異なります。
すべての仮想ドメイン (Dom0, DomUs) で Xen* プラットフォーム全体を解析するには、プロファイル・システムのターゲットタイプを選択します。
OpenGL* ES API を使用するグラフィックス・アプリケーションでは、[アプリケーションを起動] または [プロセスにアタッチ] ターゲットタイプを選択します。
注
これら 2 つの使用モデルは相互に排他的です。つまり、Xen* プラットフォーム全体の解析では、OpenGL* ES API 呼び出しは検出されず、Xen* 仮想ドメイン統計は [アプリケーションを起動] と [プロセスにアタッチ] モードでは使用できません。
解析の設定と実行
GPU レンダリング解析を設定して実行します。
インテル® VTune™ プロファイラー・ツールバーの
 (スタンドアロン GUI)/
(スタンドアロン GUI)/ (Visual Studio* IDE) [解析の設定] ボタンをクリックします。
(Visual Studio* IDE) [解析の設定] ボタンをクリックします。[解析の設定] ウィンドウが表示されます。
[どのように] ペインで、
 [実行する解析タイプを選択] ボタンをクリックして、[GPU レンダリング] を選択します。
[実行する解析タイプを選択] ボタンをクリックして、[GPU レンダリング] を選択します。次の収集オプションを修正することもできます。
GPU ハードウェア・メトリック収集の GPU サンプルの間隔を指定する、[GPU サンプリング間隔 (ミリ秒)] オプションを使用します。デフォルトでは、インテル® VTune™ プロファイラーは、ハードウェア・イベントベース・サンプリング収集には 1 ミリ秒の間隔を、ユーザーモード・サンプリングとトレース収集には 1000 ミリ秒を使用します。
[プロセッサー・グラフィックス・ハードウェア・イベントを解析] オプションにより、レンダーや GPU エンジン利用率 (インテル® グラフィックスのみ) をモニターして、エンジンのどの部分に負荷がかかっているかを特定し、GPU および CPU データと関連付けます。このオプションを使用するには、root 権限が必要です。
インテル® VTune™ プロファイラーでは、プラットフォーム固有の事前定義されたハードウェア・メトリックが用意されています。この解析では、レンダー基本イベントグループが事前に選択されています。すべての事前定義は、次の実行ユニット (EU) のアクティビティーに関するデータを収集します: EU アレイ・アクティビティー、EU アレイストール、EU アレイアイドル、計算スレッドのストール、およびコア周波数。
概要 イベントには、一般的なメモリーリード/ライト帯域幅などの GPU メモリーアクセス、GPU L3 ミス、サンプラービジー、サンプラー・ボトルネック、および GPU メモリーのテクスチャーリード/ライト帯域幅を含むメトリックが含まれます。これらのメトリックは、グラフィックスと計算集約型の両方のアプリケーションに役立ちます。
基本計算 (グローバル/ローカル・メモリー・アクセスを含む) イベントグループは、GPU 上の異なるタイプのデータアクセスを区別するメトリック (型なしメモリーリード/ライト帯域幅、型ありメモリーリード/ライト・トランザクション、SLM リード/ライト帯域幅、ロードされたレンダー/GPGPU コマンド・ストリーマー、および GPU EU アレイ使用) を含みます。これらのメトリックは、GPU 上の計算集約型のワークロードに役立ちます。
拡張計算イベントグループは、インテル® プロセッサー開発コード名 Broadwell 以降の GPU 解析のみをターゲットとするメトリックを含みます。その他のシステムでは、この事前定義は利用できません。
レンダー基本 (プレビュー) イベントグループは、ピクセルシェーダー、バーテックス・シェーダー、および出力マージメトリックを含みます。
- 完全な計算イベントグループは、概要と基本計算イベントセットの組み合わせです。
詳細セクションで事前定義されたオプションを変更するか、収集されるハードウェア・イベントのリストを変更するには、新しいカスタム解析タイプを作成します。
 [開始] ボタンをクリックして解析を実行します。
[開始] ボタンをクリックして解析を実行します。
注
コマンドラインからこの解析を実行するには、下部にある  コマンドライン・ボタンを使用します。
コマンドライン・ボタンを使用します。
インテル® VTune™ プロファイラーは、指定したターゲットのデータを収集して、その結果を GPU レンダリング・ビューポイントで開きます。
データを表示
[サマリー] ビューから解析をはじめて、ワークロードが CPU または GPU のどちらで実行されているか確認します。次に、[プラットフォーム] ビューに移動し、CPU スレッドによって GPU タスクをがどのようにスケジュールされるか視覚化し、グラフィックスを使用する CPU スレッドとプロセスを識別して、GPU 実行中に CPU が何を行っているか調査します。
Xen* プラットフォーム全体を解析するには、[プラットフォーム] ビューを使用して、組込みシステムで GPU を積極的に使用している仮想ドメインを特定します。GPU アクティビティーは、適切な仮想ドメインを示すようタイムラインで色分けされています。
OpenGL* ES API 呼び出しを使用するアプリケーションを解析する場合、[プラットフォーム] ビューには呼び出しがユーザータスクとして表示され、詳細情報がポップアップに示されます。