NPU 全般ビューポイントを使用して、インテル・ニューラル・プロセシング・ユニット (NPU) 上の AI または ML ワークロードのパフォーマンスを評価および最適化します。
NPU 全般分析が実行されると、インテル® VTune™ プロファイラーは、NPU と DDR メモリー間の DDR 帯域幅に関する NOC メトリック・セット・データを収集します。データ収集が完了すると、インテル® VTune™ プロファイラーは結果を準備し、[サマリー] ウィンドウに表示します。
NPU 全般サマリー
[サマリー] ウィンドウには、次のセクションから始まる NPU パフォーマンス・データが表示されます。
- NPU デバイスのロード - このセクションは、NPU と DDR メモリー間で転送されたデータの量を示します。
- NPU 上位計算タスク - このセクションでは、NPU でタスクが実行された合計時間を取得します。
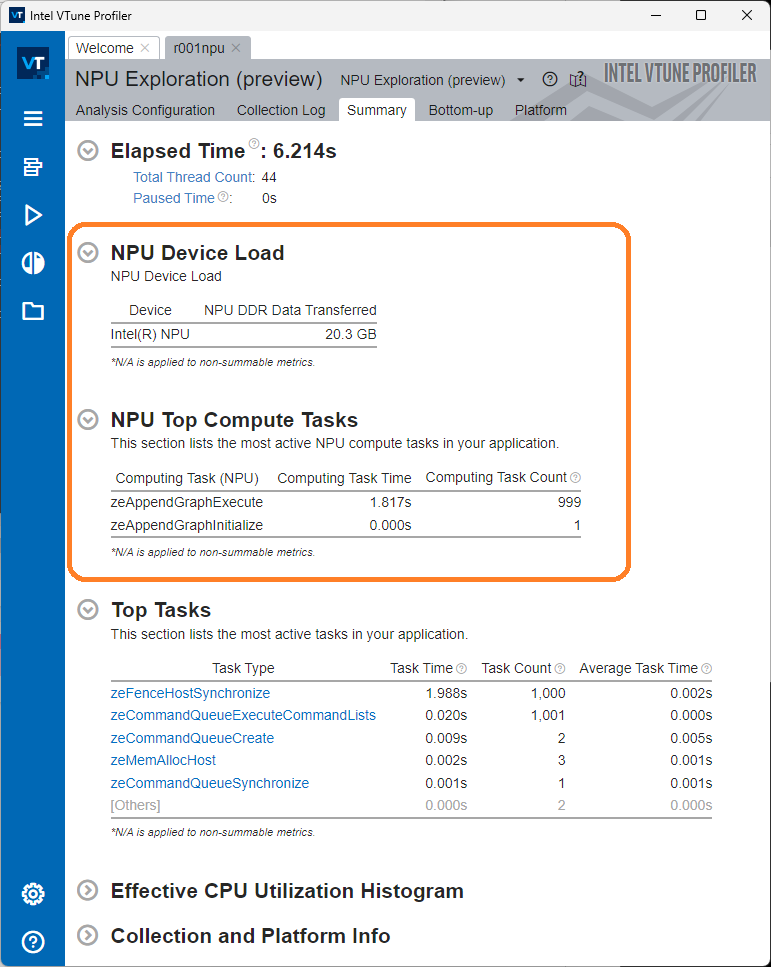
次に、上位タスクのリストを参照して、NPU にワークをオフロードしたさまざまなホストタスクを確認します。
[NPU 全般] ボトムアップ・ウィンドウ
[ボトムアップ] ウィンドウに切り替えて、ホストタスクの調査を続行します。[グループ化] プルダウンメニューで、タスクドメイン / タスクタイプ / 関数 / 呼び出しスタックのグループ化を選択します。
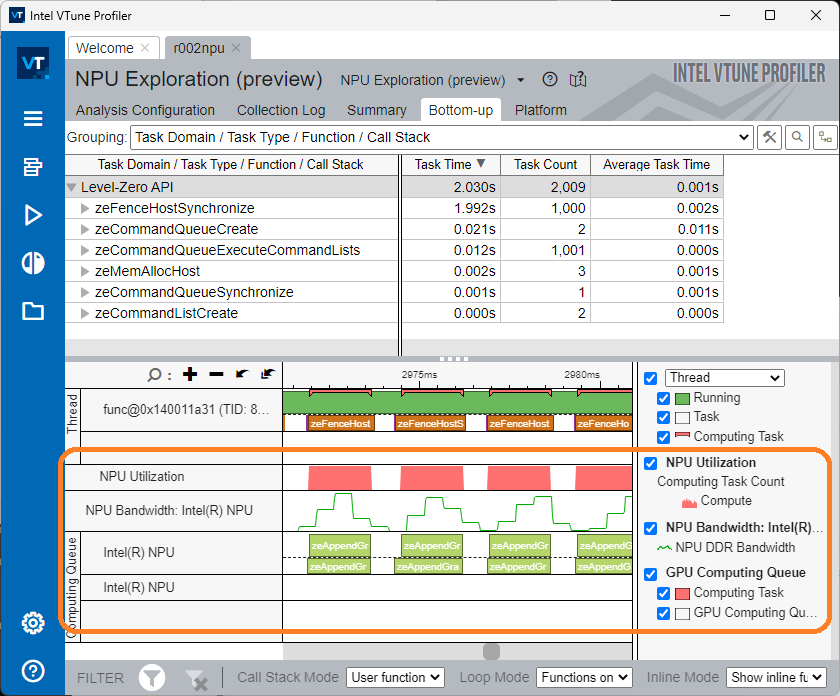
デバイスタスクが開始されたらその実行を確認します。それは、タスクが計算キューに追加された瞬間です。
計算キューのセクションでは、グラフの点線の上の部分は、タスクが NPU で実行された期間を示します。
グラフの点線の下の部分は、タスクが NPU での実行をキューで待機していた期間を示します。タスクは、NPU で実行が終了すると計算キューから削除されます。