プラットフォーム上の各種 CPU と GPU コアの実行を調査し、CPU と GPU のアクティビティーを関連付けて、アプリケーションが GPU 依存か CPU 依存かを特定します。
SYCL*、インテル® メディア SDK および OpenCL* ソフトウェア・テクノロジーをサポートし、レンダリング、ビデオ処理、および計算に GPU (グラフィックス処理ユニット) を使用するアプリケーションの GPU オフロード解析を実行します。
このツールは、システム全体のすべてのコアクロックを自動的に調整し、同じ時間進行で GPU ベースのワークロードと CPU ベースのワークロードを解析できるようにします。
この解析は以下を可能にします。
アプリケーションが SYCL* または OpenCL* カーネルをどのくらい効率良く使用しているか確認し、GPU 計算/メディア・ホットスポット解析でさらに詳しく調査します。
インテル® Media SDK タスクの実行を時間経過で解析します (Linux* ターゲットのみ)。
GPU 使用を調査し、各時点での GPU エンジンのソフトウェア・キューを解析します。
GPU オフロード解析では、インテル® VTune™ プロファイラーは CPU と GPU 両方で実行されるコードをインストルメントします。構成の設定に応じて、インテル® VTune™ プロファイラーは、GPU ハードウェアの効率と解析の次のステップに関する指標となるパフォーマンス・メトリックを提供します。解析の次のステップを特定
GPU オフロード解析の側面
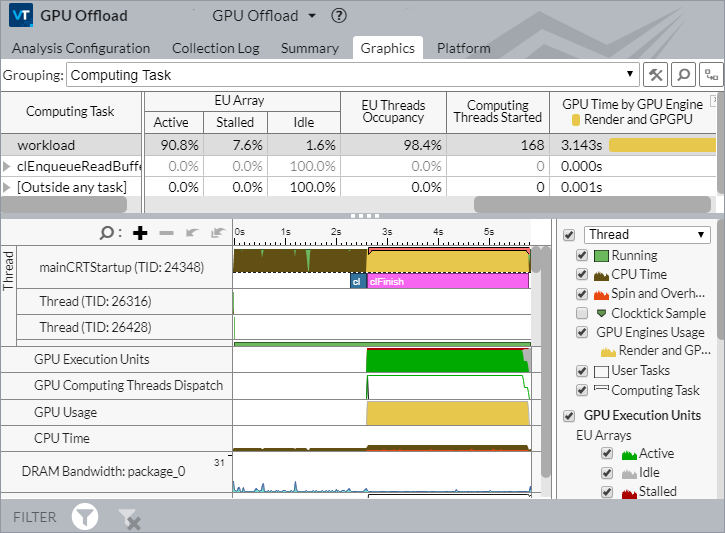
デフォルトでは、GPU オフロード解析により、[GPU 利用率] オプションが有効になり、GPU ビジーを経時的に調査して、アプリケーションが CPU 依存であるか、GPU 依存であるかが分かります。[グラフィックス] ウィンドウで [タイムライン] ビューを調べると、次のことが分かります。
- GPU がほとんどの時間でビジーであること
- ビジーな期間の間に小さなアイドルギャップがあります
- GPU ソフトウェア・キューが空になることはめったにありません
これらの動作が確認できる場合、アプリケーションは GPU 依存であると考えられます。
ビジー間隔のアイドル時間が長く、その間 CPU がビジーとなる場合、アプリケーションは CPU 依存であると言えます。
しかし、このような明確な状況はまれであるため、詳細を解析してすべての依存関係を明らかにする必要があります。例えば、GPU エンジンの使用がシリアル化されている場合 (GPU エンジンがビデオ処理とレンダリング処理を交互に実行するなど)、誤って GPU 依存と見なしてしまう可能性があります。このケースでは、CPU で実行されるアプリケーションが原因で GPU 上で非効率なスケジューリングが生じています。
解析の設定
Windows* システムで、一般的な GPU の使用状況を経時的に監視するには、管理者としてインテル® VTune™ プロファイラーを実行します。
SYCL* アプリケーションをプロファイルするには、-gline-tables-only および -fdebug-info-for-profiling インテル® oneAPI DPC++ コンパイラー・オプションを使用してコードがコンパイルされていることを確認してください。
プロジェクトを作成して、 解析システムおよびターゲットを指定します。
解析を実行
[解析の設定] ウィンドウを開きます。[ようこそ] 画面 (スタンドアロン・バージョン) の
 ボタン、または
ボタン、または  [解析の設定] (Visual Studio* IDE) ツールバーボタンをクリックします。
[解析の設定] (Visual Studio* IDE) ツールバーボタンをクリックします。[どのように] ペインから解析ツリーを開き、[アクセラレーター] グループから GPU オフロード解析を選択します。
GPU オフロード解析は、GPU 利用データを収集し、プロセッサー・グラフィックス・イベントを取得するように事前設定されています (グローバル・メモリー・アクセスのプリセット)。
注
システムに複数のインテル製 GPU が接続されている場合、選択した GPU または接続されているすべての GPU で解析を実行します。詳細については、複数の GPU の解析を参照してください。
GPU 解析オプションを設定します。
[GPU プログラミング API をトレース] オプションを使用すると、インテル® プロセッサー・グラフィックスで実行されている SYCL*、レベルゼロ、OpenCL*、およびインテル® Media SDK プログラムを解析できます。このオプションは、CPU 側でアプリケーションのパフォーマンスに影響する可能性があります。
[ホットスタックを収集] オプションを使用して、CPU で実行されるコールスタックを解析し、クリティカル・パスを特定します。また、GPU 計算タスクの CPU 側のスタックを調査し、GPU オフロードの効率を調査できます。結果が表示されたら、[フィルター] バーで [コールスタック] モードを選択して、SYCL*、レベルゼロ。または OpenCL* ランタイムのコールスタックをソートします。
[CPU - GPU 帯域幅を解析] オプションを使用して、タイムライン上のハードウェア・イベントに基づくデータ転送を表示します。このタイプの解析には、インテル・サンプリング・ドライバーがインストールされている必要があります。
Xe リンク接続を備えた GPU では、[Xe リンクの使用を解析] オプションを使用して、GPU インターコネクト (Xe リンク) 間のトラフィックを調べます。この情報は、GPU 間のデータフローと Xe リンクの使用状況を評価するのに役立ちます。
GPU パフォーマンスの詳細を表示でハードウェアの使用効率を推測し、次のステップに役立つメトリック (プロセッサー・グラフィックス・イベント解析に基づく) を取得します。次のメトリックに関する情報が収集されます。
EU アレイのメトリックは、GPU コアアレイの内訳を示します。
アクティブ: すべてのコアで命令の実行に費やされたサイクルの正規化された合計を示します。式:
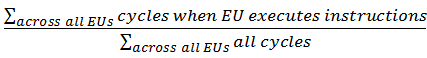
ストール: すべてがストールに費やされたサイクルの正規化された合計を示します。少なくとも 1 つのスレッドがロードされているが、コアがストールしている状態。式:
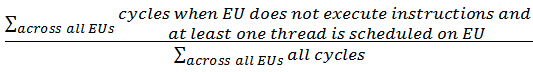
アイドル: コアにスレッドがスケジュールされなかったすべてのサイクル数 (すべてのコア分) の正規化された合計を示します。式:
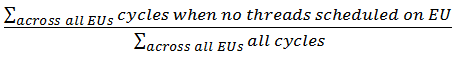
- EU スレッド占有率メトリックは、スロットにスケジュールされたスレッドがある場合の、すべてのコアとスレッドスロットの正規化された合計サイクル数を示します。
計算スレッド開始メトリックは、すべての EU で計算ワークを開始したスレッド数を示しています。
[開始] をクリックして解析を実行します。
注
インテル® Arc™ Alchemist (DG2) 以降のインテル® Xe グラフィックス製品ファミリーと以降の世代では、従来の用語から GPU アーキテクチャーの用語が変更されています。用語変更の詳細と、従来のコンテンツとの対応については、インテル® Xe グラフィックスの GPU アーキテクチャー用語を参照してください。コマンドラインから実行
次のコマンドを使用します。
$ vtune -collect gpu-offload [-knob <knob_name=knob_option>] -- <target> [target_options]
注
任意の解析設定のコマンドラインを生成するには、ウィンドウの下にある [コマンドライン] ボタンをクリックします。
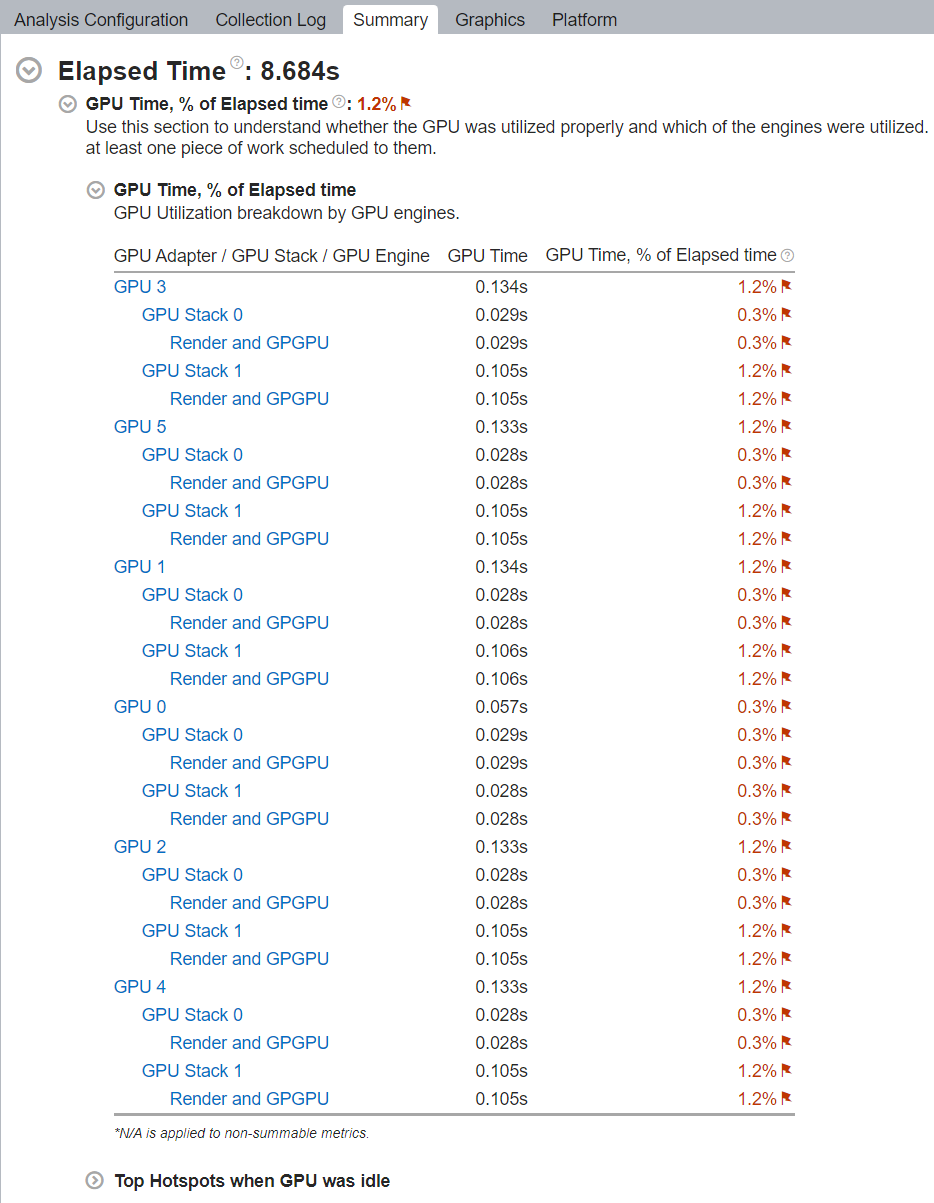
GPU オフロード解析がデータ収集を完了すると、[サマリー] ウィンドウにメトリックが表示されます。
- GPU 利用率
- GPU アイドル時間
- Xe リンク利用率
- CPU ホストで実行された最もアクティブな計算タスク
- GPU がアイドルの時に CPU で実行された最もアクティブな計算タスク
- GPU で動作した最もアクティブな計算タスクと占有率情報
 次のステップに向けた [推奨事項] とガイドも表示されます。
次のステップに向けた [推奨事項] とガイドも表示されます。
複数 GPU の解析
システムに複数のインテル製 GPU が接続されている場合、インテル® VTune™ プロファイラーは接続されているすべてのアダプターを [ターゲット GPU] プルダウンメニューで識別します。次のガイドに従ってください。
- [ターゲット GPU] プルダウンメニューを使用して、プロファイルを行うデバイスを指定します。
- インテル® VTune™ プロファイラーがシステムで複数のインテル製 GPU を検出した場合にのみ、[ターゲット GPU] プルダウンメニューが表示されます。メニューには利用可能な GPU アダプターの [バス/デバイス/関数 (BDF)] が示されます。この情報は、Windows* (タスク・マネージャーを参照) または Linux* (lspci を実行) でも確認できます。
- ユーザーが GPU を選択していない場合、インテル® VTune™ プロファイラーはデフォルトで最も新しいデバイスファミリーを選択します。
- [すべてのデバイス] を選択すると、システムに接続されているすべての GPU で解析が実行されます。
- 特性化モードの完全な計算セットは、 複数アダプターおよび複数タイル解析では利用できません。
解析が完了すると、インテル® VTune™ プロファイラーは [サマリー] ウィンドウにタイル情報を含む GPU ごとのサマリー結果を表示します。
GPU アダプターの命名規則
GPU プロファイル解析の結果は、エイリアスにより GPU アダプターを参照します。。
- エイリアスは、プロアイル結果の [サマリー]、[グリッド]、[タイムライン] セクションで GPU アダプターを識別します。GPU アダプターの完全な名前は、BDF の詳細とともに [収集とプラットフォーム] セクションに表示されます。
- 単一のエイリアスは、同一マシンで収集されたすべての結果の GPU アダプターを識別します。
- エイリアスの命名規則は、GPU 0、GPU 1 のようになります。
- エイリアスの割り当ては次の順番で行われます。
- インテル GPU アダプター (最小の PCI* アドレスから)
- 非インテル GPU アダプター
- ドライバーなどそのほかのソフトウェア・デバイス
GPU トポロジー図
システムに接続されている複数のインテル GPU (またはマルチスタック GPU) 全体の GPU 解析を実行すると、[サマリー] ウィンドウに GPU トポロジー図の GPU 間のインターコネクトが表示されます。この図には、システムに接続されている最大 2 つのソケットと 6 つの GPU 間の情報が示されています。
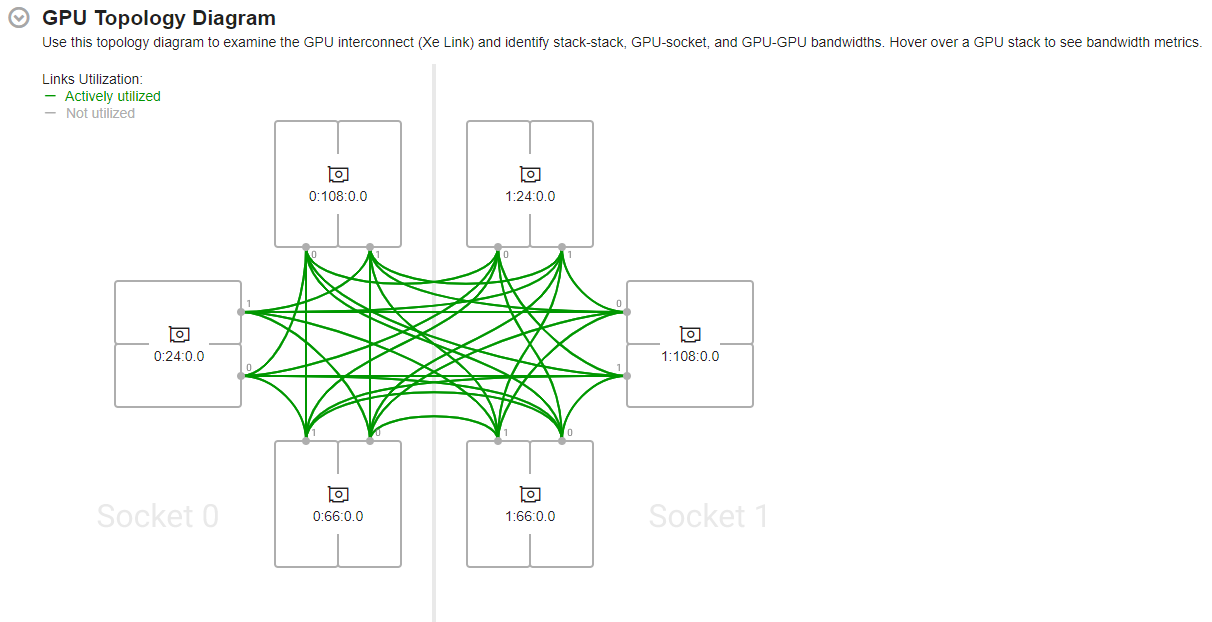
GPU トポロジー図には、ソケット (GPU 接続に使用) および GPU 間のインターコネクト (Xe リンク) 接続に関する情報が表示されます。GPU トポロジー図の GPU は、バスデバイス機能 (BDF) 番号で識別できます。
GPU スタックにマウスを移動すると、アクティブに使用されているリンク (緑色のハイライト表示) と対応する帯域幅メトリックが表示されます。
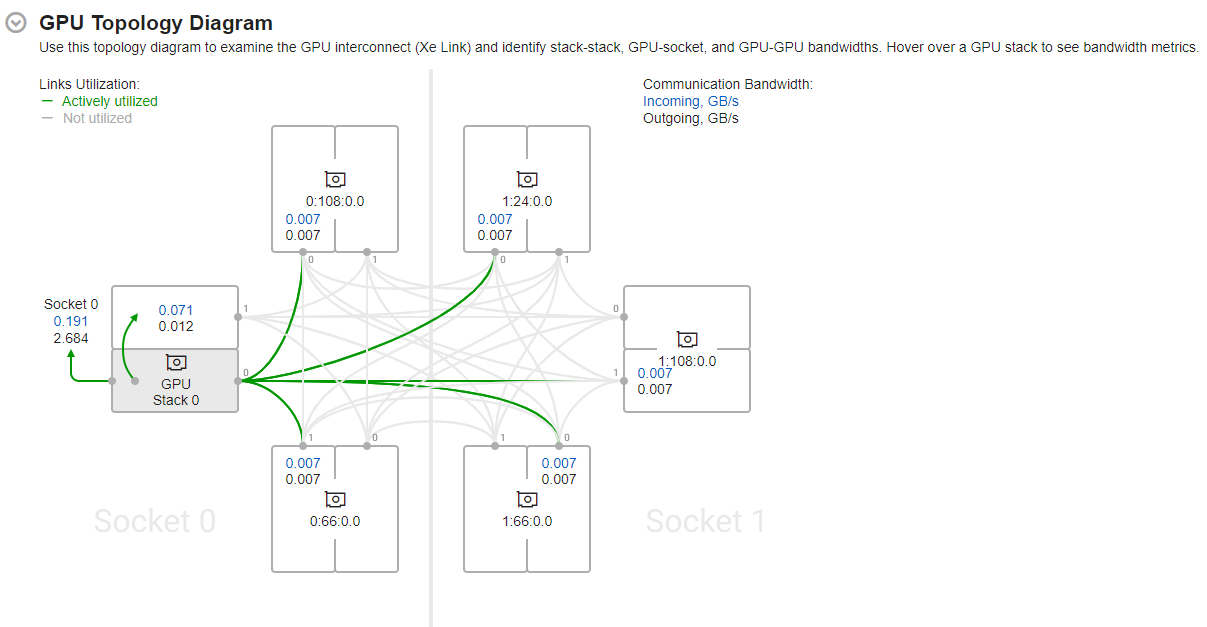
ここに示される情報を基に、転送される以下の平均データを確認します。
- Xe リンクを介して
- GPU スタック間
- GPU とソケット間
Xe リンク利用率解析
Xe リンクを備えた GPU では、(解析を実行する前に) インターコネクト (Xe リンク) の使用状況を解析するオプションを確認すると、[サマリー] ウィンドウに GPU インターコネクト (Xe リンク) を介して収集された帯域幅とトラフィック・データを表示するセクションが含まれています。この情報を GPU トポロジー図と併用して、GPU 間のトラフィック分散のインバランスを検出します。一部のリンクがほかのリンクよりも利用頻度が高い場合、その理由を確認します。

[サマリー] ウィンドウの Xe リンク利用率と、[プラットフォーム] ウィンドウには、経時的な帯域幅データが表示されます。
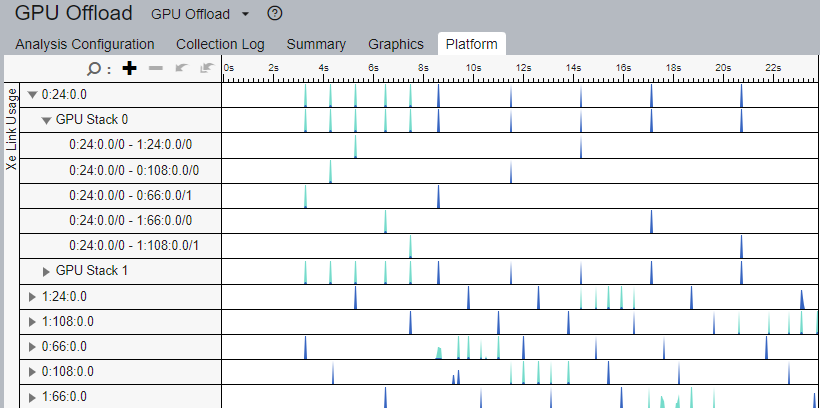
この情報を使用して、次のことを行うことができます。
- トラフィック・データをカーネルまたはコード実行と照合します。
- アプリケーションの実行中はいつでも帯域幅を確認できます。
- Xe リンクを使用するとアプリケーションのパフォーマンスが向上するか確認します。
- Xe リンクがアプリケーションの実行中に予測される帯域幅に達しているか確認します。
ホストとデバイス間のデータ転送解析
CPU ホストと GPU デバイス間のデータ転送効率を理解するには、[サマリー] と [グラフィックス] ウィンドウでメトリックを確認してください。
[サマリー] ウィンドウには、計算タスクに費やされた合計時間と、タスクごとの実行時間が表示されます。時間差は、ホストとデバイス間のデータ転送に費やされた時間を表します。実行時間がデータ転送時間よりも短い場合、オフロードスキーマの最適化が有効であることを表します。
[サマリー] ウィンドウで、ホスト - デバイス転送 と デバイス - ホスト転送 などのオフロードのコストを示すメトリックを確認します。これらのメトリックは、パフォーマンスを制限する不要なメモリー転送を特定するのに役立ちます。
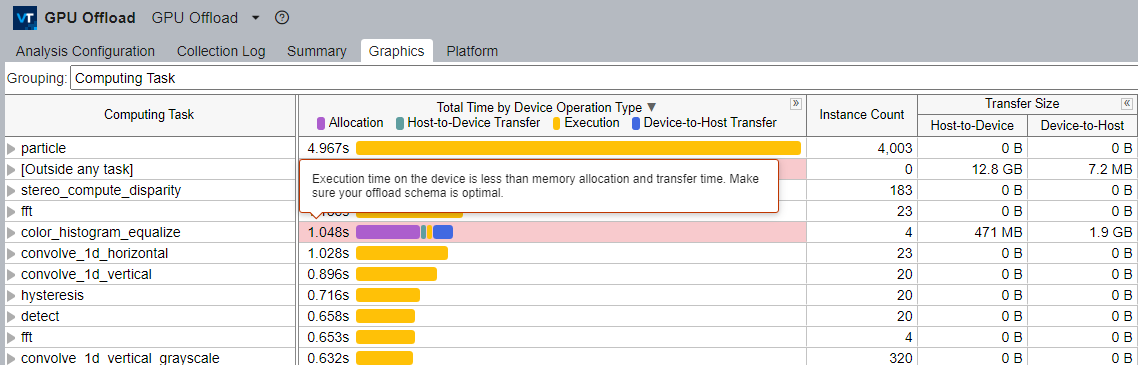
[グラフィックス] ウィンドウで、それぞれの計算タスクの合計時間を示す [デバイス操作タイプによる合計時間] カラムを参照します。
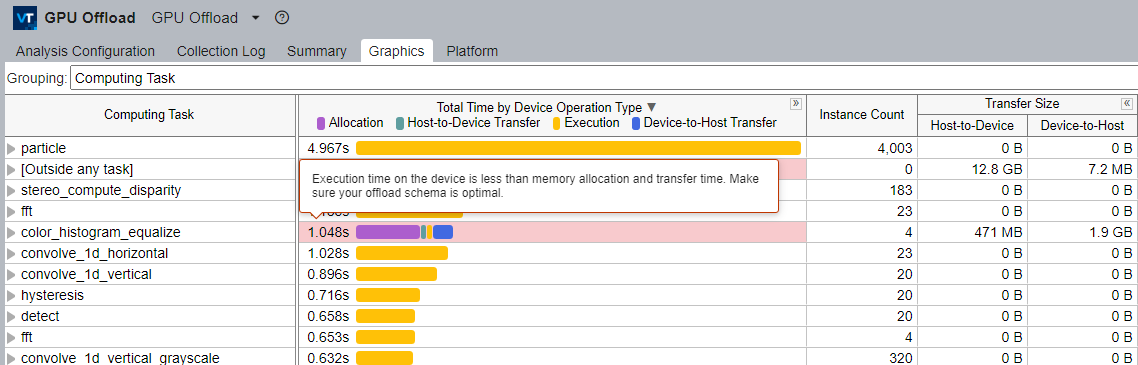
合計時間は以下のように分類できます。
- 割り当て時間
- ホストからデバイスへのデータ転送時間
- 実行時間
- デバイスからホストへのデータ転送時間
この分類は、データ転送と GPU 実行時間のバランスを理解するのに役立ちます。[グラフィックス] ウィンドウには、[転送サイズ] セクションに計算タスクごとのホストとデバイス間のデータ転送サイズも表示されます。
不適切なオフロードスキーマを持つ計算タスクは、スキーマの改善を促す詳しい説明とともにハイライト表示されます。
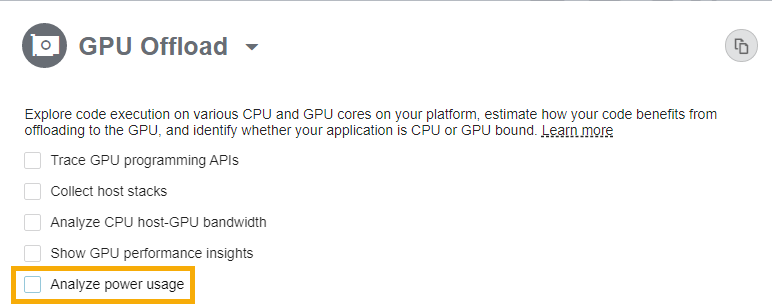
GPU の電力消費量を調査
Linux* 環境で、インテル® Iris® Xe MAX グラフィックス・ディスクリート GPU で、GPU オフロード解析を実行すると、GPU デバイスで消費されるエネルギーに関連する情報を確認できます。この情報を収集するには、[解析の設定] で [電力使用を解析] オプションをオンにしてください。
注
電力消費メトリックは、Windows* マシンでインテル® Iris® Xe MAX グラフィックスをスキャンする GPU プロファイル解析では表示されません。解析が完了したら、結果に示されるこれらの電力消費データを参照してください。
[グラフィックス] ウィンドウで、計算タスクごとにグループ化されたグリッドの [電力消費] カラムを確認します。このカラムをソートして、最も電力を消費した GPU カーネルを特定します。この情報は、タイムラインにもマッピングされていることを確認できます。
最も電力を消費する GPU カーネルを検出するには、適切な電力効率を得るため、上位のエネルギー・ホットスポットをチューニングすることから開始します。
GPU 処理時間も最適化を目的とする場合、カーネルごとの電力消費メトリックを確認して、パフォーマンス時間と電力使用量のトレードオフを観察します。
この比較を容易にするため、[合計時間] の隣にある [電飾消費] カラムに移動します。
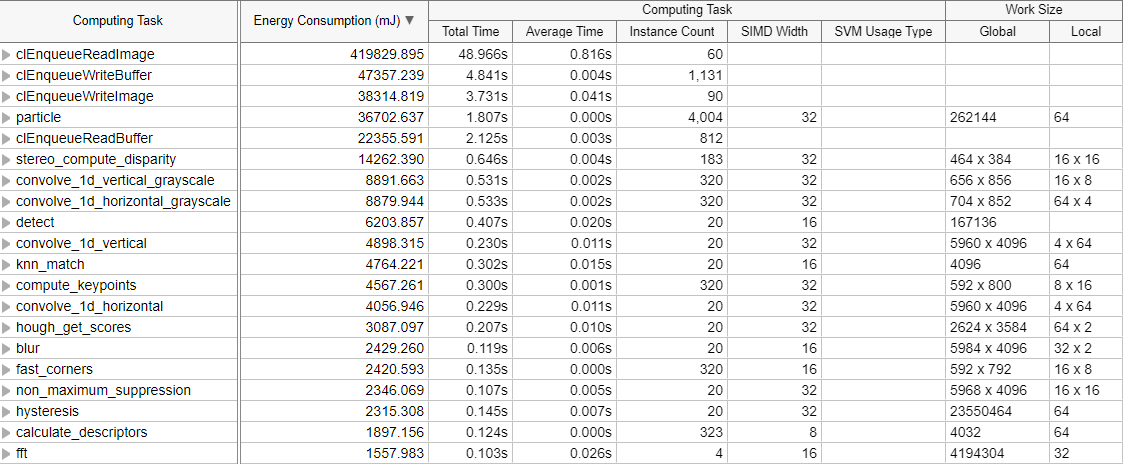
電力使用量と処理時間には直接的な相互関係はないことに気づくかもしれません。最も高速に計算を行うカーネルは、エネルギー消費量が最小であるカーネルとは異なる場合があります。電力使用量の値が大きいほど、ストール/待機期間が長いかどうかを確認します。
oneAPI レベルゼロ API を使用する SYCL* アプリケーションのサポート
このセクションでは、バックエンドで OpenCL* または oneAPI レベルゼロ API を実行する SYCL* アプリケーションの GPU オフロード解析のサポートについて説明します。インテル® VTune™ プロファイラーは、oneAPI レベルゼロ API のバージョン 1.0.4 をサポートします。
サポート対象 |
バックエンドで OpenCL* を使用する SYCL* アプリケーション |
バックエンドでレベルゼロを使用する SYCL* アプリケーション |
|---|---|---|
オペレーティング・システム |
Linux* Windows* |
Linux* Windows* |
データ収集 |
インテル® VTune™ プロファイラーは、GPU 計算タスクと GPU 計算キューを収集して表示します。 |
インテル® VTune™ プロファイラーは、GPU 計算タスクと GPU 計算キューを収集して表示します。 |
データ表示 |
インテル® VTune™ プロファイラーは、収集された GPU HW トリックを特定のカーネルにマップし、それらを図に表示しま。 |
インテル® VTune™ プロファイラーは、収集された GPU HW トリックを特定のカーネルにマップし、それらを図に表示しま。 |
ホスト側の API 呼び出しを表示 |
はい |
はい |
計算タスクのソース・アセンブラー |
はい |
はい |
DirectX* アプリケーションのサポート
このセクションでは、CPU ホストで動作する Microsoft® DirectX* アプリケーションをトレースする GPU 解析で利用可能なサポートについて説明します。このサポートは、アプリケーションを起動モードでのみ利用できます。
| サポート対象 | DirectX* アプリケーション |
|---|---|
オペレーティング・システム |
Windows* |
API のバージョン |
DXGI、Direct3D 11、Direct3D 12、Direct3D 12 上の 11 |
ホスト側の API 呼び出しを表示 |
はい |
ダイレクト・マシンラーニング (DirectML) API |
はい |
デバイス側の計算タスク |
いいえ |
計算タスクのソース・アセンブラー |
いいえ |