インテル® VTune™ プロファイラーによるパフォーマンス解析の開始点として [サマリー] ウィンドウを使用します。このウィンドウにアクセスするには、結果タブの [サマリー] サブタブをクリックします。
解析タイプに応じて、[ホットスポット] ビューポイントで、[サマリー] ウィンドウは次のアプリケーション・レベルの統計を提供します。
注
 [クリップボードへコピー] ボタンをクリックして、選択したサマリーセクションの内容をクリップボードへコピーできます。
[クリップボードへコピー] ボタンをクリックして、選択したサマリーセクションの内容をクリップボードへコピーできます。
解析メトリック
[サマリー] ウィンドウは、アプリケーション実行の全体を調査するのに役立つ CPU メトリックの一覧を表示します。疑問符  アイコンにマウスを移動すると、メトリックを説明するポップアップ・ヘルプが表示されます。パフォーマンスの問題としてフラグが付けられているメトリックにカーソルを移動して、詳しい説明を表示します。
アイコンにマウスを移動すると、メトリックを説明するポップアップ・ヘルプが表示されます。パフォーマンスの問題としてフラグが付けられているメトリックにカーソルを移動して、詳しい説明を表示します。
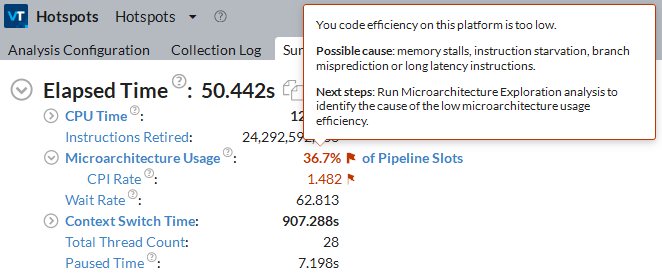
経過時間のメトリックを指標として、最適化前後の結果を比較するベースラインを求めます。マルチスレッド・アプリケーションでは、CPU 時間はすべてのアプリケーション・スレッドの CPU 時間の合計であるため、CPU 時間は経過時間とは異なります。
特定の解析タイプでは、有効な CPU 時間は CPU 利用率ごとに次のように分類されます。
利用率タイプ |
説明 |
|---|---|
アイドル |
アイドル利用率。デフォルトでは、CPU 時間の消費が多くない場合 (1 CPU の 50% 未満)、アイドルとして分類されます。 |
低い |
低い利用率。デフォルトでは、低い利用率は、同時に実行される CPU 数がターゲットの CPU 利用率の 50% 未満の状態です。 |
OK |
許容できる (OK) 利用率。デフォルトでは、OK 利用率は、同時に実行される CPU 数がターゲットの CPU 利用率の 51% ~ 85% の状態です。 |
理想的 |
理想的な利用率。デフォルトでは、理想的な利用率は、同時に実行される CPU 数がターゲットの CPU 利用率の 86% ~ 100% の状態です。 |
[オーバーヘッドとスピン時間] メトリックが示される場合 (解析による)、アプリケーションが使用する同期とスレッド化ライブラリーが CPU 時間にどのように影響しているか理解できます。これらのカテゴリーのメトリックを調査して、システム同期 API、インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB)、および OpenMP* などの同期やスレッド化ライブラリーの呼び出しで、アプリケーションが時間を費やしている場所を特定します。インテル® VTune™ プロファイラーでは、コードが CPU 時間を消費する次のような非効率性を確認できます。
インバランスまたはシリアルスピン時間 |
インバランスまたはシリアルスピン時間は、ワーキングスレッドが同期バリアでスピンして CPU リソースを消費している CPU 時間です。これは、ロード・インバランス、すべてのワーキングスレッド間の不十分な並行性、またはシリアル化された実行のバリアでの待機によって引き起こされる可能性があります。 |
ロック競合スピン時間 |
ロック競合時間は、ワーキングスレッドがロックでスピンして CPU リソースを消費している CPU 時間です。高いメトリック値は、過度に競合する同期オブジェクトと非効率な並列処理の可能性を示します。過度な同期を避けるには、可能であればリダクション、アトミック操作、またはスレッドローカル変数を使用することを検討してください。 |
その他のスピン時間 |
このメトリックは、スレッド・ランタイム・ライブラリー内の未分類のスピン時間を示します。 |
生成のオーバーヘッド時間 |
生成時間は、並列ワークを開始する際にランタイム・ライブラリーが費やす CPU 時間です。 |
スケジュールのオーバーヘッド時間 |
スケジュール時間は、ワークをスレッドに割り当てる際にランタイム・ライブラリーが費やす CPU 時間です。この時間が大きい場合、ワークを粗いチャンクにすることを検討してください。 |
リダクションのオーバーヘッド時間 |
リダクション時間は、ランタイム・ライブラリーがループまたは領域のリダクション操作に費やす CPU 時間です。 |
アトミックのオーバーヘッド時間 |
アトミック時間は、アトミック操作でランタイム・ライブラリーが費やす CPU 時間です。 |
その他のオーバーヘッド時間 |
このメトリックは、スレッド・ランタイム・ライブラリー内の未分類のオーバーヘッド時間を示します。 |
解析タイプに応じて、インテル® VTune™ プロファイラーはインテル® アーキテクチャーで定義されるしきい値と解析したメトリックを比較し、アプリケーション全体のパフォーマンスの問題としてメトリックをピンク色でハイライト表示することがあります。そのような値の問題に関する説明は、重要なメトリックの下に表示されます。または、ハイライト表示されたメトリックにカーソルを移動して表示することもできます。
リストの各メトリックはハイパーリンクとして表示されます。ハイパーリンクをクリックして [ボトムアップ] ウィンドウを開き、選択したメトリックでグリッドをソートするか、グリッドで選択したオブジェクトをハイライト表示します。
上位ホットスポット
インテル® VTune™ プロファイラーは、最もパフォーマンス・クリティカルな関数と CPU 時間を [上位ホットスポット] に表示します。これらの関数を最適化することで、一般にアプリケーション全体のパフォーマンスが向上します。リストの関数をクリックすると、その関数の [ボトムアップ] ウィンドウが表示されます。
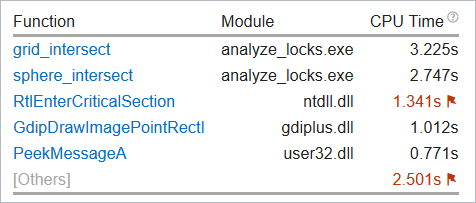
グレー表示された [その他] のモジュールがある場合、この表に含まれないアプリケーションのほかのすべての関数の合計値が示されます。
注
ビューポイント設定ファイルを介してこのリストのオブジェクト数と表示メトリックを制御できます。
詳しく調査
解析をデフォルトの [追加のパフォーマンス情報を表示] オプションで実行した場合、[サマリー] ビューにはハードウェア利用やベクトル化の効率など、ターゲットの追加メトリックを示す [詳しく調査] セクションが含まれます。この情報は、パフォーマンス解析の次のステップを明らかにし、最適化作業に集中すべき場所を特定するのに役立ちます。
上位タスク
ここでは、実行に最も時間を費やしたタスクのリストが示されます。対象となるタスクは、タスク API でマークされたコード領域、または Ftrace イベント、Atrace イベント、インテル® メディア SDK プログラム、OpenCL* カーネルなどを監視するように設定されたシステムタスクです。
表のタスクタイプをクリックすると、[タスクタイプ] の粒度でグループ化されたグリッドビュー (ボトムアップやイベントカウント) が表示されます。詳細は、「タスク解析」を参照してください。
平均帯域幅
ここでは、プロファイル・セッション全体で平均化されたパッケージあたりの合計メモリー帯域幅、リード帯域幅、ライト帯域幅を示します。このデータは、CPU/GPU 並行性など、プラットフォーム全体のメトリックを収集する解析タイプを実行する場合に使用できます。
この表の値がプラットフォームの利用可能な帯域幅の上限に近い場合、アプリケーションのパフォーマンスはメモリー帯域幅によって制限されていると言えます。プラットフォームの最大帯域幅を測定するには、インテル® メモリー・レイテンシー・チェッカー (英語) などのベンチマークを使用できます。
CPU 利用率の分布図
[CPU 利用率の分布図] を調査して、特定数の CPU が同時実行されているウォールクロック時間のパーセンテージを解析します。
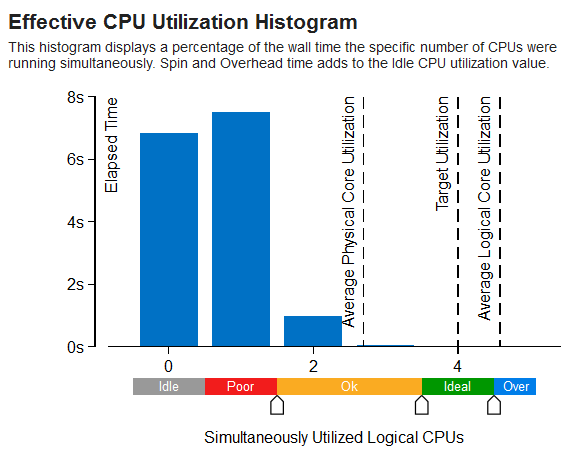
| 操作 | 説明 |
|---|---|
垂直バー |
バーにカーソルを移動して、アプリケーションが論理 CPU 数で費やした経過時間を特定できます。 |
ターゲットの利用率 |
ターゲットの CPU 利用率を特定します。この数は論理 CPU 数と等価です。この数値を最適化の目標とします。 |
平均 CPU 利用率 |
実行全体で並列に実行されている CPU の平均数を特定します。これは、CPU 時間/経過時間で計算できます。 どの時点の CPU 利用率も、使用可能な論理 CPU 数を超えることはできません。システムがオーバーサブスクライブ状態で、CPU 数よりも多くのスレッドを実行している場合であっても、CPU 利用率は CPU 数と同じです。 この数値をパフォーマンス測定のベースラインとして使用します。CPU 時間がスピンに費やされる場合を除いて、この値をできるだけ論理 CPU 数に近づけます。 |
利用率表示バー |
それぞれの利用率レベルが、同時に利用される論理 CPU にどのように割り当てられているか解析します。 |
フレームレートの分布図
フレーム API を使用して、グラフィックス・アプリケーションで繰り返し実行されるコード領域 (フレーム) の始まりと終わりをマークした場合、インテル® VTune™ プロファイラーはこのデータを解析して、低速に実行された領域を特定するのを支援します。[フレームレートの分布図] を調査して、低速あるいは高速なフレームドメインを特定します。
操作 |
説明 |
|---|---|
[ドメイン] ドロップダウン・メニュー |
[フレームレートの分布図] で解析するフレームドメインを選択します。単一のドメインのみが利用できる場合、ドロップダウン・メニューは灰色で表示されます。次に、[フレームドメイン] でグループ化された [ボトムアップ] ウィンドウに切り替え、データを低速フレームでフィルター処理して、[関数] グループに切り替えて低速なフレームドメインの関数を特定します。コードを最適化して、フレームレートを一定に維持するようにします (例えば、1 秒あたり 30 から 60 フレーム)。 |
垂直バー |
バーにカーソルを移動すると、アプリケーションが特定のフレームレートで実行したフレームの合計数が示されます。低速フレームまたは高速フレームが多いと、パフォーマンスのボトルネックが発生します。 |
フレームレート・バー |
スライドバーを使用して、開いている結果とそれに関連するすべての結果のフレームレートのしきい値 (1 秒あたりのフレーム数) を調整します。 |
OpenMP* 解析: 収集時間
このセクションには、プログラムのシリアル領域 (並列領域外) と並列領域の持続時間のメトリックと収集時間が表示されます。シリアル時間が長い場合、[上位のシリアル・ホットスポット] を確認して、並列処理を導入するか、並列化が困難なシリアル領域ではアルゴリズムやマイクロアーキテクチャーのチューニングを行って、シリアル実行を短縮することを検討してください。スレッド数の多いマシンのシリアル領域は、潜在的なスケーリングに深刻な悪影響を与えるため (アムダールの法則)、可能な限り最小にすべきです。
潜在的なゲインによる上位 OpenMP* 領域
コードの並列領域で CPU 利用率の効率を予測するには、[潜在的なゲイン] (英語) メトリックを使用します。このメトリックは、並列領域の実測された経過時間と理想化された経過時間 (スレッドのバランスが完璧で OpenMP* ランタイムのオーバーヘッドがゼロであると仮定) の差を予測します。このデータを使用して、並列実行を改善することで短縮できる最大時間を見積ることができます。
[サマリー] ウィンドウには、[潜在的なゲイン] メトリックの値が最も高い 5 つの並列領域が表示されます。#pragma omp parallel で定義された並列領域ごとに、このメトリックは並列領域のすべてのインスタンスの潜在的なゲインの合計を示します。
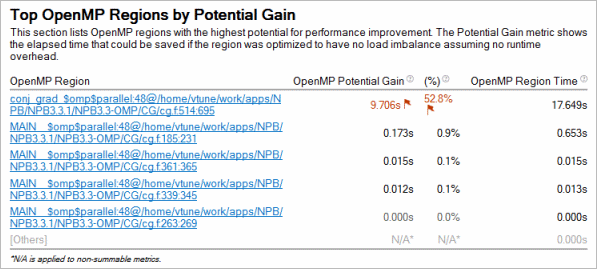
領域の潜在的なゲインが顕著である場合、領域名のリンクをクリックして [ボトムアップ] ウィンドウに移動し、バリアによるインバランスなどの非効率なメトリックの詳細な解析を示す [/OpenMP* 領域/OpenMP* バリアからバリアのセグメント/..] グループ化を使用して、さらに詳しく調査できます。
プロセス名のリンクをクリックすると、[/プロセス/OpenMP* 領域/..] でグループ化された [ボトムアップ] ウィンドウが表示されます。ここでは、MPI ランクの OpenMP* 非効率性に関する詳しい情報を取得できます。
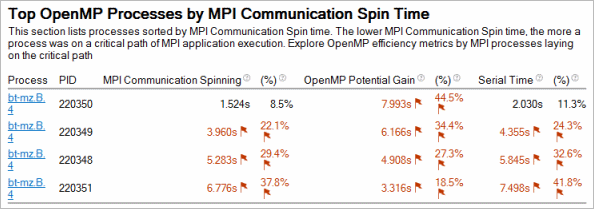
MPI 通信スピン時間による上位 OpenMP* プロセス
OpenMP* 領域を含む 1 プロセス以上の MPI 解析の結果では、[サマリー] ウィンドウに、プロセスごとに集約されたシリアル時間および OpenMP* 潜在的なゲインと MPI 実行のクリティカル・パス上の上位プロセスセクションが表示されます。
OpenMP* 領域の CPU 利用率分布図
操作 |
説明 |
|---|---|
[OpenMP* 領域] ドロップダウン・メニュー |
選択した OpenMP* 領域で分布データをフィルター処理します。[潜在的なゲイン] メトリックの値 (実行時のオーバーヘッドがゼロであると仮定し、ロード・インバランスがないように最適化された場合に期待できる最大経過時間 (収集時間 - アイドル時間)) でソートされたリストの上位から OpenMP* 解析を始めます。 |
垂直バー |
バーにカーソルを移動すると、[OpenMP* 領域] ドロップダウン・メニューから選択した OpenMP* 領域で、特定の CPU 数が同時実行されていた時間が表示されます。スピンとオーバーヘッド時間はアイドル CPU 利用率値に加算されます。 |
ターゲットの並行性 |
ターゲットの並行性レベルを特定します。この数は論理 CPU 数と等価です。この数値を最適化の目標とします。 |
平均 |
実行全体で並列に実行されている CPU の平均数を特定します。これは、CPU 時間/経過時間で計算できます。 この数値をパフォーマンス測定のベースラインとして使用します。CPU 時間がスピンに費やされる場合を除いて、この値をできるだけ論理 CPU 数 (ターゲットの並行性) に近づけます。 |
利用率表示バー |
それぞれの利用率レベルが、同時に実行される CPU にどのように割り当てられているか解析します。 |
OpenMP* 領域持続分布図
操作 |
説明 |
|---|---|
[OpenMP* 領域] ドロップダウン・メニュー |
OpenMP* 領域を選択すると、持続時間のインスタンス数の分布が表示されます。 |
インスタンス数 |
バーにカーソルを移動すると、アプリケーションが特定の持続時間で実行した OpenMP* 領域インスタンスの合計数が示されます。低速または高速領域が多いと、パフォーマンスのボトルネックが発生します。 |
持続期間タイプ (秒) |
スライドバーを使用して、開いている結果の持続時間のしきい値 (秒単位) を調整します。デフォルトの分布図では、最小領域時間と最大領域時間の間が 20/40/20 の比率で高速/良好/低速に分類されます。 |
収集とプラットフォーム情報
このセクションでは次のデータを提供します。
アプリケーションのコマンド行 |
ターゲット・アプリケーションへのパス。 |
オペレーティング・システム |
収集に使用されたオペレーティング・システム。 |
コンピューター名 |
収集に使用されたコンピューター名。 |
結果サイズ |
インテル® VTune™ プロファイラーで収集された結果のサイズ。 |
収集開始時間 |
外部収集の開始時間 (UTC 形式)。[タイムライン] ペインで、カスタムコレクターが提供するパフォーマンス統計を調査できます。 |
収集停止時間 |
外部収集の停止時間 (UTC 形式)。[タイムライン] ペインで、カスタムコレクターが提供するパフォーマンス統計を調査できます。 |
コレクタータイプ |
解析に使用されたデータコレクターのタイプ。次のタイプが利用できます。
|
CPU 情報 |
|
名前 |
収集に使用されたプロセッサー名。 |
周波数 |
収集に使用されたプロセッサーの周波数。 |
論理 CPU 数 |
収集に使用するマシンの論理 CPU 数。 |
物理コア数 |
システム上の物理コア数。 |
ユーザー名 |
データ収集を開始したユーザー。このフィールドは、製品のインストール時にユーザーごとのイベントベース・サンプリング収集モードを有効にすると利用できます。 |
GPU 情報 |
|
名前 |
システムに搭載されているグラフィックス名。 |
ベンダー |
GPU ベンダー。 |
ドライバー |
システムにインストールされているグラフィックス・ドライバーのバージョン。 |
ステッピング |
マイクロプロセッサーのバージョン。 |
EU カウント |
レンダーと GPGPU エンジンの最大実行ユニット (EU) 数。このデータは、インテル® HD グラフィックスおよびインテル® Iris® グラフィックス (以降、「インテル® グラフィックス」) 固有です。 |
最大 EU スレッドカウント |
実行ユニットごとの最大スレッド数。このデータはインテル® グラフィックス固有です。 |
最大コア周波数 |
グラフィックス・プロセッサーの最大周波数。このデータはインテル® グラフィックス固有です。 |
グラフィックス・パフォーマンス解析 |
GPU メトリック収集は、ハードウェア・レベルで有効になります。このデータはインテル® グラフィックス固有です。 注一部のシステムでは、L3 ミス、メモリーアクセス、サンプラービジー、SLM アクセスなどの拡張メトリックの収集は BIOS で無効にされています。システムによっては、BIOS オプションを設定してこの収集を有効にできます。オプションの有無およびオプション名は BIOS ベンダーによって異なります。BIOS でインテル® グラフィックス・パフォーマンス・アナライザーのオプション (または等価なオプション) を有効に設定します。 |