アプリケーションの異常検出解析を実行した後、結果を解釈します。注目するコード領域でパフォーマンスの異常を特定します。
異常検出解析の結果を解釈するには、異常検出ビューを使用します。一般的なワークフローでは、次の領域の調査が行われます。
データを表示
アプリケーションの異常検出の実行が完了すると、収集されたデータは [サマリー] ウィンドウに表示されます。
注目するコード領域の実行期間の分布図から開始します。これは、特定の期間または待機時間 (ミリ秒単位) のパフォーマンスが重要なタスクのインスタンス数を表示します。
以下を確認するため分布図を調査します。
注目するコード領域
シミュレーションが通常よりも早く、または遅く実行された領域の情報
この図は、低速な領域の予期しないパフォーマンスの異常値を特定します。

注
必要に応じて、X 軸のスライドバーで高速、良い、低速のレイテンシーのしきい値を調整します。低速な領域の負荷詳細
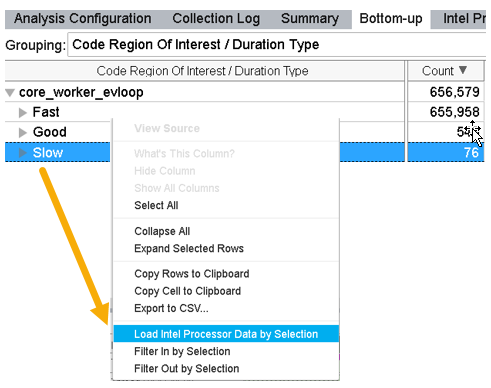
[ボトムアップ] ウィンドウで、注目する領域の低速なコードの負荷に関する詳細を確認できます。
[ボトムアップ] ウィンドウに切り替えます。
[注目する/存続期間タイプのコード領域] によるグループ化の結果。
低速な領域の異常値を詳しく調査するには、低速なフィールドを右クリックし、[選択してインテル® プロセッサーのデータをロード] を選択します。
これにより、[インテル® プロセッサー・トレース詳細] ウィンドウに、コード領域に関連する詳細がロードされます。
プロセッサー・トレースの詳細を比較
[インテル® プロセッサー・トレース詳細] ウィンドウでトレースデータをロードすると、マークされたコード領域のそれぞれのインスタンスのトレースを詳しく比較できます。スタックの上位は、カーネルのエントリーポイントを表します。
メトリック |
解釈 |
|---|---|
リタイアした命令、呼び出しカウント、反復数の合計 |
制御フローのメトリック。リタイアした命令は、カーネルへのエントリー数を表します。 |
CPU 時間 (カーネルとユーザー) |
CPU 上のアクティブ時間。 |
待機時間、インアクティブ時間 |
同期またはプリエンプションによりスレッドがアイドルであった期間。 |
経過時間 |
レイテンシー (コード領域の実行ウォールクロック時間)。 |
このウィンドウを中心にして、次のタイプのパフォーマンス異常を検出します。
コンテキスト・スイッチ異常
カーネルに起因する異常
周波数の低下
制御フロー偏差異常
コンテキスト・スイッチ異常
[インテル® プロセッサー・トレース詳細] ウィンドウで、インアクティブ時間と待機時間メトリクスを確認します。待機時間は、同期による問題でスレッドがアイドル状態であった時間を示します。
メトリックの値がゼロである場合、アプリケーションではコンテキスト・スイッチが発生しなかったことを意味します。次の異常検出の確認に進んでください。
メトリックがゼロでない場合、この手順を続行してコンテキスト・スイッチを確認します。
待機時間でデータをソートします。
待機時間が大きいインスタンスでは、待機時間と経過時間を比較します。スレドの経過時間のかなりの部分がアイドル状態である場合、問題の原因はコンテキスト・スイッチの同期によるものであると考えられます。この例では、thread 25883 は 1.318 ミリ秒の内 1.269 ミリ秒、つまり 96% の時間がアイドルであることを意味します。
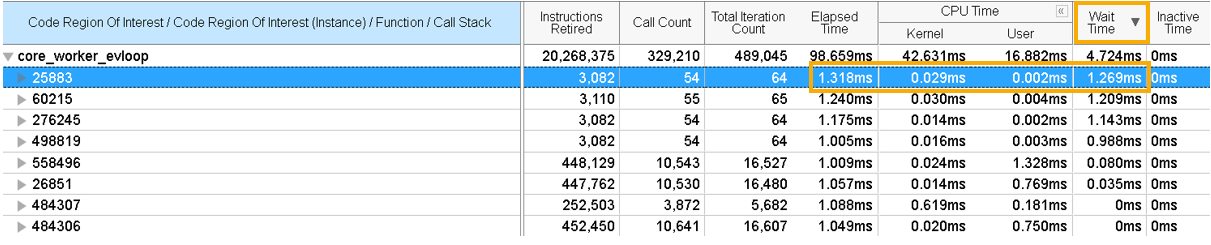
インスタンスを展開し、関数やスタックにドリルダウンできます。スレッドをアイドル状態にしたスタック (複数も可) を特定します。
カーネルに起因する異常
[インテル® プロセッサー・トレース詳細] ウィンドウで、カーネル時間でデータをソートします。スタックの最上位の要素は、カーネルへのエントリーポイントを指します。経過時間に対するカーネル時間の比率が高い場合、かなりの時間をカーネルが費やしたことを意味します。この例では、997 ミリ秒の内 566 ミリ秒がハイライトされたスレッド
 のカーネルで費やされました。
のカーネルで費やされました。スレッドを展開して、カーネル時間を長くしているスタックを見つけます。

カーネルやドライバーには動的に実行されるコードが含まれるため、バイナリーに対して静的な処理を行うことはできません。スタックの最上位にある kernel_activity ノードは、注目するコード領域の特定のインスタンスで発生したカーネル・アクティビティーにおけるすべてのパフォーマンス・データが集約されています。
カーネルバイナリーは処理されないため、インテル® VTune™ プロファイラーは、呼び出しカウント、反復カウント、またはリタイアした命令などのコードフローのメトリックを収集できません。これらのメトリックは、カーネルへのエントリー数を示すリタイアした命令を除き、すべてゼロです。
カーネルに起因する異常な症状として、ネットワーク速度の低下が考えられます。ネットワーク上で要求の受信や応答を送信する際に、制御がカーネルに移行することで速度が低下する場合があります。
周波数の低下
次のウィンドウのいずれかで、周波数の低下に関連する情報を検索します。
- [ボトムアップ] ウィンドウ: アプリケーション全体の周波数情報を表示します。
- [インテル® プロセッサーのトレース詳細] ウィンドウ: ロードした領域のみの周波数情報を表示します。
周波数低下の原因はいくつか考えられます。
ロードされたコード領域の内部または外部で、インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) 命令が実行されました。
冷却などハードウェアに問題に起因します。
アプリケーションとは別に、コアや OS のアクティビティーが少ない場合も周波数低下の原因となります。インアクティブ時間または待機時間の値が高いか確認します。
制御フロー偏差異常
一部のスレッドでリタイアした命令メトリックが予想外に大きい場合、制御フローの異常を示しています。コード領域で実行中のコードに偏差があることが考えられます。

グリッド内でリタイアした命令の値が高いノードを選択します。
右クリックして、[コンテキスト] メニューから [選択してフィルター処理] を選択します。
[呼び出し元/呼び出し先] ウィンドウに切り替えます。
![制御フロー逸脱の [呼び出し元/呼び出し先] ビュー](GUID-D5DA37C0-26E9-4430-AECF-0599FE1DA7CC-low.png)
[フラット・プロファイル] ビューでは、コメント付きのセルフと合計 CPU 時間を参照できます。[呼び出し元] ビューには、選択した関数の呼び出し元がボトムアップで表示されます。[呼び出し先] ビューには、選択された関数からのコールツリーがとトップダウンで表示されます。
この例では、_slab_evict_rand 関数から _slab_evict_one 関数の呼び出しにより、セルフ CPU 時間で分かるように大量の逸脱が発生しています。
これは、制御フローの逸脱を特定する代替手段です。
合計反復カウントを確認すると、高速反復と低速反復のループ反復回数を比較できます。
低速な反復回数が多い場合、[ソース/アセンブリー] ビューに切り替えて関数のソースコードを調査します。
低速な反復がキャッシュされた要素の評価にパスしたか確認します。
これらは両方ともまれにしか発生しませんが、キャッシュ・エビクション (キャッシュ追い出し) の発生を示します。キャッシュのエビクションは完全に排除することはできないかもしれませんが、次の方法で最小限にすることができます、
- キャッシュサイズを増やします。
- キャッシュデータを更新し、解析を繰り返します。