このウィンドウを使用して、インテル® VTune™ プロファイラーで GPU 解析を行い、高い GPU 利用率の GPU タスクを識別してこの利用率の効率を予測します。このビューは、GPU で計算ワークを実行する OpenCL*、SYCL* およびインテル® Media SDK アプリケーションの解析に役立ちます。
このウィンドウにアクセスするには、[GPU 計算/メディア・ホットスポット] ビューポイントを選択し、結果タブの [グラフィックス] サブタブをクリックします。
通常のボトムアップ解析とスタックデータに加えて、[グラフィックス] ウィンドウでは CPU/GPU のビジー状態を関連付けて、時間経過における GPU メトリックの分布を表示します。
![[グラフィックス] タブ](GUID-26BCFFCC-2161-4405-ACC7-BD9C2CD0C371-low.png)
|
グリッド。プログラム単位の基本パフォーマンス・メトリックを解析して、最も時間を消費するユニットを特定します。アプリケーションが OpenCL* ソフトウェア・テクノロジーを使用し、[GPU プログラミング API をトレース] オプションを有効にして解析すると、oグリッドはデフォルトで [計算タスクの目的] 粒度でグループ化されます。 最初に、実行時間が最も長いホットなカーネルを解析し最適化します。これらは、平均実行時間が長い、あるいは平均実行時間は短くても頻繁に呼び出される (インスタンスのカウント値を参照) といった特徴のカーネルを含みます。どちらの場合も注目すべきです。詳細は、GPU OpenCL* アプリケーション解析を参照してください。 GPU 実行ユニットがアイドル状態、キューに入れられている状態、またはコードを実行中のビジー状態のときの CPU アクティビティー (実行されたモジュール/関数とその CPU 時間) を理解するには、[GPU レンダーと EU エンジンストール状態] グループレベルを使用します。 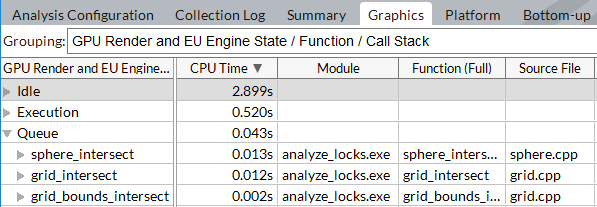 |
|
スレッド。特定のスレッドの CPU と GPU 利用率を調査します。[プラットフォーム] タブには、スレッド関数が含まれるモジュール名としてスレッド名が表示されます。例えば、myFoo 関数が、MyMegaFoo (Linux*) または MyMegaFoo.dll (Windows*) 関数に属する場合、スレッド名は MyMegaFoo (Linux*) または MyMegaFoo.dll (Windows*) と表示されます。この手法は、タイムライン上に表示されるワークを生成するスレッドコードの場所を特定するのに役立ちます。 Windows* ターゲットのみ: CPU と GPU の使用状況を関連付け、アプリケーションが GPU に依存しているか判断します。GPU エンジン利用率バーは、GPU タスクに起因する CPU スレッド上の DMA パケットを表示します。このバーは、GPU エンジンのタイプによって色分けされます (上記の例の黄色のバーはレンダーと GPGPU に対応します)。 |
|
GPU ハードウェア・メトリック。インテル® HD グラフィックスおよびインテル® Iris® グラフィックスを搭載したプロセッサーの GPU 解析で [プロセッサー・グラフィックス・ハードウェア・イベントを解析] オプションを有効にすると、インテル® VTune™ プロファイラーは選択したメトリックグループの統計を表示します。 例えば、デフォルトの概要メトリックのグループでは、GPU 実行ユニットから開始します。[EU アレイアイドル] メトリック。アイドルサイクルは無駄なサイクルです。スケジュールされているスレッドがなく、EU の貴重な計算リソースが活用されません。EU アレイアイドルがゼロの場合、GPU は効率良く活用されており、すべての EU にスレッドがスケジュールされています。 ほとんどの場合、最適化では [EU アレイストール] メトリックを最小にし、[EU アレイアクティブ] を最大にします。ただし、メモリー帯域幅に制約されるアルゴリズムは例外です。この場合、([EU アレイアクティブ] を最大にするのではなく) メモリー帯域幅を特定のプラットフォームのピークに近づけるように最適化します。 メモリーアクセスは、しばしばストールの原因になります。メモリーレイアウトと注意深く設計されたメモリーアクセスの重要性を軽視することはできません。[EU アレイストール] がゼロでなく [GPU L3 ミス] に関連しており、アルゴリズムがメモリー帯域幅に制限されていない場合は、メモリーアクセスとレイアウトの最適化を試してみるべきです。 サンプラーアクセスはコストが高く、容易にストールを引き起こします。サンプラーアクセスは、[サンプラーがボトルネック] と [サンプラービジー] メトリックによって測定できます。 注インテル® グラフィックスのハードウェア・イベントを解析するには、GPU 解析のシステム設定が適切であることを確認してください。 |
|
計算キュー: OpenCL* カーネル・サブミッションの詳細では、サブミッションと実行の順序に注目し、キューで費やされた時間を特定して、計算キューのデータにズームして解析します。インテル® VTune™ プロファイラーは、同じ名前とグローバル/ローカルサイズのカーネルを同色で表示します。同期タスクは、影付きの垂直線 カーネルタスクをクリックすると、上位レイヤーに表示された実行に対応するキュー全体がハイライトされます。カーネルの実行パラメーターを見るには、キューのオブジェクトにカーソルを移動します。 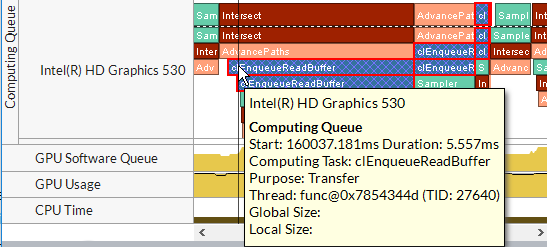 Windows* ターゲットのみ: [プラットフォーム] ウィンドウに切り替えて、OpenCL* デバイスキューの実行パスが DMA パケット・ソフトウェア・キューとどのように関連するか調査します。 |
|
GPU 使用メトリック: GPU 使用率バーは、使用されている GPU エンジンのタイプに応じて色分けされます。 [プラットフォーム] タブが、GPU がほとんどビジーであり、ビジー間隔のアイドル時間が非常に短く、GPU ソフトウェアのキューがほとんどゼロにならないことを示す場合、理論的にはアプリケーションは GPU に依存しています。ビジー間隔のアイドル時間が長く、その間 CPU がビジーとなる場合、アプリケーションは CPU 依存であると言えます。しかし、このような明確な状況はまれであるため、詳細を解析してすべての依存関係を明らかにする必要があります。例えば、GPU エンジンがシリアル化されている場合 (GPU エンジンがビデオ処理とレンダリング処理を交互に実行するなど)、誤って GPU 依存と見なしてしまう可能性があります。このケースでは、CPU で実行されるアプリケーションが原因で GPU 上で非効率なスケジューリングが生じています。 |




 で表示されます。データ転送は、斜め格子
で表示されます。データ転送は、斜め格子  で表示されます。
で表示されます。
さらに OpenCL* カーネル解析を行うには、注目する計算タスク (例えば、AdvancedPaths) を選択して、[アーキテクチャー分布図] に切り替えます。インテル® VTune™ プロファイラーは、選択されたカーネルが実行された時間範囲の GPU ハードウェア・メトリックごとのパフォーマンス・データを表示します。
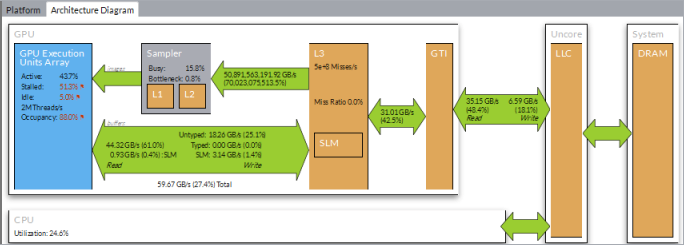
フラグ付き値にはパフォーマンスの問題があります。この例では、GPU 時間の約 50% がストールしています。これは、メモリーやサンプラーのアクセスによりパフォーマンスが制限されていることを意味します。