インテル® VTune™ プロファイラーの GPU 計算/メディア・ホットスポット・ビューポイントを使用して、GPU 依存のコードが GPU と CPU リソースをどのように利用しているか解析します。
GPU 計算/メディア・ホットスポット解析で選択したプロファイル・モードに応じて、GPU 上のコードのパフォーマンスをさまざまな観点から調査できます。
特性化モード解析を実行して、GPU にオフロードされたコードのパフォーマンスの問題を確認します。
GPU ハードウェア・イベントを使用して、メモリーアクセスと XVE パイプラインの利用率を解析します。
ソース解析モードで解析を実行し、最も負荷の高い操作を特定して、命令の実行を調査します。
- Xe ベクトルエンジン (XVE) のストールを解析
- GPU の電力消費量を調査
メモリーアクセスと XVE パイプラインの利用率
特性化モードを使用して、GPU にバインドされたアプリケーションの解析を開始します。このモードは、GPU 計算/メディア・ホットスポット解析の構成ではデフォルトで有効になっています。
[サマリー] ウィンドウの [最もホットな GPU 計算タスク] セクションには、最も時間のかかる GPU タスクが表示されます。
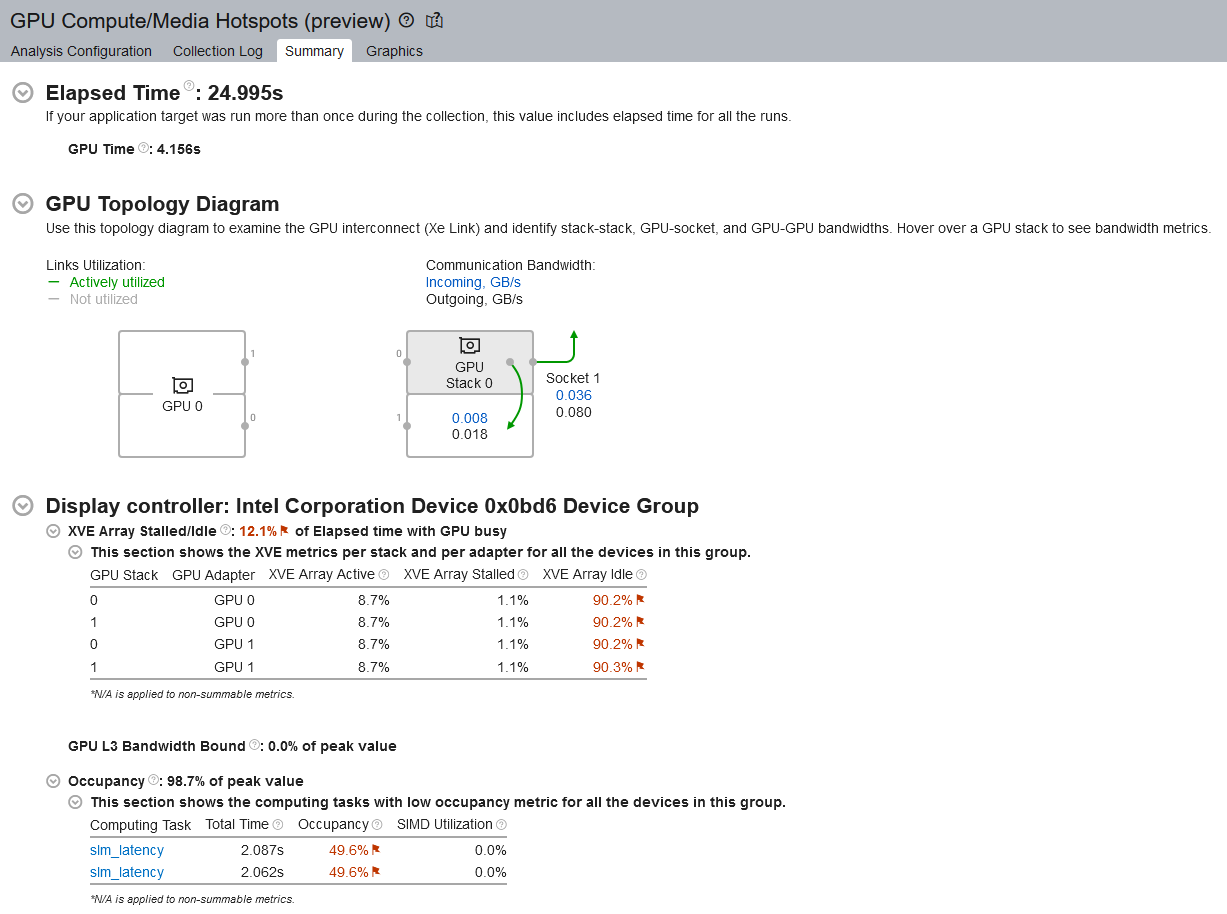
表示されるタスクをクリックして、[グラフィックス] タブを切り替えて、ホットスポットで収集された GPU ハードウェア・メトリックの詳細を確認します。デフォルトでは、これはメトリックの概要セットです。
次の図は、インテル® データセンター GPU マックスシリーズ (開発コード名 Ponte Vecchio) で GPU 解析を実行した、フル・コンピューティング解析の例です。解析の構成とハードウェアの選択に応じて、結果は異なることがあります。
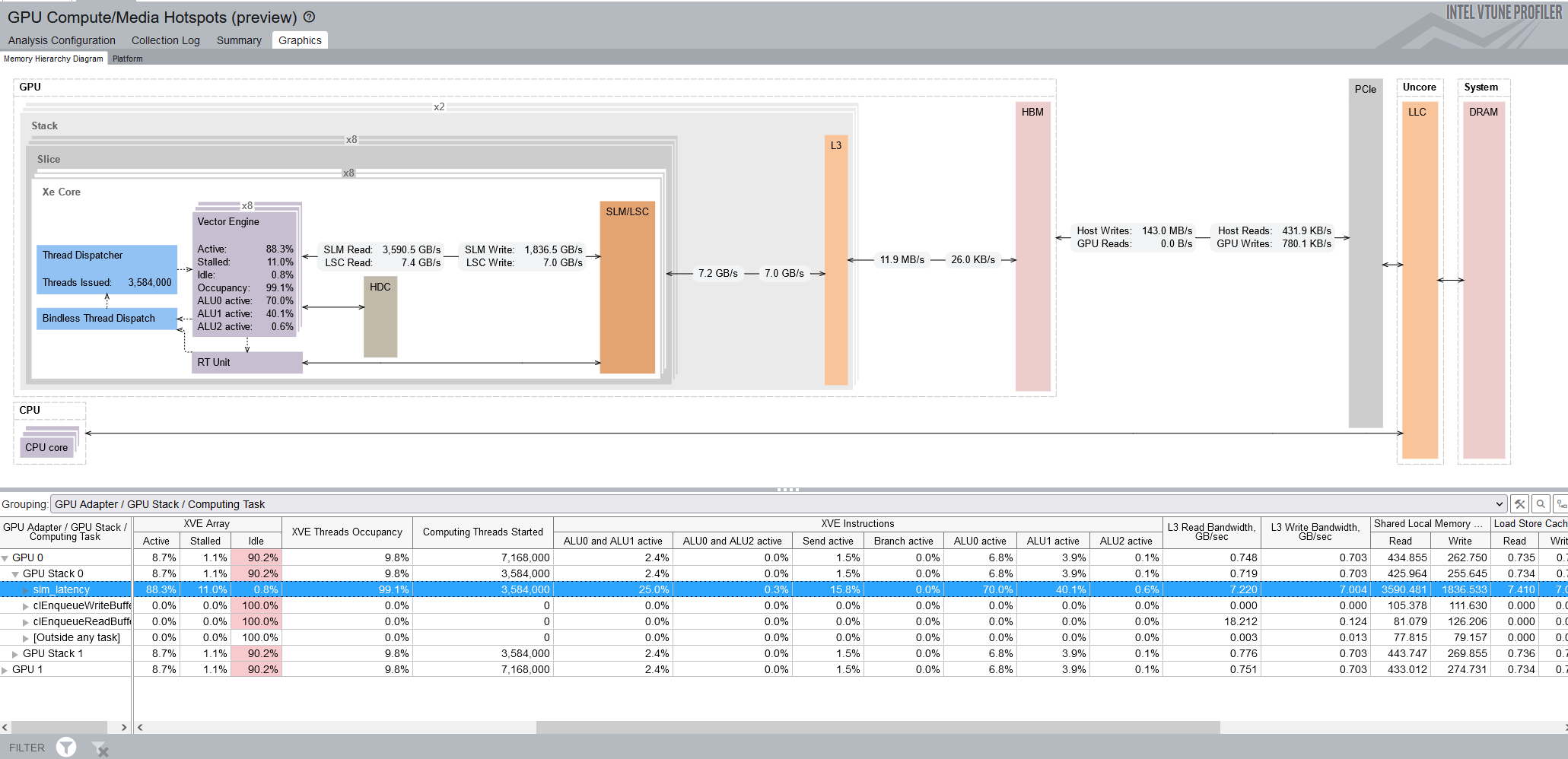
メモリー階層図には、下の表で選択したタスクにマップされている GPU ハードウェア・メトリックが表示されます。図は動的に更新され、選択されたテーブル内のメトリックが反映されます。
メモリー階層図を右クリックし、[データ表示形式] を開いて表示を変更します。
- デフォルト表示は帯域幅です。これはメモリー帯域幅を示します。
- [合計サイズ] ビューは、計算タスクを通じて発生するデータ転送量を把握している場合に役立ちます。この数値が著しく大きい場合は非効率であることを示しています。
- [帯域幅の最大値パーセント] ビューで、いずれかのリンクによる最大帯域幅によってカーネルが制限されているかどうかを確認します。
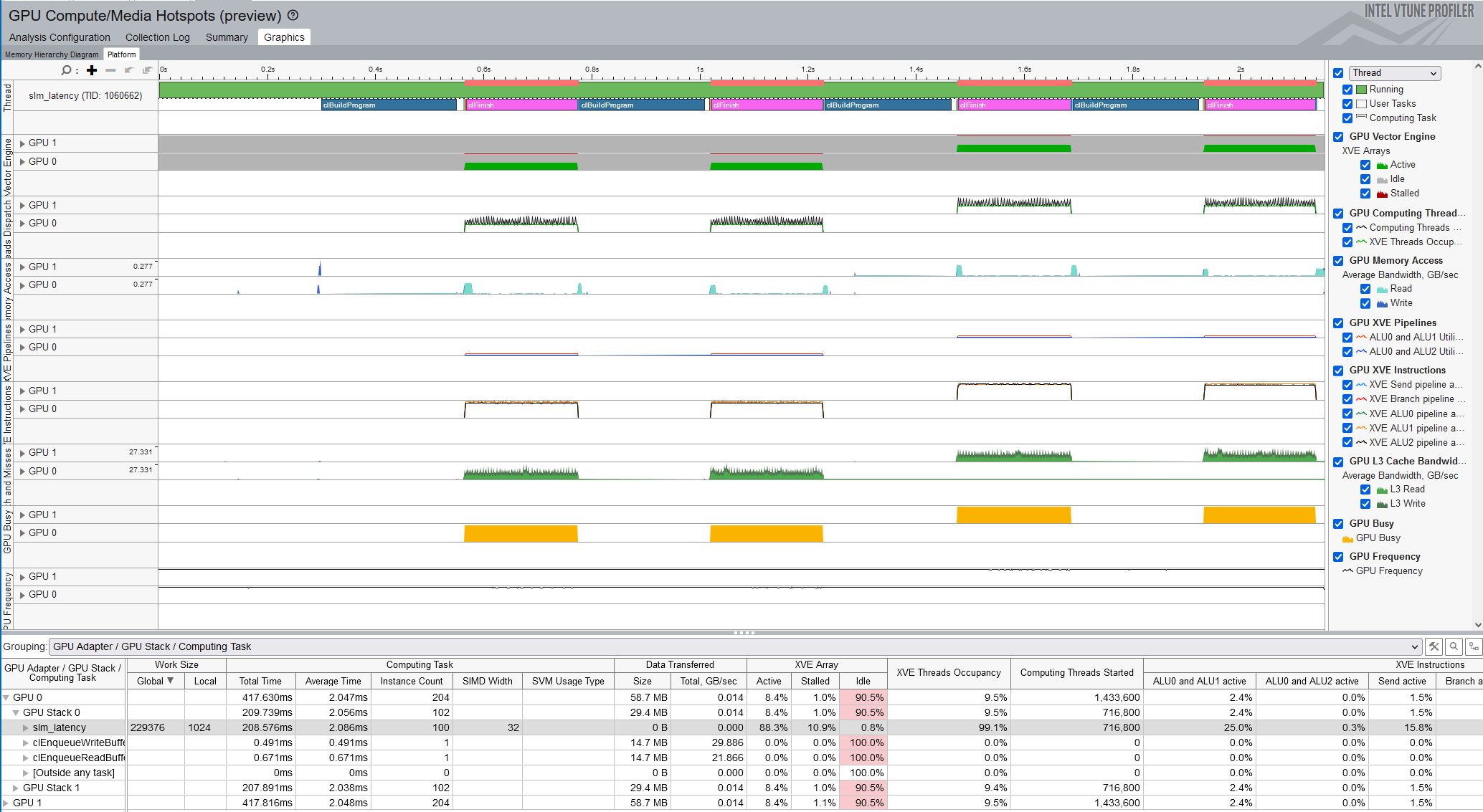
[プラットフォーム] タブには、時間の経過に伴う次のビューが表示されます。
- CPU スレッド
- アプリケーションによって呼び出される計算ランタイム API
- GPU 計算タスク
- GPU ハードウェア・メトリック
この視覚的な表示を使用して、不規則性を識別します。
GPU 命令実行を解析
[特性化] 解析設定の [動的命令カウント] プリセットを有効にした場合、[グラフィックス] タブには、次のグループのカーネルで実行された命令の分類が表示されます。

[制御フロー] グループ |
if、else、endif、while、break、cont、call、calla、ret、goto、jmpi、brd、brc、join、halt および mov、add ip レジスターを明示的に変更する命令。 |
送信グループ |
send、sends、sendc、sendsc、wait |
同期グループ |
wait |
Int16 & HP Float | Int32 & SP Float | Int64 & DP Float グループ |
ビット操作 (整数型のみ):and、or、xor など。 算術演算:mul、sub など。avg、frc、mac、mach、mad、madm。 ベクトル算術演算:line、dp2、dp4 など。 拡張算術演算:math.sin、math.cos、math.sqrt など。 |
[その他] グループ |
nop を含むほかのすべての操作。 |
注
操作 (演算) のタイプはデスティネーション・オペランドのタイプにより決定されます。
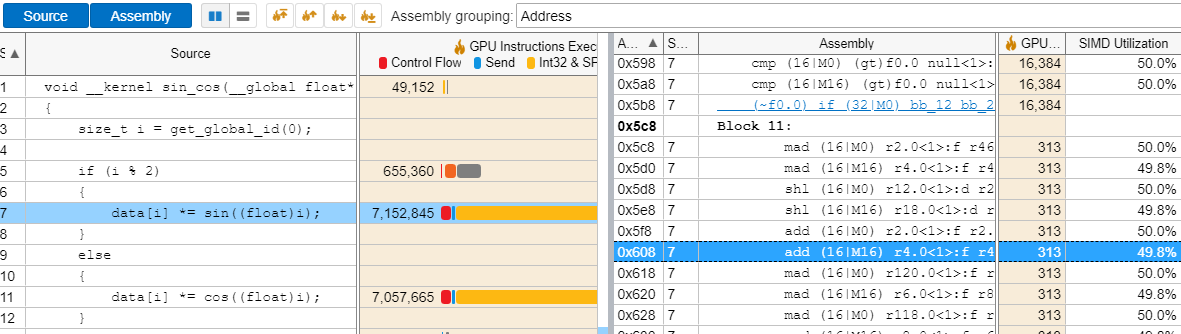
[グラフィックス] タブには、SIMD 利用率メトリックも示されます。このメトリックは、スレッドの発散を引き起こす命令により、GPU を十分に活用できないカーネルを特定するのに役立ちます。スレッドがすべての実行パスを逐次実行し、他のスレッドがストールしている間にそれぞれのスレッドが 1 つのパスを実行するため、SIMD 利用率が低くなる原因としてカーネル内の条件分岐が上げられます。
追加の情報を得るには、注目する関数をダブルクリックして、[ソースビュー] を開きます。[ソース] と [アセンブリー] ペインの両方を有効にすると、ソースコードとアセンブリー・コードを並べて表示できます。SIMD 利用率の値が低いアセンブリー命令を特定し、命令をクリックすると対応するソースコード行に対応付けることができます。これにより、目的とする SIMD 利用率の基準を満たさないカーネルを検出して最適化できます。
注
インテル® Iris® Xe MAX グラフィックスの命令セット・アーキテクチャー (ISA) については、「インテル® Iris® Xe MAX グラフィックス・オープンソース・プログラマー・リファレンス・マニュアル」(英語) を参照してください。ソース解析
[GPU 計算/メディア・ホットスポット解析] で、[ソース解析] モードを選択すると、基本ブロックのレイテンシーまたはメモリー・レイテンシーの問題について対象とするカーネルを解析できます。これには、[グラフィックス] タブでカーネルノードを展開して関数名をダブルクリックします。インテル® VTune™ プロファイラーは、選択された関数の最もホットなソース行にジャンプします。
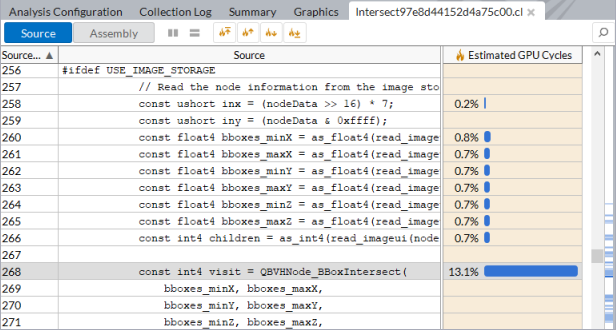
GPU 計算/メディア・ホットスポットは、カーネルソースのコード行ごとの完全な解析を可能にします。最もホットなカーネルコード行がデフォルトでハイライト表示されます。
カーネル・インスタンスごとに実行された GPU 命令のパフォーマンス統計を表示するには、[アセンブリー] ビューに切り替えます。
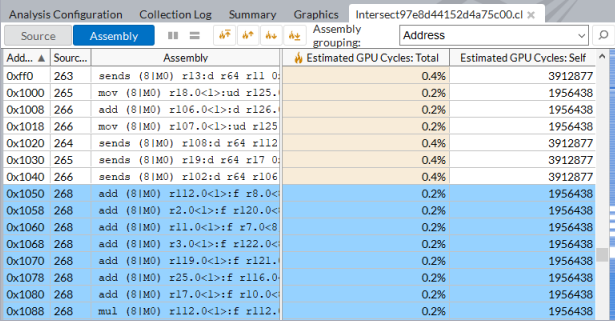
注
OpenCL* カーネルがインライン関数を使用している場合、関数ごとの GPU サイクルが正確に分類されるように、[フィルター] ツールバーの [インラインモード] が有効になっていることを確認してください。例を参照。
例: 基本ブロック・レイテンシープロファイル
計算操作を行う OpenCL* カーネルをプロファイルします。
__kernel void viete_formula_comp(__global float* data) { int gid = get_global_id(0); float c = 0, sum = 0; for (unsigned i = 0; i < 50; ++i) { float t = 0; float p = (i % 2 ? -1 : 1); p /= i*2 + 1; p /= pown(3.f, i); p -=c; t = sum + p; c = (t - sum) - p; sum = t; } data[gid] = sum * sqrt(12.f); }これらの操作を比較するため、基本ブロック・レイテンシー・モードで GPU In-kernel プロファイルを実行し、グリッドでカーネルをダブルクリックしてソースビューを開きます。
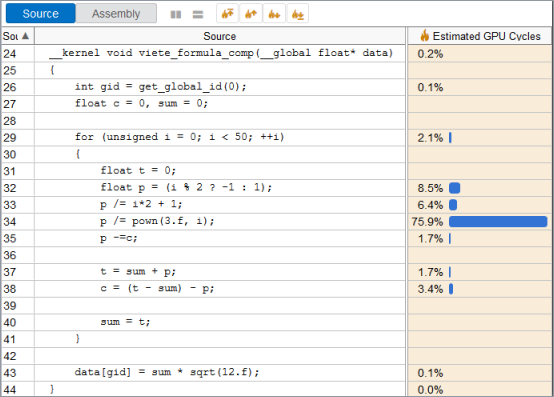
ソースビュー解析では、pown()呼び出しがこのカーネルで最もコストのかかる操作としてハイライトされています。
例: メモリー・レイテンシー・プロファイル
数回 (14、15 および 20 行目で) メモリーリードを行う OpenCL* カーネルをプロファイルします。
__kernel void viete_formula_mem(__global float* data) {
int gid = get_global_id(0);
float c = 0;
for (unsigned i = 0; i < 50; ++i) {
float t = 0;
float p = (i % 2 ? -1 : 1);
p /= i*2 + 1;
p /= pown(3.f, i);
p -=c;
t = data[gid] + p;
c = (t - data[gid]) - p;
data[gid] = t;
}
data[gid] *= sqrt(12.f);
}最も時間が長いリード命令を特定するため、メモリー・レイテンシー・モードで GPU In-kernel プロファイルを実行します。
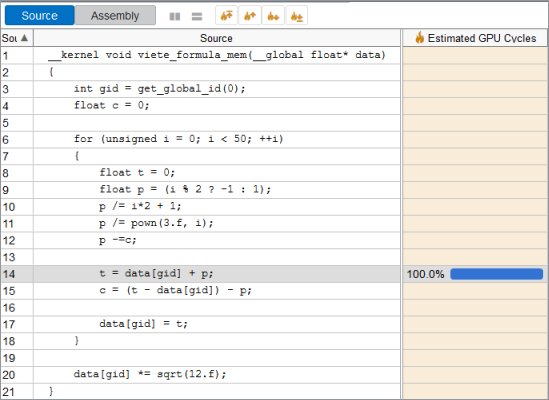
ソースビュー解析は、各スレッドが入力バッファーのそれぞれの要素のみを利用することをコンパイラーが理解して、リードを行うコードを一度だけ生成していることを示しています。入力バッファーの値はレジストリーに格納されてほかの操作で再利用されるため、コンパイラーは追加のリード命令を生成しません。
XVE ストールの解析
GPU が十分に活用されていない場合、Xe ベクトルエンジン (XVE) に関するガイドを参照して、GPU スタックのストールやアイドルの原因を理解します。
注
GPU 計算/メディア・ホットスポット解析の結果に XVE ストールの原因が含まれるのは、インテル® データセンター GPU マックスシリーズ (コード名 Ponte Vecchio) のみです。最初に、特性化モードで GPU 計算/メディア・ホットスポット解析タイプを実行しますこのモードで [概要] オプションを選択します。
解析が完了したら、ビューポイントの [サマリー] タブを確認します。XVE アレイのストール/アイドルの表には、プロファイルが行われたときにストール (計算タスクを受信したが実行しなかった) 状態、またはアイドル (計算タスクを受信しなかった) 状態の Xe ベクトルエンジン (XVE) のリストが示されます。どちらの場合も改善の余地があり、利用可能なハードウェアをより有効に活用できる可能性があります。
[XVE アレイストール] メトリックの値が高い GPU スタックの次のステップは、ソース解析モードで GPU 計算/メディア・ホットスポット解析を実行することです。
ソース解析モードでは、解析を繰り返す前に [ストールの原因] オプションを選択します。
解析が完了したら、最もホットな GPU 計算タスクの表を参照してください。ここでは、最も利用頻度が高い関数のリストが合計時間に表示されます。
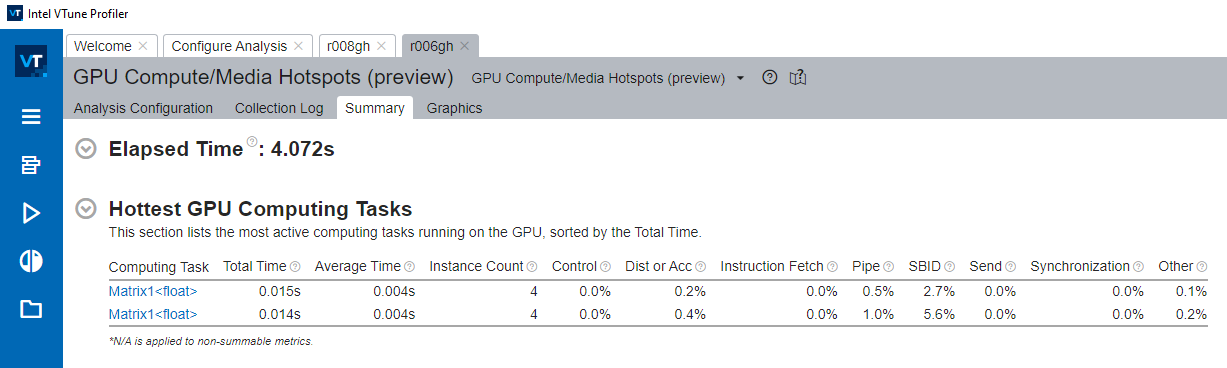
XVE ストールの原因となった計算タスクでは、ストールの原因となった理由を知ることができます。
関数をクリックして [グラフィックス] ビューに切り替えると、ストール数の分布図が表示されます。計算タスクのストールを検出するには、[グラフィックス] ビューで計算タスク/関数グループを選択する必要があります。

Xe ベクトルエンジン (XVE) がストールする原因はいくつか考えられます。次の表はこれらの原因を説明しています。
| XVE ストールの原因 | 説明 |
|---|---|
| アクティブ | 少なくても 1 つの命令がパイプラインにディスパッチされています。 |
| コントロール | 命令が分岐ユニットが利用可能になるのを待機したストールのパーセンテージ。 |
| DIST または ACC | 命令がデスティネーションまたはアーキテクチャー・レジスター・ファイル (ARF) の依存関係が解決されるのを待機するストールのパーセンテージ。 |
| 命令フェッチ | XVE が命令キャッシュから命令が返されるのを待機した時のストールのパーセンテージ。 |
| パイプ | 命令が調停され、浮動小数点または拡張演算ユニットにディスパッチできなかった場合のストールのパーセンテージ。これは、バンク競合と汎用レジスターファイル (GRF) の競合によって発生する場合があります。 |
| SBID | 命令がソフトウェア・スコアボードの依存関係が解決されるのを待機したストールのパーセンテージ。 |
| 送信 | 命令が送信ユニットが利用可能になるのを待機したストールのパーセンテージ。 |
| 同期 | 命令がスレッド同期の依存関係が解決されるのを待機したストールのパーセンテージ。 |
| その他 | その他の要因によって命令の実行が停止したときのストールのパーセンテージ。 |
GPU の電力消費量を調査
Linux* 環境で、ディスクリートのインテル® Iris® Xe MAX グラフィックス GPU で、GPU 計算/メディア・ホットスポット解析を実行すると、GPU デバイスで消費されるエネルギーに関連する情報を確認できます。この情報を収集するには、[解析の設定] で [電力使用を解析] オプションをオンにしてください。
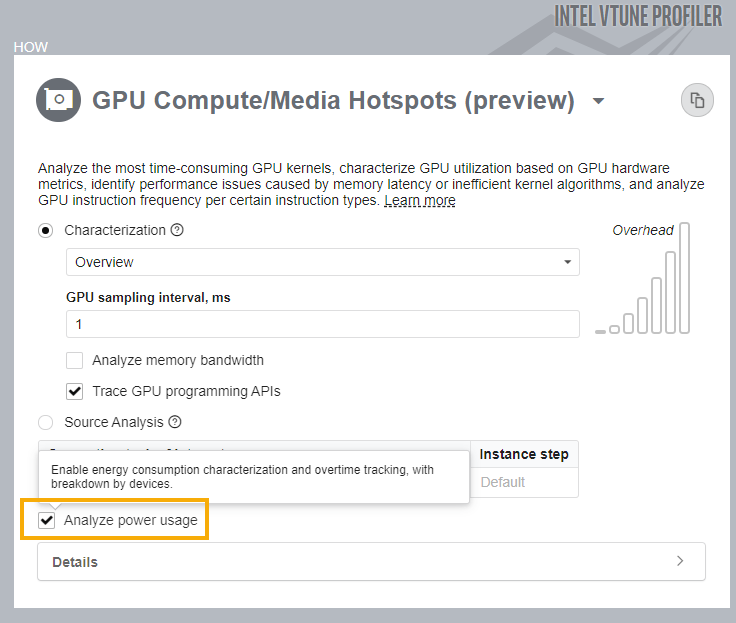
解析が完了したら、結果に示されるこれらの電力消費データを参照してください。
[グラフィックス] ウィンドウで、計算タスクごとにグループ化されたグリッドの [電力消費] カラムを確認します。このカラムをソートして、最も電力を消費した GPU カーネルを特定します。この情報は、タイムラインにもマッピングされていることを確認できます。
最も電力を消費する GPU カーネルを検出するには、適切な電力効率を得るため、上位のエネルギー・ホットスポットをチューニングすることから開始します。
GPU 処理時間も最適化を目的とする場合、カーネルごとの電力消費メトリックを確認して、パフォーマンス時間と電力使用量のトレードオフを観察します。
この比較を容易にするため、[合計時間] の隣にある [電飾消費] カラムに移動します。
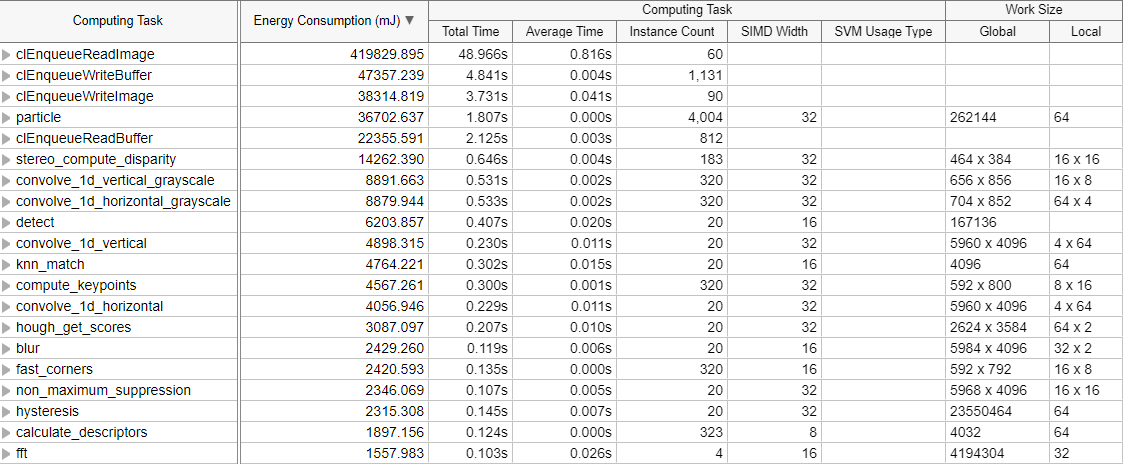
電力使用量と処理時間には直接的な相互関係はないことに気づくかもしれません。最も高速に計算を行うカーネルは、エネルギー消費量が最小であるカーネルとは異なる場合があります。電力使用量の値が大きいほど、ストール/待機期間が長いかどうかを確認します。