アシスト
メトリックの説明
このメトリックは、アシストの結果マイクロコード・シーケンサーによって供給され、CPU でリタイアした uOps のサイクル数を予測します。アシストは、実行パイプラインで直接実行できない操作に対して、特定の用途で必要とされる長い uOps のシーケンスです。例えば、非常に小さな浮動小数点値を操作する場合 (デノーマルと呼ばれます)、FP ユニットはこの操作をネイティブで行うことができません。代わりに、デノーマル値の計算を行う命令のシーケンスが、パイプラインに投入されます。これらのマイクロコード・シーケンスは数百の命令で構成されるため、マイクロコード・アシストはパフォーマンス上有害です。
考えられる問題
実行時間の大部分がマイクロコード・アシストで費やされています。
ヒント:
1.特定の原因を知るには、FP_ASSIST と OTHER_ASSISTS イベントを調査します。
2.87 コードの生成を排除するオプションを追加し、DAZ (denormals-are-zero) と FTZ (flush-to-zero) を有効にするコンパイラー・オプションを有効にします。
利用可能なコア時間
メトリックの説明
すべてのコアの合計実行時間を示します。
平均帯域幅
メトリックの説明
解析中に利用された平均帯域幅を示します。
平均 CPU 周波数
メトリックの説明
実際の平均 CPU 周波数を示します。定格周波数を超える値は、CPU がターボブースト・モードで動作していることを示します。
平均 CPU 利用率
メトリックの説明
アプリケーションの計算による平均 CPU 利用率を示します。スピンとオーバーヘッド時間はカウントされません。理想的な平均 CPU 利用率は、論理 CPU コア数と等価です。
平均フレーム時間
メトリックの説明
フレーム内で費やされた合計時間を示します。
平均レイテンシー (サイクル)
メトリックの説明
このメトリックはロードの平均レイテンシーをサイクル単位で示します。
平均論理コア利用率
メトリックの説明
このメトリックは、アプリケーションの計算による平均論理コア利用率を示します。スピンとオーバーヘッド時間はカウントされません。理想的な平均 CPU 利用率は、論理 CPU コア数と等価です。
平均物理コア利用率
メトリックの説明
このメトリックは、アプリケーションの計算による平均物理コア利用率を示します。スピンとオーバーヘッド時間はカウントされません。理想的な平均 CPU 利用率は、物理 CPU コア数と等価です。
平均 Task 時間
メトリックの説明
タスク内で費やされた平均時間を示します。
バックエンド依存
メトリックの説明
バックエンド依存のメトリックは、バックエンドで新しい uOps を受け入れるリソースが不足しているため、uOps が転送されないパイプライン・スロットの比率を表します。バックエンドはプロセッサー・コアの一部であり、準備が整った uOps をアウトオブオーダー・スケジューラーが対応する実行ユニットにディスパッチし、操作が完了すると、uOps はプログラムの順番でリタイアしていきます。例えば、データキャッシュ・ミスによるストールや、除算器のオーバーロードによるストールは、どちらもバックエンド依存に分類されます。バックエンド依存はさらにの 2 つのカテゴリーに分けられます。メモリー依存とコア依存。
考えられる問題
パイプライン・スロットの大部分が空です。バックエンドで操作に長い時間を要すると、パイプラインにバブルが生じて、マシンがサポートするよりも、サイクルごとにリタイアされる有用なワークを含むスロットが少なくなります。その結果実行が遅くなります。除算やメモリー操作など長いレイテンシーの操作は、単一の実行ポートに多くの操作が送られる可能性 (例えば、実行ユニットがサイクルあたりにサポートできるよりも、多くの乗算操作がバックエンドに割り当てられる場合) があるため、この原因となります。
メモリー帯域幅
メトリックの説明
このメトリックは、メインメモリー (DRAM) の帯域幅の限界に近づいたため、アプリケーションがストールする可能性があるサイクル数の割合を示します。このメトリックは、ほかのスレッド/コア/ソケットからの要求を収集しません (それらについては、アンコアカウンターを参照)。NUMA マルチソケット・システムのデータの局所性を改善してください。
競合アクセス (タイル内)
メトリックの説明
競合アクセスは、あるスレッドによって書き込まれたデータが別のコアのスレッドによって読み取られる場合に発生します。競合アクセスには、ロックなどの同期、ロック変数の変更などの真のデータ共有、フォルス・シェアリングがあります。競合アクセスメトリックは、すべての要求ロードとストアに対する競合アクセス数の比率です。このメトリックは、同じタイル上の 2 つのコア間の競合アクセスのみをカウントします。
考えられる問題
別のコアで更新されたキャッシュラインに対する多数の競合アクセスがあります。長いレイテンシーのロードイベント (例えば LLC ミス) の説明で提案される手法を導入するか、競合するアクセスを減らすことを検討してください。競合アクセスを減らすには、まずその原因を特定します。同期が原因であれば、同期の粒度を増やすことを考えてください。真のデータ共有であれば、データのプライベート化とリダクションを検討してください。データのフォルス・シェアリングが発生している場合は、変数を異なるキャッシュラインに配置するようにデータを再構築してください。パディングによってワーキングセットが増加するかもしれませんが、確実にフォルス・シェアリングを排除することができます。
LLC ミス
メトリックの説明
LLC (最終レベルキャッシュ) は、メインメモリー (DRAM) の手前にある、メモリー階層の最後の、そして最も長いレイテンシーのレベルです。すべての LLC メモリー要求ミスは、レイテンシーの長いローカルまたはリモート DRAM によって処理されます。LLC ミスメトリックは、すべてのサイクルに対する LLC ミスが未処理のサイクルの比率です。
考えられる問題
LLC ロードミスが処理されるのを待機するため、高い CPU サイクル数が費やされます。適用可能な最適化は、データのワーキングセットを縮小し、データアクセスの局所性を向上させ、LLC に収まるようにデータをブロック化してチャンク単位で参照し、ハードウェア・プリフェッチャーを効率的に活用することです。ソフトウェア・プリフェッチャーの使用を検討してください。ただし、通常のロードを妨げてレイテンシーの増加を招いたり、メモリーシステムへの負担が増える可能性があることに注意してください。
UTLB オーバーヘッド
メトリックの説明
このメトリックは、第 1 レベルのデータ TLB (または UTLB) ミスを処理するのに費やされたサイクルの割合を示します。通常のデータキャッシュと同様に、UTLB のオーバーヘッドを減らすため、データの局所性を改善し、ワーキングセットのサイズを抑えることに注目します。さらに、プロファイルに基づく最適化 (PGO) を使用して、頻繁に使用されるデータを同じページに配置します。頻繁に使用される大量のデータには、大きなページサイズを検討します。このメトリックには、ストア TLB ミスは含まれません。
考えられる問題
かなりのサイクルが第 1 レベルデータ TLB ミスの処理に費やされています。通常のデータキャッシュと同様に、UTLB のオーバーヘッドを減らすため、データの局所性を改善し、ワーキングセットのサイズを抑えることに注目します。さらに、プロファイルに基づく最適化 (PGO) を使用して、頻繁に使用されるデータを同じページに配置します。頻繁に使用される大量のデータには、大きなページサイズを検討します。
ポート利用率
メトリックの説明
このメトリックは、除算器に関連しないコアの問題により、アプリケーションがストールしたサイクル数の割合を示します。そのような問題の例として、近接する命令間のデータ依存関係が多い、または特定のポートに負荷をかける命令シーケンスなどがあります。ヒントループのベクトル化 - 最近のコンパイラーは自動ベクトル化機能を備えています - 複数の要素が同じ uOp で計算されるため実行ポートへの負荷を軽減します。
考えられる問題
除算器に関連しないコアの問題により、かなりのサイクルがストールしています。
ヒント
ベクトル化により、複数の要素が同じ uOp で計算されるため、実行ポートへの負荷が軽減されます。
ポート 0
メトリックの説明
このメトリックは、実行ポート 0 (SNB+: ALU; HSW+:ALU および 2 番目の分岐) で CPU がディスパッチした uOps のコアサイクルの割合を示します。
ポート 1
メトリックの説明
このメトリックは、実行ポート 1 (ALU) で CPU がディスパッチした uOps のコアサイクルの割合を示します。
ポート 2
メトリックの説明
このメトリックは、実行ポート 2 (ロードとストアアドレス) で CPU がディスパッチした uOps のコアサイクルの割合を示します。
ポート 3
メトリックの説明
このメトリックは、実行ポート 3 (ロードとストアアドレス) で CPU がディスパッチした uOps のコアサイクルの割合を示します。
ポート 4
メトリックの説明
このメトリックは、実行ポート 4 (ストアデータ) で CPU がディスパッチした uOps のコアサイクルの割合を示します。
考えられる問題
このメトリックは、実行ポート 4 (ストアデータ) で CPU がディスパッチした uOps のコアサイクルの割合を示します。このメトリック値は、分割ストアの問題によりハイライトされる可能性があることに注意してください。
ポート 5
メトリックの説明
このメトリックは、実行ポート 5 (SNB+: 分岐と ALU; HSW+: ALU ) で CPU がディスパッチした uOps のコアサイクルの割合を示します。
ポート 6
メトリックの説明
このメトリックは、実行ポート 6 (分岐と単純な ALU) で CPU がディスパッチした uOps のコアサイクルの割合を示します。
ポート 7
メトリックの説明
このメトリックは、実行ポート 7 (単純なストアアドレス) で CPU がディスパッチした uOps のコアサイクルの割合を示します。
BACLEARS
メトリックの説明
このメトリックは、ブランチ・ターゲット・バッファー (BTB) による予測を、以降の分岐予測器が補正するために失われたサイクルの割合を予測します。
考えられる問題
分岐ターゲットバッファー (BTB) による予測が、以降の分岐予測器で補正されたため、かなりの CPU サイクルが失われました。実行される分岐の数を減らしてください。
投機の問題 (キャンセルされたパイプライン・スロット)
メトリックの説明
投機の問題は、誤った投機により浪費されたパイプライン・スロットの割合を示します。これには、最終的にリタイアされない uOps の発行に使用されたスロットと、直前の誤った投機から回復するため発行パイプラインがブロックされたスロットが含まれます。例えば、分岐予測ミスにより浪費されたワークは、投機の問題カテゴリーに分類されます。別の例として、誤ったデータの予測とそれに続くメモリーオーダーの破壊があります。
考えられる問題
有用なワークを含むパイプライン・スロットの大部分がキャンセルされています。これは、分岐予測ミスやマシンクリアによって発生します。このメトリック値は、分岐リステアの問題によりハイライトされる可能性があることに注意してください。
投機の問題 (バックエンド依存のパイプライン・スロット)
メトリックの説明
スーパースカラー・プロセッサーは、概念的に命令をフェッチしてそれらを構成する操作にデコードする 'フロントエンド' と、要求される計算を実行する 'バックエンド' に分かれています。フロントエンドは、各サイクルでバックエンドを通過するパイプライン・スロットに配置される最大 4 つの操作を生成します。そのため、クロックサイクルの一定の実行期間において、その期間にリタイアすることができる有用なワークを含むパイプライン・スロットの最大数を知ることは容易です。しかし、有用なワークを含むリタイアしたパイプライン・スロットの実際の数が、この最大数になることはほとんどありません。これにはいくつかの要因が関連します: フロントエンドが時間内に命令をフェッチもしくはデコードできなかったり (フロントエンド依存の実行)、バックエンドが特定の種類の操作を受け入れる準備ができていない (バックエンド依存の実行) ことにより、パイプライン・スロットを有用なワークで埋めることができないなどが考えられます。さらに、パイプライン・スロットが有効なワークを含んでいても、投機の問題によりリタイアしない可能性があります。フロントエンド依存の実行は、大きなコードのワーキングセット、不適切なコード配置、またはマイクロコード・アシストが原因であると考えられます。バックエンド依存の実行は、長いレイテンシーの操作や実行リソースのその他の競合が原因です。投機の問題のほとんどは分岐予測ミスに由来します。
考えられる問題
パイプライン・スロットの大部分が空です。バックエンドで操作に長い時間を要すると、パイプラインにバブルが生じて、マシンがサポートするよりも、サイクルごとにリタイアされる有用なワークを含むスロットが少なくなります。その結果実行が遅くなります。除算やメモリー操作など長いレイテンシーの操作は、単一の実行ポートに多くの操作が送られる可能性 (例えば、実行ユニットがサイクルあたりにサポートできるよりも、多くの乗算操作がバックエンドに割り当てられる場合) があるため、この原因となります。
FP 算術演算
メトリックの説明
このメトリックは、CPU が実行 (リタイア) した算術浮動小数点 (FP) uOps の割合を示します。
FP アシスト
メトリックの説明
特定の浮動小数点命令は実行パイプラインで直接実行できないため、マイクロコードで実行する必要があります (小さなプログラムを実行ストリームへ投入します)。例えば、非常に小さな浮動小数点値 (デノーマルと呼ばれます) を操作する場合、浮動小数点ユニットはこの操作を直接実行することができません。代わりに、デノーマル値の計算を行う命令のシーケンスがパイプラインに投入されます。これらのマイクロコード・シーケンスは数百の命令で構成されることがあるため、マイクロコード・アシストはパフォーマンス上有害です。
考えられる問題
実行時間の大部分が浮動小数点アシストで費やされています。
ヒント
コンパイル時に DAZ (Denormals Are Zero) や FTZ (Flush To Zero) オプションを有効にして、デノーマル値をゼロにフラッシュします。デノーマル値がアプリケーションの動作に影響を与えない場合、このオプションでパフォーマンスが向上することがあります。DAZ と FTZ モードは IEEE 標準 754 と互換性がないことに注意してください。
FP スカラー
メトリックの説明
このメトリックは、CPU が実行した算術浮動小数点 (FP) スカラー uOps の割合を示します。メトリック値を解析して、ベクトル化されたコードが生成されない原因を特定します。これは、通常、アルゴリズム自身または誤った (もしくは指定されない) コンパイラー・オプションに起因します。
FP ベクトル
メトリックの説明
このメトリックは、CPU が実行した算術浮動小数点 (FP) ベクトル uOps の割合を示します。ベクトル幅が期待通りであることを確認してください。
FP x87
メトリックの説明
このメトリックは、CPU が実行した浮動小数点 (FP) x87 の uOps の割合を示します。これは、x87 FP 算術演算命令をカウントします。これにより、x87 の使用を回避し、最新の ISA にアップグレードする判断基準として使用できます。コンパイラー・オプションを使用して、新しい AVX (または SSE) 命令セットを生成します。これにより、より優れたベクトル化が行われます。
MS アシスト
メトリックの説明
特定の複雑な操作は、実行パイプラインでネイティブに処理できず、1 つ以上の uOps が発行されるマイクロコード・シーケンサー (MS) で実行する必要があります。マイクロコード・シーケンサーは、マイクロコード・アシスト (実行ストリームに投入される小さなプログラム)、フローの挿入、および命令キュー (IQ) への書き込みを実行します。例えば、非常に小さな浮動小数点値 (デノーマルと呼ばれます) を操作する場合、浮動小数点ユニットはこの操作を直接実行することができません。代わりに、デノーマル値の計算を行う命令のシーケンスがパイプラインに投入されます。これらのマイクロコード・シーケンスは数百の命令で構成されることがあるため、マイクロコード・アシストはパフォーマンス上有害です。
考えられる問題
実行時間の大部分が、マイクロコード・アシスト、フローの挿入、および命令キュー (IQ) への書き込みに費やされます。FP アシストと SIMD アシストのメトリックを調べて原因を特定します。
分岐予測ミス
メトリックの説明
分岐予測がミスしても、誤って予測されたパスの命令はパイプラインを移動し続けます。これらの命令で実行されるワークはすべてリソースを浪費し、本来実行されるべきものでないため無駄になります。このメトリックは、分岐予測ミスによって CPU が無駄にしたスロットの割合を表します。これらのスロットは、誤って推測されたプログラムの実行パスからフェッチされた uOp によって浪費されるか、マシンのアウトオブオーダー機能が投機的なパスから状態をリカバリーする場合にストールします。
考えられる問題
かなりの分岐が誤って予測され、マシンが投機的なパスから状態を回復する必要があるため、非常に多くの無駄なワークやバックエンドのストールを引き起こしています。
ヒント
1.過度な分岐予測ミスを特定して、アルゴリズムの分岐を予測し易くするか、分岐の数を減らすことを検討してください。if 文にさらに多くのワークを追加し、早期実行のためコードフロー中でそれらを上位に移動できます。'switch' と 'case' 文を使用する場合、多く実行される case 文を最初に配置します。頻繁に実行される呼び出しに仮想関数ポインターを使用しないでください。
2.コンパイラーのプロファイルに基づく最適化を使用します。
詳細は、『インテル® 64 および IA-32 プロセッサー・アーキテクチャー最適化リファレンス・マニュアル』の「サイクルのドリルダウンと分岐予測ミス」を参照してください。
バスロック
メトリックの説明
インテル® プロセッサーは、クリティカルなメモリー操作の間システムバスや同等なリンクをロックするため自動的にアサートされる LOCK# シグナルを備えています。この出力シグナルがアサートされていると、ほかのプロセッサーやバス・エージェントからのバス制御要求はブロックされます。このメトリックは、バス上に LOCK# シグナルがアサートされている間のバスサイクル比率を測定します。キャッシュ不可なメモリーによるロックされたメモリーアクセス、2 つのキャッシュラインにまたがるロックされた操作、およびキャッシュ不可なページテーブルからのページウォークがある場合、LOCK# シグナルがアサートされます。
考えられる問題
バスロックに非常に高いパフォーマンス上のペナルティーが課せられています。メモリーの同時アクセスを改善するため、ロックされたメモリーへのアクセスを避けることを強く推奨します。
ヒント
[ソース/アセンブリー] ビューの BUS_LOCK_CLOCKS.SELF イベントを調査して、LOCK# 信号がアサートされている場所を特定します。自身がアサートしている場合、メモリー・レイテンシーや再発行などのバックエンドの問題を調べてください。スキッドを考慮します。
キャッシュ依存
メトリックの説明
このメトリックは、マシンが L1、L2、および L3 キャッシュでストールした頻度を示します。キャッシュにヒットすると DRAM にヒットするよりもはるかに高速に処理されますが、パフォーマンス上重要なペナルティーを被ります。このメトリックには、共有データに対する一貫性のペナルティーも含まれます。
考えられる問題
かなりのサイクルがキャッシュからのデータフェッチに費やされています。L2 または L3 キャッシュへのアクセスに問題があるか確認するため、メモリーアクセス解析をチェックし、キャッシュをミスしたワークロードと同じパフォーマンス・チューニングの適用を検討してください。これには、データ・ワーキング・セットのサイズ縮小、データアクセス局所性の改善、低レベルのキャッシュに収めるためのワーキングセットのブロック化や分割、またはハードウェア・プリフェッチャーの使用が含まれます。ソフトウェア・プリフェッチャーの使用を検討してください。ただし、通常のロードの妨げとなったり、レイテンシーの増加やメモリー・サブシステムの負担が増える可能性があることに注意してください。このメトリックには、共有データに対する一貫性のペナルティーも含まれます。マイクロアーキテクチャー全般解析をチェックして、競合アクセスまたはデータ共有が問題であるかどうかを確認します。
リステアのクリア
メトリックの説明
このメトリックは、マシンクリアによる分岐リステアが原因で CPU がストールしたサイクルの割合を測定します。
考えられる問題
マシンクリアによる分岐リステアにより、かなりのサイクルがストールしています。
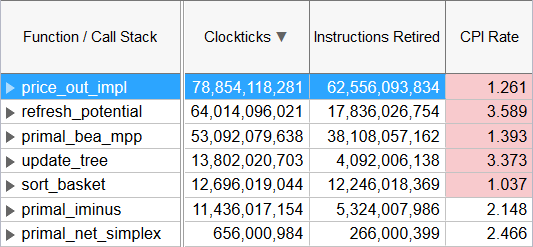
命令リタイアごとのクロックティック (CPI)
メトリックの説明
リタイアした命令あたりのクロック数 (CPI) イベント比率は、1 命令あたりのサイクル数とも呼ばれ、サンプリング・モードにおけるにおけるパフォーマンス・モニタリング・カウンター (PMC) 解析としても知られる、ハードウェア・イベントベース・サンプリング収集の基本パフォーマンス・メトリックの 1 つです。この比率は、HALT (停止) 状態ではないプロセッサー・サイクル (クロックティック) をリタイアした命令数で除算することで計算されます。プロセッサーごとにクロックティックとリタイアした命令をカウントするイベントは異なることがありますが、インテル® VTune™ プロファイラーは正しいイベントを認識します。
高い CPI 値の意味は ?
アプリケーションや関数の CPI 値は、実行に及ぼすレイテンシーの影響を表します。CPI 値が高いほど、システムのレイテンシーが増加することを意味し、平均して命令がリタイアするまでのクロックティックが長くなります。システムのレイテンシーは、キャッシュミス、I/O、およびその他のボトルネックによって引き起こされます。
パフォーマンス・チューニングの労力を費やす場所を特定する場合、CPI は最初に確認すべきメトリックです。良好な CPI 率は、コードが適切に実行されていることを示します。
CPI を使用する一般的な方法は、現在の CPI 値を同じワークロードを実行するベースライン CPI 値と比較することです。例えば、システムやコードを変更した後に、インテル® VTune™ プロファイラーを実行して CPI 値を収集します。変更後アプリケーションのパフォーマンスが低下した場合、CPI が増加した関数を特定するのは、何が起こったか理解する方法の 1 つです。アプリケーションの実行時間を短縮する最適化が行われた場合、インテル® VTune™ プロファイラーのデータを調査して CPI が減少したことを確認できます。また、この情報は以降の最適化に向けた調査でも活用できます。CPI が減少する要因は ? キャッシュミスの減少、メモリー操作の減少、メモリー・レイテンシーの減少などが考えられます。
高い CPI を特定する方法は ?
実行するワークロードの CPI 値は、コード、プロセッサー、およびシステム構成の影響を受けます。
インテル® VTune™ プロファイラーは、インテルが設定するしきい値に対して CPI 値を解析します。これらの値は一般的なガイドとして使用できます。
良い |
低い |
|---|---|
0.75 |
4 |
CPI < 1 は一般的に命令依存のコードですが、CPI > 1 はメモリー依存のようなストールサイクルに依存するアプリケーションに見られます。
CPI 値がしきい値を超えると、インテル® VTune™ プロファイラーはその値をピンク色でハイライトします。
高い CPI 比率 (>1) は、コード領域の命令を実行するため多くのプロセッサー・クロックが費やされていることを示します。大部分の命令が高レイテンシーではなく、および (また) マイクロコード ROM から供給される場合、これは問題があることを示します。この場合、プロセッサー内部で命令が実行されるように効率を高めるため、コードを変更する余地があります。
インテル® ハイパースレッディング・テクノロジーが有効なプロセッサーでは、この比率は物理パッケージのスリープモードではない、つまり物理パッケージの少なくとも 1 つの論理プロセッサーが使用するフェーズの CPI を測定します。論理プロセッサーのクロックティックは、論理プロセッサーが HALT (停止) 状態 (命令を実行しない状態) であっても継続してカウントされます。クロックティック・イベントは、リタイアした命令イベントが変わらなくとも継続してカウントされるため、論理プロセッサーの CPI 比率に影響を及ぼす可能性があります。高い CPI 値はパフォーマンスの問題があることを示しますが、特定の論理プロセッサーの高い CPI 値は非効率な CPU の使用を示し、実行上は問題とはならない可能性があります。
アプリケーションがスレッド化されている場合、CPI はすべてのコードレベルに影響します。クロックティック・イベントは、各論理プロセッサーで独立してカウントされ、並列実行は考慮されません。
次の例について考えてみます。
論理プロセッサー 0 上の関数 XYZ |------------------------| 4000 クロックティック/1000 命令
論理プロセッサー 1 上の関数 XYZ |------------------------| 4000 クロックティック/1000 命令
関数 XYZ の CPI は、(8000 / 2000) 4.0 です。クロックティックで並列実行を考慮すると、CPI は (4000 / 2000) 2.0 になります。クロックティック・イベント・データを解釈するには、アプリケーションの動作に関する知識が求められます。
CPI を使用する落とし穴は ?
CPI は誤解を招く可能性があるため、その落とし穴を理解する必要があります。システム上のコードのパフォーマンスに影響を及ぼすのは、CPI (レイテンシー) だけではありません。もう一つの重要な要因は、実行される命令数です (パス長とも呼ばれます)。コードを最適化したり変更すると、命令実行時間 (CPI) や実行する命令数、またはそれら両方に影響します。実行された命令数を考慮せずに CPI を参照すると、解析結果を誤って解釈する可能性があります。例えば、コードをベクトル化し、単一の命令で複数のデータを処理するように数学演算を変更したと仮定します。これは、多数の単一データの操作命令を、少数の複数データ操作命令に置き換えることで実現されます。これにより、コード全体で実行される命令数は減少しますが、複数データ処理命令 (SIMD) は複雑で実行に時間がかかるため、CPI が上昇する可能性があります。多くの場合、CPI が上昇してもベクトル化によりパフォーマンスは向上します。
実行されたすべての命令を考慮する必要があります。実行された命令数は、インテル® VTune™ プロファイラーでは、INST_RETIRED と呼ばれます。リタイアした命令数が一定である場合、CPI はパフォーマンス・チューニングに適した指標であると言えます (例えば、システムのチューニング)。命令数と CPI の両方が変化する場合、それぞれのメトリックを調べて、パフォーマンスが向上または低下した原因を理解する必要があります。最後に、CPI に代わってトップダウン方式を適用します。
クロックティックとパイプライン・スロット・ベースのメトリック
CPI レート
メトリックの説明
リタイアした命令あたりのサイクル数 (CPI) は、各命令の実行にかかったおおよその時間を示す基本的なパフォーマンス・メトリックです (単位はサイクル数)。最近のスーパースカラー・プロセッサーは、1 サイクルあたり 4 つまでの命令を発行できるため、理論的な最良の CPI 値は 0.25 になります。さまざまな要因 (大きなレイテンシーのメモリー、浮動小数点操作、SIMD 操作、分岐予測ミスによりリタイアしない命令、フロントエンドの命令スタベーションなど) により、測定される CPI の値は高くなる傾向にありますが、CPI が 1 の場合、HPC アプリケーションでは容認されますが、異なるアプリケーション分野の期待値はさまざまです。CPI はアプリケーションのパフォーマンス・チューニングの全体的な可能性を判断する優れたメトリックとして広く用いられています。
インテル® VTune™ プロファイラーは、クロックティックまたはパイプライン・スロットとして測定されるマイクロアーキテクチャー全般解析向けのハードウェア・イベントベースのメトリックを提供します。この違いを理解するため、次の例を考えてみます。
例えば、2 つのスロットがパイプライン・スロットの 50% のサイクルをそれぞれ浪費していると想定します。しかし、クロックティックは、各サイクルでストールがあるため、ストールメトリックは 100% になります。さらに、各サイクルのストールは異なる原因で発生する可能性があるため、クロックティックで測定されたメトリックが重複することがあります。
そのため、クロックティックで測定されたメトリックは、パイプライン・スロットで測定されたメトリックよりも精度が低くなります。これは重複するメトリックが、そのレベルの合計が必ずしも親メトリックの値と一致しないためです。しかし、このようなメトリックは、コード内部のパフォーマンスのボトルネックを特定するのに役立ちます。
考えられる問題
CPI 値が高すぎます。これは、メモリーストール、命令スタベーション、分岐予測ミス、または長いレイテンシーの命令などに起因します。高い CPI の原因を特定するには、ほかのハードウェア関連のメトリックを調査します。
CPI レート (Intel Atom® プロセッサー)
メトリックの説明
リタイアした命令あたりのサイクル数 (CPI) は、各命令のにかかったおおよその時間を示す基本的なパフォーマンス・メトリックです (単位はサイクル数)。Intel Atom® プロセッサーでは、スレッドごとの理論的な最良の CPI は 0.50 ですが、2.0 を超える場合、調査の必要があります。高い CPI 値は、長いレイテンシーのメモリー、浮動小数点操作、分岐予測ミスによるリタイアしない命令、またはフロントエンドでの命令スタベーションなど軽減可能なシステム内のレイテンシーを示します。SIMD などの最適化では、サイクルあたりの命令数が少なくなり (CPI が向上)、デバッグコードでは冗長な命令を使用することがあるためサイクルごとの命令数が増加します (CPI は低下)。
考えられる問題
CPI 値が高すぎます。これは、メモリーストール、命令スタベーション、分岐予測ミス、または長いレイテンシーの命令などに起因します。高い CPI の原因を特定するには、ほかのハードウェア関連のメトリックを調査します。
CPU 時間
メトリックの説明
CPU 時間は、CPU がアクティブにアプリケーションを実行している時間です。
コア依存
メトリックの説明
このメトリックは、ボトルネックとなったコアの非メモリー問題の割合を示します。ハードウェア計算リソース不足や依存関係のあるソフトウェア命令は、コア依存に分類されます。これは、マシンが OOO リソースを使い果たしている可能性を示し、特定の実行ユニットが過負荷であるか、命令フローの依存関係によってパフォーマンスが制限されている可能性 (FP チェーンの長いレイテンシーの算術演算など) があります。
CPU 周波数
メトリックの説明
クロックティック・イベントでキャプチャーされた APERF/MPERF MSR レジスターを使用して計算された周波数です。
2 つのサンプル間の平均論理コア周波数を示すソフトウェア周波数です。サンプラーのサンプリング間隔が小さいほど、実際の HW 周波数に近いメトリックになります。
CPU 時間
メトリックの説明
CPU 時間は、CPU がアクティブにアプリケーションを実行している時間です。
CPU 利用率
メトリックの説明
このメトリックは、アプリケーションの並列処理効率を評価します。これは、並列ランタイムシステムによるオーバーヘッドを除く、アプリケーション内で費やされるシステム内のすべての論理 CPU コアの比率を推測します。100% の利用率は、アプリケーションが実行中にすべての論理 CPU コアをビジーに保つことを意味します。
解析タイプに応じて、[ボトムアップ] グリッド (HPC パフォーマンス特性)、[タイムライン] ペイン、および有効な CPU 利用率分布図の [サマリー] ウィンドウに、CPU 利用率データが表示されます。
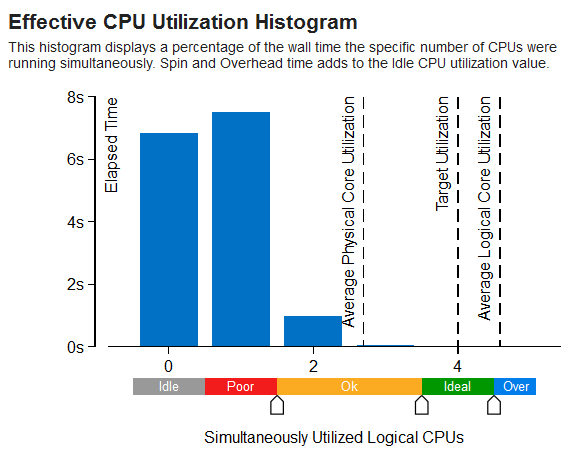
帯域幅利用率分布図
分布図では、インテル® VTune™ プロファイラーはプロセッサー利用率スケールを識別し、ターゲット CPU 利用率を計算して、プロセッサーのコア数に応じてデフォルトの利用率範囲を定義します。必要に応じて、スライドバーを調整することで利用率範囲のしきい値を変更できます。
利用率タイプ |
デフォルトの色 |
説明 |
|---|---|---|
アイドル |
|
アイドル利用率。デフォルトでは、すべてのスレッドで CPU 時間が 1 コア CPU 時間の 100% の 0.5 未満である場合、CPU 利用率はアイドルとして分類されます。式: ∑i=1,ThreadsCount(CPUTime(T,i)/T) < 0.5、ここで CPUTime(T,i) はスレッド i の間隔 T での合計 CPU 時間です。 |
低い |
|
低い利用率。デフォルトでは、低い利用率は同時に実行される CPU 数が、ターゲットの CPU 利用率の 50% 未満の状態です。 |
OK |
|
容認 (OK) できる利用率です。デフォルトでは、OK となる利用率は同時に実行される CPU 数が、ターゲットの CPU 利用率の 51% ~ 85% の状態です。 |
理想的 |
|
理想的な利用率。デフォルトでは、理想的な利用率は同時に実行される CPU 数が、ターゲットの CPU 利用率の 86% ~ 100% の状態です。 |
インテル® VTune™ プロファイラーは、スピンとオーバーヘッドをアイドル CPU 利用率として扱います。コールスタック情報の有無により、それぞれの解析タイプでスピンとオーバーヘッド時間の認識は異なります。そのため、解析タイプごとに CPU 利用率のグラフ表示が異なることがあります。
HPC パフォーマンス特性解析では、インテル® VTune™ プロファイラーは、インテル® Xeon Phi™ プロセッサー (開発コード名 Knights Mill と Knights Landing) を除くすべてのシステムで、効率的な物理コア利用率と効率的な論理コア利用率を区別します。
インテル® Xeon Phi™ プロセッサー (開発コード名 Knights Mill と Knights Landing) やインテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) が無効なシステムでは、通常の効率的な CPU 利用率メトリックのみが示されます。
CPU 利用率とスレッド効率
論理的に待機している間 (スレッドがスピンしている)、CPU でスレッドコードが実行される場合、CPU 利用率はスレッド効率 (スレッド化解析で利用可能) よりも高くなります。
次の場合に CPU 利用率はスレッド効率よりも低くなります。
並列性レベルが利用可能なコア数よりも高いと (オーバーサブスクリプション)、このレベルの CPU 利用率に達するのは困難です。一般に、オーバーサブスクリプションが頻繁に発生すると、過度なコンテキスト・スイッチが生じるため、アプリケーションのパフォーマンスに悪影響を与えます。
プロファイルされたプロセスがスワップアウトされた期間がありました。そのため、論理的には待機状態ではありませんでしたが、いずれの CPU にもスケジュールされていません。
考えられる問題
このメトリックの値が低いと、負荷インバランス、スレッド化のランタイム・オーバーヘッド、競合した同期または低いスレッド/プロセスの利用により、論理 CPU コアの利用率が低い可能性を示します。MPI と OpenMP* 並列処理の効率を推測するにはCPU 利用率のサブメトリックを調査するか、スレッド解析を実行してその他の並列化ランタイムの並列処理のボトルネックを特定します。
CPU 利用率 (OpenMP*)
メトリックの説明
このメトリックは、アプリケーションがどの程度効率的に CPU を利用しているかを示し、アプリケーションの並列効率を評価するのに役立ちます。システム上のすべての論理 CPU による平均 CPU 利用率をパーセントで示します。平均 CPU 利用率には、有効な時間のみが含まれ、スピンやオーバーヘッドは含まれません。100% の CPU 利用率は、すべての論理 CPU にアプリケーションの計算負荷がかかっていることを意味します。
考えられる問題
このメトリックの値が低いと、負荷インバランス、スレッド化のランタイム・オーバーヘッド、競合した同期または低いスレッド/プロセスの利用により、論理 CPU コアの利用率が低い可能性を示します。MPI と OpenMP* 並列処理の効率を推測するにはCPU 利用率のサブメトリックを調査するか、スレッド解析を実行してその他の並列化ランタイムの並列処理のボトルネックを特定します。
0 ポート利用サイクル
メトリックの説明
このメトリックは、任意の実行ポートで CPU が uOps を実行しなかったサイクルの割合を示します。除算などのレイテンシーが長い命令はこのメトリックに影響します。
考えられる問題
かなりのサイクルで CPU は任意の実行ポートで uOps を実行していません。除算などのレイテンシーが長い命令はこの問題につながります。[アセンブリー] ビューと最適化ガイドの付録 C を参照して、5 サイクル以上のレイテンシーの命令を確認してください。
1 ポート利用サイクル
メトリックの説明
このメトリックは、すべての実行ポートで CPU がサイクルあたり 1 uOps を実行したサイクルの割合を示します。これは、ソフトウェア命令間のデータ依存関係が顕著であることや、特定のハードウェア・リソースのオーバーサブスクライブが原因である可能性があります。1_Port_Utilized と L1 依存の値が高い場合、このメトリックは、必ずしも完全な実行スタベーションが原因ではない (リンクリストの検索など、短い L1 レイテンシーが原因の) L1 データキャッシュのレイテンシーのボトルネックを示します。これには、アセンブリーの調査が役立ちます。
考えられる問題
このメトリックは、すべての実行ポートで CPU がサイクルあたり 1 uOps を実行したサイクルの割合を示します。これは、ソフトウェア命令間のデータ依存関係が顕著であることや、特定のハードウェア・リソースのオーバーサブスクライブが原因である可能性があります。1_Port_Utilized と L1 依存の値が高い場合、このメトリックは、必ずしも完全な実行スタベーションが原因ではない (リンクリストの検索など、短い L1 レイテンシーが原因の) L1 データキャッシュのレイテンシーのボトルネックを示します。これには、アセンブリーの調査が役立ちます。このメトリック値は、L1 依存の問題によりハイライトされる可能性があることに注意してください。
2 ポート利用サイクル
メトリックの説明
このメトリックは、すべての実行ポートで CPU がサイクルあたり 2 uOps を実行したサイクルの割合を示します。ヒント: ループのベクトル化 - 今日のコンパイラーのほとんどは自動ベクトル化機能を備えます - 、複数の要素が同じ uOp で計算されるため実行ポートへの負荷を軽減します。
3 ポート以上の利用サイクル
メトリックの説明
このメトリックは、すべての実行ポートで CPU がサイクルあたり 3 uOps 以上を実行したコアサイクルの割合を示します。
除算器
メトリックの説明
すべての算術演算が同じ時間で完了するわけではありません。除算と平方根は DIV ユニットで実行され、整数や浮動小数点の加算、減算、または乗算よりも長い時間がかかります。このメトリックは、除算器ユニットがアクティブであったサイクルの割合を示します。
考えられる問題
実行時間のかなりの部分で DIV ユニットがアクティブです。
ヒント
ホットな長いレイテンシー操作を検出して、排除を試みます。例えば、定数による除算は、定数の逆数の積で置き換えることを検討してください。整数除算である場合、シフトの使用を検討してください。
(情報) DSB の適用
メトリックの説明
DSB (デコード済み命令キャッシュ、または uOp キャッシュと呼ばれる) によって供給された uOps の割合を示します。
考えられる問題
ほとんどの uOps は DSB (デコード済み命令キャッシュ、または uOp キャッシュと呼ばれる) から供給されていません。これは、ホットなコード領域が DSB に収まらないほど大きな場合に発生します。
ヒント
ホットなコード領域が DSB に収まるように、(プロファイルに基づく最適化を使用するなどして) コード配置の変更を検討してください。
『インテル® 64 アーキテクチャーおよび IA-32 アーキテクチャー最適化リファレンス・マニュアル』の「デコード済み命令キャッシュの最適化」を参照してください。
DTLB ストア・オーバーヘッド
メトリックの説明
このメトリックは、第 1 レベルのデータ TLB ストアミスを処理するのに費やされたサイクルの割合を示します。通常のデータキャッシュと同様に、DTLB のオーバーヘッドを減らすため、データの局所性を改善し、ワーキングセットのサイズを抑えることに注目します。さらに、プロファイルに基づく最適化 (PGO) を使用して、頻繁に使用されるデータを同じページに配置します。頻繁に使用される大量のデータには、大きなページサイズを検討します。
効率良い CPU 利用率
メトリックの説明
アプリケーションによって使用される論理 CPU コア数は? このメトリックは、アプリケーションの並列処理効率を評価するのに役立ちます。これは、並列ランタイムシステムによるオーバーヘッドを除く、アプリケーション内で費やされたシステム内のすべての論理 CPU コアの割合を推測します。100% の利用率は、アプリケーションが実行中にすべての論理 CPU コアをビジーに保つことを意味します。
効率的な物理コア利用率
メトリックの説明
このメトリックは、アプリケーションがどの程度効率的に物理 CPU コアを利用しているかを示し、アプリケーションの並列効率を評価するのに役立ちます。システム上のすべての物理 CPU による平均利用率のパーセントを示します。効率的な物理コア利用率には、有効な時間のみが含まれ、スピンやオーバーヘッドは含まれません。100% の利用率は、すべての物理 CPU がアプリケーションの計算をロードしていることを意味します。
考えられる問題
このメトリックの値が低いと、次の原因で物理 CPU コアの利用率が低い可能性を示します。
- ロード・インバランス
- スレッドランタイムのオーバーヘッド
- 競合する同期
- スレッド/プロセスの低い利用率
- 物理コアではなく論理コアを利用する誤ったアフィニティー
有効時間
メトリックの説明
有効時間は、ユーザーコードで費やされた CPU 時間です。このメトリックはスピンとオーバーヘッド時間を含みません。
経過時間
メトリックの説明
経過時間は、収集の最初から最後までのウォールクロック時間です。
経過時間 (グローバル)
メトリックの説明
経過時間は、収集の最初から最後までのウォールクロック時間です。
経過時間 (合計)
メトリックの説明
経過時間は、収集の最初から最後までのウォールクロック時間です。
BB 実行カウントの予測
メトリックの説明
基本ブロック (BB) の実行回数の統計予測を示します。
予測されたアイドル時間
メトリックの説明
理想的な時間は、次の公式によって OpenMP* ランタイムのオーバーヘッドがゼロになるようにロードバランスされた並列領域の予測時間です: すべての領域の合計ユーザー CPU 時間 / OpenMP* スレッド数
実行ストール
メトリックの説明
実行ストールは、マシンが計算リソースを浪費せずフル稼働していることを示します。ただし、場合によっては、クリティカルな計算リソースを待機する間に、長いレイテンシー操作をシリアル化できることがあります。このメトリックは、すべてのサイクルに対してマイクロオペレーションが実行されなかったサイクルの比率です。
考えられる問題
マイクロオペレーションが実行されなかったサイクルの比率が高いです。コード領域で実行ストールが高く、長いレイテンシーの操作を探して、代替方法を使用するか、低いレイテンシーの操作を使用してください。例えば、'div' 操作を右シフトで置き換えたり、メモリー・アクセス・レイテンシーを減らします。
フォルス・シェアリング
メトリックの説明
このメトリックは、CPU が共有されたキャッシュラインへのストア操作でストールしている頻度を示します。これは、スレッドが異なるラインにアクセスするようにパディングを追加することで簡単に回避できます。
far 分岐
メトリックの説明
このメトリックは、コール/リターンが far ポインターを使用していることを示します。far コールは、ユーザーコードから特権コードへの移行によく使用されます。
考えられる問題
ユーザーコードから特権コードへの移行が頻発している可能性があります。システム API 呼び出しを減らしてください。
フラグ・マージ・ストール
メトリックの説明
シフト cl 命令は、潜在的に高価なフラグマージを必要とします。このメトリックは、マージのパフォーマンス・ペナルティーを予測します。
考えられる問題
サイクルのほとんどがフラグマージ操作に費やされています。ソースビューを使用して、原因となる命令を特定しそれらを排除します。
FPU 利用率
メトリックの説明
このメトリックは、プログラムがどの程度 FPU に依存しているかを示します。100% の値は、FPU に完全な負荷がかかり、アプリケーション実行の各サイクルで全能力を活用してベクトル命令がリタイアしていることを意味します。
考えられる問題
メトリック値が低いです。これは、ベクトル化されていない浮動小数点操作により FPU の利用率が低いこと、または従来のベクトル命令セットやメモリー・アクセス・パターンの問題による非効率なベクトル化を示します。アプリケーションのベクトル化の効率を改善するには、インテル® Advisor のベクトル解析を使用してください。
パックド FP 命令の %
メトリックの説明
このメトリックは、パックド浮動小数点命令のパーセンテージを表します。
128 ビット・パックド浮動小数点命令の %
メトリックの説明
このメトリックは、128 ビットのパックド浮動小数点命令のパーセンテージを表します。
256 ビット・パックド浮動小数点命令の %
メトリックの説明
このメトリックは、256 ビットのパックド浮動小数点命令のパーセンテージを表します。
パックド SIMD 命令の %
メトリックの説明
このメトリックは、パックド浮動小数点命令のパーセンテージを表します。
スカラー FP 命令の %
メトリックの説明
このメトリックは、スカラー浮動小数点命令のパーセンテージを表します。
スカラー SIMD 命令の %
メトリックの説明
メトリックは、スカラー SIMD 命令のパーセンテージを表します。
FP 算術演算/メモリーリード命令の比率
メトリックの説明
このメトリックは、算術浮動小数点命令とメモリーリード命令の比率を示します。値が 0.5 より小さい場合、ベクトル操作のデータアクセスがアライメントされていないことを示し、ベクトル命令実行のパフォーマンスに影響する可能性があります。
FP 算術演算/メモリーライト命令の比率
メトリックの説明
このメトリックは、算術浮動小数点命令とメモリーライト命令の比率を示します。値が 0.5 より小さい場合、ベクトル操作のデータアクセスがアライメントされていないことを示し、ベクトル命令実行のパフォーマンスに影響する可能性があります。
ループタイプ
メトリックの説明
コンパイラーの最適化レポートを基にループのタイプ (本体、ピール、リマインダー) を表示します。
サイクルごとの SP FLOP
メトリックの説明
クロックティックごとの単精度浮動小数点操作数 (FLOP) を示します。このメトリックは、ベクトルコードの生成と実行の効率を示します。低い FLOP 数の原因を見るには、メトリックに示される問題のリストを調査します。サイクルごとの最大 FLOP 数は、ハードウェア・プラットフォームに依存します。すべての倍精度操作は 2 つの単精度操作に変換されます。
ベクトル能力の使用
メトリックの説明
アプリケーション・コードのベクトル化と浮動小数点計算の関係を示します。100% の値は、すべての浮動小数点命令がベクトル化され、完全にベクトル能力を活用していることを意味します。
ベクトル命令セット
メトリックの説明
算術浮動小数点計算とメモリーアクセス操作に使用されるベクトル命令セットを表示します。
考えられる問題
最新のベクトル命令セットを使用していません。最新のベクトル命令セットを使用するようにコンパイラー・オプションを変更して、コードを再コンパイルすることを検討してください。C++ と Fortran の詳細な情報については、コンパイラーのユーザー・リファレンス・ガイドを参照してください。
フロントエンド帯域幅
メトリックの説明
このメトリックは、命令デコーダーの非効率性や DSB (デコード済 uOps キャッシュ) でのキャッシュのコード制限など、フロントエンド帯域幅の問題により CPU がストールしたスロットの割合を示します。この場合、フロントエンドは通常、最適ではない数の uOps をバックエンドに供給します。
フロントエンド帯域幅 DSB
メトリックの説明
このメトリックは、DSB (デコード済み uOp キャッシュ) フェッチ・パイプラインにより CPU が制限を受けた可能性があるサイクルの割合を示します。例えば、非効率な DSB キャッシュ構造の使用や、読み取り時のバンク競合がここに分類されます。
フロントエンド帯域幅 LSD
メトリックの説明
このメトリックは、CPU の動作が LSD (ループストリーム検出器) ユニットによって制限されたサイクル数の割合を示します。一般に、LSD の uOp 供給は良好です。しかし、まれに LSD 構造に適していない小さなサイズ (uOps 数) のループでは、適切に uOp が供給されないことがあります。
考えられる問題
CPU のかなりのサイクルが、LSD (ループストリーム検出器) ユニットの uOps を待機するのに費やされました。一般に、LSD の uOp 供給は良好です。しかし、まれに LSD 構造に適していない小さなサイズ (uOps 数) のループでは、適切に uOp が供給されないことがあります。
フロントエンド帯域幅 MITE
メトリックの説明
このメトリックは、命令デコーダーの非効率性など MITE フェッチ・パイプラインの問題により、CPU がストールしたサイクルの割合を示します。
フロントエンド依存
メトリックの説明
フロントエンド依存のメトリックは、プロセッサーのフロントエンドがバックエンドを下回るスロットの割合を表します。フロントエンドは、バックエンドで実行される命令のフェッチを担当するプロセッサー・コアの最初の部分です。フロントエンド内部で、分岐予測器がフェッチする次のアドレスを予測し、キャッシュラインがメモリー・サブシステムからフェッチされ、命令に解読され、最後にマイクロオペレーション (uOps) にデコードされます。フロントエンド依存のメトリックは、バックエンドでストールが発生していない場合に、使用されない発行スロットがあることを示します (バックエンドが受け入れ可能にもかかわらず、フロントエンドが uOps を供給できなかったバブル)。例えば、命令キャッシュミスによるストールは、フロントエンド依存のカテゴリーに分類されます。
考えられる問題
フロントエンドの問題により、パイプライン・スロットの大部分が空です。
ヒント
コードのワーキングサイズが大きすぎないこと、コードの配置が 4 つのパイプライン・スロットを満たす十分な命令を取得するのにそれほど多くのメモリーアクセスを必要としないこと、またはマイクロコード・アシストを確認します。
フロントエンドその他
メトリックの説明
このメトリックは、フロントエンドから供給されなかったスロットを考慮して、一般的なフロントエンド・ストールとしてはカウントされません。
考えられる問題
フロントエンドは、一般的なフロントエンド・ストールとして分類できないパイプライン・スロットの大部分を供給できませんでした。
分岐リステア
メトリックの説明
このメトリックは、分岐リステアによって CPU ストールが発生したサイクルの割合を示します。
考えられる問題
分岐リステアにより、かなりのサイクルがストールしています。分岐リステアは、あらゆる種類の分岐予測ミスに続く、補正されたパスから命令をフェッチする際のフロントエンドでの遅延を予測します。例えば、多くの予測ミスを伴う分岐が多いコードは分岐リステアに分類されます。このノードの値は、兄弟コア間で重複する可能性があることに注意してください。
DSB スイッチ
メトリックの説明
このキャッシュは DSB (デコード・ストリーム・バッファー) と呼ばれ、デコード済みの uOps を保存します。MITE (マイクロインストラクション・トランスレーション・エンジン) と呼ばれる従来のデコード・パイプラインのペナルティーの多くを回避します。ただし、DSB にキャッシュされた領域から制御フローが外部に出ると、uOps の発行が DSB から MITE に切り替わるため、フロントエンドはペナルティーを被ります。DSB スイッチメトリックはこのペナルティーを測定します。
考えられる問題
サイクルの大部分が DSB から MITE への切り替えに費やされています。これは、ホットなコード領域が DSB に収まらないほど大きな場合に発生します。
ヒント
ホットなコード領域が DSB に収まるように、(プロファイルに基づく最適化を使用するなどして) コード配置の変更を検討してください。
詳細は、『インテル® 64 および IA-32 アーキテクチャー最適化リファレンス・マニュアル』の「デコード済み命令キャッシュの最適化」を参照してください。
命令キャッシュミス
メトリックの説明
新しい uOps をパイプラインに取り入れるには、コアがデコード済み命令キャッシュからフェッチしたり、メモリーから命令をフェッチしてデコードする必要があります。後者の場合、メモリーへの要求は、直近のコードのワーキングセットをキャッシュする L1I (レベル 1 命令) キャッシュを最初に通過します。フェッチされる命令が L1I に存在しない場合、フロントエンドのストールが発生する可能性があります。考えられる理由は、コードのワーキングセットが大きすぎるか、ホットなコードとコールドコード間の断片化です。後者の場合、ホットな命令が L1I にフェッチされると、キャッシュライン上の任意のコールドコードが置き換えられます。これは、ほかのホットなコードの排出に繋がります。
考えられる問題
命令フェッチのほとんどが命令キャッシュをミスしました。
ヒント
1.プロファイルに基づく最適化を使用してホットなコード領域のサイズを減らします。
2.ホットな関数が一緒に配置されるよう、関数を再配置するコンパイラー・オプションを使用してください。
3.アプリケーションがマクロを多用している場合、関数に変換するかリンカーオプションを使用して繰り返し実行されるコードを排除します。
4.Os/O1 最適化レベル、または以下の最適化のサブセットを使用して、コードのサイズを減らしてください:
フットプリントを減らせる場合にのみインライン展開を使用します。
ループアンロールを無効にします。
組込み関数のインライン展開を無効にします。
ITLB オーバーヘッド
メトリックの説明
x86 アーキテクチャーでは、仮想メモリーと物理メモリーのマッピングは、メモリーに保持されるページテーブルによって行われます。このテーブルへの参照を最小限にするため、ページテーブルの最近使用されたマッピング情報は、'トランスレーション・ルックアサイド・バッファー' (TLB) の階層にキャッシュされ、以降の仮想アドレス変換で参照されます。データキャッシュと同様に、要求が満たされるまでの距離が遠いほどパフォーマンスは低下します。このメトリックは、ITLB (命令 TLB) ミスによって引き起こされるページウォークのパフォーマンス・ペナルティーを予測します。
考えられる問題
サイクルのほとんどが命令 TLB ミスに費やされています。
ヒント
1.プロファイルに基づく最適化と IPO を使用して、ホットなコード領域のサイズを減らします。
2.ホットな関数が一緒に配置されるよう、関数を再配置するコンパイラー・オプションを使用してください。
3.アプリケーションがマクロを多用している場合、関数に変換するかリンカーオプションを使用して繰り返し実行されるコードを排除します。
4.Windows* ターゲットでは、関数分割を追加します。
5.ラージ・コード・ページの使用を検討してください。
レングス変更プリフィクス
メトリックの説明
このメトリックは、レングス変更プリフィクス (LCP) によって CPU がストールしたサイクルの割合を示します。この問題を回避するには適切なコンパイラー・オプションを使用します。インテル® コンパイラーは、デフォルトでこのオプションを有効にします。
考えられる問題
このメトリックは、レングス変更プリフィクス (LCP) によって CPU がストールしたサイクルの割合を示します。
ヒント
この問題を回避するには適切なコンパイラー・オプションを使用します。インテル® コンパイラーは、デフォルトでこのオプションを有効にします。
『インテル® 64 アーキテクチャーおよび IA-32 アーキテクチャー最適化リファレンス・マニュアル』の「レングス変更プリフィクス (LCP)」を参照してください。
MS スイッチ
メトリックの説明
このメトリックは、uOps 供給をマイクロコード・シーケンサー (MS) に切り替えたことにより、CPU がストールしたサイクルの割合を示します。一般的な命令は、DSB または MITE パイプラインによる供給向けに最適化されています。特定の操作は実行パイプラインで直接実行できないため、マイクロコードで実行する必要があります (小さなプログラムを実行ストリームへ投入します)。頻繁に MS に切り替わるとパフォーマンスに悪影響を与えます。MS は、CPIUD のような CISC 命令によって要求される長い uOp フロー、またはデノーマル値を扱う浮動小数点アシストなどの特殊な条件で供給されます。
考えられる問題
uOps 供給をマイクロコード・シーケンサー (MS) に切り替えたことにより、サイクルの大部分がストールしています。頻繁に使用される命令は、DSB または MITE パイプラインによる供給向けに最適化されます。特定の操作は実行パイプラインで直接実行できないため、マイクロコードで実行する必要があります (小さなプログラムを実行ストリームへ投入します)。頻繁に MS に切り替わるとパフォーマンスに悪影響を与えます。MS は、CPIUD のような CISC 命令によって要求される長い uOp フロー、またはデノーマル値を扱う浮動小数点アシストなどの特殊な条件で供給されます。このメトリック値は、マイクロコード・シーケンサーの問題によりハイライトされる可能性があることに注意してください。
フロントエンドのレイテンシー
メトリックの説明
このメトリックは、命令キャッシュミス、ITLB ミス、分岐予測ミス後のフェッチのストールなど、フロントエンドのレイテンシーの問題により、CPU がストールしたスロットの割合を示します。このような場合、フロントエンドは uOps を供給しません。
リタイア全般
メトリックの説明
このメトリックは、CPU がマイクロコード・シーケンサーから供給されていない uOps をリタイアするスロットの割合を示します。これは、プログラムによって実行された命令の総数と関連があります。命令ごとの uOps 比率は 1 であると想定されます。これは上位 4 つのカテゴリーのうち最も理想的ですが、高い値は改善の余地がまだあることを示します。可能であれば、命令数を減らすか、ベクトル化などさらに効率的な命令の生成に注目してください。
ハードウェア・イベント・カウント
ハードウェア・イベント・サンプル・カウント
命令キャッシュラインのフェッチ
メトリックの説明
このメトリックは、命令キャシュラインのフェッチによる損失サイクルの割合を予測します。
考えられる問題
命令キャッシュラインのフェッチにより、かなりの CPU サイクルが損失しました。
理想的な時間
メトリックの説明
理想的な時間は、次の公式によって OpenMP* ランタイムのオーバーヘッドがゼロになるようにロードバランスされた並列領域の予測時間です: すべての領域の合計ユーザー CPU 時間 / OpenMP* スレッド数
インバランスまたはシリアルスピン
メトリックの説明
インバランスまたはシリアルスピン時間は、ワーキングスレッドが同期バリアでスピンして CPU リソースを消費しているウォールクロック時間です。並列領域での高いメトリック値は、ロード・インバランスやすべてのワーキングスレッドの非効率な並行性によって引き起こされます。ロード・インバランスに対処するには、動的なワーク・スケジュールを適用することを検討してください。シリアル実行 (シリアル - 領域外) の高いメトリック値は、シリアル・アプリケーションの実行時間が顕著であり、プロセッサーの利用効率を制限していることを示します。アプリケーションのシリアル領域の並列化、アルゴリズムまたはマイクロアーキテクチャーのチューニング・オプションを調査します。
考えられる問題
並列領域内の OpenMP* バリアでの待機時間は、ロード・インバランスに起因する可能性があります。必要に応じて、動的ワーク・スケジュールを使用して、インバランスを軽減することを検討してください。シリアル実行 (シリアル - 領域外) の高いメトリック値は、シリアル・アプリケーションの実行時間が顕著であり、プロセッサーの利用効率を制限していることを示します。アプリケーションのシリアル領域の並列化、アルゴリズムまたはマイクロアーキテクチャーのチューニング・オプションを調査します。
インアクティブ同期待機カウント
メトリックの説明
インアクティブ Sync 待機カウントは、同期のため OS のスケジューラーによって実行を除外されたスレッドのコンテキスト・スイッチの回数です。スレッドのコンテキスト・スイッチの回数が多すぎると、アプリケーションのパフォーマンスに悪影響を与えます。最適化を適用して同期の競合を減らし、問題を解決します。
インアクティブ同期待機時間
メトリックの説明
インアクティブ同期待機時間は、スレッドがインアクティブのままで、同期のため OS スケジューラーによって実行から除外された時間です。アプリケーション実行のクリティカル・パスでの過度なインアクティブ同期待機時間は、低い CPU 利用率と相まって、アプリケーションの並列実行に悪影響を及ぼします。待機スタックを調査して競合する同期オブジェクトを特定し、最適化を適用して競合を減らします。
考えられる問題
同期コンテキスト切り替えの平均待機時間が短いため、スレッド間で競合する過度の同期や、非効率なシステム API の使用を示す可能性があります。
インアクティブ時間
メトリックの説明
スレッドがシステムによってプリエンプトされ、インアクティブとなった時間を示します。
インアクティブ待機カウント
メトリックの説明
インアクティブ待機カウントは、同期またはプリエンプションのため OS のスケジューラーによって実行を除外されたスレッドのコンテキスト・スイッチの回数です。スレッドのコンテキスト・スイッチの回数が多すぎると、アプリケーションのパフォーマンスに悪影響を与えます。同期の競合を減らして同期のコンテキスト・スイッチを最小化するか、スレッドのオーバーサブスクリプションを排除してスレッドのプリエンプションを最小化します。
インアクティブ待機時間
メトリックの説明
インアクティブ待機時間は、スレッドがインアクティブのままで、同期またはプリエンプションのため OS スケジューラーによって実行から除外された時間です。アプリケーション実行のクリティカル・パスでの過度なインアクティブ待機時間は、低い CPU 利用率と相まって、アプリケーションの並列実行に悪影響を及ぼします。待機スタックを調査して競合する同期オブジェクトを特定し、最適化を適用して競合を減らします。
低い CPU 利用率のインアクティブ待機時間
メトリックの説明
インアクティブ待機時間は、スレッドがインアクティブのままで、同期またはプリエンプションのため OS スケジューラーによって実行から除外された時間です。アプリケーション実行のクリティカル・パスでの過度なインアクティブ待機時間は、低い CPU 利用率と相まって、アプリケーションの並列実行に悪影響を及ぼします。待機スタックを調査して競合する同期オブジェクトを特定し、最適化を適用して競合を減らします。
受信帯域幅依存
メトリックの説明
このメトリックは、インテル® Omni-Path ファブリックの髙い受信帯域幅利用率で費やされたシステムの経過時間のパーセントを示します。メトリックは理論上の最大ネットワーク帯域幅に基づいて計算され、最大帯域幅を減少させる可能性があるリンク・オーバーサブスクリプションなどの動的なネットワーク条件を考慮していないことに注意してください。
考えられる問題
受信ネットワークの高い帯域幅利用率が検出されました。これは通信時間の増加につながります。通信パターンを解析するにはインテル® Trace Analyzer & Collector を使用します。
受信パケットレート依存
メトリックの説明
このメトリックは、インテル® Omni-Path ファブリックの髙い受信パケットレートで費やされたシステム経過時間のパーセントを示します。パケットレート分布図を調査して問題を特定します。
考えられる問題
受信ネットワークの高いパケットレートが検出されました。これは通信時間の増加につながります。通信パターンを解析するにはインテル® Trace Analyzer & Collector を使用します。
命令のスタベーション
メトリックの説明
命令セットのサイズが大きい場合や、分岐予測ミスが多い場合は、L1I ミスなどのフロントエンドの命令供給ストールが発生します。このようなストールを命令スタベーションと呼びます。このメトリックは、フロントエンドですべてのサイクルに対して命令が発行されなかったサイクルの比率です。
考えられる問題
L1I ミスやその他の問題が原因でコードが供給されるのを待機するため、多くの CPU サイクルが消費されています。コードのワーキングセット、分岐予測ミス、および仮想関数の使用を減らす方法を検討します。
割り込み時間
I/O 待機時間
メトリックの説明
このメトリックは、システムにアイドル状態のコアがある場合に、スレッドが I/O 待機状態である時間を示します。
IPC
メトリックの説明
サイクルごとにリタイアした命令数 (IPC) はサイクルごとにリタイアした命令の平均数を示します。最近のスーパースカラー・プロセッサーは、1 サイクルあたり 4 つまでの命令を発行できるため、理論的な最良の IPC 値は 4 になります。さまざまな要因 (大きなレイテンシーのメモリー、浮動小数点操作、SIMD 操作、分岐予測ミスによりリタイアしない命令、フロントエンドの命令スタベーションなど) により、測定される IPC の値は低くなる傾向にあります。IPC が 1 の場合、HPC アプリケーションでは容認されますが、異なるアプリケーション分野の期待値はさまざまです。IPC はアプリケーションのパフォーマンス・チューニングの全体的な可能性を判断する優れたメトリックとして広く用いられています。
考えられる問題
IPC 値が低すぎます。これは、メモリーストール、命令スタベーション、分岐予測ミス、または長いレイテンシーの命令などに起因します。低い IPC の原因を特定するには、ほかのハードウェア関連のメトリックを調査します。
L1 依存
メトリックの説明
このメトリックは、マシンが L1 データキャッシュをミスせずにストールしている頻度を示します。L1 キャッシュのレイテンシーは通常最短です。しかし、先行するストアによってブロックされるロードにように、特定の状況では、L1 から提供される場合であってもロードは高いレイテンシーを被る可能性があります。
考えられる問題
このメトリックは、マシンが L1 データキャッシュをミスせずにストールしている頻度を示します。L1 キャッシュのレイテンシーは通常最短です。しかし、先行するストアによってブロックされるロードにように、特定の状況では、L1 から提供される場合であってもロードは高いレイテンシーを被る可能性があります。このメトリック値は、DTLB オーバーヘッドまたは 1 ポートを利用したサイクルの問題によりハイライトされる可能性があることに注意してください。
4K エイリアシング
メトリックの説明
このメトリックは、4K のアドレスオフセットを持つ先行するストア (プログラム順) によって、メモリー・ロード・アクセスが発生した頻度を予測します。誤った一致は、ロードの再発行で数サイクルを要する可能性があります。しかし、短期間での再発行は、アウトオブオーダー・コアと HW の最適化によって隠匿されます。そのため、階層の親ノード (L1_Bound など) に伝搬しない限り、このメトリックが高い値を示しても安全に無視できます。
考えられる問題
サイクルの大部分が、ロードとストア間の誤った 4K エイリアシングを処理するために費やされています。
ヒント
[ソース/アセンブリー] ビューを使用して、エイリアシングが発生するロードとストアを特定し、エイリアシングを排除するようにデータ配置を調整します。詳細は、『インテル® 64 および IA-32 プロセッサー・アーキテクチャー最適化リファレンス・マニュアル』を参照してください。
DTLB オーバーヘッド
メトリックの説明
x86 アーキテクチャーでは、仮想メモリーと物理メモリーのマッピングは、メモリーに保持されるページテーブルによって行われます。このテーブルへの参照を最小限にするため、ページテーブルの最近使用されたマッピング情報は、'トランスレーション・ルックアサイド・バッファー' (TLB) の階層にキャッシュされ、以降の仮想アドレス変換で参照されます。データキャッシュと同様に、要求が満たされるまでの距離が遠いほどパフォーマンスは低下します。このメトリックは、第 2 レベルのデータ TLB (STLB) のヒットと、STLB ミスでのハードウェア・ページ・ウォークの実行を含む、第 1 レベルのデータ TLB (DTLB) のミスに対するパフォーマンス・ペナルティーを予測します。
考えられる問題
かなりのサイクルが第 1 レベルデータ TLB ミスの処理に費やされています。
ヒント
1.通常のデータキャッシュと同様に、DTLB のオーバーヘッドを最小限に抑えるため、データの局所性を改善し、ワーキングセットのサイズを抑えることに注目します。
2.プロファイルに基づく最適化 (PGO) を使用して、頻繁に使用されるデータを同じページに配置します。
3.頻繁に使用される大量のデータには、大きなページサイズを検討します。
FB フル
メトリックの説明
このメトリックは、L1D フィルバッファーが利用できないために、追加の L1D ミス・メモリー・アクセス要求が制限された頻度を概算します。このメトリック値が高いと、深いメモリー階層レベルのミスが処理されたことを表します。多くの場合、帯域幅の上限 (L2 キャッシュ、L3 キャッシュ、または外部メモリー) に近づいていることを示唆します。
考えられる問題
このメトリックは、L1D フィルバッファーが利用できないために、追加の L1D ミス・メモリー・アクセス要求が制限された頻度を概算します。このメトリック値が高いと、深いメモリー階層レベルのミスが処理されたことを表します。多くの場合、帯域幅の上限 (L2 キャッシュ、L3 キャッシュ、または外部メモリー) に近づいていることを示唆します。メモリー帯域幅が制限される場合、ソフトウェア・プリフェッチを使用しないでください。
ストアフォワードでブロックされたロード
メトリックの説明
パイプラインのメモリー操作を合理化するため、ロードが読み取るデータを先行するストアがまだ書き込んでいる場合、ロードはメモリー待機を回避できます (「ストアフォワード」処理)。しかし、先行するストアがロードが読み取るメモリー幅よりも小さいデータを書き込んでいる場合など状況によっては、ストアフォワードが完了するまでかなりの時間ロードがブロックされます。このメトリックは、そのようなブロックされたロードのパフォーマンス・ペナルティーを測定します。
考えられる問題
ロードは、ストアフォワード中にサイクルの大部分でブロックされました。
ヒント
[ソース/アセンブリー] ビューを使用して、ブロックされたロードを特定して、問題のあるストアフォワードを見つけます。通常ストア命令はロードの前の 10 動的命令内にあります。ストアフォワードのデータ幅がロードよりも小さい場合、ストアとロードのデータ幅を同じにします。
ロック・レイテンシー
メトリックの説明
このメトリックは、ロック操作により CPU がキャッシュミスの処理に費やしたサイクルの割合を示します。これらは、マイクロアーキテクチャーがロックを処理するため、メモリーソースにかかわらず L1 依存として分類されます。
考えられる問題
ロック操作によるキャッシュミスの処理にかなりの CPU サイクルが費やされています。これらは、マイクロアーキテクチャーがロックを処理するため、メモリーソースにかかわらず L1 依存として分類されます。このメトリック値は、ストア・レイテンシーの問題によりハイライトされる可能性があることに注意してください。
分割ロード
メトリックの説明
メモリー階層全体で、データはキャッシュライン単位 (64 バイト) で移動します。これは、整数、単精度浮動小数点、または倍精度浮動小数点などの一般的なデータ型よりはるかに大きなサイズですが、これらのデータ型がアライメントされていないと、2 つのキャッシュラインにまたがって格納されることがあります。最近のインテル® アーキテクチャーでは、キャッシュ分割を処理するため分割レジスターを導入することで、'分割ロード' のパフォーマンスが大幅に向上していますが、分割ロードが多く分割レジスターが足りない場合など、依然として分割ロードが問題になることがあります。
考えられる問題
サイクルのほとんどが分割ロードに費やされています。
ヒント
64 バイトのキャッシュラインの粒度でデータをアライメントすることを検討してください。詳細は、『インテル® 64 および IA-32 プロセッサー・アーキテクチャー最適化リファレンス・マニュアル』を参照してください。
L1 ヒット率
メトリックの説明
L1 キャッシュは、メモリー階層の最初にある最短レイテンシーのレベルです。このメトリックは、ロード要求の総数に対する L1 キャッシュにヒットしたロード要求の比率を示します。
L1D 置換比率
メトリックの説明
キャッシュラインが L1 キャッシュに取り込まれると、ラインを置き換えるためキャッシュラインを排出する必要があります。アクティブに使用されるキャッシュラインが排出されると、データをキャッシュラインに繰り返し読み戻すことによりパフォーマンスの問題が生じる可能性があります。このメトリックは、各行に起因するすべての置換のパーセンテージを測定します。例えば、グループが '関数' に設定されている場合、このメトリックは各関数によるすべての置換の割合を示し、合計は 100% となります。
考えられる問題
これは、すべての L1 キャッシュ置換の大部分に相当します。一部の置換は避けられないものであり、高い頻度の置換は必ずしも問題の可能性を示すものではありません。特定のグループに対する大量の L1 キャッシュミスの原因を調査する場合にのみ、このメトリックを考慮します。これらの置換が問題としてマークされている場合、データ構造を再配置したり (例えば、使用頻度の低いデータを頻繁に使用されるデータから切り離して、未使用のデータがキャッシュを占有しないようにする)、排出される前に可能な限りデータを再利用するように操作の順番を変更します。
L1D 置換
メトリックの説明
L1D への置換を示します。
L1I ストールサイクル
メトリックの説明
共有メモリーマシンでは、命令とデータが同じメモリーアドレス空間に格納されます。だたし、パフォーマンス上の理由から別々にキャッシュされます。大きな命令セットや分岐予測ミス (仮想関数の多用によるものも含む) は L1I ミスを引き起こし、アプリケーションのパフォーマンスを大幅に低下させます。
考えられる問題
L1I にコードが供給されるのを待機するため、多くの CPU サイクルが消費されています。命令のスタベーション (枯渇) を引き起こすアプリケーションのコードを確認し、コードを再配置します。
L2 依存
メトリックの説明
このメトリックは、マシンが L2 キャッシュでストールしている頻度を示します。キャッシュミス (L1 ミス/L2 ヒット) を回避すると、レイテンシーが改善されパフォーマンスが向上します。
L2 ヒット依存
メトリックの説明
L2 は、メインメモリー (DRAM) や MCDRAM の手前にある、メモリー階層の最後の、そして最も長いレイテンシーのレベルです。L2 にヒットすると DRAM や MCDRAM にヒットするよりもはるかに高速に処理されますが、まだパフォーマンス上重要なペナルティーを被ります。このメトリックには、共有データに対する一貫性のペナルティーも含まれます。L2 ヒット依存メトリックは、すべてのサイクルに対する L2 ヒットの処理に費やされたサイクルの比率を示します。L2 ヒットを処理するサイクルは、L2 CACHE HIT COST * L2 CACHE HIT COUNT として計算され、ここで L2 CACHE HIT COST は典型的な L2 アクセス・レイテンシー (サイクル数) として測定された定数です。
考えられる問題
サイクルの大部分は、L1 にヒットしますが L1 にミスするデータフェッチに費やされます。このメトリックには、共有データに対する一貫性のペナルティーも含まれます。
ヒント
1.競合アクセスやデータ共有が問題であると思われる場合、それらを最初に対処します。それ以外は、L2 ミスするワークロードに適用される次のパフォーマンス・チューニングを検討します: データ・ワーキング・セットの縮小、データアクセスの局所性改善、分割して L1 に収めるワーキングセットのブロック化、またはハードウェア・プリフェッチャーを活用。
2.ソフトウェア・プリフェッチャーの使用を検討してください。ただし、通常のロードを妨げる可能性があり、レイテンシーが増加してメモリー・サブシステムへの負担が増えることに注意してください。
L2 ヒット率
メトリックの説明
L2 は、DRAM や MCDRAM の手前にある、メモリー階層の最後の、そして最も長いレイテンシーのレベルです。L2 にヒットすると DRAM や MCDRAM にヒットするよりもはるかに高速に処理されますが、まだパフォーマンス上重要なペナルティーを被ります。このメトリックは、L2 で処理されたすべてのロード要求に対して、L2 にヒットしたロード要求の比率を示します。このメトリックには命令のフェッチは含まれません。
考えられる問題
L2 は、DRAM や MCDRAM の手前にある、メモリー階層の最後の、そして最も長いレイテンシーのレベルです。L2 にヒットすると DRAM にヒットするよりもはるかに高速に処理されますが、まだパフォーマンス上重要なペナルティーを被ります。このメトリックは、L2 で処理されたすべてのロード要求に対して、L2 にヒットしたロード要求の比率を示します。このメトリックには命令のフェッチは含まれません。
L2 HW プリフェッチャー割り当て
メトリックの説明
HW プリフェッチャーによる L2 割り当て数を示します。
L2 入力要求
メトリックの説明
L2 割り当ての合計数。このメトリックは、要求ロードと HW プリフェッチャー要求の両方をカウントします。
L2 ミス依存
メトリックの説明
L2 は、メインメモリー (DRAM) や MCDRAM の手前にある、メモリー階層の最後の、そして最も長いレイテンシーのレベルです。すべての L2 メモリー要求ミスは、レイテンシーの長いローカルまたはリモート DRAM や MCDRAM によって処理されます。L2 ミス依存のメトリックは、すべてのサイクル数に対する L2 ミスの処理に費やされたサイクル数の比率を示します。L2 ミスを処理するサイクル数は、L2 CACHE MISS COST * L2 CACHE MISS COUNT として計算され、ここで L2 CACHE MISS COST は典型的な DRAM アクセス・レイテンシーのサイクル数として測定される定数です。
考えられる問題
L2 ロードミスが処理されるのを待機するには、高い CPU サイクル数が費やされます。
ヒント
1.データのワーキングセットを縮小し、データのアクセス局所性を向上させて L2 に収まるようにチャンク内のデータをブロック化して参照するか、ハードウェア・プリフェッチャーを効率良く活用します。
2.ソフトウェア・プリフェッチャーの使用を検討してください。ただし、通常のロードを妨げる可能性があり、レイテンシーが増加してメモリーシステムへの負担が増えることに注意してください。
L2 ミスカウント
メトリックの説明
L2 は、メインメモリー (DRAM) や MCDRAM の手前にある、メモリー階層の最後の、そして最も長いレイテンシーのレベルです。すべての L2 メモリー要求ミスは、レイテンシーの長いローカルまたはリモート DRAM や MCDRAM によって処理されます。L2 ミスカウントのメトリックは、L2 ミスした要求ロードの合計数を示します。HW プリフェッチャーによるミスは含まれません。
L2 置換比率
メトリックの説明
キャッシュラインが L2 キャッシュに取り込まれると、ラインを置き換えるためキャッシュラインを排出する必要があります。アクティブに使用されるキャッシュラインが排出されると、データをキャッシュラインに繰り返し読み戻すことによりパフォーマンスの問題が生じる可能性があります。このメトリックは、各行に起因するすべての置換のパーセンテージを測定します。例えば、グループが '関数' に設定されている場合、このメトリックは各関数によるすべての置換の割合を示し、合計は 100% となります。
考えられる問題
これは、すべての L2 キャッシュ置換の大部分に相当します。一部の置換は避けられないものであり、高い頻度の置換は必ずしも問題の可能性を示すものではありません。特定のグループに対する大量の L2 キャッシュミスの原因を調査する場合にのみ、このメトリックを考慮します。これらの置換が問題としてマークされている場合、データ構造を再配置したり (例えば、使用頻度の低いデータを頻繁に使用されるデータから切り離して、未使用のデータがキャッシュを占有しないようにする)、排出される前に可能な限りデータを再利用するように操作の順番を変更します。
L2 置換
メトリックの説明
L2 への置換を示します。
L3 依存
メトリックの説明
このメトリックは、CPU が L3 キャッシュでストールしたか、兄弟コアと競合した割合を示します。キャッシュミス (L2 ミス/L3 ヒット) を回避すると、レイテンシーが改善されパフォーマンスが向上します。
競合アクセス
メトリックの説明
競合アクセスは、あるスレッドによって書き込まれたデータが別のコアのスレッドによって読み取られる場合に発生します。競合アクセスには、ロックなどの同期、ロック変数の変更などの真のデータ共有、フォルス・シェアリングがあります。このメトリックは、すべてのサイクルに対してキャッシュシステムが競合アクセスを処理している間に生成されたサイクルの比率です。
考えられる問題
別のコアで更新されたキャッシュラインに対する多数の競合アクセスがあります。長いレイテンシーのロードイベント (例えば LLC ミス) の説明で提案される手法を導入するか、競合するアクセスを減らすことを検討してください。競合アクセスを減らすには、まずその原因を特定します。同期が原因であれば、同期の粒度を増やすことを考えてください。真のデータ共有であれば、データのプライベート化とリダクションを検討してください。データのフォルス・シェアリングが発生している場合は、変数を異なるキャッシュラインに配置するようにデータを再構築してください。パディングによってワーキングセットが増加するかもしれませんが、確実にフォルス・シェアリングを排除することができます。
データ共有
メトリックの説明
複数のスレッドによって共有されるデータ (読み取り共有のみ) は、キャッシュの一貫性のためアクセスレイテンシーが増加する可能性があります。このメトリックはコヒーレンシーの影響を測定します。データ共有が非常に多い場合は、マルチスレッドのパフォーマンスが大幅に低下します。このメトリックは、すべてのサイクルに対してキャッシュシステムで共有データの処理に費やされたサイクルの比率です。解析によって測定される変数の競合による待機は測定されません。
考えられる問題
異なるコアによる過度のデータ共有が検出されました。
ヒント
1.競合アクセスメトリックを調査し、原因が競合アクセスであるか単純な読み取りであるかを判断します。読み取り共有は、競合アクセス、LLC ミスおよびリモートアクセスなどの問題よりも優先順位は低くなります。
2.単純な読み取り共有がパフォーマンスのボトルネックである場合、スレッド間のデータ配置や計算の再配置を検討してください。しかし、このようなチューニングは容易ではないかもしれません。また、それによりさらに重大なパフォーマンス上の問題を引き起こす可能性があります。
L3 レイテンシー
メトリックの説明
このメトリックは、負荷がかかるシナリオ (L3 レイテンシーの制限による可能性) で L3 キャッシュにヒットする要求ロードアクセスのサイクル数の割合を示します。プライベート・キャッシュミス (L2 ミス/L3 ヒット) を避けることで、レイテンシーを改善し、兄弟物理コア間の競合を減らして、パフォーマンスを向上します。このノードの値は、兄弟コア間で重複する可能性があることに注意してください。
LLC ヒット
メトリックの説明
LLC (最終レベルキャッシュ) は、メインメモリー (DRAM) の手前にある、メモリー階層の最後の、そして最も長いレイテンシーのレベルです。LLC にヒットすると DRAM にヒットするよりもはるかに高速に処理されますが、まだパフォーマンス上重要なペナルティーを被ります。このメトリックには、共有データに対する一貫性のペナルティーも含まれます。
考えられる問題
サイクルの大部分は、LLC にヒットしますが L2 にミスするデータフェッチに費やされます。このメトリックには、共有データに対する一貫性のペナルティーも含まれます。
ヒント
1.競合アクセスやデータ共有が問題であると思われる場合、それらを最初に対処します。それ以外は、LLC ミスするワークロードに適用される次のパフォーマンス・チューニングを検討します: データ・ワーキング・セットの縮小、データアクセスの局所性改善、ワーキングセットをブロック化または分割して低レベルのキャッシュに収める、またはハードウェア・プリフェッチャーを活用します。
2.ソフトウェア・プリフェッチャーの使用を検討してください。ただし、通常のロードを妨げる可能性があり、レイテンシーが増加してメモリー・サブシステムへの負担が増えることに注意してください。
SQ フル
メトリックの説明
このメトリックは、すべての要求タイプと両方のハードウェア SMT スレッドを考慮して、スーパーキュー (SQ) が一杯になったサイクルの割合を測定します。スーパーキューは、L2 キャッシュへのアクセス要求、またはアンコアへの要求に使用されます。
リモート DRAM によって処理された LLC ロードミス
メトリックの説明
NUMA (Non-Uniform Memory Architecture) マシンでは、LLC メモリー要求ミスはローカルまたはリモート DRAM によって処理されます。リモート DRAM へのメモリー要求では、ローカル DRAM への要求よりも長いレイテンシーが発生します。頻繁にアクセスするデータはできるだけローカルに保持しておくことを推奨します。このメトリックは、すべてのサイクルに対してリモート DRAM により LLC ロードミスの処理にかかったサイクルの比率です。
考えられる問題
リモート DRAM からのメモリー要求の処理には、かなりの時間がかかります。可能であれば、同一コア、または少なくとも同じパッケージに割り当てられているデータを使用するようにしてください。
LLC ミスカウント
メトリックの説明
LLC (最終レベルキャッシュ) は、メインメモリー (DRAM) の手前にある、メモリー階層の最後の、そして最も長いレイテンシーのレベルです。すべての LLC メモリー要求ミスは、レイテンシーの長いローカルまたはリモート DRAM によって処理されます。LLC ミスカウントのメトリックは、LLC ミスした要求ロードの合計数を示します。HW プリフェッチャーによるミスは含まれません。
LLC 置換比率
メトリックの説明
キャッシュラインがラスト・レベル・キャッシュに取り込まれると、ラインを置き換えるためキャッシュラインを排出する必要があります。アクティブに使用されるキャッシュラインが排出されると、データをキャッシュラインに繰り返し読み戻すことによりパフォーマンスの問題が生じる可能性があります。このメトリックは、各行に起因するすべての置換のパーセンテージを測定します。例えば、グループが '関数' に設定されている場合、このメトリックは各関数によるすべての置換の割合を示し、合計は 100% となります。
考えられる問題
これはすべてのラスト・レベル・キャッシュ置換の大部分に相当します。一部の置換は避けられないものであり、高い頻度の置換は必ずしも問題の可能性を示すものではありません。特定のグループに対する大量のラスト・レベル・キャッシュ・ミスの原因を調査する場合にのみ、このメトリックを考慮します。これらの置換が問題としてマークされている場合、データ構造を再配置したり (例えば、使用頻度の低いデータを頻繁に使用されるデータから切り離して、未使用のデータがキャッシュを占有しないようにする)、排出される前に可能な限りデータを再利用するように操作の順番を変更します。
LLC 置換
メトリックの説明
LLC への置換を示します。
ローカル DRAM アクセスカウント
メトリックの説明
このメトリックは、ローカルメモリーで処理された LLC ミスの合計数を示します。HW プリフェッチャーによるミスは含まれません。
論理コア利用率
メトリックの説明
このメトリックは、アプリケーションがどの程度効率的に CPU を利用しているかを示し、アプリケーションの並列効率を評価するのに役立ちます。システム上のすべての論理 CPU による平均 CPU 利用率をパーセントで示します。
ループ・エントリー・カウント
メトリックの説明
外部からループに到達した回数の統計的予測を示します。このメトリックの値は、コールスタック・フィルター・モードごとには集計されません。
(情報) LSD の適用
メトリックの説明
このメトリックは、LSD (ループストリーム検出またはループキャッシュ) によって供給された uOps の割合を表します。
マシンクリア
メトリックの説明
ある種のイベントは、パイプライン全体をクリアして、最後にリタイアした命令の直後から再開する必要があります。このメトリックは、メモリー順序違反、自己修正コード、不正アドレス範囲へのロードの 3 つのイベントを測定します。マシンクリアのメトリックは、マシンクリアによって CPU が無駄にしたスロットの割合を表します。これらのスロットは、クリア前にフェッチされた uOp によって浪費されるか、クリア後にマシンのアウトオブオーダー機能が状態をリカバリーする場合にストールします。
考えられる問題
実行時間の大部分がマシンクリア処理に費やされています。
ヒント
MACHINE_CLEARS イベントを調べて原因を特定します。詳細は、『インテル® 64 および IA-32 プロセッサー・アーキテクチャー最適化リファレンス・マニュアル』の「メモリー・ディスアンビゲーション」を参照してください。
最大 DRAM シングルパッケージ帯域幅
メトリックの説明
収集開始前にマイクロベンチマークを実行してシングルパッケージで測定された最大 DRAM 帯域幅。収集開始時にシステムにアクティブな負荷がかかっている場合 (例えば、アタッチモードで)、値はそれほど正確ではありません。
最大 DRAM システム帯域幅
メトリックの説明
収集開始前にマイクロベンチマークを実行してシステム全体 (パッケージ全体) で測定された最大 DDR 帯域幅。収集開始時にシステムにアクティブな負荷がかかっている場合 (例えば、アタッチモードで)、値はそれほど正確ではありません。
MCDRAM 帯域幅依存
メトリックの説明
このメトリックは、高い MCDRAM 帯域幅利用率で費やされたシステムの経過時間のパーセンテージを示します。帯域幅利用率の分布図を確認して問題の規模を予測します。
考えられる問題
システムは、高い MCDRAM 帯域幅利用率で、かなりのパーセンテージの経過時間を費やしています。帯域幅利用率の分布図を確認して問題の規模を予測します。データの局所性と L1/L2 キャッシュの再利用を改善します。
MCDRAM キャッシュ帯域幅依存
メトリックの説明
このメトリックは、高い MCDRAM キャッシュ帯域幅利用率で費やされたシステムの経過時間をパーセンテージで示します。帯域幅利用率の分布図を確認して問題の規模を予測します。
考えられる問題
システムは、高い MCDRAM キャッシュ帯域幅利用率で、かなりのパーセンテージの経過時間を費やしています。帯域幅利用率の分布図を確認して問題の規模を予測します。データの局所性と L1/L2 キャッシュの再利用を改善してください。
MCDRAM フラット帯域幅依存
メトリックの説明
このメトリックは、高い MCDRAM フラット帯域幅利用率で費やされたシステムの経過時間をパーセンテージで示します。帯域幅利用率の分布図を確認して問題の規模を予測します。
考えられる問題
システムは、高い MCDRAM フラット帯域幅利用率で、かなりのパーセンテージの経過時間を費やしています。帯域幅利用率の分布図を確認して問題の規模を予測します。データの局所性を高めたり、計算集約型のコードを帯域幅集約型のコードとマージすることを検討してください。
メモリー帯域幅
メトリックの説明
このメトリックは、メインメモリー (DRAM) の帯域幅の限界に近づいたため、アプリケーションがストールする可能性があるサイクル数の割合を示します。このメトリックは、ほかのスレッド/コア/ソケットからの要求を収集しません (それらについては、アンコアカウンターを参照)。NUMA マルチソケット・システムのデータの局所性を改善してください。
考えられる問題
メインメモリー (DRAM) の帯域幅限界に近づいたためサイクルの大部分がストールしました。
ヒント
導入可能な手法により、データアクセスを改善してメモリーとのキャッシュライン転送を減らします。
排出される前に各キャッシュラインのすべてのバイトを使用します (例えば、構造体要素の順番を変更して、利用されない要素を隔離するなど)。
計算依存のループと帯域幅依存のループを融合します。
マルチソケット・システムでは NUMA 最適化を行います。
注
ソフトウェア・プリフェッチャーは、帯域幅依存のアプリケーションには有効ではありません。
メモリー依存
メトリックの説明
このメトリックは、メモリー・サブシステムの問題がパフォーマンスに及ぼす影響を示します。メモリー依存は、ロードやストア命令によってパイプラインがストールする可能性があるスロットの割合を測定します。これは、ストアがパイプラインを圧迫する特殊ケースに加えて、実行のスタベーションと同時に生じる不完全なインフライトのメモリー要求ロードにより生じます。
考えられる問題
メトリック値が高いです。これは、実行パイプライン・スロットのかなりの部分が、メモリーロードやストアによりストールする可能性があることを示します。メモリーアクセス解析を使用して、メモリー階層、メモリー帯域幅情報、メモリー・オブジェクトの相関関係別のメトリックの内訳を調査します。
DRAM 依存
メトリックの説明
このメトリックは、CPU がメインメモリー (DRAM) でストールしている割合を示します。一般に、キャッシュを使用することでレイテンシーが改善され、パフォーマンスが向上します。
DRAM 帯域幅依存
メトリックの説明
このメトリックは、高い DRAM 帯域幅利用率で費やされたシステムの経過時間のパーセントを示します。このメトリックは正確なピークシステム DRAM 帯域幅の測定値に依存しているため、帯域幅利用率の分布図を調査して、低/中/高の利用率しきい値がシステムに対して適切であること確認してください。必要に応じて、手動で調整できます。
考えられる問題
システムは高い DRAM 帯域幅利用率で多くの時間を費やしました。導入可能な手法により、データアクセスを改善してメモリーとのキャッシュライン転送を減らします。1) キャシュラインが追い出される前にすべてのバイトを使用します (例えば、構造体の要素を並べ替え、使用頻度が少ないものを分離します)。2) 計算集約型のループと帯域幅集約型のループをマージします。3) マルチソケット・システムでは NUMA 最適化を行います。注: ソフトウェア・プリフェッチャーは、帯域幅により制限されるアプリケーションには有効ではありません。可能であれば、メモリーアクセス解析を実行して、高帯域幅メモリー (HBW) に割り当てられるデータを識別します。
UPI 利用率依存
メトリックの説明
このメトリックは、髙い UPI 利用率で費やされたシステムの経過時間のパーセンテージを示します。帯域幅利用率の分布図を調査して、低/中/高の利用率しきい値がシステムに対して適切であること確認してください。必要に応じて、手動で調整できます。
注
UPI 利用率メトリックは、インテル® マイクロアーキテクチャー開発コード名 Skylake ベースのシステムで QPI 利用率に代わるものです。
考えられる問題
システムは UPI 帯域幅を過度に消費しました。複数ソケットシステムで NUMA 最適化によりデータアクセスを改善します。
メモリー・レイテンシー
メトリックの説明
このメトリックは、メインメモリー (DRAM) のレイテンシーのため、アプリケーションがストールする可能性があるサイクル数の割合を示します。このメトリックは、ほかのスレッド/コア/ソケットからの要求を収集しません (それらについては、アンコアカウンターを参照)。データ配置を最適化するか、ソフトウェア・プリフェッチ (コンパイラーを介して) の使用を検討してください。
考えられる問題
このメトリックは、メインメモリー (DRAM) のレイテンシーのため、アプリケーションがストールする可能性があるサイクル数の割合を示します。
ヒント
データ配置の再構成やソフトウェア・プリフェッチ (コンパイラーを介して) など、利用可能な方法を適用して、データアクセスを改善するか、それらを計算とインターリーブします。
ローカル DRAM
メトリックの説明
このメトリックは、CPU がローカルメモリーからのロードでストールした頻度を示します。キャッシュすることでレイテンシーが改善され、パフォーマンスが向上します。
考えられる問題
ローカルメモリーからのロードで CPU ストール数がしきい値を超えています。データをキャッシュしてレイテンシーを改善し、パフォーマンスを向上することを検討してださい。
リモートキャッシュ
メトリックの説明
このメトリックは、ほかのソケットのリモートキャッシュからのロードで CPU がストールした頻度を示します。これは多くの場合、不適切な NUMA 割り当てによって発生します。
考えられる問題
リモートキャッシュからのロードで CPU ストール数がしきい値を超えています。これは多くの場合、不適切な NUMA メモリー割り当てによって発生します。
リモート DRAM
メトリックの説明
このメトリックは、CPU がリモートメモリーからのロードでストールした頻度を示します。これは多くの場合、不適切な NUMA 割り当てによって発生します。
考えられる問題
リモートメモリーからのロードで CPU ストール数がしきい値を超えています。これは多くの場合、不適切な NUMA メモリー割り当てによって発生します。
NUMA: リモートアクセスの %
メトリックの説明
NUMA (Non-Uniform Memory Architecture) マシンでは、LLC メモリー要求ミスはローカルまたはリモート DRAM によって処理されます。リモート DRAM へのメモリー要求では、ローカル DRAM への要求よりも長いレイテンシーが発生します。メトリックは、リモートアクセスのパーセンテージを表します。可能な限り、このメトリックを低く維持し、頻繁にアクセスされるデータをローカルに保ちます。このメトリックは、リモートキャッシュで処理されるメモリーアクセスを考慮しません。
考えられる問題
大量の DRAM ロードがリモート DRAM で処理されています。可能であれば、同一コア、または少なくとも同じパッケージに割り当てられているデータを使用するようにしてください。
メモリー効率
メトリックの説明
このメトリックは、アプリケーションによって使用されるメモリー・サブシステムの効率を示します。これは、要求ロードやストア命令によりパイプラインがストールしていないサイクルのパーセントを示します。メトリックはメモリー依存の測定をベースにしています。
マイクロアーキテクチャー使用率
メトリックの説明
マイクロアーキテクチャー使用率のメトリックは、コードが現在のマイクロアーキテクチャー上でどの程度効率的に実行されているか (% で) 予測する主な指標です。さまざまな要因 (長いレイテンシーのメモリー、浮動小数点操作、SIMD 操作、分岐予測ミスによりリタイアしない命令、フロントエンドの命令スタベーションなど) が、マイクロアーキテクチャーの使用に影響します。
考えられる問題
このプラットフォームではコードの効率が低すぎます。
これは、メモリーストール、命令スタベーション、分岐予測ミス、または長いレイテンシーの命令などに起因します。
ヒント
低いマイクロアーキテクチャー使用効率の原因を特定するため、マイクロアーキテクチャー全般解析を実行します。
マイクロコード・シーケンサー
メトリックの説明
このメトリックは、CPU がマイクロコード・シーケンサー (MS) ROM によってフェッチされた uOps をリタイアするスロットの割合を示します。MS は、デフォルトのデコーダーによって完全にデコードされない CISC 命令 (文字列移動の繰り返しなど)、または (浮動小数点アシストなど) 特定の動作モードに対処するマイクロコード・アシストによって使用されます。
考えられる問題
マイクロコード・シーケンサーによってフェッチされた uOps のリタイアに、かなりのサイクルが費やされました。
ヒント
1. /arch コンパイラー・オプションが適切であることを確認してください。
2. 子アシストメトリックを調査して、問題としてハイライトされている場合は、提示される推奨事項に従います。
MS スイッチの問題により、このメトリック値がハイライトされる可能性があることに注意してください。
リステア予測ミス
メトリックの説明
このメトリックは、実行ステージの分岐予測ミスによる分岐リステアが原因で CPU がストールしたサイクルの割合を測定します。
考えられる問題
実行ステージの分岐予測ミスによる分岐リステアにより、かなりのサイクルがストールしている可能性があります。
MO マシンクリア・オーバーヘッド
メトリックの説明
ある種のイベントは、パイプライン全体をクリアして、最後にリタイアした命令の直後から再開する必要があります。このメトリックは、メモリーの順序付けによるマシンクリアのオーバーヘッドを予測します。メモリーの順序付け (MO) マシンクリアは、別のプロセッサーからのスヌープ要求が、パイプライン内のデータ操作のソースと一致した場合にも発生します。この場合、進行中のロードやストアがリタイアする前にパイプラインはクリアされます。その後、パイプラインは直前にリタイアした命令から再開され、コア内またはコア間で、ロードやストアのメモリー順序付けを維持します。メモリー順序付けの問題は、インテル® アーキテクチャー・ベースのすべてのプロセッサーで深刻なペナルティーを引き起こします。
考えられる問題
実行時間の大部分が、メモリー順序付けを処理するためマシンクリアに費やされています。これを避けるには、ロードとストア命令 (特にロードとストアがデータを共有する場合) を並べ替えるか、共有要件を減らします。
MPI の負荷インバランス
メトリックの説明
MPI インバランスは、ランク数で正規化された、通信操作の待機でスピンするランクによって費やされた CPU 時間を示します。高いメトリック値は、ランク間のアプリケーション・ワークロードのインバランス、適切でない通信スキーマや MPI ライブラリーの設定による可能性があります。インテル® Trace Analyzer & Collector を使用して、非効率な通信に関する情報を調査してください。
クリティカル・パス上の MPI ランク
メトリックの説明
このセクションには、ノード上のアプリケーション実行のクリティカル・パスにある最小 MPI ビジー待機時間を持つランクのメトリックが含まれています。このランクの CPU 利用効率を調査してください。
MS エントリー
メトリックの説明
このメトリックは、マイクロコード・シーケンサーのエントリーによる損失サイクルの割合を予測します。
考えられる問題
マイクロコード・シーケンサーのエントリーにより、かなりの CPU サイクルが損失しました。
MUX 信頼性
メトリックの説明
このメトリックは、HW イベント関連のメトリックの信頼性を予測します。収集された HW イベント数がカウンターの上限を超えたため、インテル® VTune™ プロファイラーはイベントの多重化 (MUX) を使用して HW カウンターを共有して、時間経過で異なるイベントのサブセットを収集します。これは収集されたイベントデータの精度に影響します。このメトリックの理想的な値は 1 です。この値が 0.7 より小さい場合、収集されたデータは信頼できない可能性があります。
考えられる問題
収集されたハードウェア・イベント・データの精度は十分ではありません。メトリックデータの信頼性が低い可能性があります。アプリケーションの実行時間を長くしたり、イベントの多重化の代わりに複数実行モードを使用したり、もしくは HW イベントを限定したカスタム解析を作成することを検討してください。ドライバーを使用しない収集を行っている場合、/sys/bus/event_source/devices/cpu/perf_event_mux_interval_ms ファイルの値を減らしてください。
注
このメトリックの値が高いと、ハードウェア・ベースのメトリックの精度は保証されません。ただし、値が低くても問題があります、そのため [複数実行を許可] オプションを使用するか、精度を上げるため実行時間を増やして解析を再度実行する必要があります。
OpenMP* 解析: 収集時間
メトリックの説明
収集時間は、ポーズ時間を除く収集の開始から終了までのウォールクロック時間です。
OpenMP* 領域時間
メトリックの説明
OpenMP* 領域時間はすべての構造領域インスタンスの持続期間です。
その他
メトリックの説明
このメトリックは、CPU が実行した浮動小数点 (FP) 以外の uOp の割合を示します。アプリケーションが FP 操作を行っていない場合、これが最大の原因であると考えられます。
送信帯域幅依存
メトリックの説明
このメトリックは、インテル® Omni-Path ファブリックの髙い送信帯域幅利用率で費やされたシステムの経過時間のパーセントを示します。メトリックは理論上の最大ネットワーク帯域幅に基づいて計算され、最大帯域幅を減少させる可能性があるリンク・オーバーサブスクリプションなどの動的なネットワーク条件を考慮していないことに注意してください。
考えられる問題
送信ネットワークの高い帯域幅利用率が検出されました。これは通信時間の増加につながります。通信パターンを解析するにはインテル® Trace Analyzer & Collector を使用します。
送信パケットレート依存
メトリックの説明
このメトリックは、インテル® Omni-Path ファブリックの髙い送信パケットレートで費やされたシステム経過時間のパーセントを示します。パケットレート分布図を調査して問題を特定します。
考えられる問題
送信ネットワークの高いパケットレートが検出されました。これは通信時間の増加につながります。通信パターンを解析するにはインテル® Trace Analyzer & Collector を使用します。
オーバーヘッド時間
メトリックの説明
オーバーヘッド時間は、システム同期 API、インテル® oneAPI スレッディング・ビルディング・ブロック(oneTBB )、および OpenMP* などの同期およびスレッド化ライブラリーで費やされた CPU 時間です。
考えられる問題
CPU 時間の大部分が同期またはスレッドのオーバーヘッドで費やされています。タスクの粒度またはデータ同期のスコープを増やすことを検討してください。
ページウォーク
メトリックの説明
x86 アーキテクチャーでは、仮想メモリーと物理メモリーのマッピングは、メモリーに保持されるページテーブルによって行われます。このテーブルへの参照を最小限にするため、ページテーブルの最近使用されたマッピング情報は、'トランスレーション・ルックアサイド・バッファー' (TLB) の階層にキャッシュされ、以降の仮想アドレス変換で参照されます。データキャッシュと同様に、要求が満たされるまでの距離が遠いほどパフォーマンスは低下します。このメトリックは、第 2 レベルのデータ TLB (STLB) のヒットと、STLB ミスでのハードウェア・ページ・ウォークの実行を含む、第 1 レベルの TLB のミスに対するパフォーマンス・ペナルティーを予測します。
考えられる問題
ページウォークは、複数のメモリー位置にアクセスして物理アドレスを計算する必要があるため、パフォーマンスが大幅に低下します。このメトリックには、命令 TLB ミスとデータ TLB ミスの両方を処理するサイクルが含まれているため、ITLB オーバーヘッドと DTLB オーバーヘッドを参照して、手順に従ってパフォーマンスを改善してください。また、さらに詳しく調査するため、[ソース/アセンブリー] ビューの PAGE_WALKS.D_SIDE_CYCLES と PAGE_WALKS.I_SIDE_CYCLES イベントを参照します。スキッドを考慮します。
並列領域時間
メトリックの説明
並列領域時間は、すべての並列構造領域のすべてのインスタンスの合計持続期間です。収集時間をベースとしたパーセント値で表されます。
ポーズ時間
メトリックの説明
ポーズ時間は、解析が GUI、CLI コマンド、またはユーザー API によってポーズされた経過時間を示します。
パーシステント・メモリー幅依存
メトリックの説明
このメトリックは、インテル® Optane™ DC パーシステント・メモリーからのロードで CPU がストールする頻度を推測します。このメトリックは、インテル® Optane™ DC パーシステント・メモリーのアプリケーション・ダイレクト・モードを備えたマシンで定義されます。
パイプライン・スロット
メトリックの説明
パイプライン・スロットは、1 つのマイクロオペレーションを操作するために必要なハードウェア・リソースを表します。
トップダウン特性化では、それぞれの CPU コアには、各クロックサイクルで利用可能ないくつかのパイプライン・スロットがあると仮定します。この数はパイプラインの幅と呼ばれます。
OpenMP* 潜在的なゲイン
メトリックの説明
潜在的なゲインは、実行時のオーバーヘッドがないと仮定して、OpenMP* 領域のロード・インバランスがないように最適化されている場合に短縮可能な最大時間を示します (並列領域時間 - 領域の理想的な時間)。潜在的なゲインが大きい場合、この領域のワークロードが十分でループのスケジュールが最適であることを確認してください。
インテル® VTune™ プロファイラーは、次の方法論によりスレッド数で正規化された非効率性の合計である [潜在的なゲイン] メトリックを計算します。
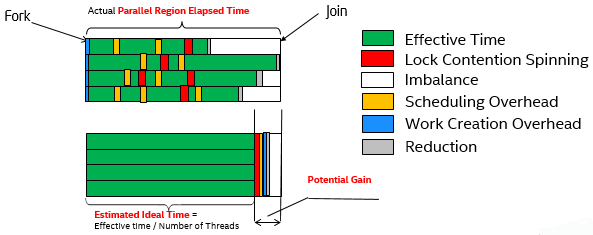
考えられる問題
ロード・インバランスや並列ワークの調整に浪費される時間が大きいと、アプリケーションのパフォーマンスとスケーラビリティーに悪影響を及ぼします。最大のメトリック値を持つ OpenMP* 領域を探します。領域のワークロードが十分で、ループのスケジュールが最適であることを確認してください。
インバランス
メトリックの説明
OpenMP* インバランスの潜在的なゲインは、OpenMP* 構造がバランスよく最適化された場合に節約できる最大経過時間を示します。これは、バリアでスピンしているすべての OpenMP* スレッドを OpenMP* スレッド数で割った CPU 時間のサマリーとして計算されます。
考えられる問題
並列領域内の OpenMP* バリアでの待機時間が極端に長い場合、ロード・インバランスに起因する可能性があります。必要に応じて、動的ワーク・スケジュールを使用して、インバランスを軽減することを検討してください。
ロック競合
メトリックの説明
OpenMP* ロック競合の潜在的なゲインは、OpenMP* ロックと順序付けの同期の経過時間コストを示します。高いメトリック値は、過度に競合する同期オブジェクトと非効率な並列処理の可能性を示します。過度な同期を避けるには、可能であればリダクション、アトミック操作、またはスレッドローカル変数を使用することを検討してください。このメトリックは、CPU サンプリングをベースとし、受動的な待機は含みません。
考えられる問題
並列領域内で同期オブジェクトが使用されると、スレッドは共有リソースにアクセスするためほかのスレッドと競合し、ロックの解放を待機するため CPU 時間を費やす可能性があります。可能であれば、リダクションやアトミック操作を使用して同期を減らすか、クリティカル・セクション内で実行されるコードを最小限に抑えます。
誤った事前デコード
メトリックの説明
このメトリックは、デコーダーが誤った命令長を予測したことで失われたサイクルの割合を予測します。
考えられる問題
デコーダーが誤った命令長を予測したため、かなりの CPU サイクルが失われています。
リモート・キャッシュ・アクセス・カウント
メトリックの説明
このメトリックは、別のソケットのリモートキャッシュで処理された LLC ミスの合計数を示します。HW プリフェッチャーによるミスは含まれません。
リモート DRAM アクセスカウント
メトリックの説明
このメトリックは、リモートメモリーで処理された LLC ミスの合計数を示します。HW プリフェッチャーによるミスは含まれません。
リモート / ローカル DRAM 比率
メトリックの説明
NUMA (Non-Uniform Memory Architecture) マシンでは、LLC メモリー要求ミスはローカルまたはリモート DRAM によって処理されます。リモート DRAM へのメモリー要求では、ローカル DRAM への要求よりも長いレイテンシーが発生します。頻繁にアクセスするデータはできるだけローカルに保持しておくことを推奨します。このメトリックは、ローカル DRAM ロードに対するリモート DRAM ロードの比率によって定義されます。
考えられる問題
大量の DRAM ロードがリモート DRAM で処理されています。可能であれば、同一コア、または少なくとも同じパッケージに割り当てられているデータを使用するようにしてください。
リタイアストール
メトリックの説明
このメトリックは、すべてのサイクルに対してマイクロオペレーションがリタイアされなかったサイクルの比率です。パフォーマンス問題、長いレイテンシー操作、依存関係チェーンなどがない場合、リタイアストールはあまり問題になりません。そうでない場合は、パフォーマンスが低下します。
考えられる問題
多数のリタイアストールが検出されました。これは、分岐予測ミス、命令スタベーション、長いレイテンシーの命令、およびその他の問題によって発生する可能性があります。このメトリックを使用して命令がストールした場所を検出します。問題が特定できたら、LLC ミス、実行ストール、リモートアクセス、データ共有、およびアクセス競合などのメトリックを解析するか、除算や文字列操作などの長いレイテンシーの命令を探して原因を理解します。
リタイア
メトリックの説明
リタイアメトリックは、有用なワークによって利用されるパイプライン・スロットの割合を表します。これは、最終的にリタイアする発行済みの uOps を意味します。理想的には、すべてのパイプライン・スロットはリタイアカテゴリーに属します。100% のリタイアは、サイクルあたりにリタイア可能な最大 uOps 数に達したことを示します。リタイアを最大化すると、通常、サイクルあたりの命令数 (IPC) メトリックが増加します。高いリタイア値は、必ずしもパフォーマンス向上の余地がないことを意味しないことの注意してください。例えば、マイクロコード・アシストはリタイアに分類されます。これはパフォーマンスに影響しますが、避けることができます。
考えられる問題
パイプライン・スロットの大部分が有用なワークで利用されました。
ヒント
このメトリック値を可能な限り大きくすることが目標ですが、ベクトル化されていないコードのリタイア値が高い場合は、コードのベクトル化を考慮してください。ベクトル化することにより、命令数を大幅に増やすことなく、より多くの計算を実行できるためパフォーマンスが向上します。このメトリック値は、マイクロコード・シーケンサー (MS) の問題により強調表示される可能性があるため、MS の使用を避けることでパフォーマンスを向上できます。
セルフ時間と合計時間
セルフ時間
セルフ時間は特定のプログラム単位内で費やされた時間です。例えば、ソース行のセルフ時間は、特定のソース行でアプリケーションが費やした時間を示します。セルフ時間は、関数がプログラムに及ぼす影響を理解するのに役立ちます。単一の関数の影響を調査することは、ボトムアップ解析とも呼ばれます。
例えば、待機時間が無視できるシングルスレッドのプログラムで、関数 foo() のセルフ時間がプログラムの CPU 時間の 10% であるとします。この場合、foo() を 2 倍高速に最適化すると、プログラムの経過時間は 5% 向上します。
並列アプリケーションの経過時間に対するセルフ時間の影響は、スレッドごとの利用率によって異なります。特定の関数の実行時間をほぼゼロまで最適化しても、アプリケーションの経過時間に影響しないこともあります。
合計時間
合計時間は、プログラム単位の累積時間です。関数の合計時間には、関数自体のセルフ時間と、その関数から呼び出されるすべての関数のセルフ時間が含まれます。合計時間は、アプリケーションで費やされる時間の概要を理解するのに役立ちます。関数呼び出しと関数の影響を調査することは、トップダウン解析とも呼ばれます。
シリアル CPU 時間
メトリックの説明
シリアル CPU 時間は、収集中にマスタースレッドの OpenMP* 並列領域外でアプリケーションが費やした CPU 時間です (並列領域外のシリアル時間と比較されます)。アプリケーションの収集時間とスケーリングに直接影響します。この値が高いと、コードの最適化やアルゴリズムのチューニングによって解決すべきパフォーマンスの問題があることを示します。
MPI ビジー待機時間
メトリックの説明
MPI ビジー待機時間は、MPI ランタイム・ライブラリーが通信操作で待機のためスピンしている CPU 時間です。高いメトリック値は、ランク間の負荷インバランス、アクティブな通信、または MPI ライブラリーの不適切な設定による可能性があります。インテル® Trace Analyzer & Collector を使用して、非効率な通信に関する情報を調査してください。
考えられる問題
MPI 通信操作の待機に費やされる CPU 時間が極端に多い場合、アプリケーションのパフォーマンスとスケーラビリティーに悪影響を与える可能性があります。これは、ランク間のロード・インバランス、アクティブな通信、または MPI ライブラリーの不適切な設定による可能性があります。インテル® Trace Analyzer & Collector を使用して、非効率な通信に関する情報を調査してください。
シリアル時間 (並列領域外)
メトリックの説明
シリアル時間は、パフォーマンス・データの収集中にマスタースレッドの OpenMP* 並列領域外でアプリケーションが費やした時間です。アプリケーションの収集時間とスケーリングに直接影響します。この値が高いと、コードの最適化やアルゴリズムのチューニングによって解決すべきパフォーマンスの問題があることを示します。
考えられる問題
アプリケーションのシリアル時間が長くなっています。これはアプリケーションの経過時間とスケーラビリティーに直接影響します。アプリケーションのシリアル領域の並列化、アルゴリズムまたはマイクロアーキテクチャーのチューニング・オプションを調査します。
SIMD アシスト
メトリックの説明
SIMD アシストは、インテル® MMX® テクノロジーのコードが浮動小数点スタック内の MMX 状態を変更した後に、EMMS 命令が実行されると呼び出されます。EMMS 命令は、すべての MMX テクノロジー・プロシージャーやサブルーチンの終わりに、および MMX と X87 命令が混在する場合にパフォーマンス・ペナルティーを招く可能性がある X87 浮動小数点命令を実行する他のプロシージャーやサブルーチンを呼び出す前に、MMX テクノロジーの状態をクリアします。SIMD アシストは、DAZ (Denormals Are Zeros) がオフで入力がデノーマル値の場合、または FTZ (Flush To Zero) フラグがオフで結果がアンダーフローする場合に、インテル® ストリーミング SIMD 拡張命令 (インテル® SSE) で必要となります。
考えられる問題
実行時間の大部分が SIMD アシストで費やされています。コンパイル時に DAZ (Denormals Are Zero) や FTZ (Flush To Zero) オプションを有効にして、デノーマル値をゼロにフラッシュします。デノーマル値がアプリケーションの動作に影響を与えない場合、このオプションでパフォーマンスが向上することがあります。DAZ と FTZ モードは IEEE 標準 754 と互換性がないことに注意してください。
SIMD 計算からの L1 アクセス比率
メトリックの説明
このメトリックは、メモリーロードの総数に対する SIMD 計算命令の比率を表します。各メモリーロードは最初に L1 キャッシュをアクセスします。計算リソースを効率的に使用するには、この比率が大きいことが重要です。
SIMD 計算からの L2 アクセス比率
メトリックの説明
このメトリックは、L2 キャッシュにヒットするメモリーロードの総数に対する SIMD 計算命令の比率を表します。計算リソースを効率的に使用するには、この比率が大きいことが重要です。
サイクルごとの SIMD 命令
メトリックの説明
このメトリックは、プログラムがどの程度 FPU に依存しているかを示します。100% の値は、FPU に完全な負荷がかかり、アプリケーション実行の各サイクルで全能力を活用してベクトル命令がリタイアしていることを意味します。
低速 LEA ストール
メトリックの説明
いくつかの LEA 命令 (特に 3 オペランドの LEA 命令) は、ほかの LEA 命令と比較してレイテンシーが長く、ディスパッチ・ポートの選択肢が少なくなります。このメトリックは、そのような低速 LEA のパフォーマンス・ペナルティーを予測します。
考えられる問題
サイクルのほとんどが低速な LEA 命令に費やされています。ソースビューを使用して、原因となる命令を特定しそれらを排除します。
SMC マシンクリア
メトリックの説明
ある種のイベントは、パイプライン全体をクリアして、最後にリタイアした命令の直後から再開する必要があります。このメトリックは自己修正コード (SMC) イベントのみを測定します。このイベントは、プログラムがほかのプロセッサーやコード内でデータページとして共有されるコード領域に書き込みを行い、パイプライン全体とトレースキャッシュをクリアした回数をカウントします。自己修正コードは、インテル® アーキテクチャー・ベースのすべてのプロセッサーで深刻なペナルティーを引き起こします。
考えられる問題
実行時間の大部分が、自己修正コードイベントによって発生したマシンクリアの処理に費やされています。動的に変更されるコード (例えば、ターゲット修正) は、SMC によるパフォーマンスの低下につながります。これを避けるには、間接分岐とレジスター間接呼び出しを利用してデータページ (コードページではなく) 上のデータテーブルを使用します。
サイクルごとの SP FLOP
メトリックの説明
クロックティックごとの単精度浮動小数点操作数 (FLOP) を示します。このメトリックは、ベクトルコードの生成と実行の効率を示します。低い FLOP 数の原因を見るには、メトリックに示される問題のリストを調査します。サイクルごとの最大 FLOP 数は、ハードウェア・プラットフォームに依存します。すべての倍精度操作は 2 つの単精度操作に変換されます。
SP GFLOPS
メトリックの説明
1 秒あたりの単精度ギガ浮動小数点操作数を示します。すべての倍精度操作は 2 つの単精度操作に変換されます。
スピン時間
メトリックの説明
スピン時間は、CPU がビジーだった間の待機時間です。通常は、ソフトウェア・スレッドが待機中に、同期 API により CPU がポーリングされると発生します。ある程度のスピン時間は、スレッドのコンテキスト・スイッチを増加させるよりも良いかもしれません。ただし、スピン時間が長すぎると、ワークの生産性に影響します。
考えられる問題
CPU 時間の大部分が待機で費やされています。このメトリックを使用して同期のスピンを特定します。スピン待機パラメーターの調整、ロックの実装変更 (例えば、バックオフしてスケジュール取り消し)、または同期の粒度の調整を検討してください。
通信 (MPI)
メトリックの説明
MPI ビジー待機時間は、MPI ランタイム・ライブラリーが通信操作で待機のためスピンしている CPU 時間です。高いメトリック値は、ランク間の負荷インバランス、アクティブな通信、または MPI ライブラリーの不適切な設定による可能性があります。インテル® Trace Analyzer & Collector を使用して、非効率な通信に関する情報を調査してください。
考えられる問題
MPI 通信操作の待機に費やされる CPU 時間が極端に多い場合、アプリケーションのパフォーマンスとスケーラビリティーに悪影響を与える可能性があります。これは、ランク間のロード・インバランス、アクティブな通信、または MPI ライブラリーの不適切な設定による可能性があります。インテル® Trace Analyzer & Collector を使用して、非効率な通信に関する情報を調査してください。
インバランスまたはシリアルスピン
メトリックの説明
インバランスまたはシリアルスピン時間は、ワーキングスレッドが同期バリアでスピンして CPU リソースを消費している CPU 時間です。これは、ロード・インバランス、すべてのワーキングスレッド間の不十分な並行性、またはシリアル化された実行のバリアでの待機によって引き起こされる可能性があります。
考えられる問題
スレッドランタイム関数が CPU 時間を過度に消費するインバランスやシリアルスピンに関連しています。これは、ロード・インバランス、すべてのワーキングスレッド間の不十分な並行性、またはシリアルコードを実行中のワーカースレッドでのビジー待機によって引き起こされる可能性があります。インバランスがある場合、動的なワーク・スケジュールを行うか、ワークチャンクまたはタスクのサイズを減らします。並行性が不十分である場合、外部と内部ループの畳み込みを検討してください。シリアルコードの完了待機がある場合、インテル® Advisor による並列化、またはインテル® VTune™ プロファイラーのホットスポットやマイクロアーキテクチャー全般解析を使用したアルゴリズムやマイクロアーキテクチャーのチューニングの可能性を調査します。OpenMP* アプリケーションでは、HPC パフォーマンス特性解析でバリアごとの [OpenMP* 潜在的なゲイン] メトリックを使用して、インバランスまたはシリアルスピン時間が長い理由を調査します。
ロック競合
メトリックの説明
ロック競合時間は、ワーキングスレッドがロックでスピンして CPU リソースを消費している CPU 時間です。高いメトリック値は、過度に競合する同期オブジェクトと非効率な並列処理の可能性を示します。過度な同期を避けるには、可能であればリダクション、アトミック操作、またはスレッドローカル変数を使用することを検討してください。
考えられる問題
並列領域内で同期オブジェクトが使用されると、スレッドは共有リソースにアクセスするためほかのスレッドと競合し、ロックの解放を待機するため CPU 時間を費やす可能性があります。可能であれば、リダクションやアトミック操作を使用して同期を減らすか、クリティカル・セクション内で実行されるコードを最小限に抑えます。
その他 (スピン)
メトリックの説明
このメトリックは、スレッド・ランタイム・ライブラリー内の未分類のスピン時間を示します。
スピンとオーバーヘッド時間
オーバーヘッド時間
オーバーヘッド時間は、システムが共有リソースを解放した所有者から取得する所有者に提供するのにかかる時間です。理想的には、オーバーヘッド時間は、リソースがアイドル状態で無駄に消費されていないことを示すゼロに近い値にする必要があります。しかし、並列アプリケーションのすべての CPU 時間が、実際のワークに費やされるわけではありません。並列ランタイム (インテル® スレッディング・ビルディング・ブロック、インテル® Cilk™ Plus、OpenMP* など) が非効率に使用される場合、並列ランタイムでかなりの CPU 時間が無駄に消費される可能性があります。例えば、一定量のワークを並列に実行するスレッドの数を増やすと、各スレッドのワークが少なくなり、相対的にオーバーヘッドは大きくなります。これは、アムダールの法則の基本的な応用です。
浪費される CPU 時間を減らすため、インテル® VTune™ プロファイラーはある時点のコールスタックを解析し、オーバーヘッド時間のパフォーマンス・メトリックを計算します。インテル® VTune™ プロファイラーは、スタックレイヤーをユーザー、システム、およびオーバーヘッド・レイヤーに分類し、オーバーヘッド関数によって呼び出されるシステム関数で費やされた CPU 時間をオーバーヘッド関数に属性化します。
スピン時間
スピン時間は、CPU がビジーだった間の待機時間です。通常は、ソフトウェア・スレッドが待機中に、同期 API により CPU がポーリングされると発生します。ある程度のスピン時間であれば、スレッドのコンテキスト・スイッチを増加させるよりも良いかもしれません。ただし、スピン時間が長すぎるとワークの生産性に影響します。
オーバーヘッドとスピン時間
インテル® VTune™ プロファイラーは、CPU 利用率によるホットスポット、スレッド並行性によるホットスポット、およびホットスポット・ビューポイントのグリッドとタイムライン・ビューで、合計した [オーバーヘッドとスピン時間] メトリックを提供します。このメトリックは、コールサイトのタイプがオーバーヘッド + CPU 時間で、コールサイトのタイプが同期である CPU 時間として計算されたオーバーヘッド時間値とスピン時間値の合計を表します。オーバーヘッドとスピン時間の値を個別に表示するには、 をクリックしてカラムを展開します。
をクリックしてカラムを展開します。
注
インテル® VTune™ プロファイラーは、CPU 利用率メトリックを計算する際に、オーバーヘッドとスピン時間を無視します。
考えられる問題
CPU 時間の大部分が同期またはスレッドのオーバーヘッドで費やされています。タスクの粒度またはデータ同期のスコープを増やすことを検討してください。
アトミック
メトリックの説明
アトミック時間は、アトミック操作でランタイム・ライブラリーが費やす CPU 時間です。
考えられる問題
CPU 時間の多くがアトミック操作に費やされています。可能であればリダクション操作を行います。
生成
メトリックの説明
生成時間は、並列ワークを開始する際にランタイム・ライブラリーが費やす CPU 時間です。
考えられる問題
並列ワークの準備に費やされる CPU 時間は、並列処理の粒度が細かすぎる結果である可能性があります。内部ループよりも外部ループを並列化して、ワークを開始するオーバーヘッドを軽減してください。
その他 (オーバーヘッド)
メトリックの説明
このメトリックは、スレッド・ランタイム・ライブラリー内の未分類のオーバーヘッド時間を示します。
リダクション
メトリックの説明
リダクション時間は、ランタイム・ライブラリーがループまたは領域のリダクション操作に費やす CPU 時間です。
考えられる問題
CPU 時間の大部分がリダクションに費やされています。
スケジュール
メトリックの説明
スケジュール時間は、ワークをスレッドに割り当てる際にランタイム・ライブラリーが費やす CPU 時間です。この時間が大きい場合、ワークを粗いチャンクにすることを検討してください。
考えられる問題
小さなワークの動的スケジュールでは、スレッドが頻繁にスケジューラーに戻るため、オーバーヘッドを増加させる可能性があります。チャンクサイズを増やしてオーバーヘッドを減らしてください。
タスク処理
メトリックの説明
タスク時間は、ランタイム・ライブラリーがタスクの割り当てと完了に費やした CPU 時間です。
分割ストア
メトリックの説明
メモリー階層全体で、データはキャッシュライン単位 (64 バイト) で移動します。これは、整数、単精度浮動小数点、または倍精度浮動小数点などの一般的なデータ型よりはるかに大きなサイズですが、これらのデータ型がアライメントされていないと、2 つのキャッシュラインにまたがって格納されることがあります。最近のインテル® アーキテクチャーでは、キャッシュ分割を処理するため分割レジスターを導入することで、'分割ストア' のパフォーマンスが大幅に向上しています。しかし、分割ストアが分割レジスターを使用しているために別の分割ロードがレジスターを使用できない場合などに問題となります
考えられる問題
サイクルのほとんどが分割ストアに費やされています。
ヒント
64 バイトのキャッシュラインの粒度でデータをアライメントすることを検討してください。
このメトリック値は、ポート 4 の問題によりハイライトされる可能性があることに注意してください。
ストア依存
メトリックの説明
このメトリックは、CPU がストア操作でストールされた頻度を示します。メモリーへのストアアクセスは、通常、アウトオブオーダーの CPU をストールさせることはありませんが、ストアが実際にストールにつながるいくつかのケースがあります。
考えられる問題
CPU のかなりのサイクルがストア操作でストールしました。
ヒント
フォルス・シェアリング解析を行うことを検討してください。
ストア・レイテンシー
メトリックの説明
このメトリックは、長いレイテンシーのストアミス (L2 キャッシュミス) の処理に費やした CPU サイクルの割合を示します。
考えられる問題
長いレイテンシーのストアミス (L2 キャッシュミス) の処理に、かなりの CPU サイクルが費やされています。必要のない (または容易にロード/計算できる) メモリーストアを回避するか減らしてください。このメトリック値は、ロック・レイテンシーの問題によりハイライトされる可能性があることに注意してください。
タスク時間
メトリックの説明
タスク内で費やされた合計時間を示します。
スレッドの並行性
スレッドのオーバーサブスクリプション
メトリックの説明
スレッドのオーバーサブスクリプションは、システムで利用可能な論理コアの数よりも多くの数のスレッドを同時に実行するコードで費やされた時間を示します。
考えられる問題
アプリケーションの多くの時間がスレッドのオーバーヘッドで費やされています。これは、スレッドのプリエンプションおよびコンテキスト・スイッチのコストにより、並列パフォーマンスに悪影響を与えます。
反復カウントの合計
メトリックの説明
合計ループ反復カウントの統計的予測を示します。このメトリックの値は、コールスタック・フィルター・モードごとには集計されません。
uOps
メトリックの説明
uOp、または micro-op は、低レベルのハードウェア操作です。CPU フロントエンドは、アーキテクチャーの命令を表すプログラムコードをフェッチして、それらを 1 つ以上の μOp (マイクロオペレーション) にデコードします。
VPU 利用率
メトリックの説明
このメトリックは、任意のベクトル長とマスクによるパックドベクトル操作を実行したマイクロオペレーションの割合を測定します。VPU 利用率メトリックとコンパイラーのベクトル化レポートを使用して、VPU 利用率を評価し、コンパイラーがコードをどのように判断したのかを理解できます。このメトリックは、ロードとストアをカウントせず、ベクトル長とマスクも考慮しないことに注意してください。整数パックド SIMD を含みます。
考えられる問題
このメトリックは、任意のベクトル長とマスクによるパックドベクトル操作を実行したマイクロオペレーションの割合を測定します。VPU 利用率メトリックとコンパイラーのベクトル化レポートを使用して、VPU 利用率を評価し、コンパイラーがコードをどのように判断したのかを理解できます。このメトリックは、ロードとストアをカウントせず、ベクトル長とマスクも考慮しないことに注意してください。このメトリックは整数パックド SIMD を含みます。
待機カウント
メトリックの説明
待機カウントは、ブロックまたは同期を引き起こす API により、ソフトウェア・スレッドが待機する回数を測定します。
待機レート
メトリックの説明
同期コンテキスト・スイッチごとの平均待機時間 (ミリ秒) を示します。低いメトリック値は、スレッド間の競合の増加とシステム API の非効率な利用を示します。
考えられる問題
平均待機時間が低すぎます。これは、短いタイムアウト、スレッド間の高い競合、またはシステム同期関数の過度な呼び出しによって発生する可能性があります。コールスタック、タイムライン、およびソースコードを調査して、同期コンテキスト・スイッチごとに待機時間が短い原因を特定します。
待機時間
メトリックの説明
待機時間は、ソフトウェア・スレッドが同期 API または同期をブロックする API によって待機する場合に発生します。待機時間はスレッドごとであるため、待機時間の合計はアプリケーションの経過時間を超えることがあります。