CPU/FPGA 相互作用ビューポイントを使用して、カーネルの実行に費やされた FPGA 時間、CPU と FPGA 間のメモリー転送の合計時間、および CPU と FPGA 間のワークロードのバランスを評価します。
CPU/FPGA 相互作用ビューポイントで示されるパフォーマンス・データを解釈するには、次のステップに従います。
パフォーマンスのベースラインを定義する
アプリケーションの実行に関する一般的な情報を提供する [サマリー] ウィンドウから調査を始めます。最適化の重要な領域には、アプリケーションの実行時間、CPU または FPGA の時間が長いタスク、およびカーネルの実行時間が含まれます。
経過時間値を指標として、最適化前後のバージョンを比較するベースラインを求めます。
FPGA 利用率を評価
FPGA 上で実行されているカーネルの一覧については、[サマリー] ウィンドウの [FPGA の上位計算タスク] リストを参照してください。
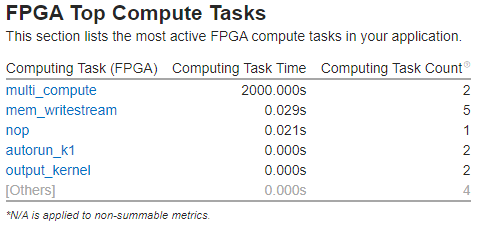
[ボトムアップ] ウィンドウに切り替えて、[計算タスクの目的/ソース計算タスク (FPGA)] グループ化を使用して、カーネルのホットスポットを表示します。
ヒント
[ボトムアップ] ウィンドウで [FPGA 上位計算タスク] のリストからタスクをクリックすると、そのタスクに移動します。
[FPGA 利用率] タイムラインを確認します。これは、FPGA 上で同時に実行されているカーネルと転送数を示します。
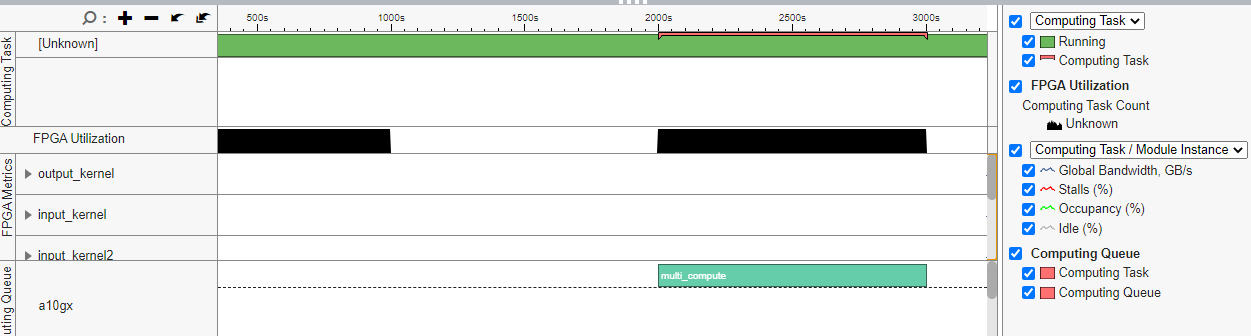
メモリー転送を確認する
[ボトムアップ] ウィンドウの [データ転送] カラム、または [プラットフォーム] ウィンドウの [計算キュー] 行を参照して、FPGA カーネルとメモリー転送を確認します。
ワークロードの影響を判断する
[サマリー] ウィンドウの [コンテキスト・スイッチ時間] メトリックには、CPU がコンテキスト・スイッチに費やした時間が表示されます。[プラットフォーム] ウィンドウに切り替えて、タイムラインにカーソルを移動するとコンテキスト・スイッチの理由が表示されます。CPU コンテキスト・スイッチは、FPGA に対する CPU 待機時間を示す場合もあります。FPGA 利用率の行を調べて、CPU が FPGA を待機する可能性がある時間とその逆の時間を特定します。例えば、FPGA アクティビティーがなく、CPU アクティビティーが高い場合、FPGA は CPU の準備が完了するのを待機している可能性があります。
FPGA デバイスメトリックを調査
[ボトムアップ] ウィンドウに切り替えて、ストール、グローバル帯域幅および占有率メトリックを解析し、FPGA デバイスがカーネルで効率良く実行されているか確認します。
アイドル % メトリックを解析して、有効なワーク項目が実行されていない、またはメモリーやチャネル命令を実行もしくはストールしているサイクルのパーセンテージを理解します。アクティビティー % メトリックは、プレディケートされたチャネルまたはメモリー命令が有効であるサイクルのパーセンテージを示します。
チャネルの深さを解析
[ボトムアップ] ウィンドウで、選択したインスタンスの平均または最大チャネル深度の情報を参照します。必要に応じて、チャネルの深さを調整します。
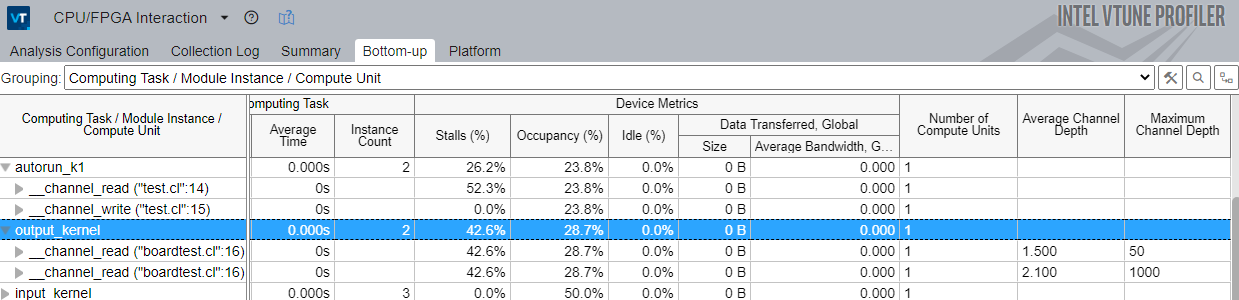
チャネルが常にフルであれば、チャネルの書込みは読み取りよりも高速に動作していることになり、書き込みカーネルでストールすることになります。チャネルがほとんど空であれば、読み取り側がストールしている可能性が高く、チャネルの深さが 32 ビットよりも大きければ、パフォーマンスを低下させることなくサイズを小さくできます。
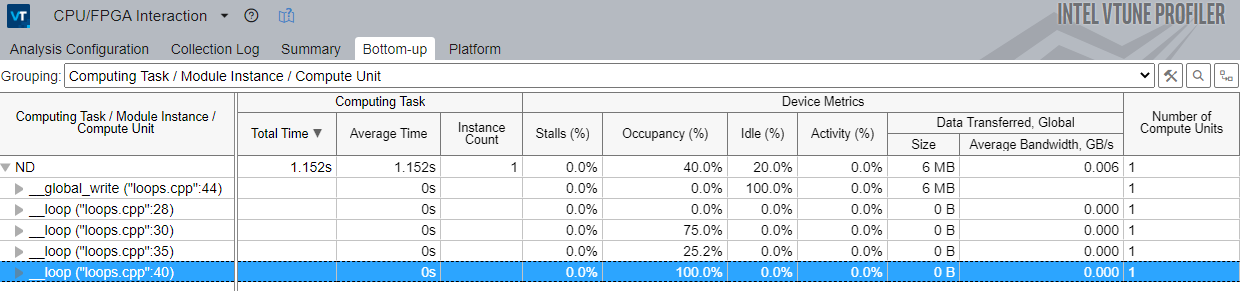
ループを解析
プロファイルされたループの占有率を解析します。
ホストのアプリケーション部分のソースを解析
最適化する関数をダブルクリックして、関連するソースコード・ファイルを [ソース/アセンブリー] ウィンドウに表示します。インテル® VTune™ プロファイラーから直接コードエディターを開いてコードを編集できます (例えば、ホットスポット関数の呼び出し回数を最小限に抑えるなど)。
FPGA デバイスで実行されるカーネルのソースを解析
カーネルソース行ごとの FPGA デバイスのメトリックを参照するには、カーネルをダブルクリックします。[ソース] ビューでは、いずれのチャネルやメモリーがストールの原因となり、どのくらいデータが転送されているか確認できます。