インテル® VTune™ プロファイラーの入出力解析で提供されるプラットフォーム・レベルのメトリックを理解します。
入出力解析タイプは、プラットフォーム・レベルの解析向けに次のメトリックを提供します。
- I/O デバイスが外部 PCIe* デバイスであるか、統合アクセラレーターであるかにかかわりなく、I/O デバイスごとにプラットフォームの I/O トラフィックを解析します。
- インテル® データ・ダイレクト I/O テクノロジー (インテル® DDIO) の利用率の効率を解析します。
- ダイレクト I/O (インテル® VT-d) 向けインテル® バーチャライゼーション・テクノロジーの利用率を解析します。
- DRAM とパーシステント・メモリー帯域幅の消費を監視します。
- 非効率なリモートソケットのアクセスによって引き起こされる I/O パフォーマンスの問題を特定します。
- アウトバウンド I/O、オフロード MMIO) の原因を特定します。
このようなパフォーマンスの問題を特定するには、次のオプションを有効にして入出力解析を実行します。
トポロジーの解析とハードウェアリソース利用率
データ収集が完了すると、インテル® VTune™ プロファイラーはデフォルトで [サマリー] ウィンドウを開きます。
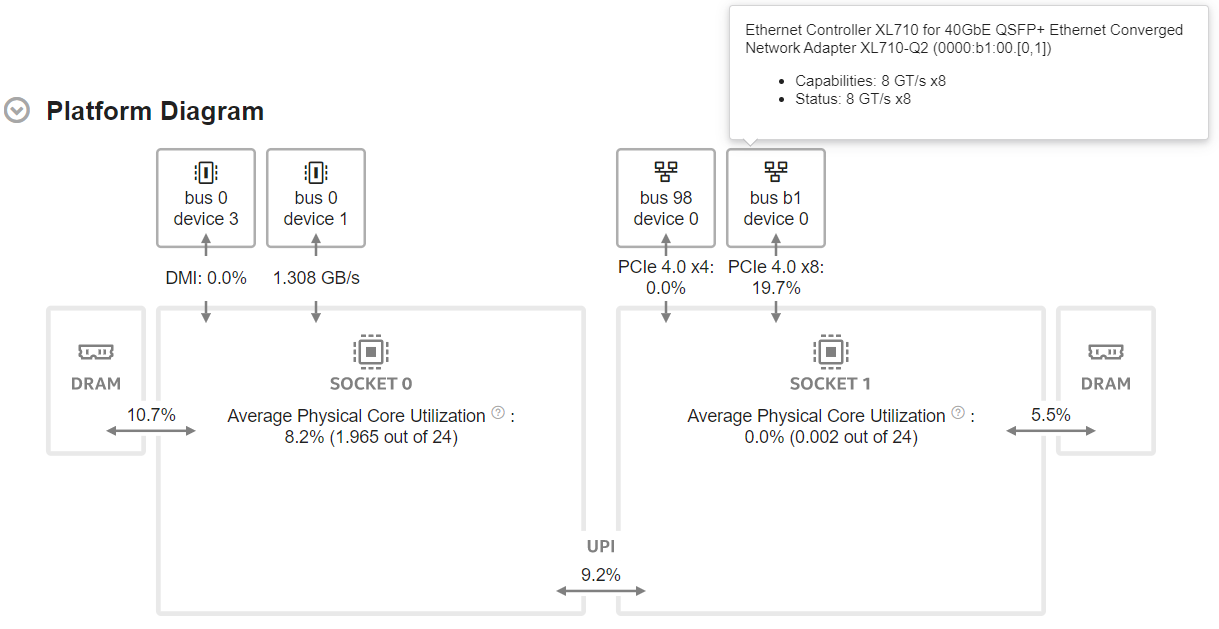
[サマリー] ウィンドウの [プラットフォーム図] セクションから調査を開始します。[プラットフォーム図] には、PCIe*、インテル® UPI リンク、DRAM および物理コアのシステムトポロジーと利用率メトリックが表示されます。
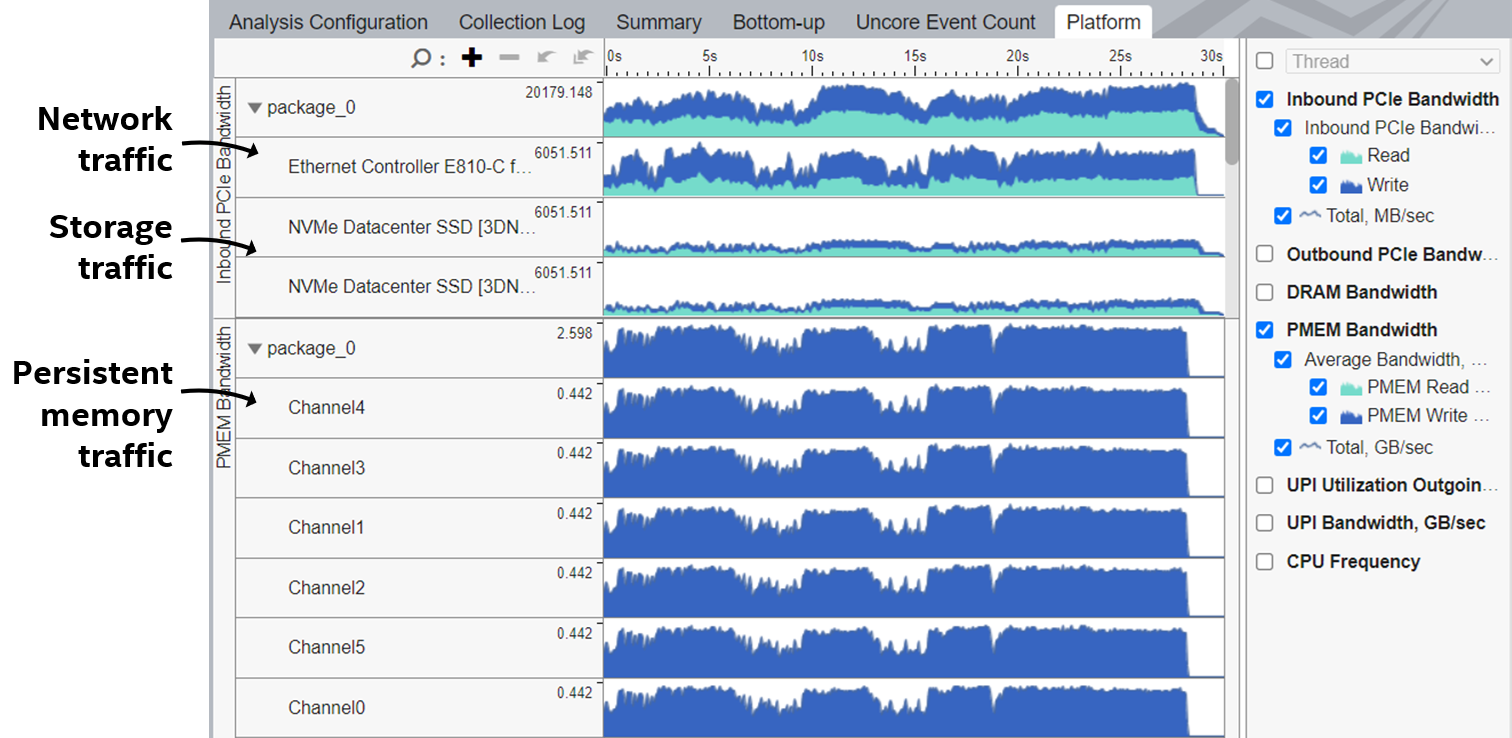
以下は、ソケット 1 にアクティブなネットワーク・インターフェイス・カード (NIC) と、ソケット 0 にアクティブなインテル® QuickData テクノロジー (CBDMA) を備えた 2 ソケットサーバーの [プラットフォーム図] の例です。
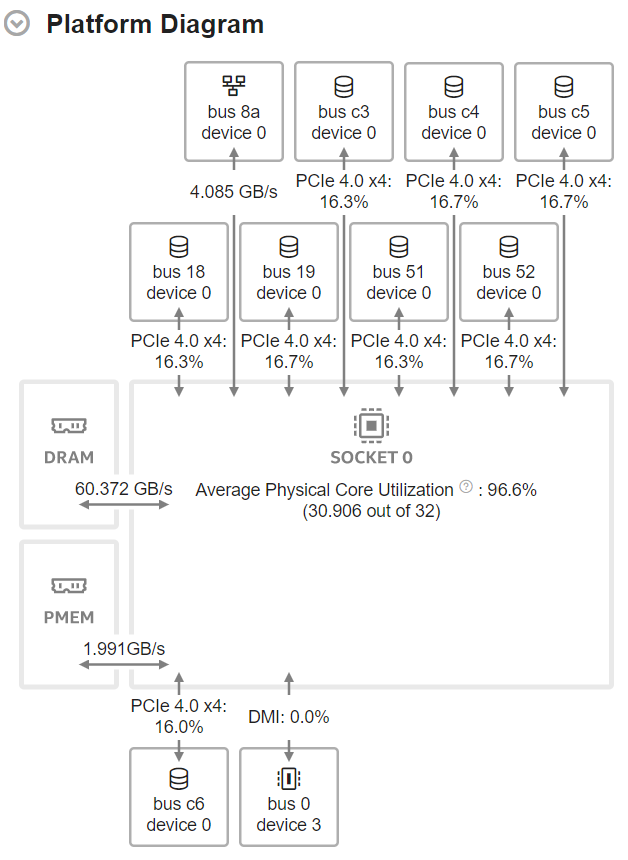
これは、8 つのアクティブな NVMe SSD、ネットワーク・インターフェイス・カード、およびパーシステント・メモリーを備えたシングル・ソケット・サーバーの [プラットフォーム図] です。
注
[プラットフォーム図] は、インテル® マイクロアーキテクチャー開発コード名 Skylake (最大 4 ソケット) と Sapphire Rapids ベースのサーバー・プラットフォーム以降で利用できます。
物理的な PCIe* デバイスは、PCI バスとデバイス番号からなる短縮名で表示されます。デバイスのツールチップには、デバイスの完全名、リンク機能、ステータスが表示されます。デバイスのイメージ画像にカーソルを合わせると詳細情報が表示されます。
プラットフォーム図は、スループットが制限される原因となる可能性があるデバイス状態の問題を示しています。典型的な問題は、設定されたリンク速度/幅がデバイスの最大速度/幅と一致しないことです。

デバイスの機能が判明しており、最大物理帯域幅を計算できる場合、デバイスリンクはデータ転送で消費された帯域幅と、利用可能な物理帯域幅の比率を表わす [有効リンク利用率] メトリックに関連付けられます。このメトリックは、プロトコルのオーバーヘッド (TLP ヘッダー、DLLP、物理エンコード) を考慮せず、ペイロードの観点からのリンク利用率が反映されます。そのため 100% になることはありません。しかし、これはリンクが飽和状態からどのくらい離れているかを知る手がかりになります。最大理論帯域幅は、デバイスのツールチップに表示されるデバイスのリンク機能に対して計算されます。
プラットフォーム図は、[解析の設定] で [DRAM の最大帯域幅を評価] チェックボックスを選択すると [最大 DRAM 帯域幅] を表示します。それ以外は、[平均 DRAM 利用率] を示します。
システムにパーシステント・メモリーが搭載されている場合、プラットフォーム図には [パーシステント・メモリー帯域幅] が表示されます。
平均 UPI 利用率メトリックは、送信の観点から UPI 利用率を示します。プラットフォーム図では、パッケージのペアを接続する UPI リンク数に関わりなく、単一のソケット間接続が示されます。複数のリンクが存在する場合、最大値が示されます。
各ソケットの上部に表示される [平均物理コア利用率] メトリックには、解析されるアプリケーションの計算による物理コアの利用率が示されます。
トポロジーと利用率を調査したら、プラットフォームのパフォーマンス詳細にドリルダウンします。
フォーム分布図の高帯域幅メモリーデータ
インテル マイクロアーキテクチャー 開発コード名 Sapphire Rapids ベースのサーバー・プラットフォームでは、フォーム分布図に高帯域幅メモリー (HBM) に関する情報が含まれます。この情報で DRAM 固有の利用状況を区別することができます。
例えば、この図はシステムに DRAM が搭載されていない HBM モードの利用率に関する情報を示しています。

HBM と DRAM の両方を備えるシステムのフォーム分布図データの例を示します。

プラットフォーム I/O 帯域幅の解析
プラットフォーム上の PCIe* トラフィックを調査するには、[サマリー] ウィンドウの [PCIe* トラフィックのサマリー] セクションから始めます。これらの上位レベルのメトリックは、インバウンドとアウトバウンドの I/O トラフィックの合計を反映します。
インバウンド PCIe* 帯域幅は、システムメモリーへの書き込みおよびシステムメモリーからの読み取りを行う I/O デバイス (外部 PCIe* デバイスと統合アクセラレーター、またはその両方) によって引き起こされます。これらの読み取りと書き込みは、インテル® データダイレクト I/O (インテル® DDIO) 機能を介してプラットフォームによって処理されます。
インバウンド PCIe* リード — PCIe* デバイスはプラットフォーム・メモリーから読み取りを行います。
インバウンド PCIe* ライト — PCIe* デバイスはプラットフォーム・メモリーに書き込みを行います。
アウトバウンド PCIe* 帯域幅は、PCIe* デバイスのメモリーまたはレジスターに対するコア・トランザクションによって引き起こされます。通常、コアはメモリーマップされた I/O (MMIO) アドレス空間を介してデバイスメモリーにアクセスします。
アウトバウンド PCIe* リード — コアはデバイスのレジスターから読み取ります。
アウトバウンド PCIe* ライト — コアはデバイスのレジスターに書き込みます。
インバウンドとアウトバウンドの PCIe* 帯域幅メトリックの粒度は、CPU モデル、使用するコレクター、およびユーザー権限によって異なります。詳細については、プラットフォーム・レベルのメトリック表を参照してください。
[ボトムアップ] または [プラットフォーム] タブのタイムラインで、デバイスごとに インバウンドとアウトバウンドの PCIe* 帯域幅 を時系列に解析できます。
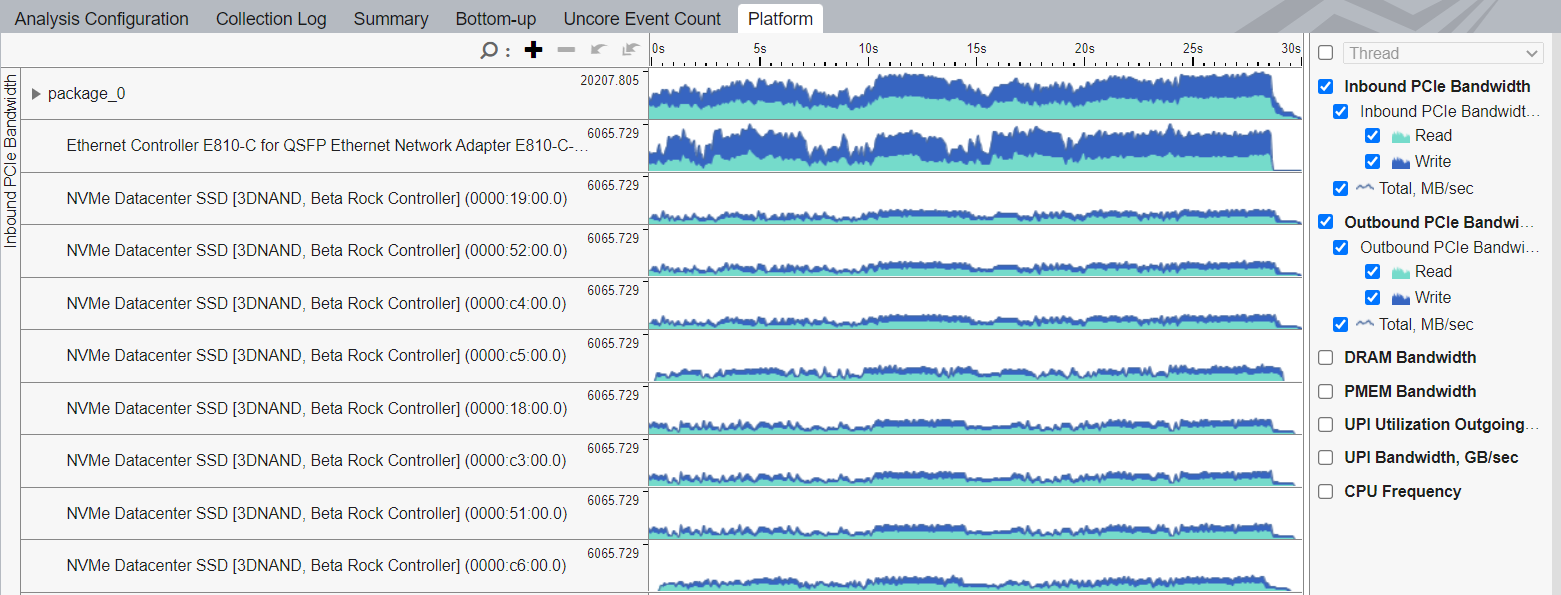
インテル® データ・ダイレクト I/O 利用率の効率を解析
アプリケーションがインテル® DDIO を効率良く利用しているか理解するには、PCIe* トラフィックのサマリー セクションの 2 階層目のメトリックを調査します。
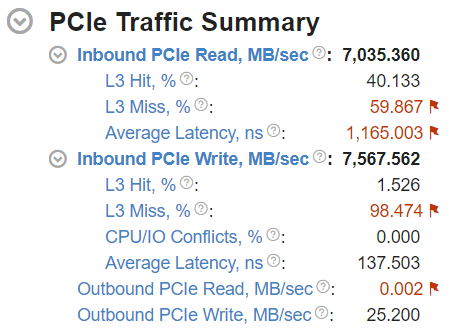
インバウンド PCIe* 要求の L3 ヒット/ミス比率は、IO デバイスからシステムメモリーへの要求のうち、L3 キャッシュにヒットしたものとミスしたものの比率を表します。インテル® DDIO の利用効率の詳細については、クックブックのレシピ「インテル データダイレクト I/O テクノロジーの有効な利用」を参照してください。
注
L3 ヒット/ミスのメトリックは、インテル® Xeon® プロセッサー開発コード名 Haswell 以降で利用できます。
インバウンド PCIe* リード/ライトグループの平均レイテンシーメトリックは、プラットフォームが単一のキャッシュラインのインバウンドのリード/ライト要求の処理に費やす平均時間を示します。
コア/IO 競合比率は、IO コアと I/O コントローラー間でキャッシュラインの競合が発生したインバウンドの PCIe* 書き込み要求の一部を示します。このような競合は、キャッシュラインのスヌーピングが原因で発生します。これにより、特定の条件下で I/O コントローラーがそのキャッシュラインの所有権を失う可能性があります。これにより、I/O コントローラーはそのキャッシュラインを再取得します。この問題は、ポーリング通信モデルを採用するアプリケーションで発生する可能性があり、その結果スループットとレイテンシーが適切ではなくなります。この問題を解決するには、UEFI/BIOS の統合 I/O 設定の [Snoop Response Hold Off] オプションを調整することを検討してください (オプション名はプラットフォームの製造元によって異なります)。
注
インバウンド PCIe* リード/ライトの平均レイテンシー、およびコア/IO 競合メトリックは、インテル® Xeon® プロセッサー開発コード名 Skylake 以降で利用できます。
[DDIO 効率] メトリック (インバウンド I/O 帯域幅の 2 番目のメトリック) の粒度は、CPU モデル、使用するコレクター、およびユーザー権限によって異なります。詳細については、プラットフォーム・レベルのメトリック表を参照してください。
[ボトムアップ] ペインの [パッケージ/M2PCIe*] グループを使用して、デバイスごとのインバウンドとアウトバウンド・トラフィック、L3 にヒットおよびミスしたインバウンド要求、平均レイテンシー、およびコア/IO 競合の内訳を取得できます。

ダイレクト I/O のインテル® バーチャライゼーション・テクノロジーの利用状況を解析
ワークロードが、ダイレクト I/O 向けインテル® バーチャライゼーション・テクノロジー (インテル® VT-d) をどのように利用しているか理解するには、結果の [サマリー] タブを調査します。インテル® VT-d により、インバウンド I/O 要求のアドレス再マップが可能になります。
注
インテル® VT-d メトリックは、インテル® マイクロアーキテクチャー開発コード名 Ice Lake ベース以降のサーバー・プラットフォームで利用できます。
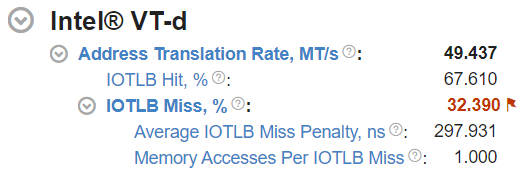
最上位のメトリックは、平均合計アドレス・トランスレーション率を示します。
IOTLB (I/O トランスレーション・ルックアサイド・バッファー) は、デバイスが使用する仮想アドレスからホストの物理アドレスへの変換効率を高める、再マップ・ハードウェア・ユニット内のアドレス変換キャッシュです。IOTLB ルックアップは、アドレス変換要求によって発生します。[IOTLB ヒット] と [IOTLB ミス] メトリックは、IOTLB にヒットしたアドレス変換要求とヒットしなかったアドレス変換要求の比率を反映します。
IOTLB ミスの次のレベルのメトリックには次のものがあります。
- 平均 IOTLB ミスのペナルティー (ns) — IOTLB ミスの処理に費やされた平均時間。この時間には、コンテキスト・キャッシュ、中間ページ・テーブル・キャッシュ、およびミス時のページテーブル読み取り (ページウォーク) の検索が含まれ、これらはメモリー読み取り要求に変わります。
- IOTLB ミスごとのメモリーアクセス — IOTLB ミスごとに発生するメモリー読み取り要求 (ページウォーク) の平均数。
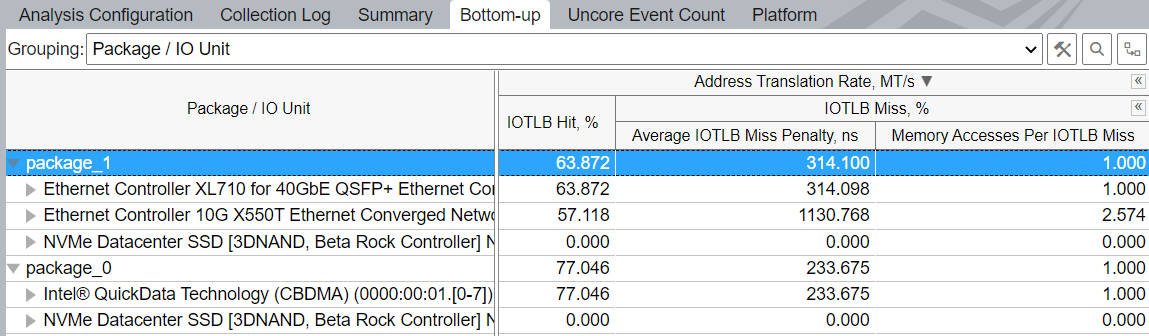
インテル® VT-d メトリックの粒度は、CPU モデル、使用するコレクター、およびユーザー権限によって異なります。詳細については、プラットフォーム・レベルのメトリック表を参照してください。必要条件が満たされている場合、インテル® VT-d メトリックは、I/O デバイス (外部 PCIe* デバイスと統合アクセラレーター、またはその両方) ごとに表示できます。それぞれのセットには、単一の I/O コントローラーによって処理されるすべてのデバイスが含まれており、通常は 16 個の PCIe* レーンをサポートします。[ボトムアップ] ウィンドウに切り替え、[パッケージ/IO ユニット] でグループ化します。
MMIO アクセスの解析
[サマリー] タブの PCIe* トラフィックのサマリー セクションに表示されるアウトバウンド PCIe* トラフィックは、PCIe* デバイスのメモリーとレジスターをコアが読み書きすることで発生します。
通常、コアはメモリーマップされた I/O (MMIO) アドレス空間を介して PCIe* デバイスのメモリーにアクセスします。PCIe* デバイスにマッピングされた MMIO アドレス空間のロードまたはストア操作によって、それぞれ PCIe* のリードまたはライトのアウトバウンド・トランザクションが発生します。通常のロードとストア命令が実行される場合、このようなメモリーアクセスは I/O デバイスのアクセス・レイテンシーの影響を受けるため、かなりコストがかかります。そのため、高いパフォーマンスを達成するには、このようなアクセスを最小限にする必要があります。最新のインテル® アーキテクチャーには、ダイレクトストア命令 (MOVDIR*) (英語) が実装されており、通常のジョブの送信や「ドアベル呼び出し」に使用される MMIO 書き込みを高速化します。
[解析の設定] で [MMIO アクセスを特定] オプションを有効にして、アウトバウンド・トラフィックのソースを検出します。MMIO アクセスのセクションから、特定の PCIe* デバイスの MMIO リード と MMIO ライト を実行する関数を検索します。

[ボトムアップ] ペインを使用して、メモリーマップされた PCIe* デバイスのアクセス元を特定します。コールスタックを調査して、[ソースとアセンブリー] ビューにドリルダウンします。

関数名をダブルクリックすると、[ソース] または [アセンブリー] ビューに移動し、MMIO の読み取りと書込みを行うコードをソース行レベルで検出できます。

注
MMIO アクセスデータは、[MMIO アクセスを特定] チェックボックスを選択している場合にのみ収集されます。しかし、いくつかの制限があります。
この機能は、インテル® マイクロアーキテクチャー 開発コード名 Skylake ベースのサーバー・プラットフォーム以降で利用できます。
[プロセスにアタッチ] と [アプリケーションを起動] 収集モードでのみサポートされます。[システムをプロファイル] モードで実行する場合、このオプションはキャッシュ不可なメモリーからの読み取りを行う関数のみを表示します。
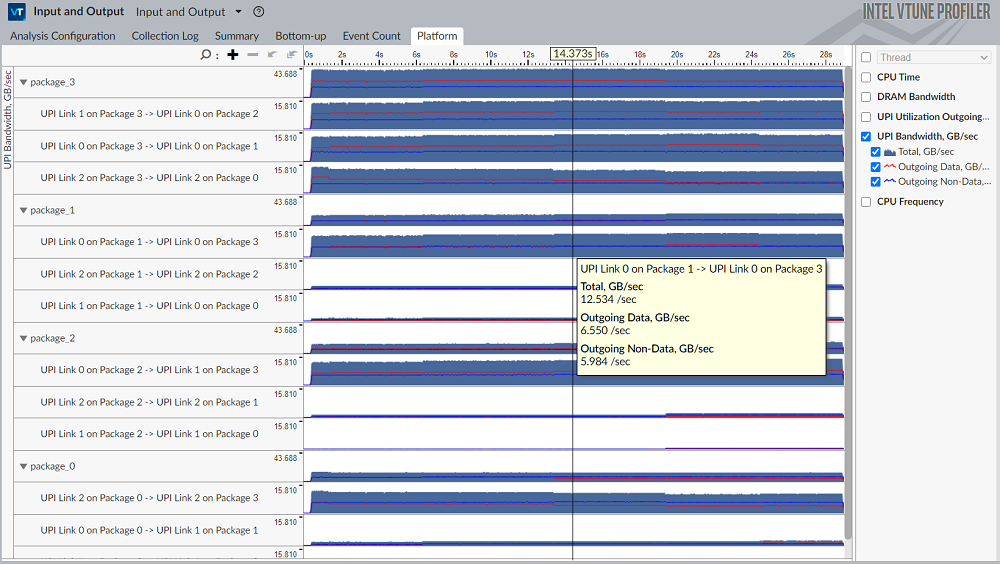
メモリー、パーシステント・メモリー、およびソケット間の帯域幅を解析
[プラットフォーム] タブを使用して、インバウンドの PCIe* トラフィックと DRAM およびソケット間のインターコネクト帯域幅を関連付けることができます。
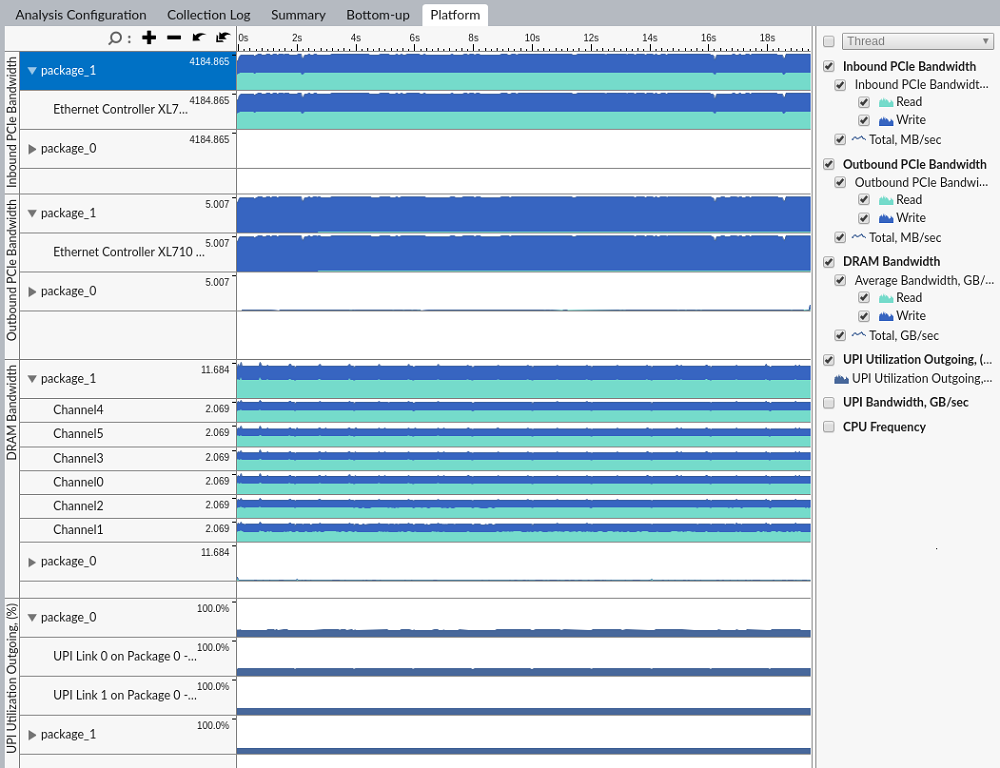
インテル® VTune™ プロファイラーはチャネルごとの DRAM 帯域幅の内訳を示します。
インテル® UPI トラフィック向けに 2 つのメトリックが用意されています。
- UPI 送信利用率 – 送信の観点から UPI の利用率を示すメトリック。
- UPI 帯域幅 – データ/非データごとの内訳と詳細な帯域幅に関する情報を示します。
UPI リンクごとに UPI メトリックの内訳を取得できます。プロセッサーの仕様を参考にして、プロセッサーの各ソケットで有効な UPI リンク数を確認してください。
UPI リンク名は、接続されているソケットと I/O コントローラーを示し、システムのトポロジーを明確にします。
以下は、インテル® マイクロアーキテクチャー開発コード名 Skylake をベースとするインテル® プロセッサーを搭載する、4 ソケットのサーバー・プラットフォームで収集された結果の例です。データは、ソケット 3 に接続されたリンクで帯域幅がはるかに高い、UPI トラフィックのインバランス状態を示しています。