 インテル® oneDAL
インテル® oneDAL インテル® MKL とインテル® DAAL によるビッグデータ解析のスピードアップ
この記事は、インテル® デベロッパー・ゾーンに公開されている「Speeding Up Big Data Analysis With Intel MKL and Intel DAAL」の日本語参考訳です。 生成されるデータが増え続ける中、それ...
 インテル® oneDAL
インテル® oneDAL  HPC
HPC  HPC
HPC  HPC
HPC  HPC
HPC  インテル® DPC++/C++ コンパイラー
インテル® DPC++/C++ コンパイラー 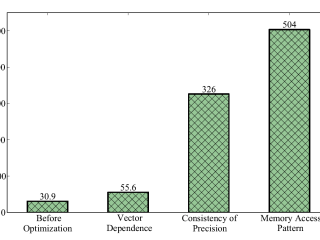 インテル® Advisor
インテル® Advisor  HPC
HPC  インテル® Advisor
インテル® Advisor 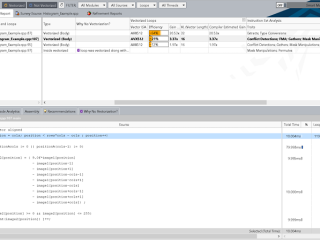 インテル® Advisor インテル® Advisor
インテル® Advisor インテル® Advisor  HPC インテル® DPC++/C++ コンパイラー
HPC インテル® DPC++/C++ コンパイラー  インテル® oneDAL
インテル® oneDAL  HPC
HPC 