 インテル® oneTBB
インテル® oneTBB インテル® TBB 2020 の有用な機能: タスク・スケジューラー
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® Threading Building Blocks Documentation』の「Task Scheduler」( の日本語参考訳です。 インテル® スレッディン...
 インテル® oneTBB インテル® oneTBB
インテル® oneTBB インテル® oneTBB 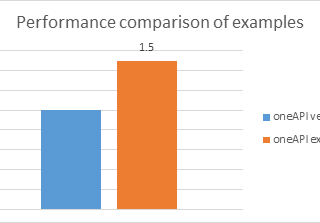 インテル® oneAPI
インテル® oneAPI  インテル® oneAPI
インテル® oneAPI  その他
その他  インテル® DPC++/C++ コンパイラー
インテル® DPC++/C++ コンパイラー 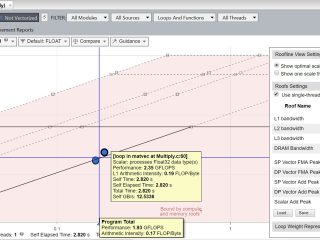 インテル® Advisor
インテル® Advisor 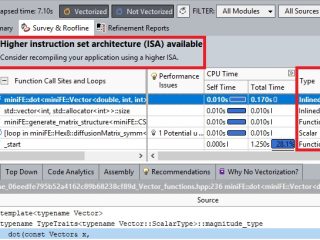 インテル® Advisor
インテル® Advisor 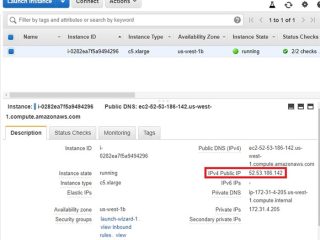 インテル® Advisor
インテル® Advisor  インテル® Advisor
インテル® Advisor 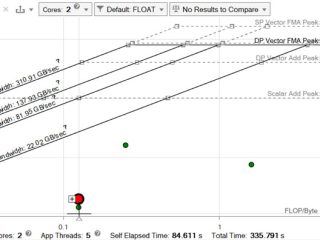 インテル® Advisor
インテル® Advisor  インテル® ディストリビューションの Python*
インテル® ディストリビューションの Python*  インテル® Parallel Studio XE
インテル® Parallel Studio XE  HPC
HPC  インテル® Advisor
インテル® Advisor 