 その他
その他 インテル® 64 アーキテクチャーおよび IA-32 アーキテクチャー最適化リファレンス・マニュアル – 248966-037 July 2017 rev. 2
最新のドキュメント番号: 248966-037 July 2017 最新のドキュメントは、以下からダウンロードできます: Intel® 64 and IA-32 Architectures Optimization Reference Ma...
 その他 その他
その他 その他 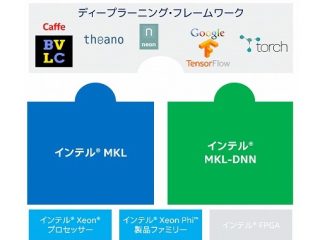 インテル® oneDAL
インテル® oneDAL 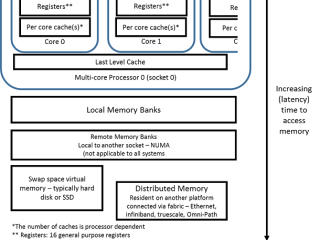 HPC
HPC  HPC
HPC  インテル® oneMKL
インテル® oneMKL  HPC
HPC 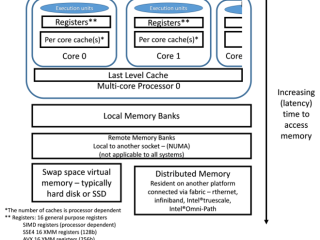 HPC
HPC 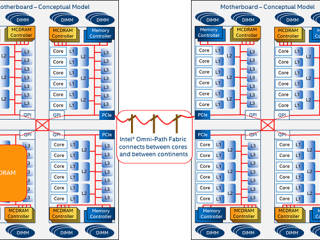 HPC
HPC  インテル® Advisor インテル® Advisor
インテル® Advisor インテル® Advisor  その他
その他 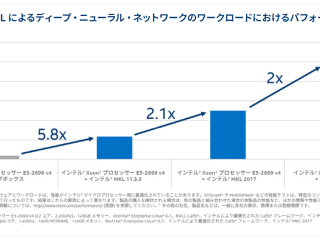 インテル® oneMKL
インテル® oneMKL  インテル® oneMKL
インテル® oneMKL  インテル® oneMKL
インテル® oneMKL 