 HPC
HPC コードを GPU にオフロードする
このセッションは、Tech.Decoded で公開されている「Offload Your Code from CPU to GPU … and Optimize It」( の日本語版です。ボトルネックの特定と排除は、すべての開発者が避けて通れ...
 HPC
HPC  インテル® Parallel Studio XE
インテル® Parallel Studio XE  インテル® Advisor
インテル® Advisor  インテル® Parallel Studio XE
インテル® Parallel Studio XE  インテル® MPI ライブラリー インテル® IPP インテル® oneMKL インテル® ディストリビューションの Python* HPC
インテル® MPI ライブラリー インテル® IPP インテル® oneMKL インテル® ディストリビューションの Python* HPC 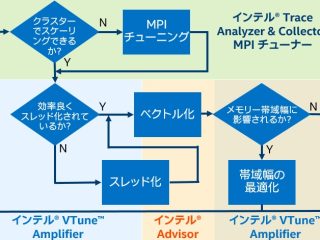 HPC
HPC  HPC
HPC  HPC
HPC 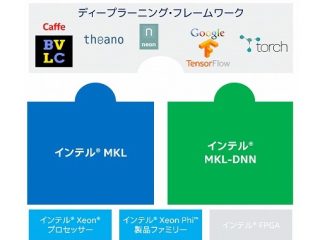 インテル® oneDAL
インテル® oneDAL  インテル® Advisor インテル® Advisor
インテル® Advisor インテル® Advisor 