
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Top-down Microarchitecture Analysis Method」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
アプリケーションが利用可能なハードウェア・リソースをどのように使用しているかを把握し、CPU マイクロアーキテクチャーの利点を活用できるようにします。この情報を得る 1 つの手段として、オンチップのパフォーマンス・モニタリング・ユニット (PMU) を使用する方法があります。
コンテンツ・エキスパート: Jackson Marusarz、Dmitry Ryabtsev
PMU は、システム上で発生した特定のハードウェア・イベントをカウントする CPU コア内部の専用ロジックです。これらのイベントには、キャッシュミスや分岐予測ミスなどがあります。これらのイベントを組み合わせることで、命令あたりのサイクル数 (CPI) などの高レベルのメトリックを構成して監視できます。
特定のマイクロアーキテクチャーでは、PMU を介して数百ものイベントを利用できます。特定のパフォーマンスの問題を検出して解決する際に、どのイベントが有用であるかを判断することは容易ではありません。生のイベントデータから有用な情報を得るには、マイクロアーキテクチャーの設計と PMU 仕様の両方に関する深い知識が求められます。しかし、事前定義されたイベントとメトリックを使用することにより、トップダウン特性化方法論の利点を活用してデータを実用的な情報に変換することができます。
PMU 解析レシピでは、その手法とインテル® VTune™ プロファイラーでの使用方法を説明します。
- 使用するもの:
- 手順:
- 関連クックブック・レシピ
トップダウン・マイクロアーキテクチャー解析法の概要
現代の CPU は、リソースを可能な限り有効に活用するため、ハードウェアによるスレッド化、アウトオブオーダー実行、命令レベルの並列性などの技術とともにパイプラインを採用しています。しかし、ソフトウェア・パターンとアルゴリズムの中には、依然として非効率なものがあります。例えば、リンクデータ構造はソフトウェアで良く利用されますが、これはハードウェア・プリフェッチャーの有効性を損ねる間接アドレスの原因となります。多くの場合、このような振る舞いはパイプラインに無益な隙間 (パイプライン・バブル) を作り、データが取得されるまで実行するほかの命令がない状態となります。リンクデータ構造は、ソフトウェアの問題に対しては適切なソリューションですが、非効率な結果となるでしょう。このほかにも、CPU パイプラインに関連して重要な意味を持つ多くのソフトウェア・レベルの例があります。トップダウン・マイクロアーキテクチャー解析法は、トップダウン特性化方法論をベースとして、アルゴリズムとデータ構造が適切な選択を行っているかどうか、詳しい情報を提供します。トップダウン・マイクロアーキテクチャー解析法の詳細は、『インテル® 64 および IA-32 アーキテクチャー最適化リファレンス・マニュアル』の付録 B.1 を参照してください。
トップダウン特性化は、アプリケーションのパフォーマンス・ボトルネックを特定するイベントベースのメトリックを階層的に構成します。これは、CPU がアプリケーションを実行する際のパイプラインの利用率の平均を示します。以前のフレームワークは、CPU のクロックティックをカウントする方法を使用して、どの要素の CPU のクロックティックが、どの操作 (L2 キャッシュミスによるデータ取得など) に費やされたか判別して、イベントを解釈していました。このフレームワークは、その代わりに、パイプラインのリソースをカウントする方法を使用します。トップダウン特性化を理解するため、高レベルのマイクロアーキテクチャーの概念を調査します。マイクロアーキテクチャーの詳細の多くはこのフレームワークで抽象化されており、ハードウェアのエキスパートでなくても理解して、使用することができます。
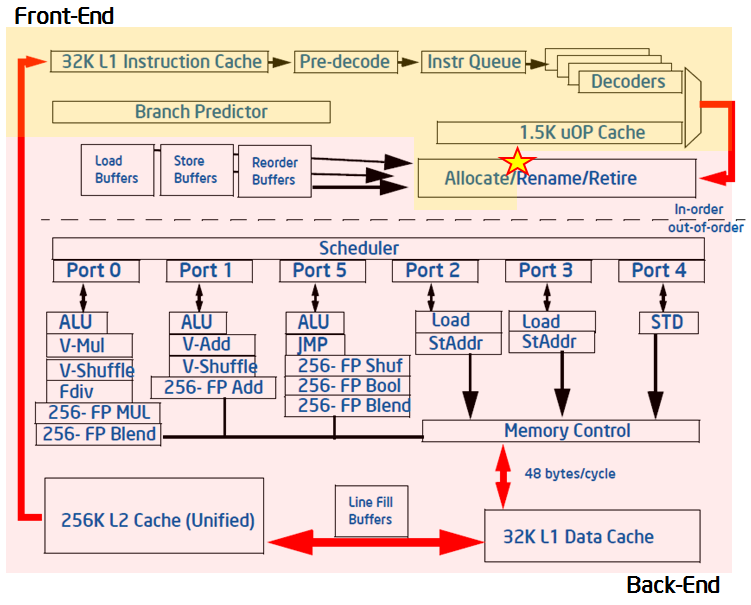
現代のハイパフォーマンス CPU のパイプラインは、非常に複雑です。以下の図に示すように、パイプラインは概念的にフロントエンドとバックエンドの 2 つに分割できます。フロントエンドは、アーキテクチャーの命令を表すプログラムコードをフェッチして、それらを μop (マイクロオペレーション) と呼ばれる 1 つ以上の低レベルのハードウェア操作にデコードします。μop は、パイプラインの「アロケーション」と呼ばれる過程でバックエンドへ送られます。アロケーションが行われると、バックエンドは μop のデータオペランドが利用可能になるのを監視し、利用可能な実行ユニットで μop を実行する役割を担います。μop の実行完了は「リタイア」と呼ばれ、μop の実行結果はアーキテクチャー状態にコミットされます (CPU レジスターやメモリーへの書き戻し)。通常、ほとんどの μop はパイプラインを通過してリタイアしますが、投機的にフェッチされた μop はリタイアする前に取り消される場合があります (分岐予測ミスのようなケース)。
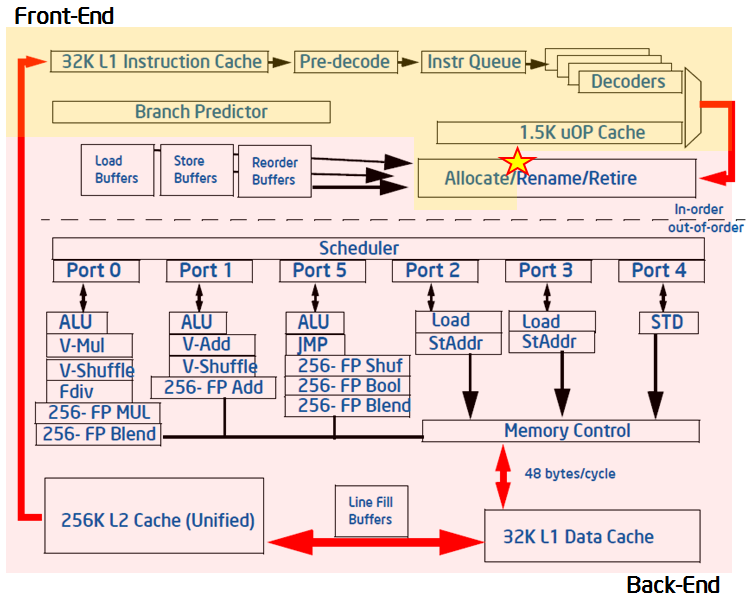
最近のインテル® マイクロアーキテクチャーでは、パイプラインのフロントエンドはサイクルごとに 4 つの μop をアロケートでき、バックエンドはサイクルごとに 4 つの μop をリタイアできます。これらの機能を考慮して、パイプライン・スロットの抽象化の概念を定義します。パイプライン・スロットは、1 つのマイクロオペレーションを操作するために必要なハードウェアのリソースを表します。トップダウン特性化では、それぞれの CPU コアには、各クロックサイクルで利用可能な 4 つのパイプライン・スロットがあると仮定します。そして、特殊な PMU イベントを使用して、これらのパイプライン・スロットがどの程度効率良く利用されているか測定します。パイプライン・スロットの状態は、アロケーションの時点 (上記の図で★印が記された場所) で取得され、μop はフロントエンドからバックエンドへ移ります。アプリケーションの実行中に利用可能な各パイプライン・スロットは、上記のパイプラインの図に基づいて 4 つのカテゴリーのいずれかに分類されます。
すべてのサイクルで、パイプライン・スロットは空であるか、μop で埋められているかのどちらかです。スロットが 1 クロックサイクルで空の場合、ストールに分類されます。このパイプラインを分類するために必要な次のステップは、パイプラインのフロントエンドまたはバックエンドのどちらがストールの原因であるか判断することです。この処理は、指定された PMU イベントと式を使用して行われます。トップダウン特性化の目的は重要なボトルネックを特定することですが、フロントエンドもしくはバックエンドのどちらかがストールの原因であるかは重要な考慮点です。一般に、ストールの原因がフロントエンドによる μop 供給の能力不足であれば、このサイクルはフロントエンド依存 (Front End Bound) スロットとして分類され、パフォーマンスはフロントエンド依存カテゴリーのいくつかのボトルネックで制限されます。バックエンドで μop を処理する準備ができていないためにフロントエンドが μop を渡せない場合、空のパイプライン・スロットはバックエンド依存 (Back End Bound) として分類されます。バックエンド・ストールは、一般にバックエンドがいずれかのリソース (ロードバッファーなど) を使い果たしていることにより生じます。そして、フロントエンドとバックエンドの両方がストールしている場合、そのスロットはバックエンド依存として分類されます。これは、そのような場合にフロントエンドのストールを解決しても、アプリケーションのパフォーマンス改善に直結することが少ないためです。バックエンドがボトルネックであれば、フロントエンドの問題を解決する前にボトルネックを排除する必要があります。
プロセッサーがストールしていない場合、パイプライン・スロットはアロケーションの時点で μop で満たされます。この場合、スロットをどのように分類するか決定する要因は、μop が最終的にリタイアするかどうかです。リタイアすれば、そのスロットはリタイアに分類されます。そうでなければ、フロントエンドによる不適切な分岐予測、もしくは自己修正コードによるパイプライン・フラッシュなどのクリアイベントによって、そのスロットは投機の問題に分類されます。これら 4 つのカテゴリーが、トップダウン特性化のトップレベルを形成します。アプリケーションを特性化するため、それぞれのパイプライン・スロットは 4 つのカテゴリーの 1 つに分類されます。
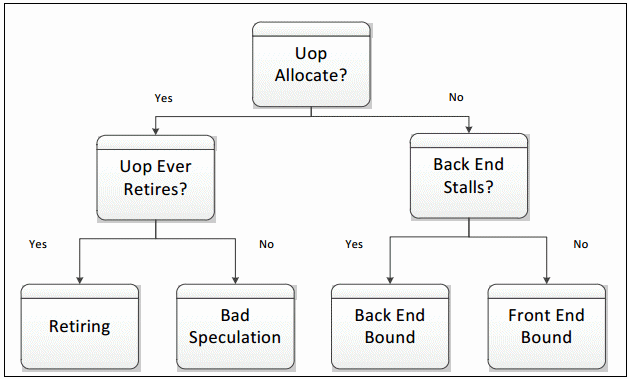
これら 4 つのカテゴリーにおけるパイプライン・スロットの分布は非常に有用です。イベントベースのメトリックは長年使用されてきましたが、この特性化以前は最もパフォーマンスに影響を与える問題を識別する手法はありませんでした。パフォーマンス・メトリックをこのフレームワークに当てはめると、開発者は最初に取り組むべき問題を知ることができます。4 つのカテゴリーにパイプライン・スロットを分類するイベントは、インテル® マイクロアーキテクチャー開発コード名 Sandy Bridge (第 2 世代インテル® Core™ プロセッサー・ファミリーとインテル® Xeon® プロセッサー E5 ファミリー) から利用できます。以降のマイクロアーキテクチャーでは、これらのハイレベルのカテゴリーを、より詳細なパフォーマンス・メトリックに分割できます。
インテル® VTune™ プロファイラーによるトップダウン解析法
インテル® VTune™ プロファイラーは、インテル® マイクロアーキテクチャー開発コード名 Ivy Bridge 以降のトップダウン特性化で定義されたイベント収集のための事前定義を含む [Microarchitecture Exploration (マイクロアーキテクチャー全般)] 解析タイプ (英語) を提供します。マイクロアーキテクチャー全般はまた、その他の有用なパフォーマンス・メトリックの計算に必要なイベントを収集します。マイクロアーキテクチャー全般解析の結果は、デフォルトでは [Microarchitecture Exploration (マイクロアーキテクチャー全般)] ビューポイント (英語) に表示されます。
マイクロアーキテクチャー全般の結果は、トップダウン特性化を補足する階層的なカラムで表示されます。[Summary (サマリー)] ウィンドウは、アプリケーション全体の各カテゴリーのパイプライン・スロットの比率を表示します。結果はさまざまな方法で調査できます。最も一般的な方法は、関数レベルで表示されるメトリックを調査することです。
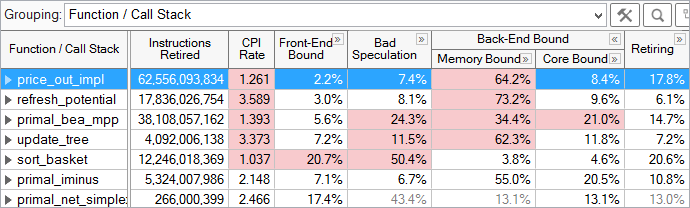
それぞれの関数で、各カテゴリーのパイプライン・スロットが表示されます。例えば、上記で選択されている price_out_impl 関数は、パイプライン・スロットの 2.2% がフロントエンド依存、7.4% が投機の問題、64.2% がメモリー依存、8.4% がコア依存、そして 17.8% がリタイアカテゴリーです。各カテゴリーを展開すると、そのカテゴリーに属するメトリックが表示されます。自動ハイライト機能により、開発者の注意を促す潜在的な問題領域が強調されます。ここでは、price_out_impl のメモリー依存のパイプライン・スロットの比率がハイライトされています。
マイクロアーキテクチャー・チューニングの方法論
パフォーマンス・チューニングを行う際は、常にアプリケーションの上位の hotspot に注目します。「hotspot」は最も CPU 時間を消費している関数です。これらのスポットに注目し、アプリケーションのパフォーマンス全体に影響する最適化を特定します。インテル® VTune™ プロファイラーには、ユーザーモードのサンプリングとハードウェア・イベントベースのサンプリングの 2 つの収集モードを備えた hotspot 解析機能があります。マイクロアーキテクチャー全般ビューポイント内の hotspot は、CPU クロックティック数を測定して、最も高いクロックティック・イベントの関数やモジュールを決定することで特定できます。マイクロアーキテクチャーのチューニングから最大限の利益を得るため、並列処理の追加などのアルゴリズムの最適化がすでに行われていることを確認します。一般にシステムのチューニングが最初に行われ、その後アプリケーション・レベルのアルゴリズムのチューニング、アーキテクチャーとマイクロアーキテクチャーのチューニングへと続きます。この手順は、トップダウンのソフトウェア・チューニング方法論と同様に、「トップダウン」と呼ばれます。ワークロードの選択などその他の重要なパフォーマンス・チューニングについては、「謎めいたソフトウェア・パフォーマンスの最適化を紐解く」 (https://software.intel.com/en-us/articles/de-mystifying-software-performance-optimization) の記事で説明されています。
- hotspot の (アプリケーションの合計クロックティックの大半を占める) 関数を特定します。
- トップダウン法と以下に示すガイドラインを使用して hotspot の効率を評価します。
- 非効率であれば、最も重要なボトルネックを示すカテゴリーをドリルダウンし (掘り下げ)、ボトルネックのサブレベルを調べて原因を特定します。
- 問題を最適化します。インテル® VTune™ プロファイラーのチューニング・ガイドには、各カテゴリーの多くのパフォーマンスの問題に対するチューニングの推奨事項が含まれます。
- 上位の hotspot をすべて評価するまで上記のステップを繰り返します。
インテル® VTune™ プロファイラーは、hotspot が事前定義されたしきい値の範囲を超えている場合、GUI 上のメトリック値を自動的にハイライト表示します。インテル® VTune™ プロファイラーは、アプリケーション内で取得された合計クロックティックの 5% 以上である関数を hotspot として分類します。パイプライン・スロットが特定のカテゴリーのボトルネックを構成するかどうかの判断はワークロードに関係していますが、以下の表に一般的なガイドラインを示します。
| 各カテゴリーのパイプライン・スロットの期待される範囲 (適切に最適化された hotspot) |
|||
|---|---|---|---|
| カテゴリー | クライアント/ デスクトップ向け アプリケーション |
サーバー/データベース/ 分散型アプリケーション |
ハイパフォーマンス・ コンピューティング (HPC) アプリケーション |
| リタイア | 20-50% | 10-30% | 30-70% |
| バックエンド依存 | 20-40% | 20-60% | 20-40% |
| フロントエンド依存 | 5-10% | 10-25% | 5-10% |
| 投機の問題 | 5-10% | 5-10% | 1-5% |
これらのしきい値は、インテルの研究所でいくつかのワークロードを解析した結果に基づいています。hotspot のカテゴリー (リタイアを除く) に費やされた時間が上位にあるか、示される範囲よりも大きい場合、調査が役立つと考えられます。この状況が 1 つ以上のカテゴリーに当てはまる場合、時間が最も上位のカテゴリーを最初に調査します。hotspot が各カテゴリーで時間を費やしていても、その値が通常の範囲内であれば問題は報告されない可能性があることに注意してください。
トップダウン法を適用する際に重要なことは、ボトルネックではないカテゴリーに最適化の時間をかける必要はないということです。最適化を行っても大幅なパフォーマンス向上にはつながりません。
バックエンド依存カテゴリーのチューニング
チューニングされていないアプリケーションのほとんどは、バックエンド依存です。バックエンドの問題を解決するのは、多くの場合、必要以上にリタイアに時間のかかるレイテンシーの原因を解決することです。インテル® マイクロアーキテクチャー開発コード名 Sandy Bridge 向けに、インテル® VTune™ プロファイラーは、高いレイテンシーの原因を検出するためのバックエンド依存メトリックを用意しています。例えば、ラストレベル・キャッシュミス (LLC Miss) メトリックは、データを取得するために DRAM にアクセスする必要があるコード領域を特定し、分割ロード (Split Loads) と分割ストア (Split Stores) メトリックは、パフォーマンスに影響する複数のキャッシュ間のメモリー・アクセス・パターンを指摘します。インテル® マイクロアーキテクチャー開発コード名 Sandy Bridge のメトリックの詳細は、「チューニング・ガイド」を参照してください。インテル® マイクロアーキテクチャー開発コード名 Ivy Bridge (第 3 世代インテル® Core™ プロセッサー・ファミリー) 以降では、バックエンド依存に分類されるイベントが、メモリー依存とコア依存のサブメトリックに区分されています。上位 4 つのカテゴリーに属するメトリックは、パイプライン・スロット・ドメイン以外のドメインを使用する可能性があります。各メトリックは、PMU イベントの最も適切なドメインを使用します。詳細は、各メトリックまたはカテゴリーのドキュメント (英語) を参照してください。
メモリー依存とコア依存のサブメトリックは、トップレベルの分類で使用されるアロケーション・ステージとは対照的に、実行ユニットの使用率に対応するイベントを使用して決定されます。したがって、これらのメトリックの合計は、必ずしもトップレベルで決定されたバックエンド比率と一致するわけではありません (関連性は高い)。
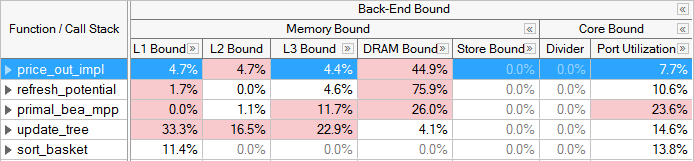
メモリー依存カテゴリーのストールの原因は、メモリー・サブシステムに関連します例えば、キャッシュミスとメモリーアクセスは、メモリー依存のストールの原因となります。コア依存のストールは、各サイクルで CPU の実行ユニットが十分に利用されていないことが原因で発生します。例えば、連続する複数の除算命令は、除算ユニットの競合を引き起こし、コア依存のストールの原因となります。この分類では、ストールで未完了のメモリーアクセスがない場合、そのスロットはコア依存に分類されます。例えば、遅延しているロードがある場合、ロードがまだデータを取得していないことが原因で実行ユニットが待機しているため、サイクルはメモリー依存に分類されます。PMU イベントは、アプリケーションの真のボトルネックを特定するのに役立つ分類が可能になるように、ハードウェアで実装されています。バックエンドの問題のほとんどは、メモリー依存カテゴリーに区分されます。
メモリー依存カテゴリーのほとんどのメトリックは、L1 キャッシュからメモリーまでの、ボトルネックになっているメモリー階層のレベルを特定します。この決定に使用されるイベントは注意深く設計されています。一旦バックエンドがストールすると、メトリックは遅延中の特定のキャッシュレベルへのロード、または実行中のストアのストールを区分しようとします。hotspot が特定のレベルで制限されている場合、そのデータの多くはキャッシュやメモリー階層から取得されていることを意味します。最適化の際は、コアに近い位置にデータを移動することに注目します。ストア依存 (Store Bound) は、パイプラインを進行中のロードが直前のストアに依存しているなどの依存性を示すサブカテゴリーとしても利用されます。これらのカテゴリーには、メモリー依存実行の原因となるアプリケーション固有の動作を特定するメトリックがあります。例えば、ストアフォワードでブロックされたロード (Loads Blocked by Store Forwarding) と 4K エリアス (4K Aliasing) は、アプリケーションが L1 依存 (L1 Bound) であることを示すメトリックです。
コア依存のストールは、バックエンド依存ではそれほど多くはありません。これらのストールは、大量のメモリー要求がないために利用可能な計算リソースが効率的に利用されない場合に発生します。例えば、浮動小数点 (FP) 数値計算を小さなループで行い、データがキャッシュに収まる場合などです。インテル® VTune™ プロファイラーは、このカテゴリーの動作を検出するいくつかのメトリックを用意しています。例えば、除算器 (Divider) メトリックは、除算器ハードウェアが頻繁に使用されたサイクルを特定し、ポート使用率 (Port Utilization) メトリックは実行ユニットの個々の競合を特定します。
注
灰色で表示されるメトリック値は、このメトリックで収集されたデータの信頼性が低いことを表します。これは、収集された PMU イベントのサンプル数が非常に少ないことが原因であると考えられます。このデータは無視できますが、収集に戻ってデータ収集時間、サンプリングの間隔、またはワークロードを増やして再度収集することもできます。
フロントエンド依存カテゴリーのチューニング
フロントエンド依存カテゴリーは、ほかのタイプのパイプライン・ストールをいくつかカバーします。パイプラインのフロントエンド部分がアプリケーションのボトルネックになることは、それほど多くはありません。例えば、JIT コードとインタープリターで解釈されるコードは、命令ストリームが動的に生成される (コンパイラーによるコード配置の利点が得られない) ため、フロントエンド・ストールの原因となります。フロントエンド依存カテゴリーのパフォーマンスの改善は、通常、コード配置 (ホットなコードと隣接して配置) とコンパイラーのテクニックに関連します。例えば、分岐の多いコードや大きなフットプリントのコードは、フロントエンド依存カテゴリーで警告されます。コードサイズの最適化やコンパイラーによるプロファイル・ガイド最適化 (PGO) などのテクニックは、多くの場合ストールを軽減するのに有効です。
インテル® マイクロアーキテクチャー開発コード名 Ivy Bridge 以降のトップダウン法では、フロントエンド依存のストールがフロントエンド・レイテンシーとフロントエンド帯域幅の 2 つのカテゴリーに分離されました。フロントエンド・レイテンシー (Front-End Latency) メトリックは、バックエンドの準備ができているにもかかわらず、フロントエンドによって μop が発行されないサイクルを報告します。フロントエンド・クラスターは、サイクルあたり最大 4μop を発行できることを思い出してください。フロントエンド帯域幅 (Front-End Bandwidth) メトリックは、発行された μop が 4 未満のサイクル、つまり、フロントエンドの能力を使い切っていないサイクルを報告します。各カテゴリーの下には、さらにメトリックがあります。
分岐予測ミスは、多くの場合、投機の問題カテゴリーに分類されますが、インテル® マイクロアーキテクチャー開発コード名 Ivy Bridge 以降では、フロントエンドに属する分岐リステア (Branch Resteer) メトリックによって、フロントエンドが非効率になったことが示されます。
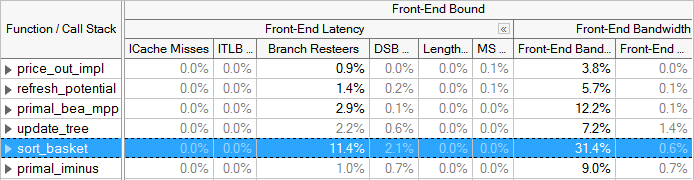
インテル® VTune™ プロファイラーは、フロントエンド依存の原因を特定するメトリックの一覧を表示します。これらのカテゴリーのいずれかの結果が顕著な場合、メトリックをさらに深く調査して原因を特定し、修正する方法を考えます。例えば、命令トランスレーション・ITLB オーバーヘッド (ITLB Overhead) と命令キャッシュミス (ICache Miss) メトリックは、フロントエンド依存の実行で問題のある領域が分かります。チューニングの推奨事項は、インテル® VTune™ プロファイラーのチューニング・ガイドを参照してください。
投機の問題カテゴリーのチューニング
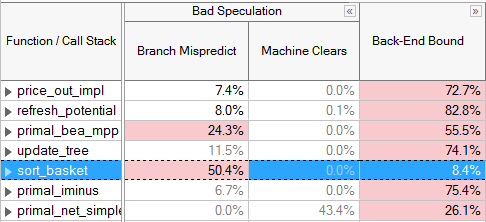
3 番目のトップレベルのカテゴリー、投機の問題は、パイプラインがリタイアしない命令をフェッチして実行しているためにビジーであることを示します。投機の問題のパイプライン・スロットは、マシンが不適切な投機実行から回復する間、リタイアしないまたはストールする μop が発行されることでスロットが浪費されている状態です。投機の問題は、分岐予測ミスとマシンクリア、および (一般的ではありませんが) 自己修正コードによって引き起こされます。投機の問題は、コンパイラーによるプロファイル・ガイド最適化 (PGO)、間接分岐の回避、およびマシンクリアを引き起こすエラー条件の排除などのテクニックで軽減できます。投機の問題を解決することは、フロントエンド依存のストール数を減らすのに役立ちます。特定のチューニングのテクニックについては、適切なマイクロアーキテクチャー向けのインテル® VTune™ プロファイラーのチューニング・ガイドを参照してください。
リタイアカテゴリーのチューニング
トップレベルの最後のカテゴリー、リタイアは、パイプラインが通常動作の実行でビジーであることを意味します。可能であれば、このカテゴリーにアプリケーションの多くのスロットが分類されるのが理想的です。しかし、パイプライン・スロットでリタイアする大部分がコード領域であれば、改善の余地はあります。リタイアカテゴリーの 1 つのパフォーマンスの問題は、マイクロシーケンサーの高い利用率です。これは、特定の条件が記述された μop の長いストリームを生成することで、フロントエンドをアシストします。この場合、多くの μop がリタイアしますが、いくつかは回避することが可能です。例えば、FP アシストはデノーマルイベントに適用され、多くの場合、コンパイラーのオプション (DAZ や FTZ) によって軽減できます。コード生成の選択もまた、これらの問題を軽減するのに役立ちます。詳細は、インテル® VTune™ プロファイラーのチューニング・ガイドを参照してください。インテル® マイクロアーキテクチャー開発コード名 Sandy Bridge では、アシスト (Assists) はリタイアカテゴリーのメトリックとして分類されます。インテル® マイクロアーキテクチャー開発コード名 Ivy Bridge 以降では、リタイアカテゴリーのパイプラインは、全般リタイア (General Retirement) と呼ばれるサブカテゴリーに分割され、マイクロコード・シーケンサーの μop は別に識別されます。
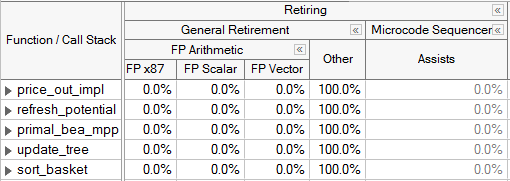
まだ行っていない場合、アルゴリズムの並列化やベクトル化によるチューニングは、リタイアカテゴリーでのコード領域のパフォーマンスを改善するのに役立ちます。
まとめ
トップダウン法とインテル® VTune™ プロファイラーにおけるその有効性は、PMU を使用したパフォーマンス・チューニングの新たな方向性を示しています。開発者がこの特性化を習得するために費やす時間は価値あるものです。特性化のサポートは最近の PMU 向けに設計されており、その階層構造は将来のインテル® マイクロアーキテクチャーにも拡張可能です。例えば、特性化は、インテル® マイクロアーキテクチャー開発コード名 Sandy Bridge からインテル® マイクロアーキテクチャー開発コード名 Ivy Bridge の間で大幅に拡張されました。
トップダウン法の目標は、アプリケーション・パフォーマンスのボトルネックの種類を特定することです。インテル® VTune™ プロファイラーの全般解析と可視化機能の目標は、アプリケーションを改善するために適用可能な情報を提供することです。これらを併用することで、アプリケーションのパフォーマンスを大幅に改善できるだけでなく、最適化における生産性も向上できます。
関連クックブック・レシピ
関連情報
- マイクロアーキテクチャー・パイプ (英語)
- マイクロアーキテクチャー全般ビュー (英語)
- チューニング・ガイドとパフォーマンス解析の記事
- クロックティックとパイプライン・スロット・ベースのメトリック
(https://software.intel.com/en-us/vtune-amplifier-help-clockticks-vs-pipeline-slots-based-metrics)
