
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Profiling MPI Applications」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、インテル® VTune™ Amplifier を使用して MPI アプリケーションのインバランスと通信の問題を特定し、アプリケーション・パフォーマンスを向上します。
コンテンツ・エキスパート: Carlos Rosales-fernandez
- 使用するもの
- 手順:
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: heart_demo サンプル・アプリケーション。GitHub* https://github.com/CardiacDemo/Cardiac_demo.git (英語) からダウンロードできます。
- ツール:
- インテル® C++ コンパイラー
- インテル® MPI ライブラリー 2019
- インテル® VTune™ Amplifier2019
- インテル® VTune™ Amplifier アプリケーション・パフォーマンス・スナップショット
注
- インテル® MPI ライブラリーは、https://www.isus.jp/intel-mpi-library/ から利用できます。
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- オペレーティング・システム: Linux*
- CPU: インテル® Xeon® Platinum 8168 プロセッサー (開発コード名 Skylake)
- ネットワーク・ファブリック: インテル® Omni-Path アーキテクチャー (インテル® OPA)
アプリケーションをビルドする
インテル® VTune™ Amplifier がパフォーマンス・データをソースコードとアセンブリーに関連付けることができるように、デバッグシンボル付きでアプリケーションをビルドします。
- GitHub* リポジトリーのアプリケーションをローカルシステムにクローンします。
git clone https://github.com/CardiacDemo/Cardiac_demo.git
- インテル® C++ コンパイラーとインテル® MPI ライブラリーの環境を設定します。
source <compiler_install_dir>/bin/compilervars.sh intel64 source <mpi_install_dir>/bin/mpivars.sh
- サンプルパッケージのルートレベルに build ディレクトリーを作成し、作成したディレクトリーに移動します。
mkdir build cd build
- 次のコマンドを使用してアプリケーションをビルドします。
mpiicpc ../heart_demo.cpp ../luo_rudy_1991.cpp ../rcm.cpp ../mesh.cpp -g -o heart_demo -O3 -std=c++11 -qopenmp -parallel-source-info=2
heart_demo 実行ファイルが現在のディレクトリーに作成されます。
全体的なパフォーマンス特性を確立する
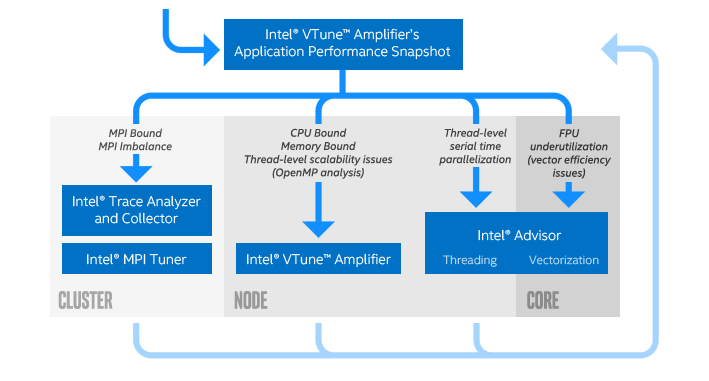
インテル® ソフトウェア開発ツールを使用するアプリケーション・チューニングの推奨ワークフローでは、最初にアプリケーション・パフォーマンスのスナップショットを取得してから、最適なツールを使用して問題に注目します。インテル® VTune™ Amplifier のアプリケーション・パフォーマンス・スナップショットは、シンプルなインターフェイスと低オーバーヘッドの実装で、アプリケーションの全体的なパフォーマンス特性を提供します。特定の問題を詳しく調査する前に、アプリケーション・パフォーマンス・スナップショットを使用してアプリケーションの一般的な特性を理解します。
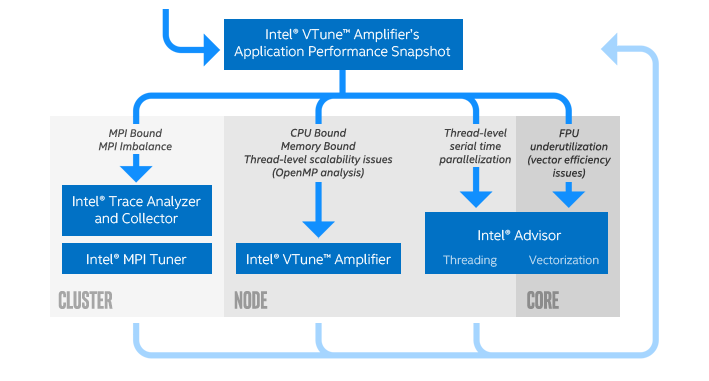
インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Skylake) を使用して、デュアル・ソケット・ノードのセットのパフォーマンス・スナップショットを取得します。この例では、ソケットあたり 24 コアのインテル® Xeon® Platinum 8168 プロセッサーを使用して、ノードごとに 4 MPI ランク、ランクごとに 12 スレッドで実行するように設定します。ランクとスレッドの数は、使用しているシステムの要件に応じて変更してください。
対話型セッションまたはバッチスクリプトで次のコマンドを実行して、4 ノードのパフォーマンス・スナップショットを取得します。
export OMP_NUM_THREADS=12 mpirun –np 16 –ppn 4 aps ./heart_demo -m ../mesh_mid -s ../setup_mid.txt -t 100
解析が完了すると、aps_result_YYYYMMDD という名前のディレクトリーとプロファイル・データが生成されます。ここで、YYYY は収集の年、MM は月、DD は日を表します。次のコマンドを実行して、結果の HTML スナップショットを生成します。
aps --report=./aps_result_20190125
作業ディレクトリーに aps_report_YYYYMMDD_<stamp>.html ファイルが作成されます。<stamp> 番号は、既存のレポートが上書きされるのを防ぐために追加されます。レポートには、MPI と OpenMP* のインバランス、メモリー・フットプリントと帯域幅の利用率、浮動小数点演算のスループットを含む、全体的なパフォーマンスに関する情報が含まれます。レポートの上部の説明は、アプリケーションの主な問題を示しています。
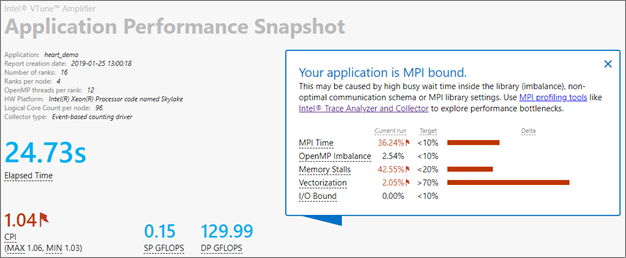
このアプリケーションは全体的に MPI 通信に依存していますが、メモリーとベクトル化の問題もあります。[MPI Time (MPI 時間)] セクションは、MPI インバランスや使用された上位の MPI 関数呼び出しなど、追加の情報を提供します。この情報から、コードは主にポイントツーポイント通信を使用しており、インバランスは中程度であることが分かります。
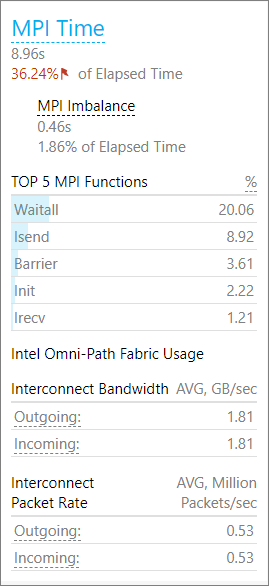
この結果は、コードに複雑な問題があることを示しています。パフォーマンスの問題をさらに詳しく調査し、問題を切り分けるため、インテル® VTune™ Amplifier の HPC パフォーマンス特性解析を使用します。
HPC パフォーマンス特性解析を設定して実行する
ほとんどのクラスターは、ログインノードと計算ノードで構成されています。通常、ユーザーはログインノードに接続し、スケジューラーを使用してジョブを計算ノードに送信し、ジョブが実行されます。クラスター環境でインテル® VTune™ Amplifier を使用して MPI アプリケーションをプロファイルする最も実用的な方法は、コマンドラインでデータを収集し、ジョブが完了したら GUI でパフォーマンス解析を行います。
MPI 関連のメトリックのレポートは、コマンドラインから簡単に取得できます。一般に、分散環境で実行する最も簡単な方法は、次のようにコマンドを作成することです。
<mpi launcher> [options] amplxe-cl [options] –r <results dir> — <application> [arguments]
注
- コマンドは、対話型セッションで使用することも、バッチ送信スクリプトに含めることもできます。
- MPI アプリケーションでは、結果ディレクトリーを指定する必要があります。
- インテル® MPI ライブラリーを使用していない場合は、-trace-mpi を追加します。
次の手順に従って、コマンドラインから HPC パフォーマンス特性解析を実行します。
- 関連するインテル® VTune™ Amplifier ファイルを source して環境を設定します。bash シェルを使用するデフォルトのインストールでは、次のコマンドを使用します。
source /opt/intel/vtune_amplifier/amplxe-vars.sh
- hpc-performance 解析を使用して heart_demo アプリケーションのデータを収集します。このアプリケーションは、OpenMP* と MPI の両方を使用して、前述の構成 (インテル® MPI ライブラリーを使用して 4 つの計算ノード、16 の MPI ランク) で実行されます。実行には、インテル® Xeon® Platinum 8168 プロセッサーと MPI ランクごとに 12 の OpenMP* スレッドを使用します。
export OMP_NUM_THREADS=12 mpirun –np 16 –ppn 4 amplxe-cl –collect hpc-performance –r vtune_mpi -- ./heart_demo -m ../mesh_mid -s ../setup_mid.txt -t 100
解析が開始され、次の命名規則に従って 4 つの出力ディレクトリーが生成されます: vtune_mpi.<node host name>。
注
ほかの MPI ランクを同時に実行しながら、特定の MPI ランクのみプロファイル・データを収集するように選択できます。詳細は、「選択した MPI ランクのプロファイル」 (https://software.intel.com/en-us/articles/using-intel-advisor-and-vtune-amplifier-with-mpi) を参照してください。
インテル® VTune™ Amplifier GUI で結果を解析する
インテル® VTune™ Amplifier のグラフィカル・インターフェイスは、収集したパフォーマンス・データを解析するため、コマンドラインよりも豊富な機能とインタラクティブな体験を提供します。次のコマンドを実行して、結果をインテル® VTune™ プロファイラー GUI で開きます。
amplxe-gui ./vtune_mpi.node_1
注
インテル® VTune™ Amplifier GUI を表示するには、ローカルシステムで実行されている X11 マネージャー、またはシステムに接続されている VNC セッションが必要です。システムはそれぞれ異なるため、推奨される方法についてはローカル管理者に相談してください。
結果がインテル® VTune™ Amplifer で開き、アプリケーション・パフォーマンスの概要を示す [Summary (サマリー)] ウィンドウが表示されます。heart_demo は MPI 並列アプリケーションであるため、[Summary (サマリー)] ウィンドウに通常のメトリックに加えて、[MPI Imbalance (MPI インバランス)] 情報と実行クリティカル・パスの MPI ランクに関する詳細が表示されます。
- [MPI Imbalance (MPI インバランス)] は、ノード上のすべてのランクの平均 MPI ビジー待機時間です。この値は、バランスが理想的であれば節約できる時間を示します。
- [MPI Rank on the Critical Path (クリティカル・パス上のランク)] は、最小ビジー待機時間のランクです。
- [MPI Busy Wait Time (MPI ビジー待機時間)] と [Top Serial Hotspots (上位のシリアル・ホットスポット)] は、クリティカル・パスのランクに対して表示されます。通常、インバランスやビジー待機メトリックの値が高い場合スケーラビリティーが制限されるため、これはスケーラビリティーの問題を特定する良い方法です。マルチノード実行でクリティカル・パス上のランクの [MPI Busy Wait Time (MPI ビジー待機時間)] が大きい場合、ほかのノード上に外れ値のランクがある可能性があります。
この例では、インバランスがあり、コードのシリアル領域で多くの時間が費やされています (以下の図には表示されていません)。
![[Summary (サマリー)] ウィンドウは、[Effective Physical Core Utilization (効率的な物理コア利用率)]、[Effective Logical Core Utilization (効率的な論理コア利用率)]、および [Serial Time (シリアル時間)] の効率が悪いことを示しています。](https://www.isus.jp/wp-content/uploads/image/vtune-cookbook-22614073-EC69-4EF1-BA4C-E25F3CC920CF.png)
プロファイルはノード全体で収集されるかもしれませんが、すべての MPI データを確認するには、各ノードの結果を個別にロードする必要があります。詳細な MPI トレースには、インテル® Trace Analyzer & Collector を推奨します。
インテル® VTune™ Amplifer 2019 以降では、[Summary (サマリー)] ウィンドウにインテル® Omni-Path アーキテクチャー (インテル® OPA) ファブリックの使用分布図が含まれます。これらのメトリックは帯域幅とパケットレートを表示し、実行時間に占めるコードが高帯域幅使用率や高パケットレート使用率によって制限されていた割合 (%) を示します。heart_demo アプリケーションは、帯域幅やパケットレートによって制限されていませんが、分布図は平均に近い 1.8GB/秒の最大帯域幅使用率を示しています。これは、MPI 通信の継続的で非効率的な使用を示唆しています。
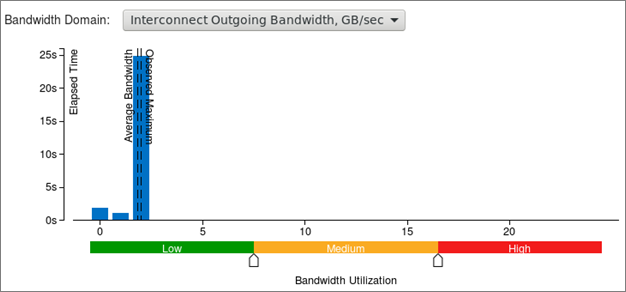
[Bottom-up (ボトムアップ)] タブに切り替えてさらに詳しく調査します。次のような表示になるように、[Grouping (グループ化)] で Process (プロセス) がトップレベルになるように設定します。
![[OpenMP Potential Gain (OpenMP* 潜在的なゲイン)] と [MPI Busy Wait Time (MPI ビジー待機時間)] がハイライト表示された [Bottom-up (ボトムアップ)] タブ](https://www.isus.jp/wp-content/uploads/image/vtune-cookbook-B45D06D7-18B0-4CE4-B865-4A93180B801B.png)
このコードは MPI と OpenMP* の両方を使用するため、[Bottom-up (ボトムアップ)] ウィンドウには通常の CPU とメモリーのデータに加えて、両方のランタイムに関連したメトリックが表示されます。この例では、クリティカル・パスから最も離れている MPI ランクの [MPI Busy Wait Time (MPI ビジー待機時間)] メトリックが赤色で示されています。また、最も大きな [OpenMP Potential Gain (OpenMP* 潜在的なゲイン)] も赤色で示されています。これは、スレッド化を改善することで、パフォーマンスが向上する可能性を示唆しています。
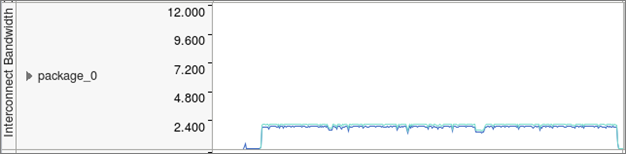
[Bottom-up (ボトムアップ)] ウィンドウの下部で DDR と MCDRAM 帯域幅、CPU 時間、インテル® OPA 使用率を含むいくつかのメトリックの実行タイムラインを確認します。このコードのインターコネクト帯域幅のタイムラインは、適度な帯域幅 (GB/秒単位) で継続的な使用率を示しています。これは、分散コンピューティングで一般的な間違いの 1 つである、小さなメッセージの通常の MPI 交換が原因です。
より興味深いことは、スレッドごとの詳細な実行時間と [Effective Time (有効時間)]、[Spin and Overhead Time (スピンとオーバーヘッド時間)]、および [MPI Busy Wait Time (MPI ビジー待機時間)] の内訳です。デフォルトのビューは [Super Tiny (最小)] 設定で、パフォーマンスのビジュアルマップにすべてのプロセスとスレッドをまとめて表示します。
![CPU 時間の [Super Tiny (最小)] ビュー](https://www.isus.jp/wp-content/uploads/image/vtune-cookbook-B24A2E01-3C91-424D-B225-96A06A76FA35.png)
このケースでは、ほとんどのスレッドで有効時間がわずかしかなく (緑色)、MPI オーバーヘッドの量もわずかです (黄色)。これは、スレッド化の実装に潜在的な問題があることを示しています。
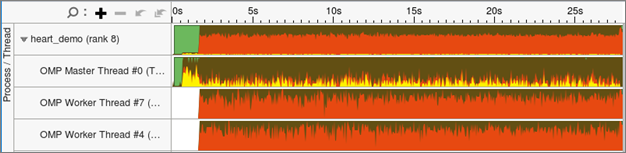
さらに詳しく調査するため、グラフの左側の灰色の領域を右クリックして、[Rich (最大)] ビューを選択します。次に、各 MPI ランクと各スレッドの役割がより明確になるように、グラフの右側で [Process/Thread (プロセス/スレッド)] を選択して結果をグループ化します。このグループ化を使用することで、各プロセスの最上部のバーはすべての子スレッドの平均結果を示し、その下に各スレッドがスレッド番号とプロセス ID とともにリストされます。
この例では、マスタースレッドが各 MPI ランクのすべての MPI 通信を明確に処理しています。これはハイブリッド・アプリケーションでは一般的です。実行の最初の 10 秒間は、MPI 通信 (黄色) に多くの時間が費やされています。ここでは、問題のセットアップとデータの分配が行われていると考えられます。その後は通常の MPI 通信となり、[Bandwidth Utilization (帯域幅使用率)] タイムラインと [Summary (サマリー)] レポートの結果と一致しています。
スピンとオーバーヘッド (デフォルトでは赤色で表示) が高いことが分かります。これは、アプリケーションのスレッド化の実装に問題があることを示しています。[Bottom-up (ボトムアップ)] ウィンドウの上部で、[OpenMP Region / Thread / Function / Call Stack (OpenMP* 領域/スレッド/関数/コールスタック)] を選択してデータをグループ化し、ウィンドウ下部のフィルターを適用して [Functions only (関数のみ)] を表示します。ツリーを展開すると、init_send_bufs 関数はスレッド 0 以外から呼び出されていないことが分かります。これが、パフォーマンス低下の原因です。この行をダブルクリックするとソースコード・ビューが開きます。コードを調査すると、関数の外側のループを並列化し、この問題を修正する簡単な方法があることが分かります。
(オプション) インテル® VTune™ Amplifier GUI でコマンドラインを生成する
インテル® VTune™ Amplifier のあまり知られていない便利な機能は、GUI を使用して解析を設定し、対応するコマンドラインを保存して、コマンドラインから直接使用できます。これは、高度にカスタマイズされたプロファイルや複雑なコマンドを素早く作成するのに便利です。
- インテル® VTune™ Amplifier を起動して、[New Project (新規プロジェクト)] をクリックするか、既存のプロジェクトを開きます。
- [Configure Analysis (解析の設定)] をクリックします。
- [WHERE (どこを)] ペインで [Arbitrary Host (not connected) (任意のホスト (未接続))] を選択し、ハードウェア・プラットフォームを指定します。
- [WHAT (何を)] ペインで次の操作を行います。
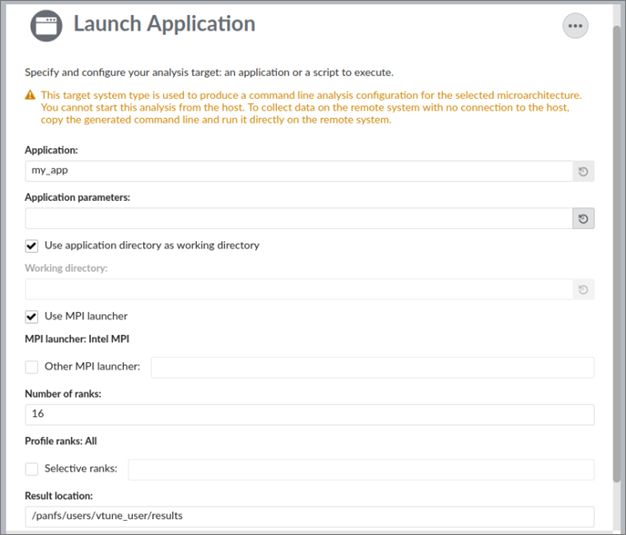
- アプリケーションを指定して、引数と作業ディレクトリーを設定します。
- [Use MPI launcher (MPI ランチャーを使用)] チェックボックスをオンにして、MPI 実行に関連した情報を指定します。
- (オプション) プロファイルする特定のランクを選択します。
- [HOW (どのように)] ペインでデフォルトの [Hotspots (ホットスポット)] 解析から [HPC Performance Characterization (HPC パフォーマンス特性)] 解析に変更し、利用可能なオプションをカスタマイズします。

- ウィンドウの下部にある [Command Line (コマンドライン)] ボタン
 をクリックします。ポップアップ・ウィンドウが開き、GUI で設定したカスタム解析に対応するコマンドラインが表示されます。必要に応じて、コマンドにその他の MPI オプションを追加できます。
をクリックします。ポップアップ・ウィンドウが開き、GUI で設定したカスタム解析に対応するコマンドラインが表示されます。必要に応じて、コマンドにその他の MPI オプションを追加できます。
注
インテル® MPI ライブラリーの場合、コマンドラインは -gtool オプションで生成されます。これにより、選択したランクのプロファイル構文が非常に簡潔になります。
(オプション) コマンドライン・レポートを使用して結果を解析する
インテル® VTune™ Amplifier は、有益なコマンドライン・テキスト・レポートを提供します。例えば、サマリーレポートを取得するには、次のコマンドを実行します。
amplxe-cl -report summary -r ./results_dir
結果のサマリーが画面に出力されます。結果を直接ファイルに保存したり、別のファイル形式 (csv、xml、html) で保存するオプションなど、その他のオプションも利用できます。コマンドライン・オプションの詳細は、amplxe-cl -help コマンドで確認するか、ユーザーガイド (英語) を参照してください。
(オプション) 選択したコード領域をプロファイルする
デフォルトでは、インテル® VTune™ Amplifier はアプリケーション全体のパフォーマンス統計を収集しますが、バージョン 2019 Update 3 以降では MPI アプリケーションのデータ収集を制御する機能が追加されました。この機能を使用することで、高速に処理可能な小さな結果ファイルを生成して、対象コード領域に注目できます。
領域の選択は、MPI_Pcontrol 関数を使用して行います。MPI_Pcontrol(0) 呼び出しでデータ収集を一時停止し、MPI_Pcontrol(1) 呼び出しで再開します。API と -start-paused コマンドライン・オプションを一緒に使用して、アプリケーションの初期化フェーズを除外できます。この場合、初期化の直後に MPI_Pcontrol(1) を呼び出してデータ収集を再開します。この方法では、スタティック ITT API ライブラリーへのリンクが必要な ITT API 呼び出しを使用する場合とは異なり、アプリケーションのビルドプロセスの変更が不要です。
注
このレシピの情報は、デベロッパー・フォーラム (英語) を参照してください。
| 最適化に関する注意事項 |
|---|
| インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。 注意事項の改訂 #20110804 |
