
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Profiling Machine Learning Applications」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピでは、インテル® VTune™ プロファイラーを使用して、マシンラーニング (ML) のワークロードをプロファイルする方法を紹介します。
ソフトウェアやウェブベースのアプリケーションによってデジタル化が進み、マシンラーニング (ML) アプリケーションの普及が拡大しています。ML コミュニティーは、Tensorflow*、PyTorch*、Keras* などのディープラーニング (DL) フレームワークを使用して、実世界の問題を解決しています。
しかし、Python* や C++ などの DL コードにおける計算やメモリーのボトルネックを理解することは困難であり、階層的なレイヤーや非線形関数の存在により、しばしば多大な労力を必要とします。Tensorflow* や PyTorch* などのフレームワークは、ディープラーニング・モデル開発のさまざまな段階でパフォーマンス・メトリックの収集と解析を可能にするネイティブツールや API を提供していますが、その範囲は限定的であり、ディープライニング・モデル内のさまざまな演算子や関数を最適化するのに役立つ、ハードウェア・レベルの詳細は提供しません。
このレシピでは、インテル® VTune™ プロファイラーで Python* ワークロードをプロファイルし、追加の API を使用してデータ収集を改善する方法を学びます。
コンテンツ・エキスパート: Rupak Roy (英語)
使用するもの
以下は、このパフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
アプリケーション: TensorFlow_HelloWorld.py (英語) および Intel_Extension_For_PyTorch_Hello_World.py (英語)。どちらも、畳み込みレイヤー、正規化レイヤー、ReLU レイヤーを持つ単純なニューラル・ネットワークの実装であり、トレーニングと評価が可能です。
解析ツール: インテル® VTune™ プロファイラー 2022 以降のユーザーモード・サンプリングとトレース収集
注:
バージョン 2020 から、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックの大部分のレシピは、異なるバージョンのインテル® VTune™ プロファイラーにも適用できます。バージョンにより、調整が必要になる場合があります。
最新バージョンのインテル® VTune™ プロファイラーは以下から入手できます。
CPU: 第 11 世代インテル® Core™ i7-1165G7 プロセッサー @ 2.80GHz
オペレーティング・システム: Ubuntu* Server 20.04.5 LTS
Python* アプリケーションでのインテル® VTune™ プロファイラーの実行
まず、Intel_Extension_For_PyTorch_Hello_World.py ML アプリケーションに対して、コードを変更せずにホットスポット解析 (英語) を実行します。この解析は、コード内の最も時間のかかる領域を特定する良い出発点です。
コマンドラインで、次のコマンドを入力します。
$vtune -collect hotspots -knob sampling-mode=sw -knob enable-stack-collection=true -source-search-dir=path_to_src -search-dir /usr/bin/python3 -result-dir vtune_hotspots_results -- python3 Intel_Extension_For_PyTorch_Hello_World.py
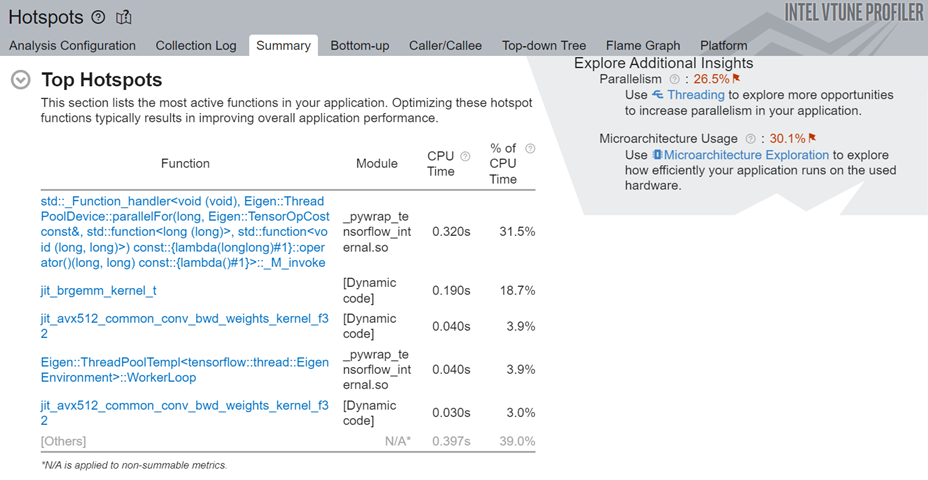
解析が完了したら、[Summary (サマリー)] ウィンドウの [Top Hotspots (上位のホットスポット)] セクションを調べて、コード内の最もアクティブな関数を確認します。

この例では、sched_yield 関数に多くの CPU 時間が費やされています。この関数を頻繁に呼び出すと、不要なコンテキスト・スイッチが発生し、アプリケーション・パフォーマンスが低下します。
次に、アプリケーションの上位のタスクを確認します。
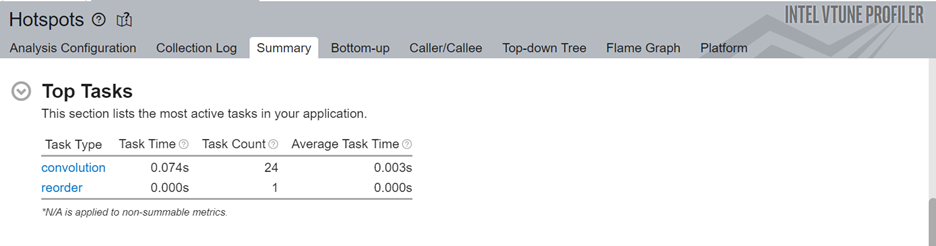
ここでは、convolution (畳み込み) タスクが最も処理時間を費やしていることが分かります。
[Bottom-up (ボトムアップ)] ウィンドウに切り替えてより深く掘り下げることができますが、最適化の候補となる領域を特定するのは難しいでしょう。特に、大規模なアプリケーションでは、コードの各レイヤーにモデル演算子や関数が多数存在する可能性があります。そこで、コードにインテル® インストルメンテーションおよびトレーシング・テクノロジー (ITT) API を追加して、解釈しやすい結果を生成します。
ITT-Python API の追加
インテル® VTune™ プロファイラーで使用されるインテル® インストルメンテーションおよびトレーシング・テクノロジー (ITT) API に、ITT-Python (英語) の Python* バインディングを追加します。このバインディングには、データ収集を制御するユーザー・タスク・ラベルと、タスク・インスタンスの作成と破棄を行うユーザータスク API が含まれます。
ITT-Python は 3 種類の API を使用します。
- ドメイン API
- domain_create(name)
- タスク API
- task_begin(domain, name)
- task_end(domain)
- 異常検出 API
- itt_pt_region_create(name)
- itt_pt_region_begin(region)
- itt_pt_region_end(region)
TensorFlow_HelloWorld.py (英語) の以下のコードは、ITT-Python のドメイン API とタスク API を呼び出します。
itt.resume()
domain = itt.domain_create("Example.Domain.Global")
itt.task_begin(domain, "CreateTrainer")
for epoch in range(0, EPOCHNUM):
for step in range(0, BS_TRAIN):
x_batch = x_data[step*N:(step+1)*N, :, :, :]
y_batch = y_data[step*N:(step+1)*N, :, :, :]
s.run(train, feed_dict={x: x_batch, y: y_batch})
'''Compute and print loss. We pass Tensors containing the predicted and true values of y, and the loss function returns a Tensor containing the loss.'''
print(epoch, s.run(loss,feed_dict={x: x_batch, y: y_batch}))
itt.task_end(domain)
itt.pause()
上記のコードで行われている一連の操作を以下に示します。
- itt.resume() API を使用して、ループが実行を開始する直前にプロファイルを再開します。
- 大部分の ITT API 呼び出し用に ITT ドメイン (Example.Domain.Global など) を作成します。
- itt.task.begin() API を使用して、タスクを開始します。タスクに CreateTrainer というラベルを付けます。このラベルはプロファイル結果に表示されます。
- itt.task() API を使用して、タスクを終了します。
- itt.pause() API を使用して、データ収集を一時停止します。
ホットスポット解析とマイクロアーキテクチャー全般解析の実行
コードを変更したら、変更したコードのホットスポット解析を実行します。
$vtune -collect hotspots -start-paused -knob enable-stack-collection=true -knob sampling-mode=sw -search-dir=/usr/bin/python3 -source-search-dir=path_to_src -result-dir vtune_data -- python3 TensorFlow_HelloWorld.py
このコマンドは、-start-paused パラメーターを使用して、ポーズ状態で解析を開始し、ITT-Python API によってマークされたコード領域のみをプロファイルします。新しいホットスポット解析の結果を確認します。[Top Hotspots (上位のホットスポット)] セクションには、ITT-Python API によってマークされたコード領域のホットスポットが表示されます。
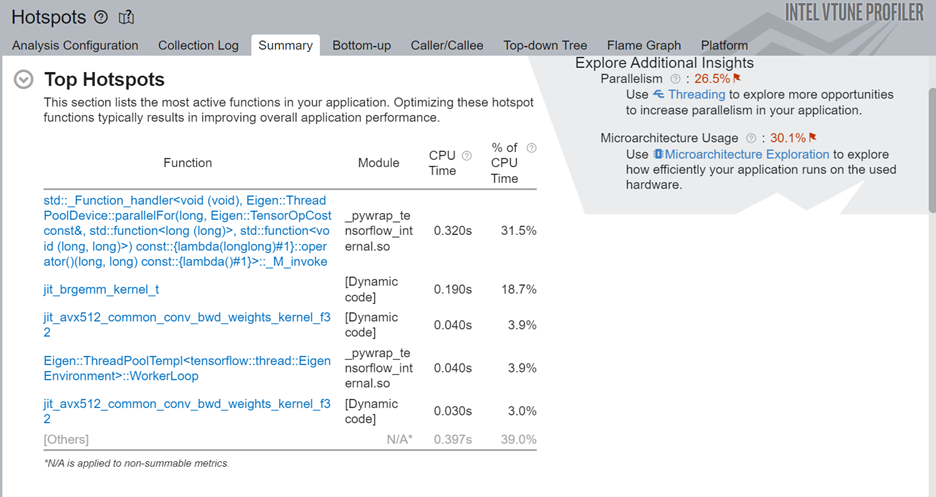
ターゲットコード領域で最も時間を費やしている ML プリミティブを調べます。最適化を改善するため、まずこれらのプリミティブに注目します。ITT-API を使うことで、ML プリミティブに関連するホットスポットを素早く特定できます。
次に、ITT-Python API ターゲットの上位タスクを確認します。API によりプロファイル結果を特定のコード領域に限定できるため、このセクションの ITT 論理タスクには以下のような情報が表示されます。
- CPU 時間
- 有効時間
- スピン時間
- オーバーヘッド時間
- CPU 利用率時間
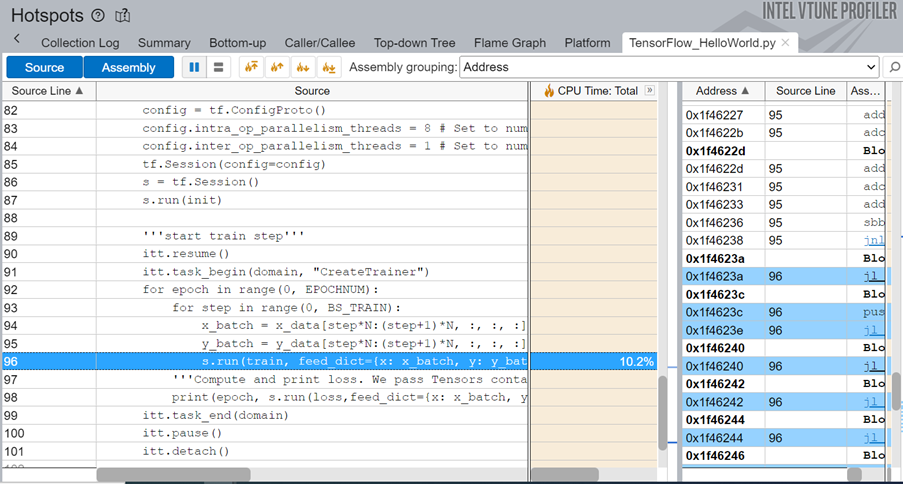
- ソースコード行レベルの解析
ML コードのソース行レベルのプロファイルにより、CPU 時間のソース行ごとの内訳が明らかになります。この例では、コードの実行時間の 10.2% がモデルのトレーニングに費やされています。
アプリケーションのパフォーマンスをより深く理解するため、マイクロアーキテクチャー全般解析 (英語) を実行してみましょう。コマンドラインで、次のコマンドを入力します。
$vtune -collect uarch-exploration -knob collect-memory-bandwidth=true -source-search-dir=path_to_src -search-dir /usr/bin/python3 -result-dir vtune_data_tf_uarch -- python3 TensorFlow_HelloWorld.py
解析が完了すると、[Bottom-up (ボトムアップ)] ウィンドウに ITT-Python API でマークされたタスクの詳細なプロファイル情報が表示されます。CreateTrainer タスクはフロントエンドに依存しており、フロントエンドからバックエンドに十分な操作が供給されていないことが分かります。また、重い操作 (2µops 以上を必要とする操作) の割合が高くなっています。
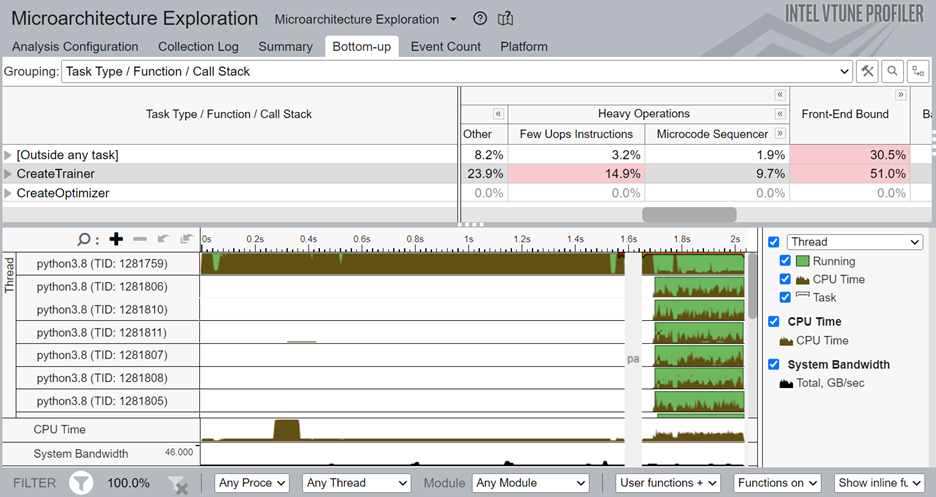
より小さなコードブロックに注目して解析するには、CreateTrainer タスクの 1 つを右クリックし、フィルタリングを有効にします。
PyTorch* ITT API の追加 (PyTorch* フレームワークのみ)
ITT-Python API と同様に、PyTorch* ITT API (英語) もインテル® VTune™ プロファイラーで使用できます。PyTorch* ITT API を使用すると、各 PyTorch* 演算子のタイムスパンにラベルを付けたり、カスタマイズしたコード領域の詳細な解析結果を取得できます。PyTorch* 1.13 では、インテル® VTune™ プロファイラー向けの torch.profiler.itt API を提供しています。
- is_available()
- mark(msg)
- range_push(msg)
- range_pop()
これらの API がどのように使われているか、Intel_Extension_For_PyTorch_Hello_World.py (https://github.com/ONEAPI-SRC/ONEAPI-SAMPLES/BLOB/MASTER/AI-AND-ANALYTICS/GETTING-STARTED-SAMPLES/INTEL_EXTENSION_FOR_PYTORCH_GETTINGSTARTED/INTEL_EXTENSION_FOR_PYTORCH_HELLO_WORLD.PY) のコードを見てみましょう。
itt.resume()
with torch.autograd.profiler.emit_itt():
torch.profiler.itt.range_push('training')
model.train()
for batch_index, (data, y_ans) in enumerate(trainLoader):
data = data.to(memory_format=torch.channels_last)
optim.zero_grad()
y = model(data)
loss = crite(y, y_ans)
loss.backward()
optim.step()
torch.profiler.itt.range_pop()
itt.pause()
上記のコードで行われている一連の操作を以下に示します。
- itt.resume() API を使用して、ループが実行を開始する直前にプロファイルを再開します。
- プロファイルするコード領域を指定するには、torch.autograd.profiler.emit_itt() API を使用します。
- range_push() API を使用して、入れ子の範囲スパンのスタックにレンジをプッシュします。メッセージ (‘training’) でマークします。
- 対象コード領域を挿入します。
- range_pop() API を使用して、入れ子の範囲スパンのスタックから範囲をポップします。
PyTorch* ITT API を使用したホットスポット解析の実行
PyTorch* ITT API を使って変更したコードのホットスポット解析を実行します。コマンドラインで、次のコマンドを入力します。
$vtune -collect hotspots -start-paused -knob enable-stack-collection=true -knob sampling-mode=sw -search-dir=/usr/bin/python3 -source-search-dir=path_to_src -result-dir vtune_data_torch_profiler_comb -- python3 Intel_Extension_For_PyTorch_Hello_World.py
以下は、対象コード領域の上位のホットスポットです。
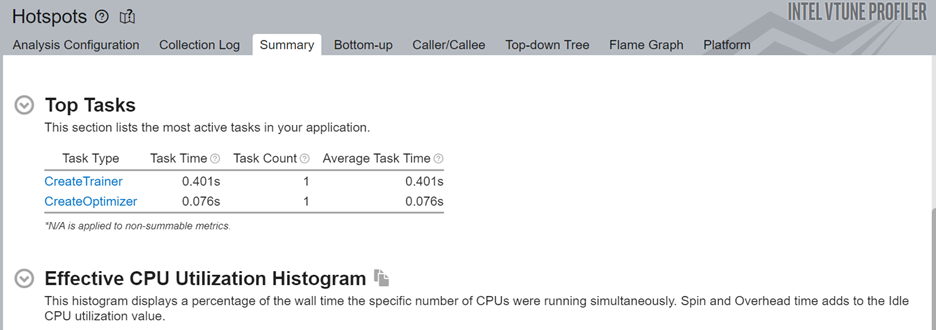
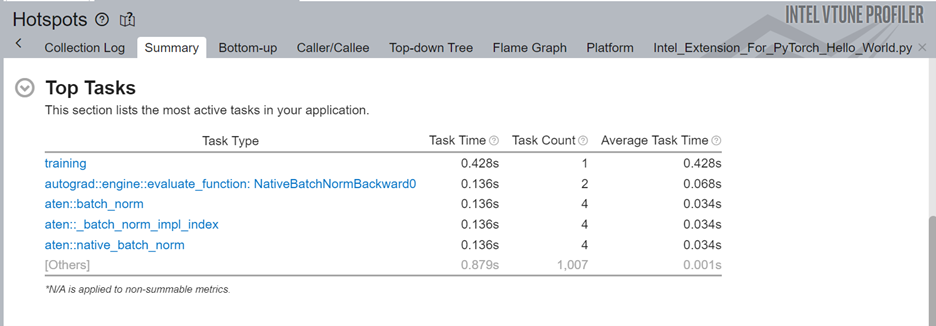
[Summary (サマリー)] の [Top Tasks (上位のタスク)] セクションに、ITT-API を使ってラベル付けされたトレーニング・タスクがあります。
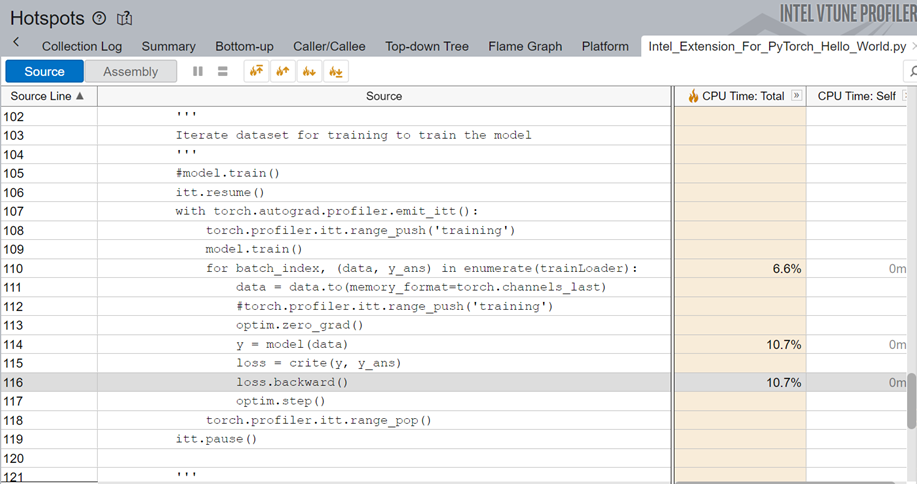
PyTorch* コードのソース行のプロファイルを調べると、コードはバックプロパゲーションに総実行時間の 10.7% を費やしていることが分かります。
[Platform (プラットフォーム)] ウィンドウに切り替えまて、PyTorch* の ITT API を使用してマークされた training タスクのタイムラインを表示します。
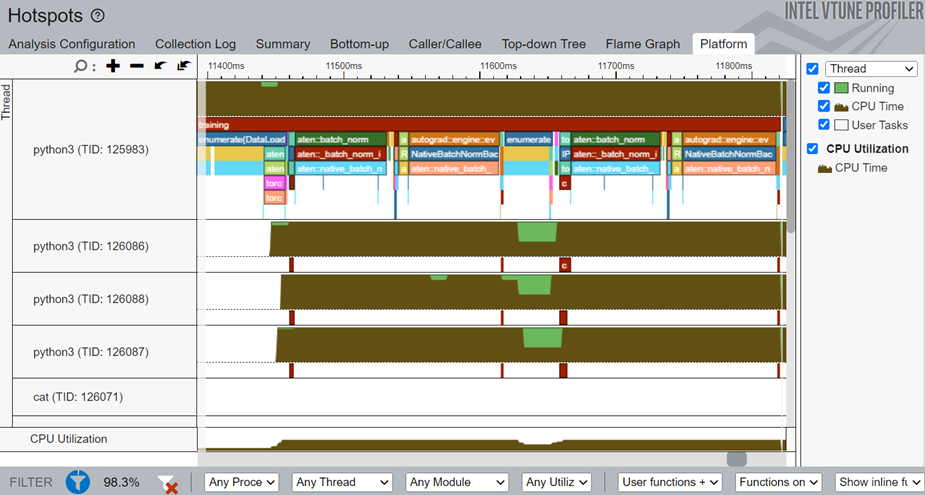
タイムラインから、メインスレッドは python3(TID:125983) で、いくつかの小さなスレッドを含んでいることが分かります。aten::batch_norm、aten::native_batch_norm、aten::batch_norm_i で始まる演算子名はモデル演算子です。
[Platform (プラットフォーム)] ウィンドウから、次の詳細が得られます。
- 各スレッドの特定の期間の CPU 利用率
- 開始時間
- ユーザータスクと oneDNN プリミティブ (畳み込み、リオーダー) の時間
- 各タスクとプリミティブのソース行 (タスク/プリミティブのソースファイルをデバッグ情報と一緒にコンパイルしたら、タスク/プリミティブをクリックしてソース行を表示します)
- 反復回数でグループ化されたプロファイル結果 (複数の反復回数が利用可能な場合)
