
この記事は、インテルのウェブサイトに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Profiling Large Language Models on Intel® Core™ Ultra 200V」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピでは、インテル® VTune™ プロファイラーを使用して大規模言語モデル (LLM) を解析し、AI アプリケーションのパフォーマンスを向上させる方法を示します。ここでは、インテル® ディストリビューションの OpenVINO™ ツールキットにデプロイされた LLM を使用します。
大規模言語モデル (LLM) は、生成 AI (GenAI) アプリケーションの基本的なビルディング・ブロックであり、ベース・コンポーネントです。しかし、LLM のパフォーマンス問題のプロファイルには、固有の課題があり、以下のような要素を検証する際に、重大な問題に遭遇することがあります。
- モデルのコンパイル時間
- 最初のトークン時間
- 平均トークン時間
- リソース利用率
さらに、次のようないくつかの重要な要素に注目する必要があります。
- モデルの最適化
- ハードウェア利用率
- LLM の効率良いデプロイ
このレシピでは、LLM を解析し、インテル® Core™ Ultra プロセッサー 200V シリーズを搭載した AI PC 上で動作する AI アプリケーションのパフォーマンスを改善する方法を示します。LLM はインテル® ディストリビューションの OpenVINO™ ツールキットにデプロイされています。
コンテンツ・エキスパート: Yu Zhang、Xiake Sun
使用するもの
以下は、このパフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: phi-3 (英語) LLM アプリケーション
- LLM: Phi-3-mini-4k-instruct (英語)
- 推論エンジン: インテル® ディストリビューションの OpenVINO™ ツールキット 2024.3 (zip ファイル)
- 解析ツール: インテル® VTune™ プロファイラー 2025.0 以降
- プラットフォーム: インテル® Core™ Ultra 5 プロセッサー 238V @2.10GHz
- オペレーティング・システム: Microsoft* Windows*
環境の設定
環境を設定するには、次の操作を行います。
- OpenVINO™ ソースのビルド
- LLM アプリケーションのビルドと実行
OpenVINO™ ソースのビルド
- リポジトリーから OpenVINO™ ソースを取得します。
$ git clone https://github.com/openvinotoolkit/openvino.git $ cd openvino $ git submodule update --init --recursive
- ソースをビルドします。インストルメンテーションおよびトレーシング・テクノロジー (ITT) を使用したプロファイルを有効にします。
$ mkdir build && cd build $ cmake -G "Visual Studio 17 2022" -DENABLE_PYTHON=OFF \ -DCMAKE_BUILD_TYPE=Release \ -DENABLE_PROFILING_ITT=ON -DCMAKE_INSTALL_PREFIX=ov_install .. $ cmake –build . --config Release --verbose –j8 $ cmake --install .
設定の詳しい手順は、「Windows* システム向け OpenVINO™ ランタイムのビルド」 (英語) を参照してください。
LLM アプリケーションのビルドと実行
- リポジトリーからアプリケーションのソースを取得します。
$ git clone https://github.com/sammysun0711/openvino.genai -b vtune_cookbook
- アプリケーションをビルドします。
# ov_install_path refers to the ov_install path above $ set OpenVINO_DIR= ov_install_path\runtime\cmake $ mkdir build && cd build $ cmake -DCMAKE_BUILD_TYPE=Release .. $ cmake --build . --config Release --verbose -j8
- OpenVINO™ モデルを準備します。
$ pip install optimum[openvino]==1.20.0 openvino==2024.3 --extra-index-url https://download.pytorch.org/whl/cpu $ optimum-cli export openvino --task text-generation-with-past --trust-remote-code --model microsoft/Phi-3-mini-4k-instruct --weight-format int4 --sym --group-size 128 --ratio 1 phi-3-mini-4k-instruct
変換された OpenVINO™ Phi-3 および Tokenizer/Detokenizer モデルは、phi-3-mini-4k-instruct ディレクトリーに保存されます。 - アプリケーションを実行します。
# The dependencies of the application are all located in ov_install_path $ set OPENVINO_LIB_PATHS= ov_install_path\bin\intel64\Release; ov_install_path\runtime\3rdparty\tbb\bin $ ov_install_path\setupvars.bat $ openvino.genai\build\llm\phi_cpp\Release\phi.exe -m openvino.genai\phi-3-mini-4k-instruct\openvino_model.xml -token openvino.genai\phi-3-mini-4k-instruct\openvino_tokenizer.xml -detoken openvino.genai\phi-3-mini-4k-instruct\openvino_detokenizer.xml -d GPU --output_fixed_len 256 --force_max_generation
GPU オフロード解析の実行
環境を設定したら、インテル® VTune™ プロファイラーで GPU オフロード解析を実行します。この解析タイプは、次の場合に役立ちます。
- CPU と GPU でのコード実行を調べる
- CPU と GPU のアクティビティーを関連付ける
- パフォーマンス・ボトルネックを特定する
準備
- インストール・ディレクトリーのセルフチェック・スクリプトを使用して、インテル® VTune™ プロファイラーが正しくインストールされていることを確認します。
- GPU ドライバーとランタイムが、GPU をプロファイルするように設定されていることを確認します。
- サンプリング・ドライバーがロードされていることを確認します。
GPU オフロード解析を実行するには、次の操作を行います。
- インテル® VTune™ プロファイラーの解析ツリーから [GPU Offload (GPU オフロード)] 解析タイプを開きます。
- [WHAT (何を)] ペインでは、[Launch Applicatio (アプリケーションを起動)] を選択します。
- LLM アプリケーションのパスを指定します。必要に応じて、パラメーターを指定してください。
- [Start (開始)] ボタンをクリックして、解析を実行します。
この解析をコマンドラインから実行するには、GUI で [Command Line (コマンドライン)] オプションを選択し、生成されたコマンドをコピーしてターミナルウィンドウにペーストし、実行します。
解析が完了すると、結果が [Summary (サマリー)] ウィンドウに表示されます。結果を確認して、[Graphics (グラフィックス)] ウィンドウに切り替えます。
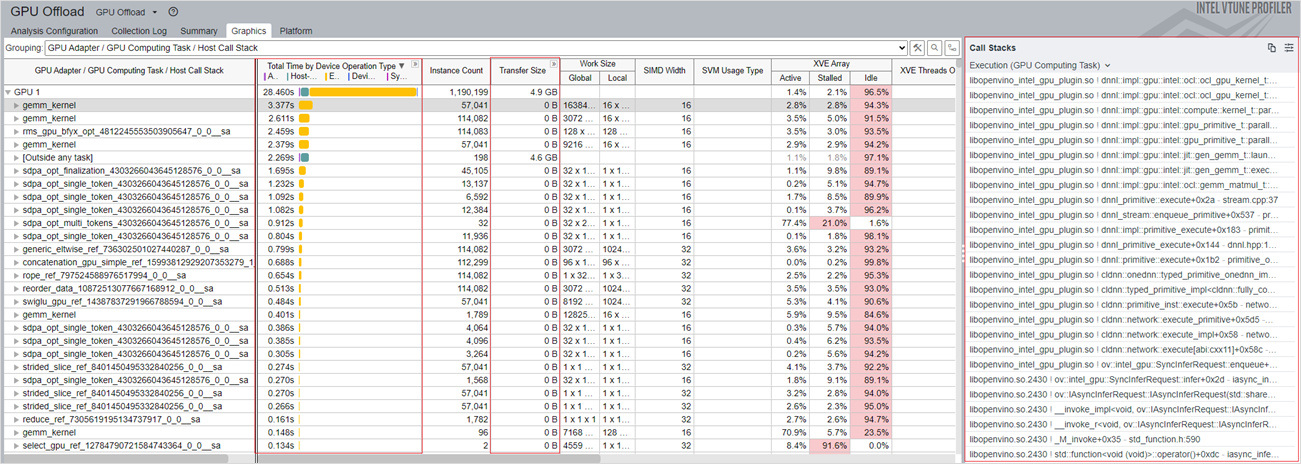
[Graphics (グラフィックス)] ウィンドウで以下を確認します。
- [Total Time by Device Operation Type (デバイス操作別合計時間)] カラムには、さまざまな操作タイプの計算タスクごとの合計時間が表示されます。この情報は、CPU または GPU で最も多くの時間を費やしたカーネルごとの操作 (割り当て、転送、実行、または同期) を特定するのに役立ちます。最もホットなカーネルの動作を詳しく理解するには、後述する GPU 計算/メディア・ホットスポット解析を実行します。
- [Transfer Size (転送サイズ)] カラムには、CPU ホストと GPU デバイス間のカーネルごとのデータ転送サイズが表示されます。
[Platform (プラットフォーム)] ウィンドウに切り替えます。

[Thread View (スレッドビュー)]で以下を確認します。
- Tokenizer/Detokenizer モデルは CPU 上に、Phi-3 モデルは GPU 上にデプロイされています。
- 上の図では、GPU Plugin Thread (GPU プラグインスレッド) (青色の枠で表示) に CPU と GPU で実行されるすべての操作が表示されています。
- Tokenizer モデルの入力として使用できるテキストの段落は 8 つあります。そのため、ITT を有効にすると、Tokenizer モデルの 8 つの推論タスクが phi スレッドに表示されます。
- 上の図では、Tokenizer モデルの推論タスクは Phi Thread (Phi スレッド) (赤色の枠で表示) に表示されています。
- そして、Tokenizer の文推論の後に Detokenizer の一連の推論結果が続きます。
- phi スレッドに対応して、phi-3 モデルの推論タスクが GPU プラグインスレッドで実行されます。
GPU リソースの利用状況を把握するには、計算キューとカーネルを、タイムライン上の GPU リソースに関する情報と関連付けます。
例えば、キューで待機しているカーネルとカーネル実行時間を確認します。同時に、対応する GPU メトリックを確認します。
- gemm_kernel とベクトルエンジンの相関
- GPU メモリーアクセス
- CPU 時間
- GPU 周波数
これらのメトリックは、以下の図の下部 (黄色の枠で表示) に表示されます。
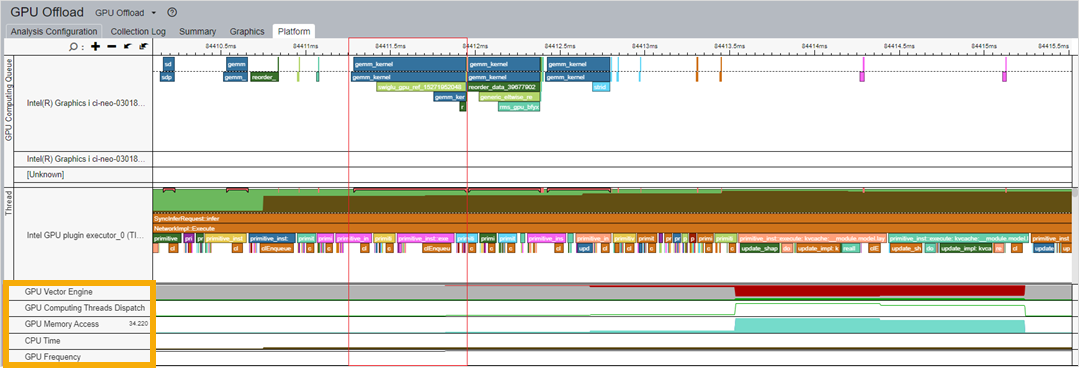
これらの情報から GPU リソースを最も多く消費するカーネルを特定したら、GPU 計算/メディア・ホットスポット解析を実行して、実行ストールや占有率の低下の原因を調べることができます。
GPU 計算/メディア・ホットスポット解析の実行
- インテル® VTune™ プロファイラーの解析ツリーから [GPU GPU Compute/Media Hotspots (GPU 計算/メディア・ホットスポット)] 解析タイプを開きます。
- [WHAT (何を)] ペインでは、[Launch Applicatio (アプリケーションを起動)] を選択します。
- LLM アプリケーションのパスを指定します。必要に応じて、パラメーターを指定してください。
- [Start (開始)] ボタンをクリックして、解析を実行します。
この解析をコマンドラインから実行するには、GUI で [Command Line (コマンドライン)] オプションを選択し、生成されたコマンドをコピーしてターミナルウィンドウにペーストし、実行します。
解析が完了すると、結果が [Summary (サマリー)] ウィンドウに表示されます。
[Summary (サマリー)] ウィンドウ
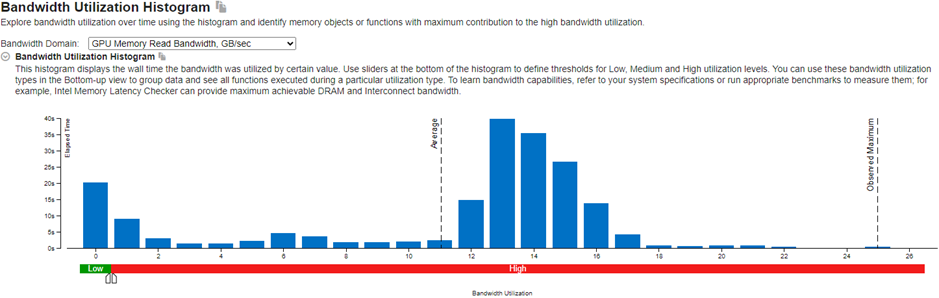
[Bandwidth Utilization Histogram (帯域幅利用率のヒストグラム)] から確認します。このヒストグラムは、メモリーレベル (この例では GPU メモリーと SLM) の特定の帯域幅を時間に対してプロットします。
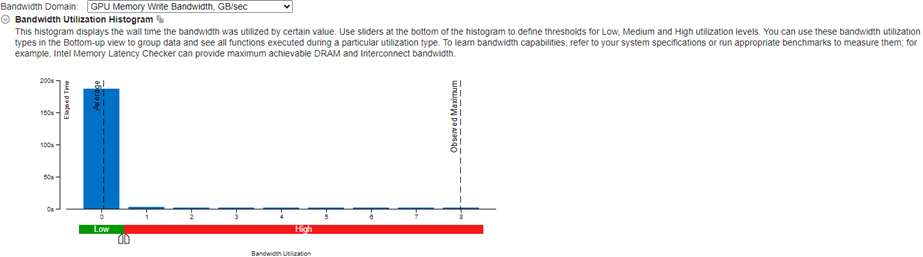
GPU Memory Read Bandwidth (GPU メモリー読み取り帯域幅) メトリックと GPU Memory Write Bandwidth (GPU メモリー書き込み帯域幅) メトリックから、経時的な GPU メモリーの使用状況を確認します。利用率が高い場合は、共有ローカルメモリーの使用とキャッシュの再利用を検討してください。これらのオプションは、GPU メモリーアクセスの軽減に役立ちます。
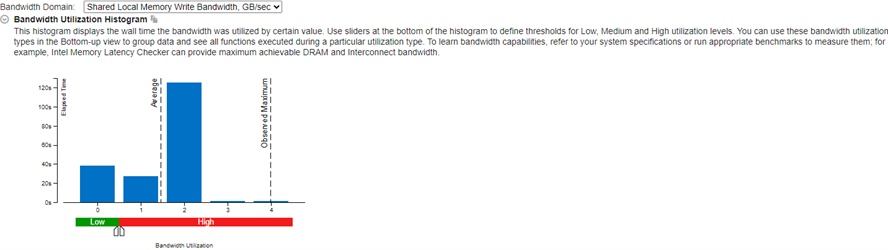
Shared Local Memory Read Bandwidth (共有ローカルメモリー読み取り帯域幅) メトリックと Shared Local Memory Write Bandwidth (共有ローカルメモリー書き込み帯域幅) メトリックから、経時的な共有ローカルメモリー (SLM) の利用状況を確認します。SLM を多く使用すると、パフォーマンスの向上が期待できます。

次に、[Graphics (グラフィックス)] ウィンドウの情報を確認します。
[Graphics (グラフィックス)] ウィンドウ
関連する情報が 2 つのタブに表示されます。
- Memory Hierarchy Diagram (メモリー階層ダイアグラム)
- Platform (プラットフォーム)
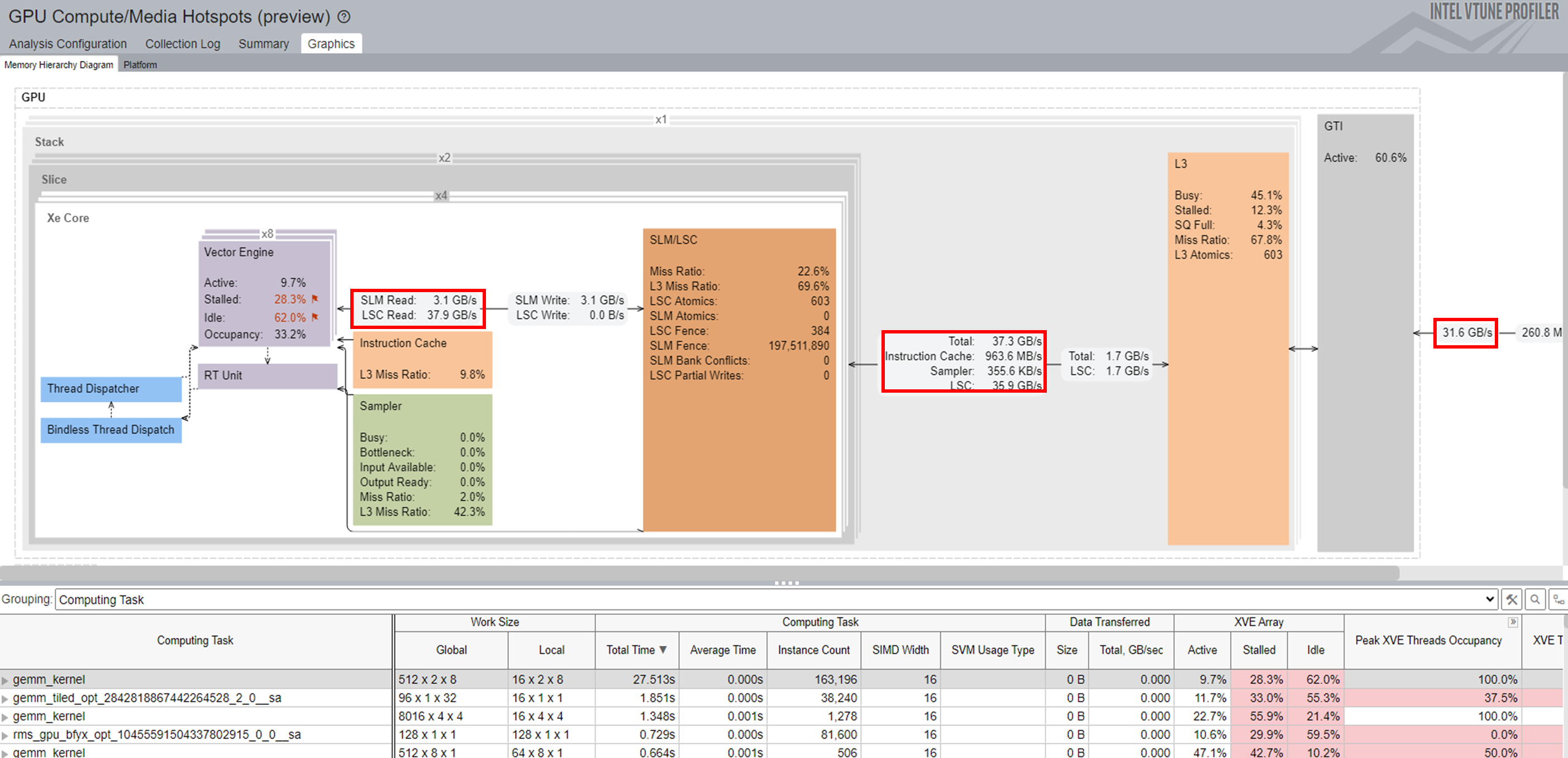
[Memory Hierarchy Diagram (メモリー階層ダイアグラム)]:
図の下のテーブルで選択したカーネルにマップされた GPU ハードウェア・メトリックが表示されます。メモリー階層ダイアグラムは、テーブルで現在選択されているメトリックを反映するように動的に更新されます。
インテル® VTune™ プロファイラーは、GPU カーネルの実行をトレースし、各カーネルに GPU メトリックの注釈を付けます。この情報は、図の下のテーブルに表示されます。カーネルを選択すると、階層ごとのメモリーアクセスが表示されます。この情報は、メモリー関連のパフォーマンス問題を解析する際に役立ちます。キャッシュの再利用と SLM の使用により、メモリーアクセスのレイテンシーを短縮できます。
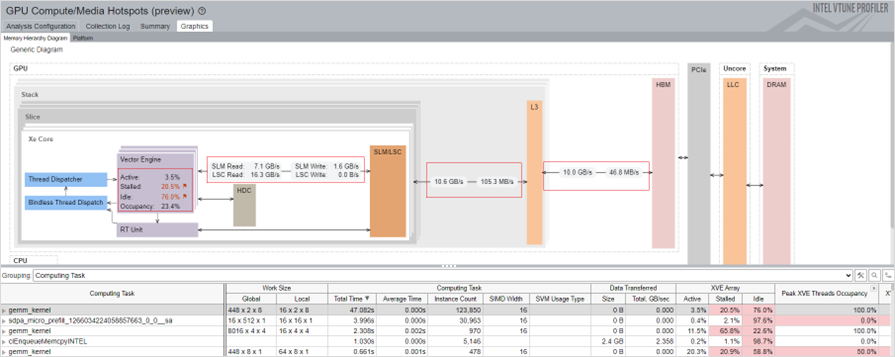
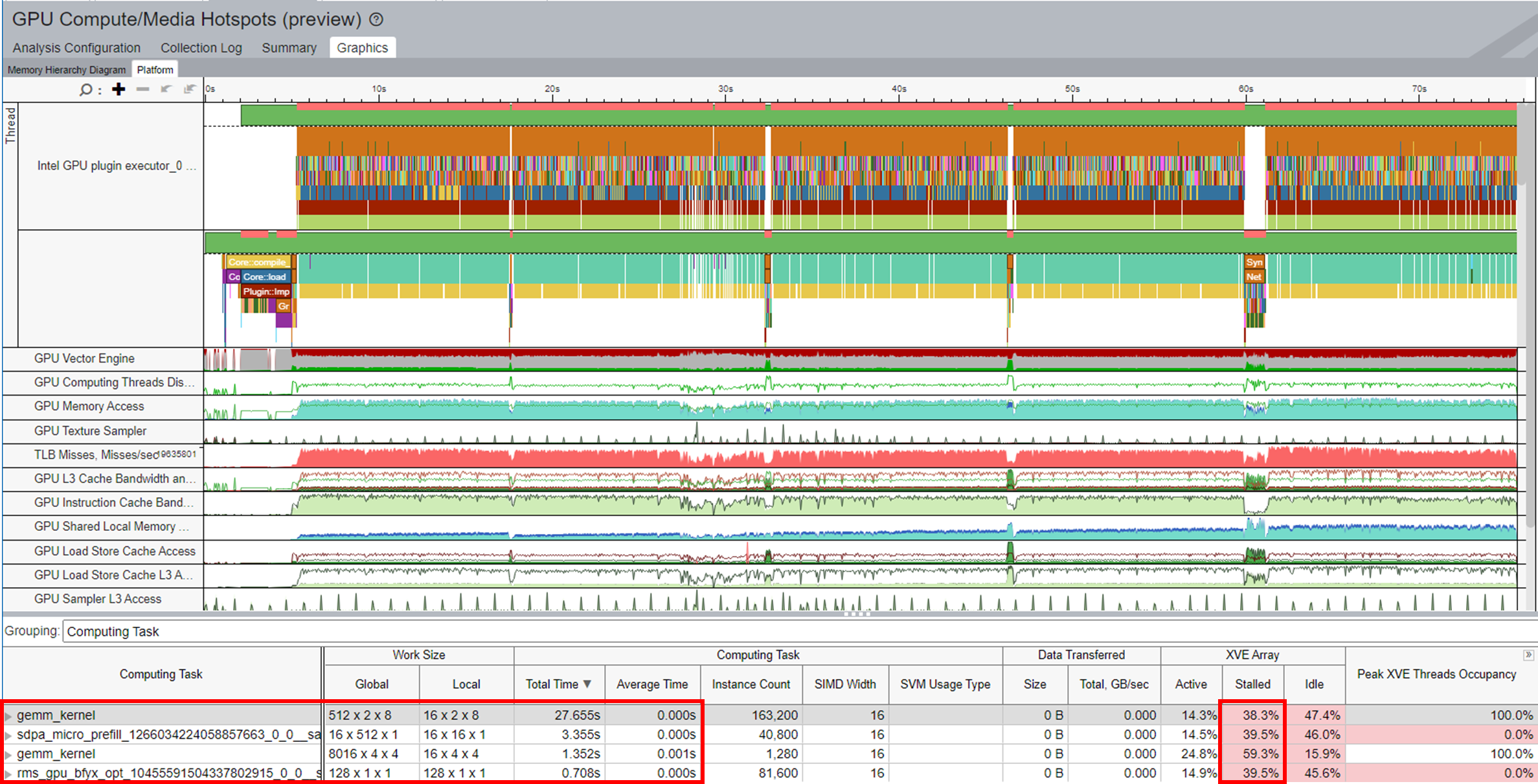
計算関連の問題をプロファイルするには、結果を Computing Task (計算タスク) でグループ化します。
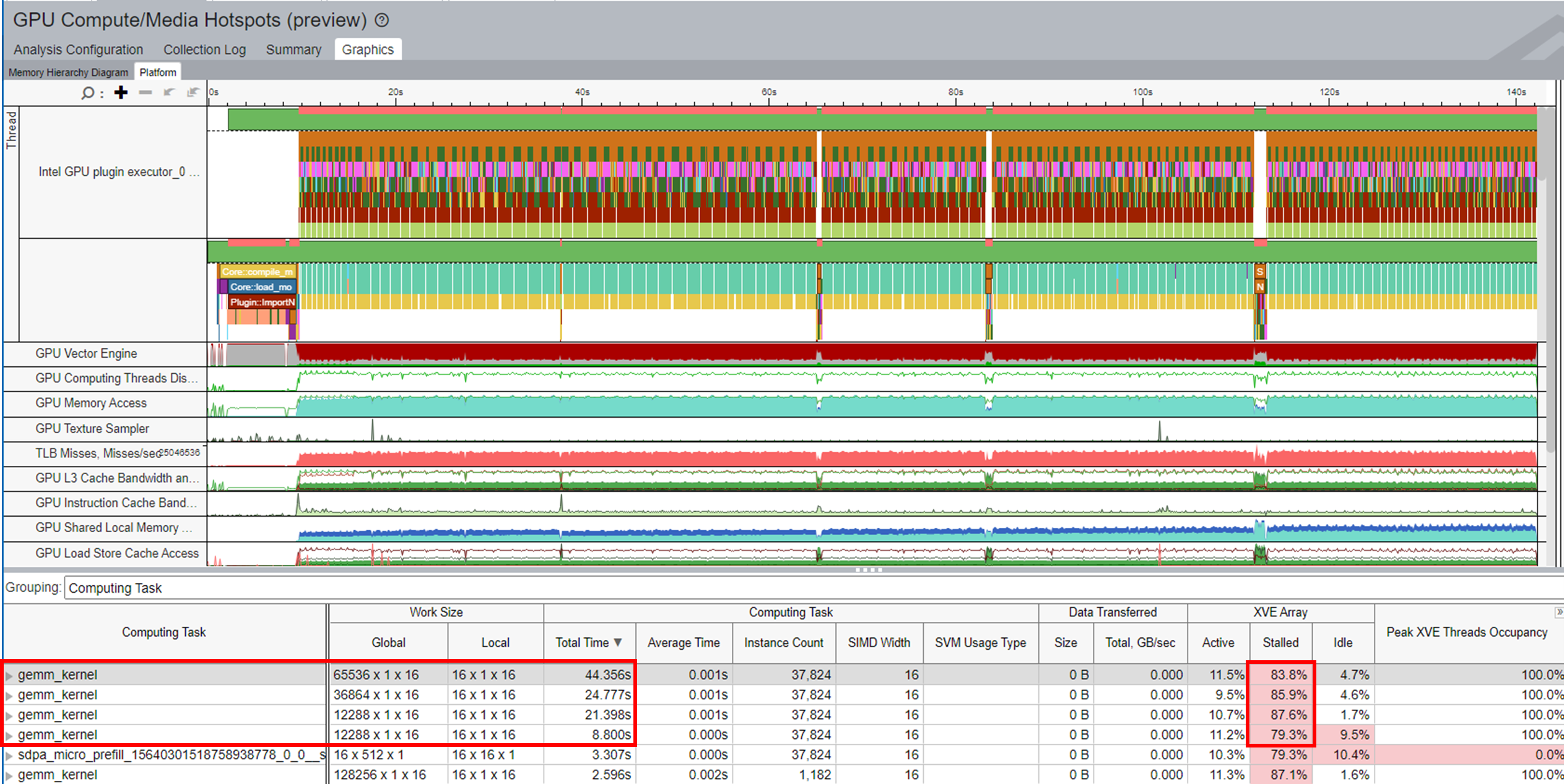
[Platform (プラットフォーム)]:
メトリックの経時的な傾向が表示されます。
- GPU ベクトルエンジン
- GPU 計算スレッド・ディスパッチ
- GPU メモリーアクセス
- GPU L3 キャッシュ帯域幅とミス
- GPU 共有ローカル・メモリー・アクセス
- GPU ロード/ストア・キャッシュ・アクセス
- GPU 周波数
これらのメトリックの情報を使用して、異常と最適化の可能性を特定します。ズームインして、関心のある領域を表示できます。例えば、最初のトークン推論 (下の図で First token と示した部分) は、関連する GPU ハードウェア・リソースに対応します。
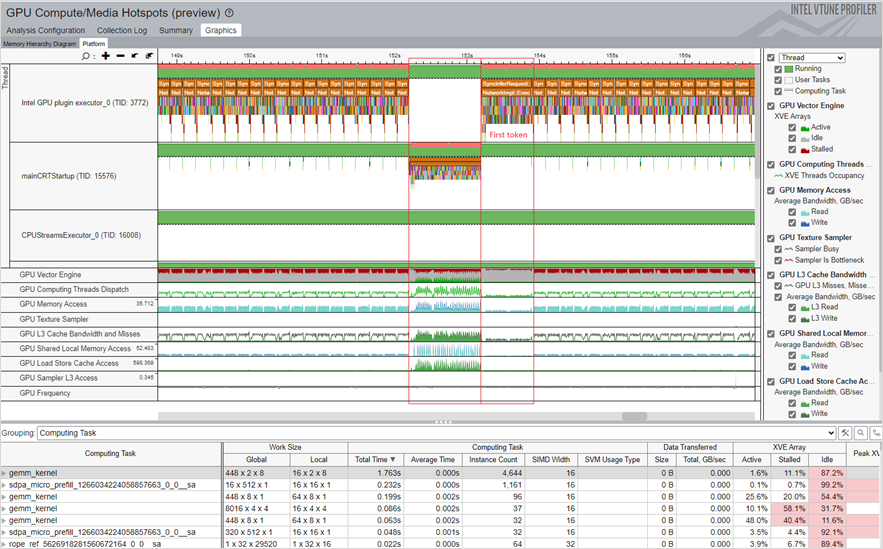
このテーブルの各カラムは、選択したカーネルに関連付けられた GPU メトリックを表します。すべてのカーネルは、タスクに費やされた合計時間でソートされます。
メトリックから、パフォーマンスに関する以下の考察を推測できます。
- GPU Vector Engine (GPU ベクトルエンジン) メトリックと Computing Thread Dispatch (計算スレッド・ディスパッチ) メトリックは、GPU がビジーであるかを示します。
- GPU Memory Access (GPU メモリーアクセス) メトリックは、メモリー帯域幅の制限に関連する問題とレイテンシーの問題を特定するのに役立ちます。モデルの最適化と量子化により、マルチレベル・メモリー・アクセスの帯域幅制限を軽減できます。
- L3 Cache Bandwidth and Misses (L3 キャッシュ帯域幅とミス) メトリックは、L3 キャッシュの再利用状況を明らかにします。
- Shared Local Memory Access (共有ローカル・メモリー・アクセス) メトリックは、データアクセスの帯域幅が高く、レイテンシーが非常に低いことを示しています。SLM を使用すると、メモリーアクセスのレイテンシーを軽減できます。
- プロファイル期間中の GPU Frequency (GPU 周波数) メトリックの変動は、アプリケーションのパフォーマンスに影響を与える可能性があります。
結果を計算タスクでグループ化すると、テーブルの各カラムは、選択したカーネルに関連付けられた GPU メトリックを表します。すべてのカーネルは、タスクに費やされた合計時間でソートされます。
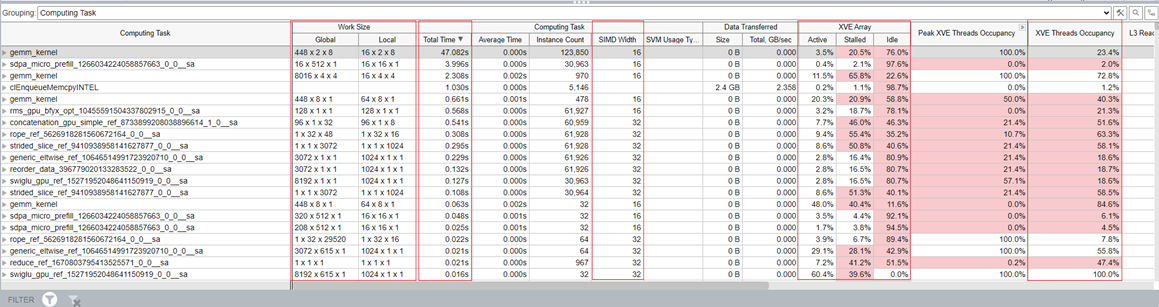
XVE Array (XVE アレイ) カラムの Idle (アイドル) セクションは、スレッドのないサイクルが XVE でスケジュールされたことを示しています。この値が高い場合、GPU が比較的空いていた (アイドル状態であった) ことを示します。つまり、ホストには GPU にオフロードする十分なタスクがなかったということです。Stalled (ストール) セクションは、メモリーアクセスのレイテンシーまたはメモリー帯域幅の制限により、GPU 時間が失われたことを示します。Memory Hierarchy Diagram (メモリー階層ダイアグラム) では、メモリーアクセス情報をより詳しく知ることができます。
XVE Threads Occupancy (XVE スレッド占有率) は Work Size (ワークサイズ) と SIMD Size (SIMD サイズ) によって決まります。占有率を増やして GPU 利用率を向上したい場合は、ワークサイズと SIMD 幅 (英語) をファイン・チューニングする方法を学ぶことができます。
AI プロファイル・シナリオの検証
AI アプリケーションのプロファイルに関する次のシナリオでは、OpenVINO™ ワークロードを使用します。これらのワークロードでは、インテル® VTune™ プロファイラーはインストルメンテーションおよびトレース・テクノロジー (ITT) API を使用して、タスクに費やされた時間を分析します。結果はタイムラインに表示されます。タイムラインに表示される時間は ITT オーバーヘッドを含むため、タスクで実際に消費された時間よりも多くなりますが、この情報はパフォーマンス解析に関連しており参考になります。
ここでは 4 つのシナリオについて説明します。
- ケース 1: モデルのコンパイルの最適化
- ケース 2: SDPA (Scaled Dot-Product Attention ) サブグラフの最適化によるパフォーマンスの最適化
- ケース 3: Logits の最後の MatMul 計算とメモリー使用量の軽減
- ケース 4: LLM の KV キャッシュのステートフル・モデルの最適化
ケース 1: モデルのコンパイルの最適化
一般的なワークフローでは、推論ごとにモデルがコンパイルされます。例えば、下の図のホットスポット・ビューのタイムラインでは、Core::compile_model::Path のタスクは完了するまでに 7 秒かかります。このタスクでは、Plugin::compile_model は約 6 秒かかります。
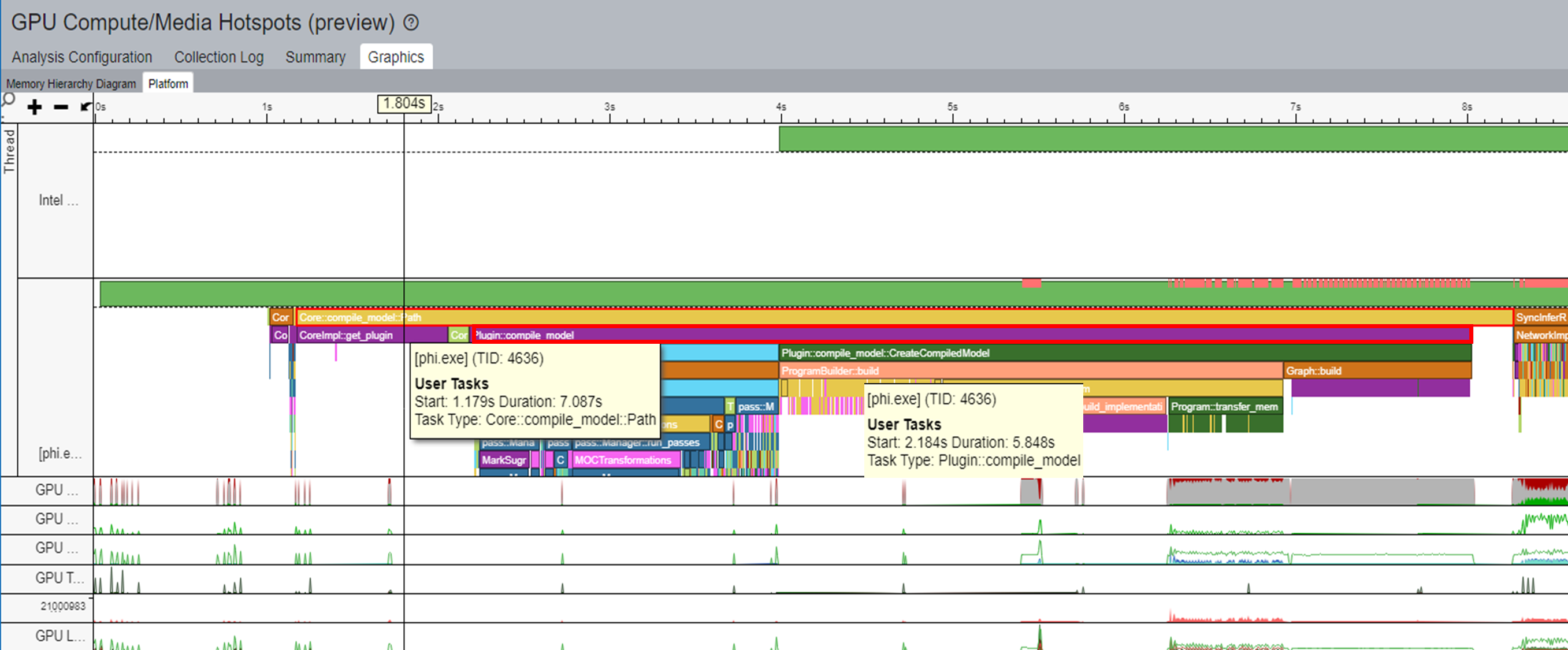
OpenVINO™ には、モデルのコンパイルの高速化に使用できるモデルキャッシュ機能が含まれています。
ov::Core core;
core.set_property(ov::cache_dir("/path/to/cache/dir"));
auto compiled = core.compile_model(modelPath, device, config);
モデル キャッシュの詳細については、「OpenVINO™ モデルキャッシュの概要」を参照してください。
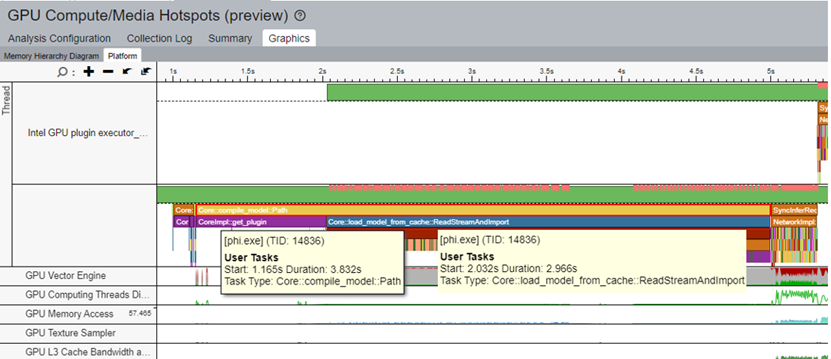
最初の実行時にモデルをキャッシュし、推論ごとにキャッシュからモデルをロードすることで、モデルのコンパイル時間を短縮できます。この手法をサンプル・ワークロードに適用すると、Core::compile_model::Path のタスク時間が 4 秒に短縮されました。その結果、Core::load_model_from_cache のタスク時間は 3 秒になりました。この最適化により、モデルのコンパイル・パフォーマンスが 40% 向上しました。
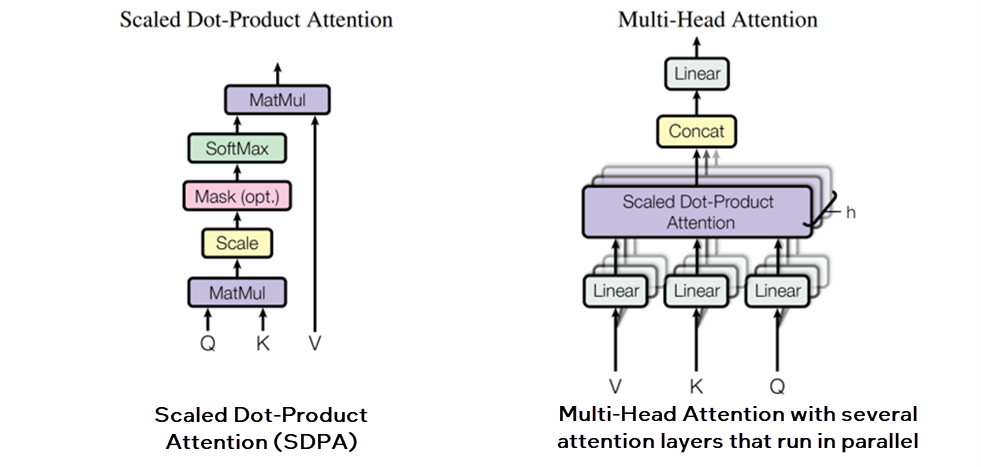
ケース 2: SDPA (Scaled Dot-Product Attention ) サブグラフの最適化によるパフォーマンスの最適化
Transformer ネットワーク・アーキテクチャー (英語) では、SDPA アテンション・メカニズムが導入されています。
SDPA アーキテクチャー (出典: https://arxiv.org/pdf/1706.03762)
SDPA サブグラフ融合が無効な場合のメモリー使用量:
OpenVINO™ は、SDPA サブグラフ融合用の ScaledDotProductAttention 演算子を提供します。この演算子を使用すると、メモリー依存の問題を軽減し、MHA (Multi-Head Attention) の並列処理とメモリー・アクセス・パターンを改善できます。これらの手順を実行すると、メモリー・フットプリントを軽減し、アプリケーションのパフォーマンスを向上できます。インテル® VTune™ プロファイラーを使用して、特に最もホットな計算タスクの推論中のメモリー使用量を観察します。
SDPA サブグラフ融合が有効な場合のメモリー使用量:
最もホットな計算タスク gemm_kernel では、推論全体を通じてさまざまなメモリーレベル (SLM、L3、および GTI) 間のメモリー・フットプリントを観察できます。SDPA サブグラフ融合を有効にすると、帯域幅が大幅に向上します。

SDPA サブグラフ融合が無効な場合の推論時間

SDPA サブグラフ融合が有効な場合の推論時間

SDPA サブグラフ融合を有効にすることで、合計推論時間が 85 秒から 73 秒に短縮され、15% の改善がもたらされました。
ケース 3: Logits の最後の MatMul 計算とメモリー使用量の軽減
LLM のコンテキストでは、語彙サイズとは、モデルが認識して使用できる一意の単語またはトークンの合計数を指します。語彙サイズが大きいほど、モデルはよりニュアンスを捉え、詳細な言語理解が可能になります。例えば、Phi-3 モデルの語彙サイズは 32064 で、隠れサイズは 3072 です。
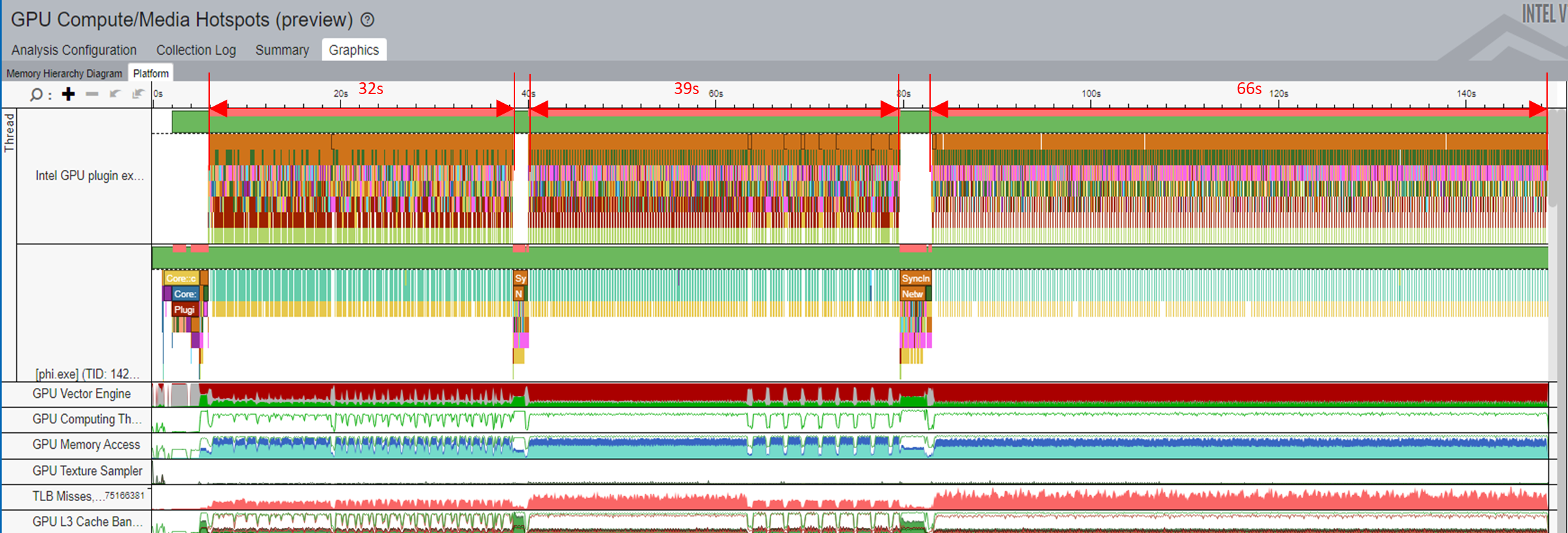
ただし、語彙サイズが大きいと、展開に必要な計算リソースとメモリーリソースも増えます。下の図は、より多くの MatMul 計算とメモリーが必要であることを示しています。その結果、この例のワークロードの計算は、ストール問題により推論時間全体で 143 秒かかりました。
Logits の MatMul 計算の軽減が無効な場合
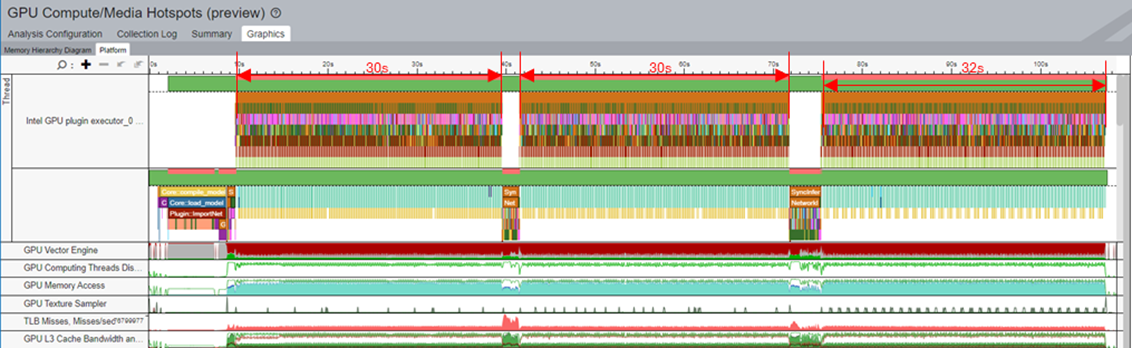
LLM 貪欲検索生成の場合、推論ごとに LLM によって生成されるトークンは 1 つだけです。追加のグラフ最適化手法を適用して、Logits の最後の MatMul の入力形状を縮小することができます。Multiply ノードと MatMul ノードの間にスライス操作を挿入すると、reshape ノード出力の 2 番目の次元の最後の要素のみが抽出されます。Phi-3 モデルの場合、MatMul 演算子の最初の入力は [1, seq_len, 3072] から [1,1, 3072] に縮小されます。この縮小により、MatMul の計算とメモリー使用量が大幅に軽減されます。
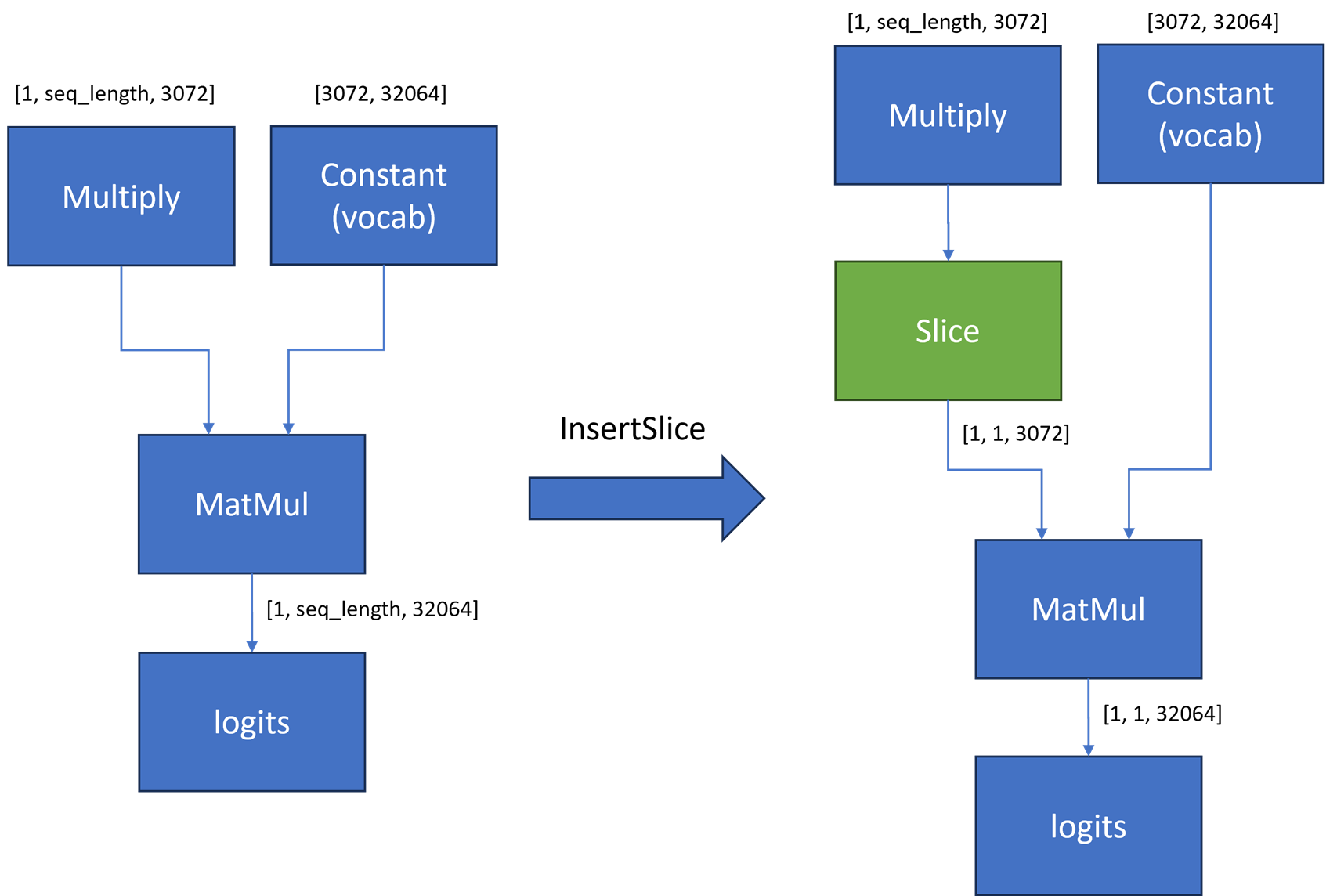
下の図から、次の詳細を推測できます。
Logits の MatMul 計算の削減が有効な場合
- グラフ最適化を有効にすると、gemm_kernel 呼び出しが大幅に削減されます。
- ストール問題が軽減されます。
- 推論時間はわずか 76 秒です。
- パフォーマンスが最大 1 倍向上しました。
ケース 4: LLM の KV キャッシュのステートフル・モデルの最適化
テキスト生成プロセスにおいて、LLM は各入力トークンのキーと値 (KV) ペアを自己回帰的に計算します。この方法では、生成された出力が入力の一部となるため、毎回同じ KV 値を再計算する場合は効率的ではありません。
これを最適化するため、過去のキーと値を毎回計算する代わりに保存する KV キャッシュ最適化が提案されました。この手法により、計算を軽減しながら、ホストとデバイス間の追加の KV キャッシュメモリー転送を実現できます。
OpenVINO™ は、連続する 2 つの推論呼び出し間でモデルの内部状態として KV キャッシュを暗黙的に保持するステートフル API を提供します。この KV キャッシュは、モデルへの入力とモデルの出力に代わって使用され、不要なメモリーコピーのオーバーヘッドを回避します。このキャッシュは、長い入力トークンで大幅に拡張できます。この最適化の詳細については、「OpenVINO™ ステートフル・モデルとステート API」を参照してください。
下の図のステートレス・モデルでは、5 つの文すべての推論時間は文の長さとともに徐々に増加します。
ステートレス・モデル – モデルの入出力を KV キャッシュに保持する場合
ただし、下の図に示すステートフル・モデルでは推論時間の変化はすべてわずかです。
ステートフル・モデル – ステートフル API を使用してモデルの内部状態を KV キャッシュに保持する場合
このレシピについて、Analyzers フォーラム (英語) で意見交換することができます。
