
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Profiling a SYCL* Application running on a GPU」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2025.0
更新日: 2024年10月31日
インテル® VTune™ プロファイラーを使用して、GPU にオフロードされた SYCL* アプリケーションを解析する方法を紹介します。
コンテンツ・エキスパート: Cory Levels
- 使用するもの
- 手順:
使用するもの
以下は、このパフォーマンス解析の最小ハードウェアおよびソフトウェア要件です。
- アプリケーション: matrix_multiply_vtune (英語)。このサンプル・アプリケーションは、インテル® oneAPI ツールキットのサンプルコード・パッケージ (英語) に含まれています。
- コンパイラー: SYCL* アプリケーションをコンパイルするには、インテル® oneAPI ツールキットに含まれるインテル® oneAPI DPC++/C++ コンパイラーが必要です。
- ツール: インテル® VTune™ プロファイラー – GPU オフロード解析および GPU 計算/メディア・ホットスポット解析
- マイクロアーキテクチャー:
- 第 9 世代インテル® プロセッサー・グラフィックス
- インテル® マイクロアーキテクチャー開発コード名 Kaby Lake、Coffee Lake、または Ice Lake
- オペレーティング・システム:
- Linux* カーネルバージョン 4.14 以降
- Windows* 10
- Linux* 向けグラフィカル・ユーザー・インターフェイス:
- GTK+ (2.10 以降、2.18 以降を推奨)
- Pango* (1.14 以降)
- X.Org* (1.0 以降、1.7 以降を推奨)
SYCL* アプリケーションを作成してコンパイルする
Linux*:
サンプル・ディレクトリーに移動します。
cd <sample_dir>/VtuneProfiler/matrix_multiply_vtune
src ディレクトリーの multiply.cpp ファイルには、行列乗算のいくつかのバージョンが含まれています。multiply.hpp の対応する #define MULTIPLY 行を編集してバージョンを選択します。
サンプル・アプリケーションをコンパイルします。
cmake . make
matrix.dpcpp -fsycl 実行ファイルが生成されます。
プログラムを削除するには、次のコマンドを実行します。
make clean
make コマンドによって作成された実行ファイルとオブジェクト・ファイルが削除されます。
Windows*:
サンプル・ディレクトリーに移動します。
<sample_dir>\VtuneProfiler\matrix_multiply_vtune
matrix_multiply.sln という名前の Visual Studio* プロジェクト・ファイルを開きます。
multiply.cpp ファイルには、行列乗算のいくつかのバージョンが含まれています。multiply.hpp の対応する #define MULTIPLY 行を編集してバージョンを選択します。
Release 構成でプロジェクト全体をビルドします。
matrix_multiply.exe 実行ファイルが生成されます。
SYCL* アプリケーションの GPU オフロード解析を実行する
必要条件: GPU 解析を実行するシステムを準備します。「GPU 解析向けにシステムを設定」を参照してください。
インテル® VTune™ プロファイラーを起動して、[Welcome (ようそこ)] ページで [New Project (新規プロジェクト)] をクリックします。
[Create a Project (プロジェクトの作成)] ダイアログボックスが表示されます。
プロジェクトの名前と場所を指定したら、[Create Project (プロジェクトの作成)] をクリックします。
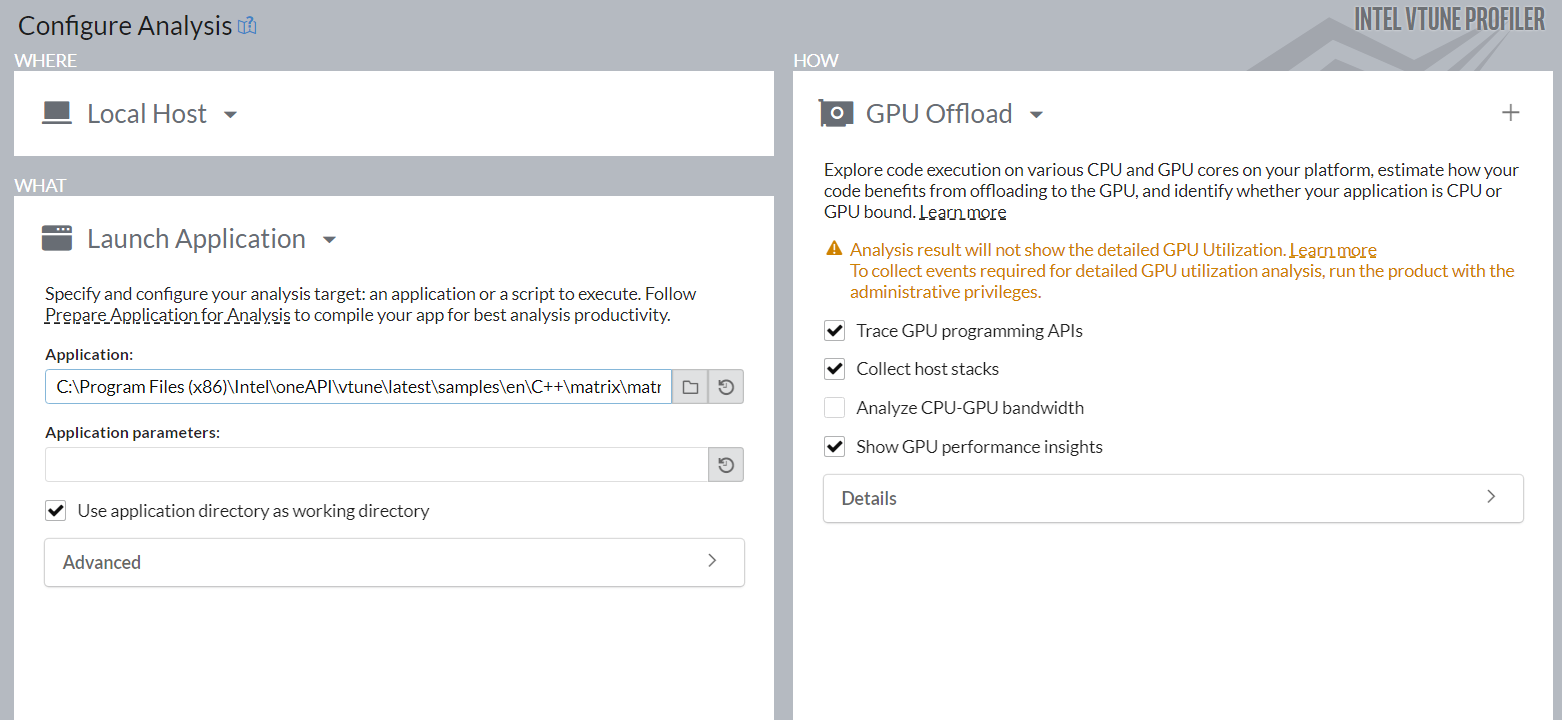
[Configure Analysis (解析の設定)] ダイアログボックスが開きます。
[WHERE (どこを)] ペインで [Local Host (ローカルホスト)] が選択されていることを確認します。
[WHAT (何を)] ペインでは、[Launch Application (アプリケーションを起動)] が選択されていることを確認して、[Application (アプリケーション)] に matrix_multiply バイナリーを指定します。
[HOW (どのように)] ペインで [Accelerators (アクセラレーター)] グループから [GPU Offload (GPU オフロード)] 解析タイプを選択します。
これは、インテル® VTune™ プロファイラーでサポートされるインテル® グラフィックスおよびサードパーティー製 GPU 搭載プラットフォームで実行するアプリケーションに対して、最も干渉が少ない解析タイプです。
[Start (開始)] ボタンをクリックして、解析を実行します。
コマンドラインから解析を実行する
コマンドラインから解析を実行するには、次のコマンドを使用します。
Linux*:
スクリプトをエクスポートしてインテル® VTune™ プロファイラーの環境変数を設定します。
export <install_dir>/env/vars.sh
解析を実行します。
vtune -collect gpu-offload - ./matrix.dpcpp -fsycl
Windows*:
バッチファイルを実行してインテル® VTune™ プロファイラーの環境変数を設定します。
export <install_dir>\env\vars.bat
解析を実行します。
vtune.exe -collect gpu-offload -- matrix_multiply.exe
収集データを解析する
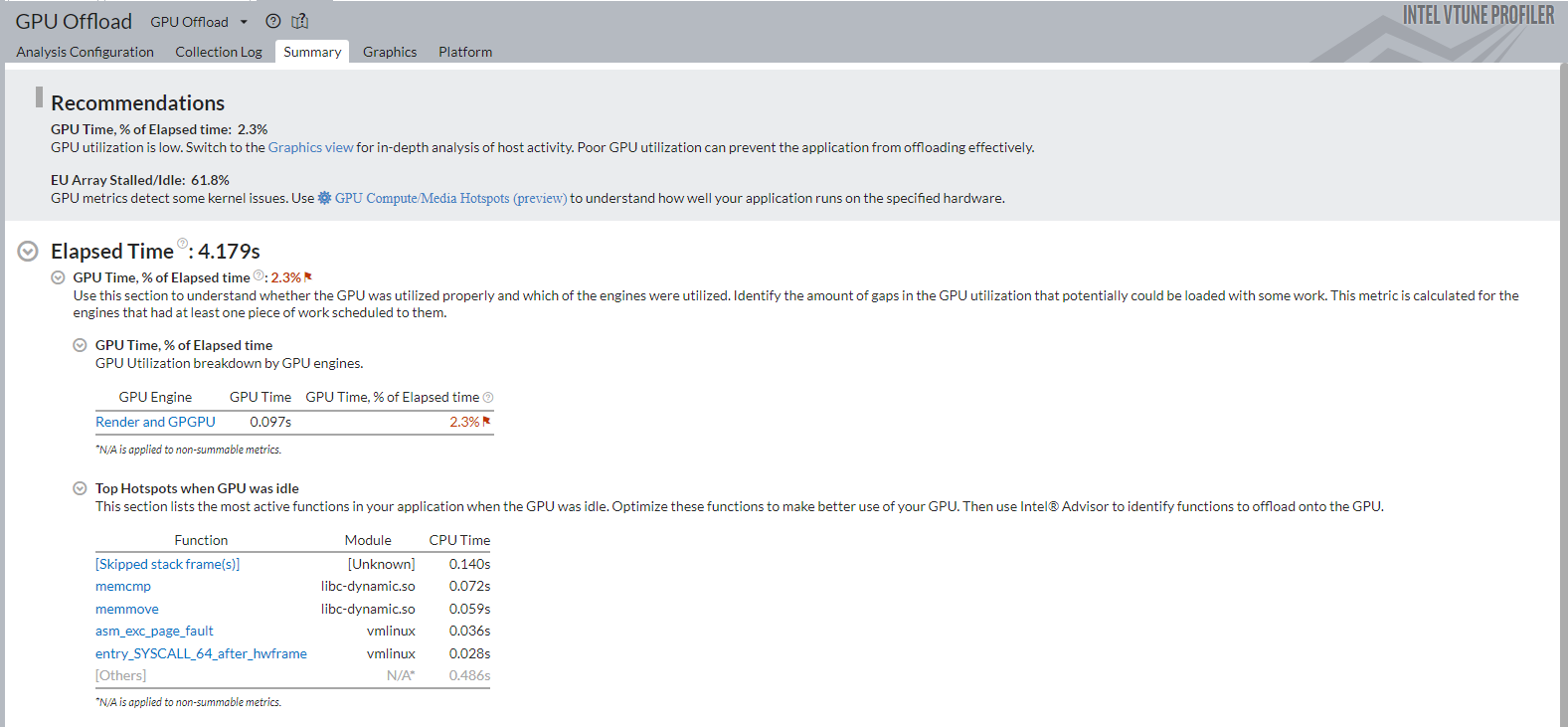
[GPU Offload (GPU オフロード)] ビューポイントから調査を開始します。[Summary (サマリー)] ウィンドウで CPU と GPU リソースの利用に関する統計を確認して、アプリケーションが GPU 依存か、CPU 依存か、あるいはシステムの計算能力を効率良く利用できているかどうかを判断します。この例では、アプリケーションは計算集約型の処理に GPU を使用すべきです。しかし、解析結果から、実際の GPU 利用率が低いことが分かります。
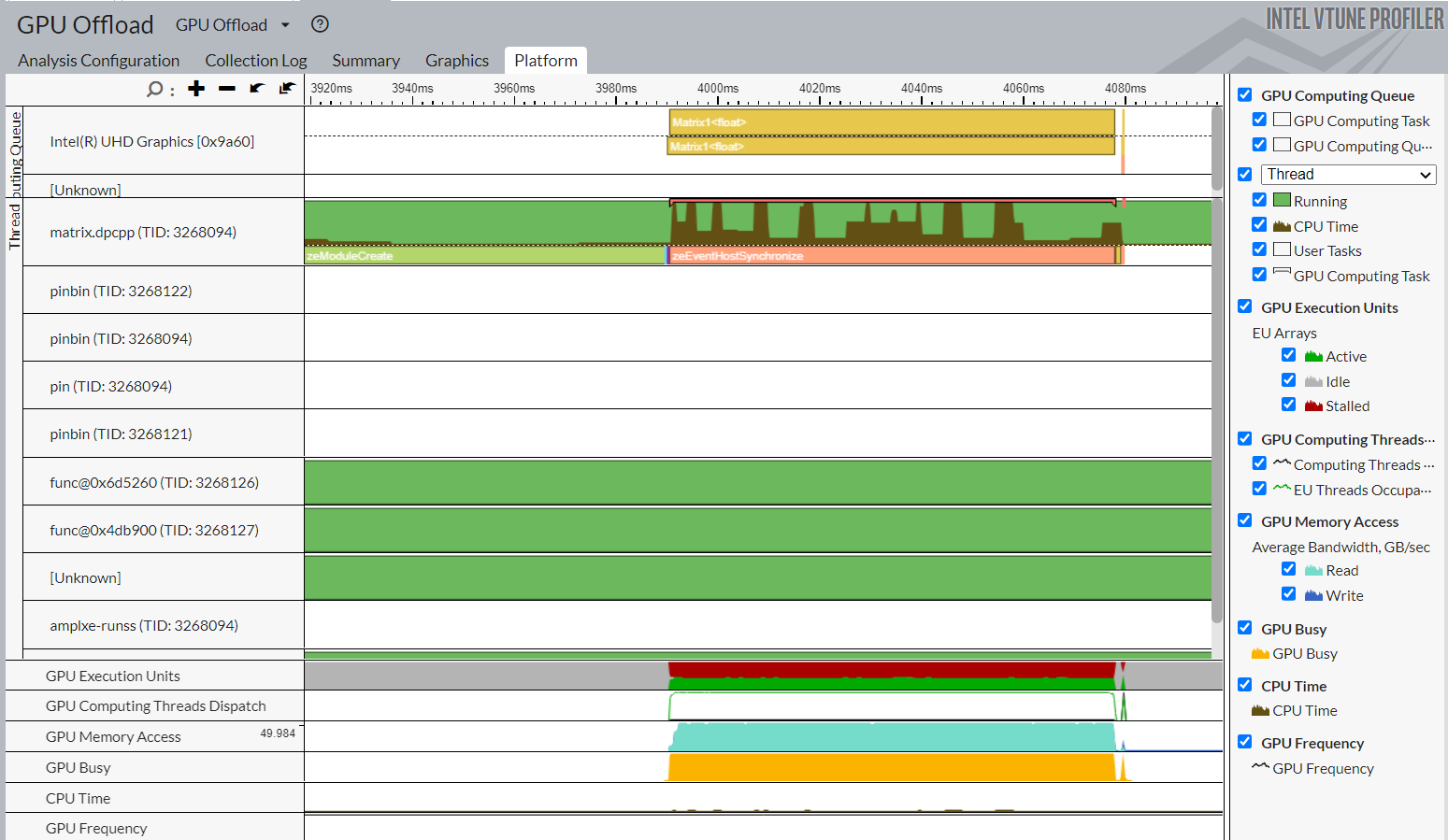
[Platform (プラットフォーム)] ウィンドウに切り替えます。ここでは、ソフトウェア・キューの GPU 利用率の解析に役立つ基本的な CPU および GPU メトリックを確認できます。このデータは、タイムラインで CPU 利用率に関連付けられます。[Platform (プラットフォーム)] ウィンドウの情報は、いくつかの推論に役立ちます。
GPU 依存アプリケーション |
CPU 依存アプリケーション |
|---|---|
プロファイル時間の大部分で GPU がビジー |
プロファイル時間の大部分で CPU がビジー |
ビジーである間に小さなアイドル時間がある |
ビジーである間に大きなアイドル時間がある |
GPU ソフトウェア・キューがほとんどゼロにならない |
注:
インテル® Arc™ GPU (開発コード名 DG2) 以降のインテル® Xe グラフィックス製品では、従来の製品で使用されていた GPU 用語が変更されています。用語の変更についての詳細と新旧の対照表については、「インテル® Xe グラフィックスの GPU アーキテクチャー用語」を参照してください。
注:
ほとんどのアプリケーションでは、上記に示すような明らかな状況は観測できないでしょう。すべての依存関係を理解するには、詳細な解析が重要です。例えば、ビデオ処理とレンダリングを行う GPU エンジンが交互にロードされる場合、これらのエンジンはシリアルに使用されます。アプリケーション・コードを CPU で実行する場合、GPU のスケジュールが非効率になります。これにより、誤ってアプリケーションが GPU 依存であると解釈される可能性があります。
計算タスク・リファレンスと [GPU Utilization (GPU 利用率)] メトリックに基づいて GPU 実行フェーズを特定します。そして、タスクの作成とキューへの配置のオーバーヘッドを定義します。
計算タスクを調査するには、[Graphics (グラフィックス)] ウィンドウに切り替えて、スレッドごとに GPU 上で実行しているワークの種類 (レンダリングまたは計算) を調べます。[Computing Task (計算タスク)] グループを選択して、テーブルでタスクのパフォーマンス特性を調べます。
計算タスクを詳しく解析するため、GPU 計算/メディア・ホットスポット解析を実行します。

multiply.cpp コードのほかの実装をプロファイルするには、サンプルの README ファイルに従ってください。
GPU 計算/メディア・ホットスポット解析を実行する
必要条件: まだ行っていない場合は、GPU 解析を実行するためシステムを準備します。「GPU 解析向けにシステムを設定」を参照してください。
解析を実行するには、次の操作を行います。
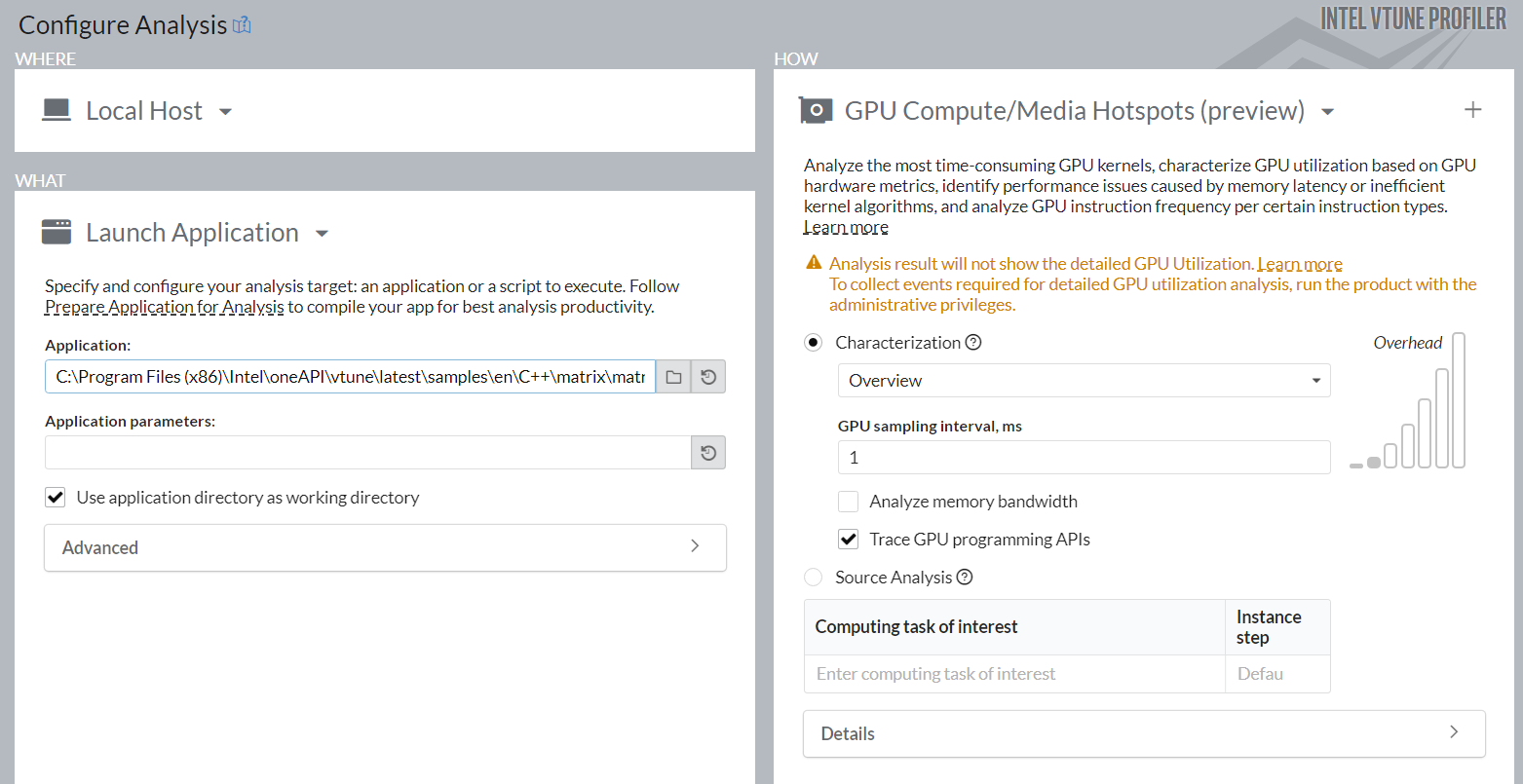
[Accelerators (アクセラレーター)] グループで [GPU Compute/Media Hotspots (GPU 計算/メディア・ホットスポット)] 解析タイプを選択します。
前のセクションで説明したように解析オプションを設定します。
[Start (開始)] ボタンをクリックして、解析を実行します。
コマンドラインから解析を実行する
コマンドラインから解析を実行するには、次のコマンドを使用します。
Linux*:
vtune -collect gpu-hotspots – ./matrix.dpcpp -fsycl
Windows*:
vtune.exe -collect gpu-hotspots -- matrix_multiply.exe
計算タスクを調査する
デフォルトの解析設定は、Overview (概要) メトリックセットを含む [Characterization (特性)] プロファイルを実行します。[GPU Offload (GPU オフロード)] 解析で提供される個々の計算タスクの特性に加えて、GPU メモリー階層ごとに分類されたメモリー帯域幅メトリックを取得できます。

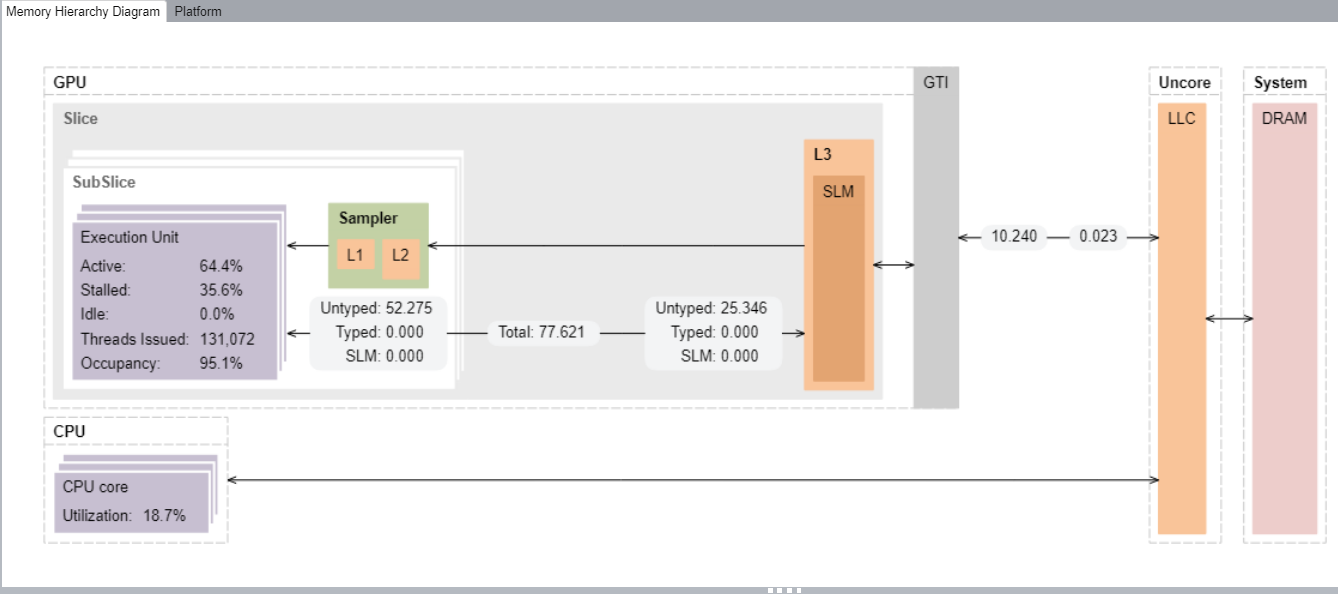
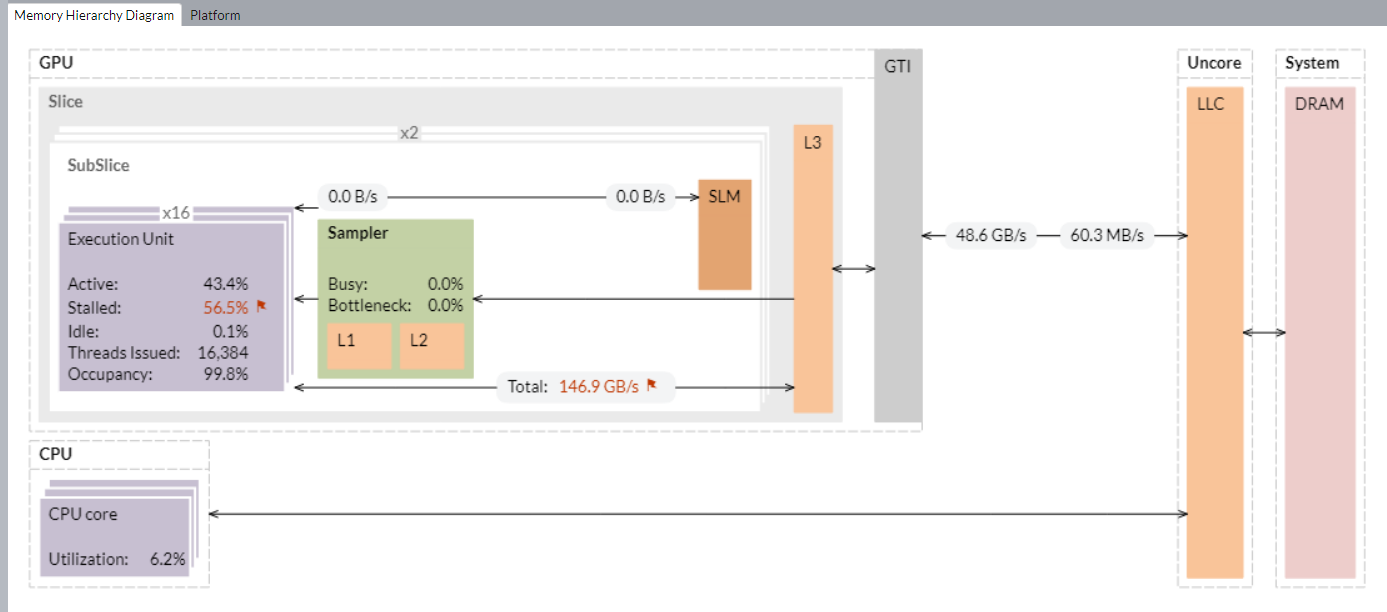
メモリー階層を視覚的に確認するには、[Memory Hierarchy Diagram (メモリー階層ダイアグラム)] を使用します。このダイアグラムは、現在の GPU マイクロアーキテクチャーを反映しており、メモリー帯域幅メトリックを提供します。このダイアログからメモリーユニットと実行ユニット間のデータ・トラフィックを理解できます。また、EU ストールの原因となる潜在的なボトルネックも特定できます。例えば、下の図では、L3 帯域幅とストールした EU の両方が、調査が必要な潜在的な問題としてフラグ付けされていることが分かります。
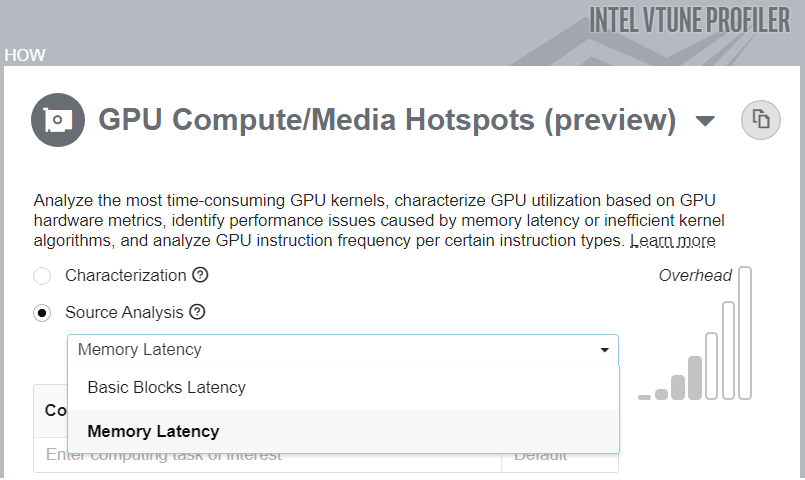
ソースコード・レベルで計算タスクを調査することもできます。例えば、特定のタスクやメモリー・レイテンシーにより費やされた GPU クロックサイクル数を特定するには、[Source Analysis (ソース解析)] オプションを使用します。
このレシピについて、インテル® VTune™ プロファイラー・デベロッパー・フォーラム (英語) で意見交換することができます。
関連情報
- インテル® VTune™ プロファイラーを使用してインテル® GPU 向けにアプリケーションを最適化
- インテル® oneAPI ベース・ツールキットを使用した GPU アプリケーションの最適化
- インテル® Xe グラフィックス製品の GPU アーキテクチャー用語
- GPU オフロード解析
- GPU 計算/メディア・ホットスポット解析
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのトップに戻る
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
