
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Profiling Data Parallel Python* Applications」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピでは、インテル® VTune™ プロファイラーを使用して、Python* アプリケーションのパフォーマンスをプロファイルする方法を紹介します。
ソフトウェアやウェブベースのアプリケーションによってデジタル化が進み、マシンラーニング (ML) アプリケーションの普及が拡大しています。ML コミュニティーは、Tensorflow*、PyTorch*、Keras* などのディープラーニング (DL) フレームワークを使用して、実世界の問題を解決しています。
しかし、Python* や C++ などの DL コードにおける計算やメモリーのボトルネックを理解することは困難であり、階層的なレイヤーや非線形関数の存在により、しばしば多大な労力を必要とします。Tensorflow* や PyTorch* などのフレームワークは、ディープラーニング・モデル開発のさまざまな段階でパフォーマンス・メトリックの収集と解析を可能にするネイティブツールや API を提供していますが、その範囲は限定的であり、ディープラーニング・モデル内のさまざまな演算子や関数の最適化に役立つ、ハードウェア・レベルの詳細は提供しません。
このレシピでは、インテル® VTune™ プロファイラーで Python* ワークロードをプロファイルし、追加の API を使用してデータ収集を改善する方法を学びます。
インテル® ディストリビューションの Python* と Data Parallel Extensions for Python* (英語) を使用して説明します。
コンテンツ・エキスパート: Rupak Roy (英語)、Lalith Sharan Bandaru、Rob Albrecht-Mueller
使用するもの
以下は、このパフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
アプリケーション: ペアワイズ距離計算アルゴリズムの NumPy* サンプル。NumPy* サンプルには、次のパッケージを使用する 3 つの実装があります。
- インテル® ディストリビューションの Python* の NumPy*
- Data Parallel Extension for NumPy*
- Data Parallel Extension for Numba* (GPU)
以下は、NumPy* サンプルのコードです。
import numpy as np import time #compute pairwise distance def pairwise_distance(data, distance): data_sqr = np.sum(np.square(data), dtype = np.float32, axis=1) np.dot(data, data.T, distance) distance *= -2 np.add(distance, data_sqr.reshape(data_sqr.size, 1), distance) np.add(distance, data_sqr, distance) np.sqrt(distance, distance) data = np.random.ranf((10*1024,3)).astype(np.float32) distance = np.empty(shape=(data.shape[0], data.shape[0]), dtype=np.float32) #time pairwise distance calculations start = time.time() pairwise_distance(data, distance) print("Time to Compute Pairwise Distance with Stock NumPy on CPU:", time.time() - start)- 解析ツール: インテル® VTune™ プロファイラー 2022 以降のユーザーモード・サンプリングとトレース収集
- コンパイラー: インテル® oneAPI DPC++/C++ コンパイラー
- ソフトウェア: インテル® ディストリビューションの Python* と Data Parallel Extensions for Python* (英語)
- ソフトウェア・コンポーネント:
- dpcpp-llvm-spirv 2024.1.0
- dpctl 0.16.0
- dpnp 0.14.0+189.gfcddad2474
- mkl-fft 1.3.8
- mkl-random 1.2.4
- mkl-service 2.4.0
- mkl-umath 0.1.1
- numba 0.59.0
- numba-dpex 0.21.4
- numpy 1.26.4
- packaging 23.1
- ittapi 1.1.0
- setuptools 67.7.2
- TBB 0.2
- CPU: インテル® Xeon® Platinum 8480+ プロセッサー
- GPU: インテル® データセンター GPU Max 1550
- オペレーティング・システム: Ubuntu* Server 22.04.3 LTS
Python* パッケージのインストールと設定
- インテル® ディストリビューションの Python* をインストールします。
- インテル® ディストリビューションの Python* の仮想環境を作成します。
python -m venv pyenv source ./pyenv/bin/activate
- Python* パッケージをインストールします。
pip install numpy==1.26.4 pip install dpnp pip install numba pip install numba-dpex pip install ittapi
ホットスポット解析によるペアワイズ距離計算の NumPy* 実装のプロファイル
NumPy* 実装にインテル® インストルメンテーションおよびトレーシング・テクノロジー (ITT) API を追加して、論理タスクを指定します。
import numpy as np
import ittapi
def pairwise_distance(data, distance):
with ittapi.task('pairwise_sum'):
data_sqr = np.sum(np.square(data), dtype = np.float32, axis=1)
with ittapi.task('pairwise_dot'):
np.dot(data, data.T, distance)
distance *= -2
with ittapi.task('pairwise_add'):
np.add(distance, data_sqr.reshape(data_sqr.size, 1), distance)
np.add(distance, data_sqr, distance)
with ittapi.task('pairwise_sqrt'):
np.sqrt(distance, distance)
with ittapi.task('data_load'):
data = np.random.ranf((100*1024,3)).astype(np.float32)
distance = np.empty(shape=(data.shape[0], data.shape[0]), dtype=np.float32)
注釈付きの NumPy* コードのホットスポット解析を実行します。この解析は、コード内の最も時間のかかる領域を特定する良い出発点です。Python* コードに関するプロファイル情報を確認できるように、解析でユーザーモード・サンプリングを有効にしてください。
コマンドラインで、次のコマンドを入力します。
vtune -collect hotspots -knob sampling-mode=sw --python3 NumPy-Implementation.py
このコマンドは、NumPy* 実装のサンプリング・モードのホットスポット解析を実行します。解析が完了すると、プロファイル結果が [Summary (サマリー)] ウィンドウに表示されます。
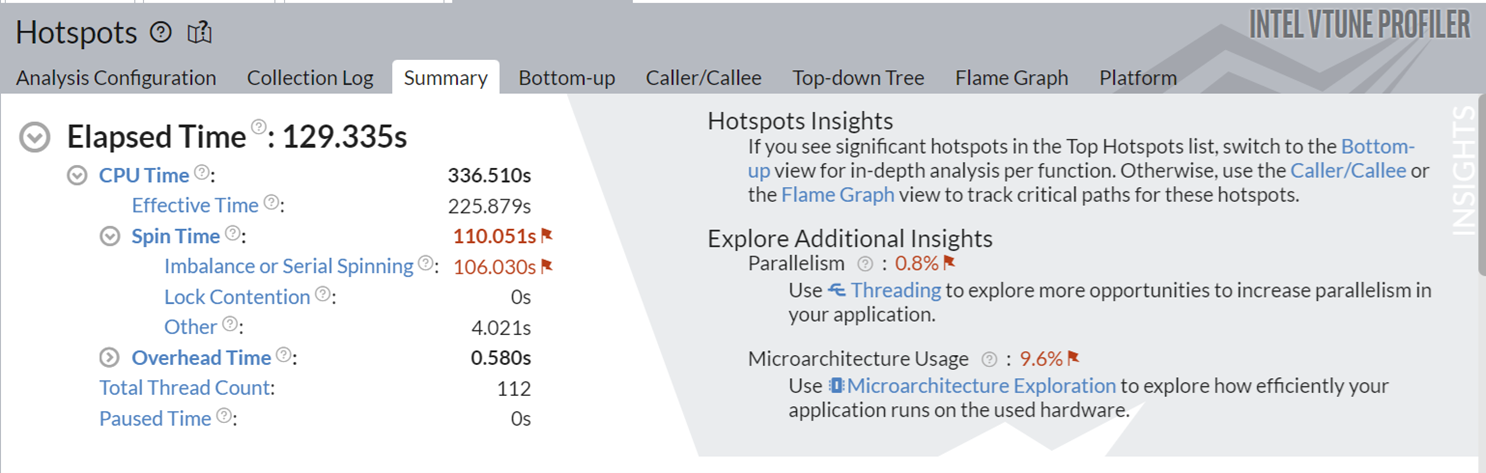
この実装は実行に約 130 秒かかり、シリアルスピンにかなりの時間を費やしています。右上の [Additional Insights (その他の情報)] セクションでは、これらのボトルネックをよく理解するため、[Threading (スレッド化)] 解析と [マイクロアーキテクチャー全般解] 解析の実行を検討するように推奨されています。
次に、アプリケーションの上位のタスクを確認します。
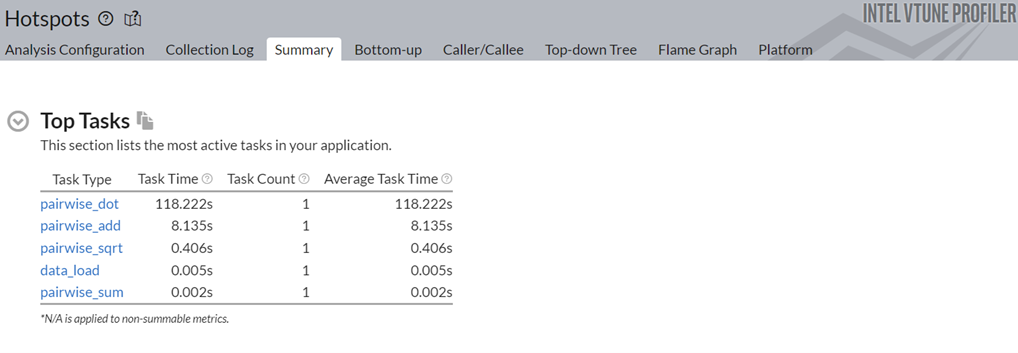
テーブルの最上位にある pairwise_dot タスクをクリックします。[Bottom-up (ボトムアップ)] ウィンドウに切り替えて、このタスク内の API を調べます。
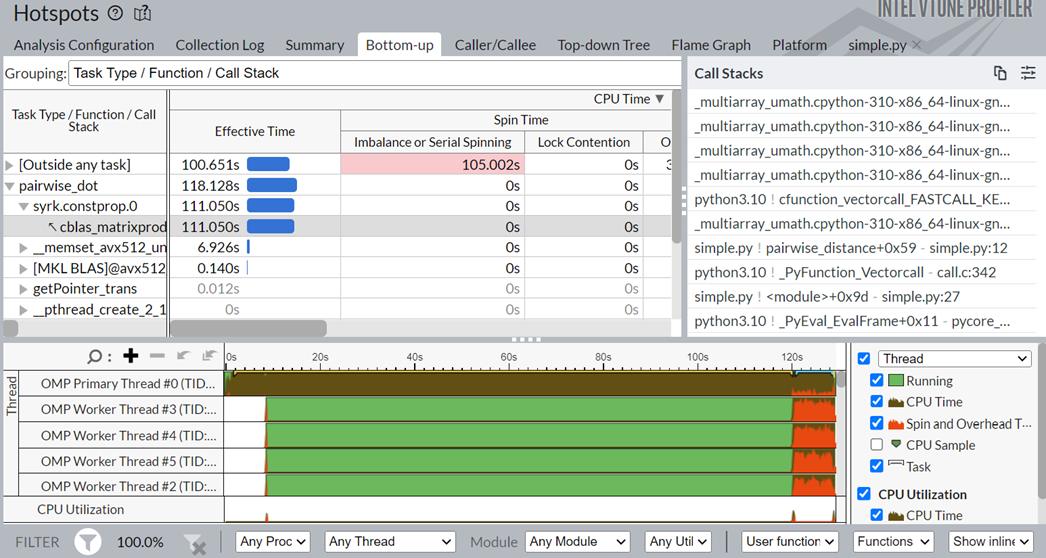
上の図の [Task Type (タスクタイプ)] 列では、pairwise_dot タスクに複数の API が関連付けられています。syrk oneMKL ルーチンが最も多くの時間を費やしており、次に memset とその他の操作が続きます。
simple.py のソースコード・ウィンドウに切り替えます。np.dot 関数が合計実行時間の 33% を占めていることが分かります。
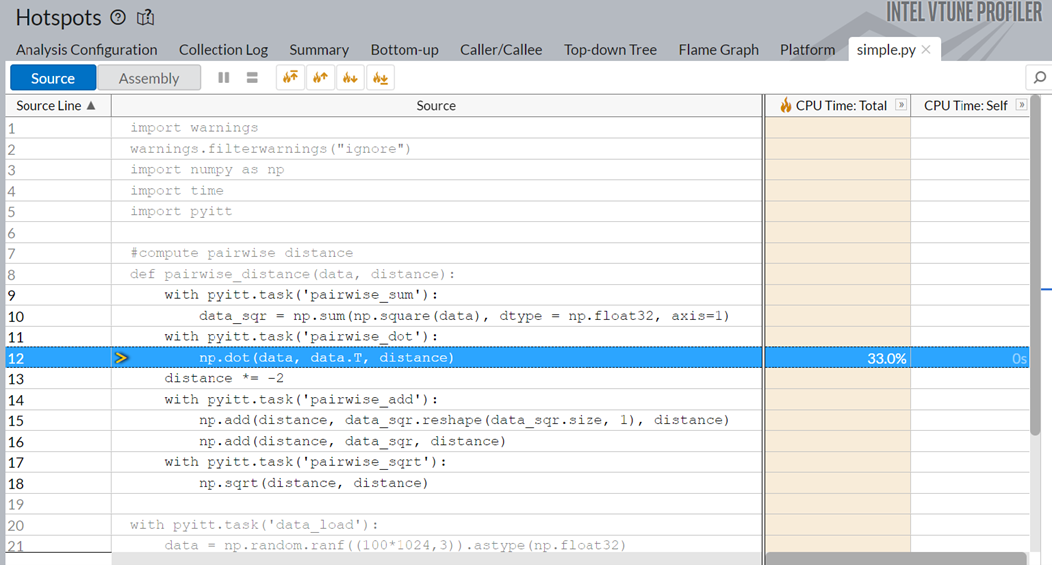
np.dot 関数を最適化したり、より優れた API に置き換えるとアプリケーションの実行時間が大幅に改善される可能性があります。
ホットスポット解析によるペアワイズ距離計算の Data Parallel Extension for NumPy* 実装のプロファイル
前の手順で特定したボトルネックを最適化してみましょう。NumPy* 実装から Data Parallel Extension for NumPy* 実装に切り替えます。次に示すように、オリジナルのコードで numpy を dpnp に置き換えます。
import dpnp as np
import time
#compute pairwise distance
def pairwise_distance(data, distance):
data_sqr = np.sum(np.square(data), dtype = np.float32, axis=1)
np.dot(data, data.T, distance)
distance *= -2
np.add(distance, data_sqr.reshape(data_sqr.size, 1), distance)
np.add(distance, data_sqr, distance)
np.sqrt(distance, distance)
data = np.random.ranf((10*1024,3)).astype(np.float32)
distance = np.empty(shape=(data.shape[0], data.shape[0]), dtype=np.float32)
#time pairwise distance calculations
start = time.time()
pairwise_distance(data, distance)
print("Time to Compute Pairwise Distance with Stock NumPy on CPU:", time.time() - start)
Data Parallel Extension for NumPy* 実装のホットスポット解析を実行します。
プロファイルが完了したら、[Summary (サマリー)] ウィンドウで結果を開きます。

合計実行時間が 130 秒から 33.38 秒に大幅に改善されたことが分かります。
この改善の理由を理解するには、[Summary (サマリー)] ウィンドウの [Top Tasks (上位のタスク)] セクションに移動します。
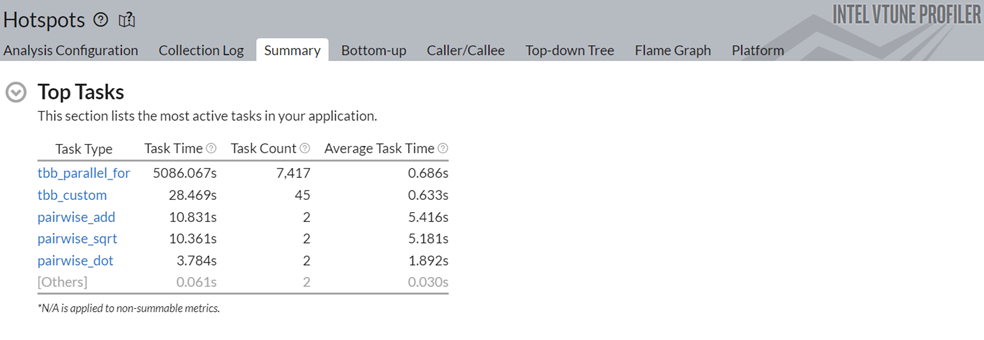
pairwise_dot タスクの実行時間が 118.2 秒から 3.78 秒に短縮されています。Data Parallel Extension for NumPy* 実装によってもたらされた変更を確認するには、[Bottom-Up (ボトムアップ)] ウィンドウに切り替えます。
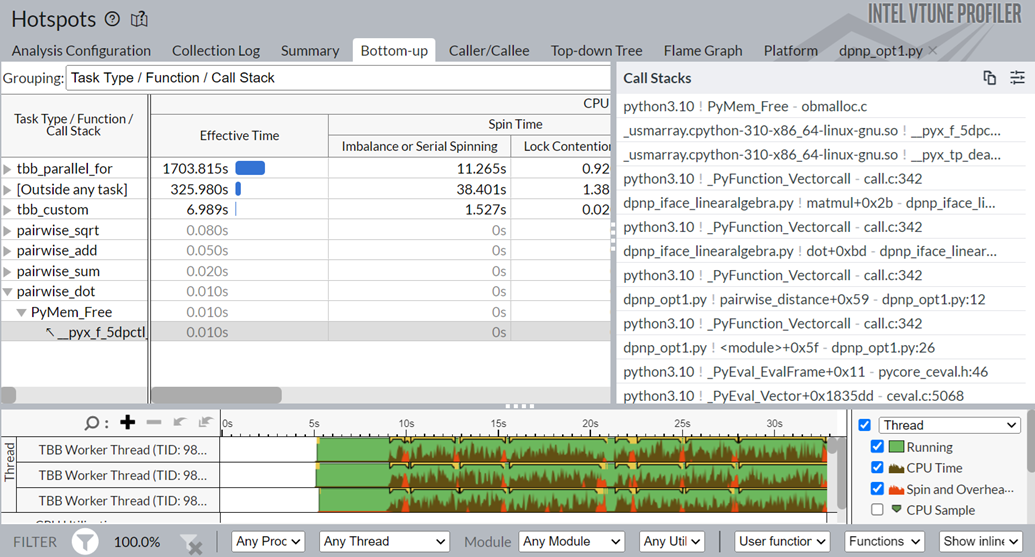
pairwise_dot 関数が、NumPy* 実装で使用していた oneMKL API の代わりに、dpctl API を使用していることが分かります。dpctl API がパフォーマンス向上をもたらしています。
[Summary (サマリー)] ウィンドウの [Additional Insights (その他の情報)] セクションに移動して、アプリケーションの並列性を高めてみましょう。そのためには、Numba 実装を使用します。
ホットスポット解析によるペアワイズ距離計算の Data Parallel Extension for Numba* 実装のプロファイル
ペアワイズ距離の Numba 実装は、以下のコードを使用します。
from numba_dpex import dpjit
from numba import prange
@dpjit #using Numba JIT compiler optimizations, now on any SYCL device
def pairwise_distance(data, distance):
float0 = data.dtype.type(0)
#prange used for parallel loops for further opt
for i in prange(data.shape[0]):
for j in range(data.shape[0]):
d = float0
for k in range(data.shape[1]):
d += (data[i, k] - data[j, k])**2
distance[j, i] = np.sqrt(d)
data = np.random.ranf((10*1024,3)).astype(np.float32)
distance = np.empty(shape=(data.shape[0], data.shape[0]), dtype=np.float32)
#do compilation first run, wecode- will calculate performance on subsequent runs
#wrapper consistent with previous np and dpnp scripts
pairwise_distance(data, distance)
#time pairwise distance calculations
start = time.time()
pairwise_distance(data, distance)
#using heterogeneous
Numba 実装の GPU 計算/メディア・ホットスポット解析を実行します。
vtune -collect gpu-hotspots –-python numba_implementation.py
解析が完了したら、[Summary (サマリー)] ウィンドウで結果を確認します。
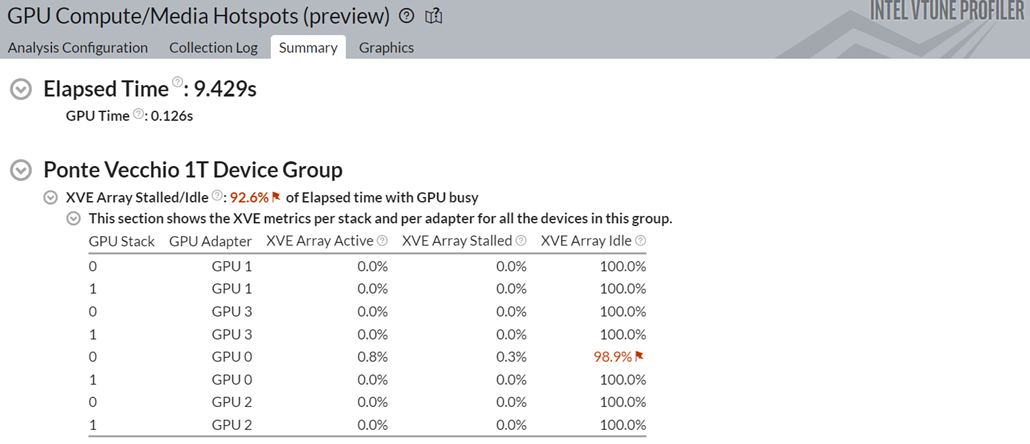
Numba 実装を使用すると、パフォーマンスが 3 倍スピードアップすることが分かります。
また、利用可能な 4 つの GPU のうち、GPU 0 の Stack 0 のみが使用されています。アイドル時間は長く、これは小規模なワークロードではよくあることです。それにもかかわらず、合計実行時間は大幅に改善しています。
[Graphics (グラフィックス)] ウィンドウに切り替えます。テーブルの結果を [Computing Task (計算タスク)] でグループ化します。
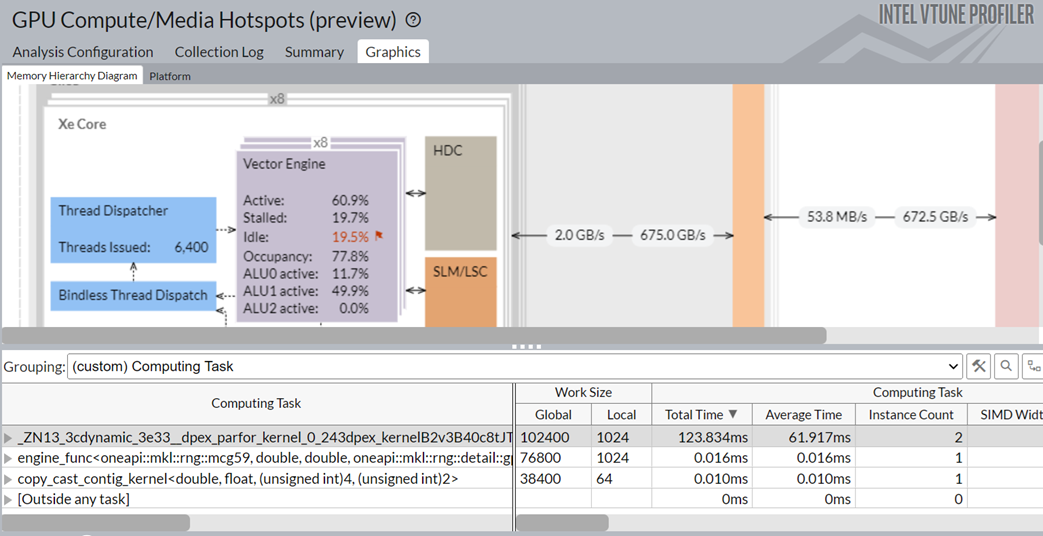
以下のことが分かります。
- Numba dpex_kernel は最も多くの時間を費やしています。これは想定どおりです。
- Numba dpex_kernel は GPU ベクトルエンジンをビジー状態に保ちます。Xe ベクトルエンジンのアクティビティー・レベルは約 60.9% です。
複数のカーネルで大規模なワークロードを使用する場合、computing-tasks-of-interest knob で注目するカーネルを指定します。
