この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Poor Port Utilization」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、インテル® VTune™ Amplifier のマイクロアーキテクチャー全般解析を使用してコア依存の matrix アプリケーションをプロファイルし、低いポート使用率の原因を理解します。また、インテル® Advisor を使用してコンパイラーがベクトル化を行うようにします。
コンテンツ・エキスパート: Dmitry Ryabtsev (英語)
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: 2048×2048 サイズの 2 つの行列を乗算する行列乗算サンプル (要素は double 型)。matrix_vtune_amp_axe.tgz サンプルパッケージは、製品の <install-dir>/samples/en/C++ ディレクトリーに含まれています。https://software.intel.com/en-us/product-code-samples (英語) からダウンロードすることもできます。
- パフォーマンス解析ツール:
- インテル® VTune™ Amplifier 2019: マイクロアーキテクチャー全般解析 (英語)
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- インテル® Advisor: ベクトル化解析 (英語)
- インテル® VTune™ Amplifier 2019: マイクロアーキテクチャー全般解析 (英語)
- オペレーティング・システム: Ubuntu* 16.04 64 ビット
- CPU: インテル® Core™ i7-6700K プロセッサー
ベースラインを作成する
単純な乗算アルゴリズムを実装した matrix コードの初期バージョンを最適化することにより (「頻繁な DRAM アクセス」レシピを参照)、実行時間は 26 秒から 1.3 秒になりました。これが、以降の最適化で使用する新しいパフォーマンスのベースラインとなります。
マイクロアーキテクチャー全般解析を実行する
サンプル・アプリケーションの潜在的なパフォーマンス・ボトルネックを理解するため、全般解析を実行します。
- ツールバーの
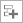 [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: matrix) を指定します。
[New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: matrix) を指定します。
[Configure Analysis (解析の設定)] ウィンドウが表示されます。
- [WHERE (どこを)] ペインで、[Local Host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [WHAT (何を)] ペインで、[Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、解析するアプリケーションを指定します。
- [HOW (どのように)] ペインで、[…] ボタンをクリックして [Microarchitecture (マイクロアーキテクチャー)] > [Microarchitecture Exploration (マイクロアーキテクチャー全般)] を選択します。
- オプションで、最適化した matrix アプリケーションのように小さなワークロードで、サンプリング間隔を 0.1 秒にして信頼性のあるメトリック値が得られるか確認します。
- [Start (開始)] をクリックして解析を開始します。
インテル® VTune™ プロファイラーは、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
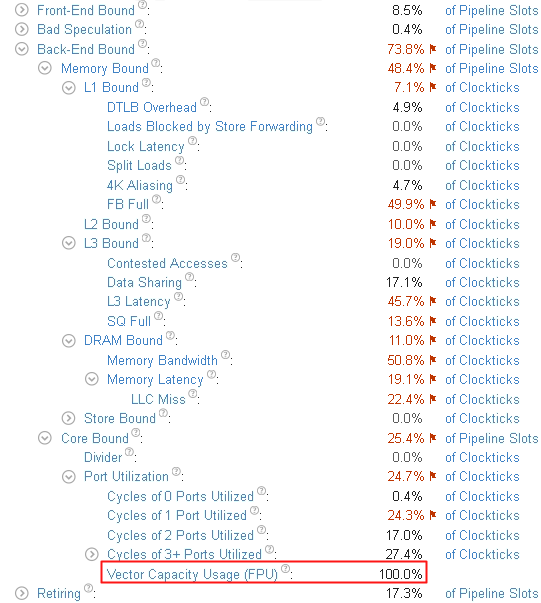
低いポート使用率の原因を特定する
ハードウェア・メトリックごとのアプリケーション・パフォーマンスの統計が表示される [Summary (サマリー)] ビューから始めます。
主要なボトルネックが [Core Bound (コア依存)] > [Port Utilization (ポート利用率)] に移動し、ほとんどの時間で 3 つ以上の実行ポートが同時に使用されていることが分かります。[Vector Capacity Usage (ベクトル能力の使用)] メトリックもクリティカルな値としてフラグが付いていることに注意してください。これは、コードがベクトル化されていないか、ベクトル化の効率が悪いことを意味します。確認のため、次のように、カーネルの [Assembly (アセンブリー)] ビューに切り替えます。
- [Vector Capacity Usage (FPU) (ベクトル能力の使用 (FPU))] メトリックをクリックして、このメトリックでソートされた [Bottom-up (ボトムアップ)] ビューに切り替えます。
- ホットな multiply1 関数をダブルクリックして [Source (ソース)] ビューを開きます。
- ツールバーの [Assembly (アセンブリー)] ボタンをクリックして、逆アセンブルしたコードを表示します。
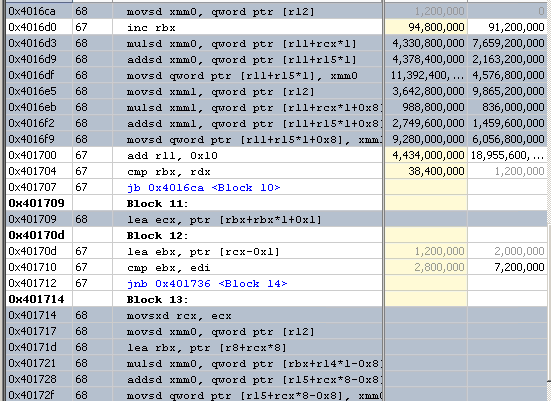
スカラー命令が使用されていることが分かります。コードはベクトル化されていません。
ベクトル化のオプションを調べる
インテル® Advisor のベクトル化アドバイザー・ツールを使用して、コードのベクトル化を妨げている原因を調べます。
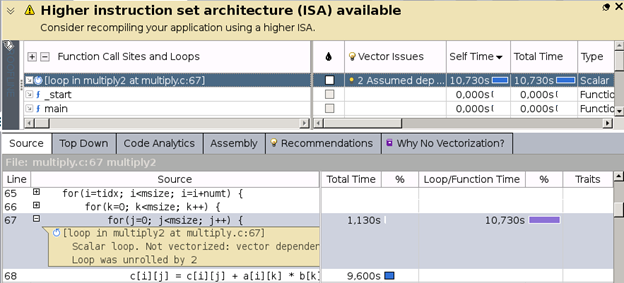
インテル® Advisor は、依存関係が仮定されたためにループがベクトル化されなかったと報告しました。詳細に確認するため、ループをマークしてインテル® Advisor の依存関係解析を実行します。
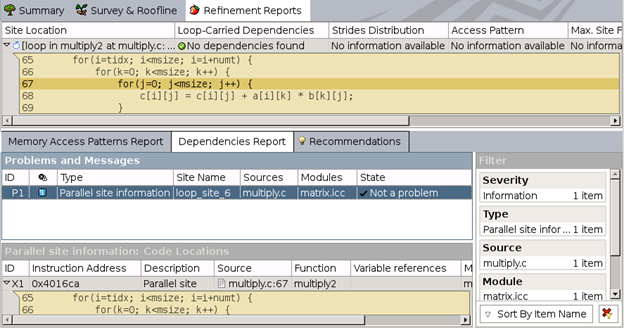
レポートによれば、依存関係は存在していません。インテル® Advisor は、コンパイラーが仮定された依存関係を無視するように #pragma を使用することを推奨しています。

次の ように、matrix コードに #pragma を追加します。
void multiply2_vec(inte msize, int tidx, int numt, TYPE a[][NUM],
TYPE b[][NUM], TYPE c[][NUM], TYPE t[][NUM]
{
int i,j,k;
for(i=tidx; i<msize; i=i+numt) {
for(k=0; k<msize; k++) {
#pragma ivdep
for(j=0; j<msize; j++) {
c[i][j] = c[i][j] + a[i][j] * b[i][j];
}
}
}
}
更新したコードをコンパイルして実行すると、実行時間は 0.7 秒になりました。
最新の命令セットを使用してコンパイルする
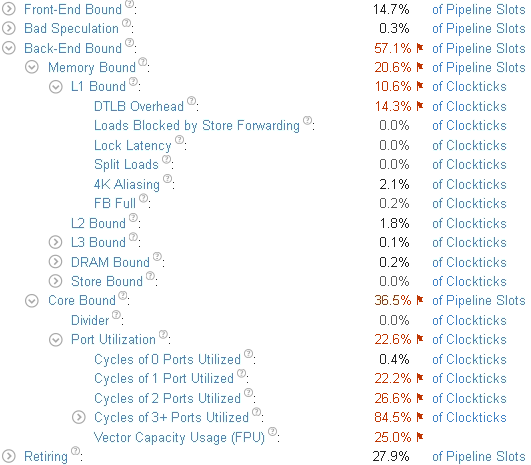
最新バージョンのコードでインテル® VTune™ プロファイラーのマイクロアーキテクチャー全般解析を再度実行すると、結果は次のようになりました。

[Vector Capacity Usage (ベクトル能力の使用)] は 50% まで向上していますが、まだパフォーマンス・クリティカルのフラグが付いたままです。詳細な情報を得るため、[Assembly (アセンブリー)] ビューを再度調べます。
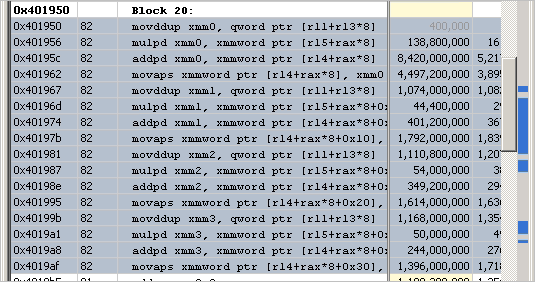
再コンパイルしたコードでは、実行時間は 0.6 秒になりました。マイクロアーキテクチャー全般解析を再度実行して最適化を確認します。[Vector Capacity Usage (ベクトル能力の使用)] メトリックの値は 100% になりました。