
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「OS Thread Migration」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、インテル® VTune™ Amplifier の高度な hotspot 解析を使用して NUMA アーキテクチャーの OS スレッド・マイグレーションを特定する手順を説明します。
注
高度な hotspot 解析は、インテル® VTune™ Amplifier 2019 で汎用の hotspot 解析 (英語) に統合されました。ハードウェア・イベントベース・サンプリング収集モードで利用できます。
現代の複雑なオペレーティング・システムは、スケジューラーを使用してアプリケーション・スレッド (ソフトウェア・スレッド) をプロセッサー・コアに割り当てます。スケジューラーは、システムステート、システムポリシーなどのさまざまな異なる要因に応じて、物理コア上のアプリケーション・スレッドの配置を選択します。ソフトウェア・スレッドは、スワップアウトされて待機状態になるまで、コアで一定時間実行されます。ソフトウェア・スレッドは、I/O によるブロックのようなさまざまな理由により待機します。利用可能な場合、別のソフトウェア・スレッドがこのコアで実行されます。オリジナルのソフトウェア・スレッドが再度実行可能になると、スケジューラーは、オリジナルのソフトウェア・スレッドが実行できるように別のソフトウェア・スレッドを別のコアに移動します。ソフトウェア・スレッドを移動すると、スレッドとすでにキャッシュにフェッチされたデータの関連付けが解消され、データアクセスのレイテンシーが大きくなるため、新しい計算アーキテクチャーでは問題が発生します。この問題は、各プロセッサーが個別のローカルメモリーを保持し、それらに直接アクセスする NUMA (Non Uniform Memory Access) アーキテクチャーではさらに大きくなります。NUMA アーキテクチャーでは、ソフトウェア・スレッドを別のコアに移動すると、以前のコアのローカルメモリーに格納されていたデータがリモートになり、メモリーアクセス時間が大幅に増加します。スレッド・マイグレーションはパフォーマンス低下の原因となるため、アプリケーションでスレッド・マイグレーションが発生しているかどうか確認することが重要です。
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: OpenMP* テスト・アプリケーション。このアプリケーションはデモ用であり、ダウンロードすることはできません。
- パフォーマンス解析ツール: インテル® VTune™ Amplifier 2018: 高度な hotspot 解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- オペレーティング・システム: Ubuntu* 16.04 64 ビット
- CPU: インテル® Core™ i7-6700K プロセッサー
高度な hotspot 解析を実行する
インテル® VTune™ Amplifier (GUI または amplxe-cl) を使用して、インテル® アーキテクチャー上で実行中のアプリケーションのソフトウェア・スレッド・マイグレーションを特定します。OS スレッド・マイグレーションを特定するには、アプリケーションで基本 hotspot 解析または高度な hotspot 解析を実行します。高度な hotspot 解析の例を次に示します。
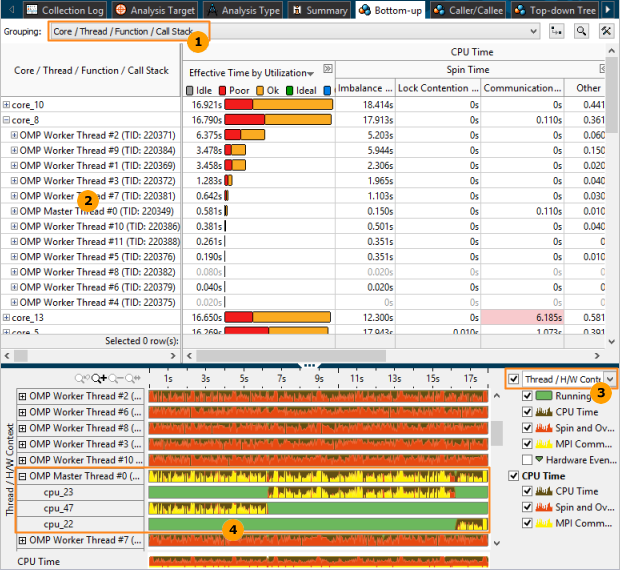
スレッド・マイグレーションを特定する
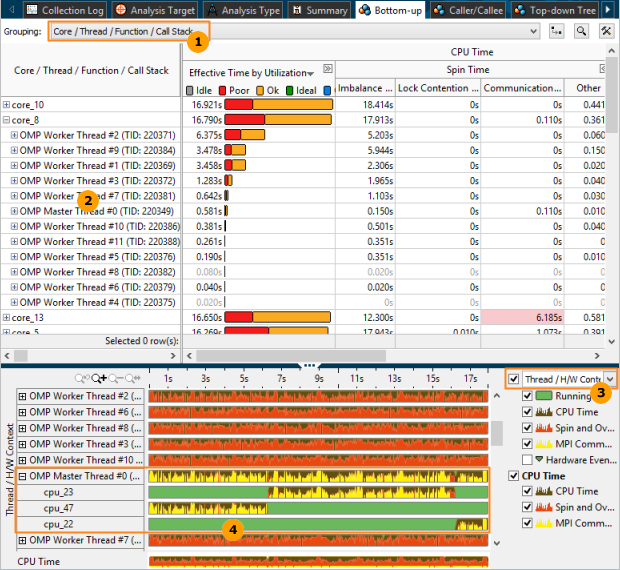
| GUI を使用してスレッド・マイグレーションを特定するには、[Core/Thread/Function/Call Stack (コア/スレッド/関数/コールスタック)] グループを選択します。 | |
| コアノードを展開してソフトウェア・スレッドの数を確認します。一般に、ソフトウェア・スレッドの数は、CPU でサポートしているハードウェア・スレッドの数以下にする必要があります。また、スレッドをコア間で均等に分散する必要もあります。いずれかのコアに予想よりも多くのソフトウェア・スレッドが表示されている場合、アプリケーションでスレッド・マイグレーションが発生しています。上記の例では、(インテル® Xeon® プロセッサーはインテル® ハイパースレッディング・テクノロジーをサポートしているため) 予想される 2 スレッドではなく 12 の OpenMP* ワーカースレッドが core_8 で実行されています。これはスレッド・マイグレーションを示しています。 | |
| [Thread/H/W Context (スレッド/ハードウェア・コンテキスト)] グループを選択して、[Timeline (タイムライン)] ペインでスレッド・マイグレーションを解析します。 | |
| スレッドのノードを展開して、このスレッドが実行された CPU の番号を確認し、経時的なスレッド実行を解析します。上記の例では、OpenMP* スレッド #0 は cpu_23 で実行された後、cpu_47 に移動しています。 |
次のように、コマンドラインから直接これらの結果を見ることもできます。
amplxe-cl -group-by thread,cpuid -report hotspots -r /temp/test/omp -s "H/W Context" -q | less Thread H/W Context CPU Time:Self ------------------------------ ----------- ------------- OMP Worker Thread #5 (0x3d86) cpu_0 0.004 matmul-intel64 (0x3d52) cpu_1 0.013 OMP Worker Thread #15 (0x3d90) cpu_10 2.418 matmul-intel64 (0x3d52) cpu_10 2.023 OMP Worker Thread #8 (0x3d89) cpu_10 0.687 OMP Worker Thread #13 (0x3d8e) cpu_10 0.097 OMP Worker Thread #6 (0x3d87) cpu_10 0.065 OMP Worker Thread #4 (0x3d85) cpu_10 0.059 OMP Worker Thread #1 (0x3d82) cpu_10 0.048 OMP Worker Thread #9 (0x3d8a) cpu_10 0.034 OMP Worker Thread #11 (0x3d8c) cpu_10 0.009
多くの OpenMP* ワーカースレッドが cpu_10 で実行されていることも分かります。
スレッド・マイグレーションを訂正する
スレッド・マイグレーションはスレッド・アフィニティーを設定することで訂正できます。スレッド・アフィニティーは、特定のスレッドの実行をマルチプロセッサー・コンピューターの物理処理ユニットの一部に限定します。インテルのランタイム・ライブラリーには、OpenMP* スレッドを物理処理ユニットにバインドする機能があります。OMP_PROC_BIND および OMP_PLACES、またはインテルのランタイム固有の KMP_AFFINITY 環境変数を使用して OpenMP* アプリケーションのスレッド・アフィニティーを設定することもできます。
