
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「OpenMP* Imbalance and Scheduling Overhead」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、バリアやスケジュール・オーバーヘッドのインバランスなど、OpenMP* プログラムでよくある並列ボトルネックを検出して修正する方法を説明します。
コンテンツ・エキスパート: Dmitry Prohorov (英語)
バリアは、スレッドチームのすべてのスレッドがバリアに到達した後に実行できる同期ポイントです。実行作業が不規則で、作業チャンクがワーカースレッドによって均等かつ静的に分散されている場合、バリアに到達したスレッドは、有効な作業を行う代わりにほかのスレッドを待機して時間を無駄にします。チーム内のスレッド数で正規化されたバリアでの合計待機時間は、インバランスを排除することでアプリケーションが軽減できる経過時間を示しています。
バリアのインバランスを排除する 1 つの方法は、動的スケジューリングを使用してスレッド間で動的に作業チャンクを分散することです。ただし、細粒度のチャンクでこれを行うと、スケジュール・オーバーヘッドにより状況がさらに悪化することがあります。このレシピを参考にして、インテル® VTune™ Amplifier を使用して OpenMP* ロード・インバランスとスケジュール・オーバーヘッドの問題に対応するワークフローを学びます。
- 使用するもの
- 手順:
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: 特定の範囲の素数を計算するアプリケーション。メインループは、OpenMP* parallel for 構文で並列化されています。
- コンパイラー: インテル® コンパイラー 13 Update 5 以降。このレシピは、インテル® VTune™ Amplifier の解析で使用されるインテルの OpenMP* ランタイム・ライブラリー内のインストルメンテーションを実行するため、このコンパイラー・バージョンを必要とします。インテル® コンパイラーの parallel-source-info=2 オプションを追加してコンパイルすることで、OpenMP* 領域名でソースファイル情報が提供され、ユーザーが識別しやすくなります。
- パフォーマンス解析ツール:
- インテル® VTune™ Amplifier 2018: HPC パフォーマンス特性解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- インテル® VTune™ Amplifier 2018: HPC パフォーマンス特性解析
- オペレーティング・システム: Ubuntu* 16.04 LTS
- CPU: インテル® Xeon® プロセッサー E5-2699 v4 @ 2.20GHz
ベースラインを作成する
サンプルコードの初期バージョンは、デフォルトの静的スケジューリングでループに OpenMP* parallel for プラグマを使用します (行 21)。
#include <stdio.h>
#include <omp.h>
#define NUM 100000000
int isprime( int x )
{
for( int y = 2; y * y <= x; y++ )
{
if( x % y == 0 )
return 0;
}
return 1;
}
int main( )
{
int sum = 0;
#pragma omp parallel for reduction (+:sum)
for( int i = 2; i <= NUM ; i++ )
{
sum += isprime ( i );
}
printf( "Number of primes numbers: %d", sum );
return 0;
}
コンパイルしたアプリケーションの実行には約 3.9 秒かかります。これが、以降の最適化で使用するパフォーマンスのベースラインとなります。
HPC パフォーマンス特性解析を実行する
サンプル・アプリケーションの潜在的なパフォーマンス・ボトルネックを理解するため、まず、インテル® VTune™ プロファイラーの HPC パフォーマンス特性解析を実行します。
- ツールバーの
 [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: primes) を指定します。
[New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: primes) を指定します。
- [Create Project (プロジェクトの作成)] をクリックします。
[Configure Analysis (解析の設定)] ウィンドウが表示されます。
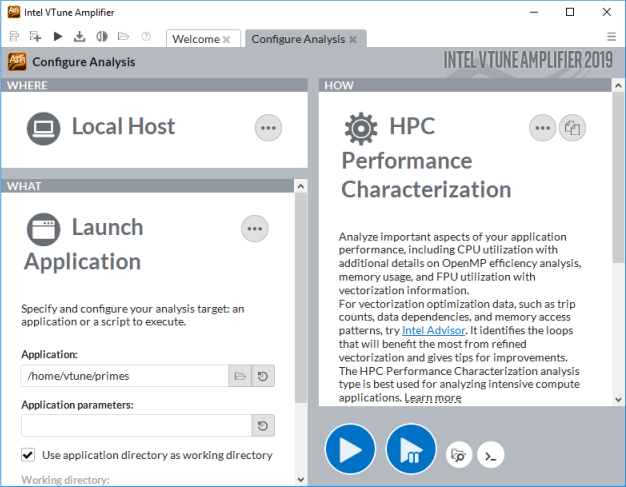
- [WHERE (どこを)] ペインで、[Local Host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [WHAT (何を)] ペインで、[Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、解析するアプリケーションを指定します。次に例を示します。
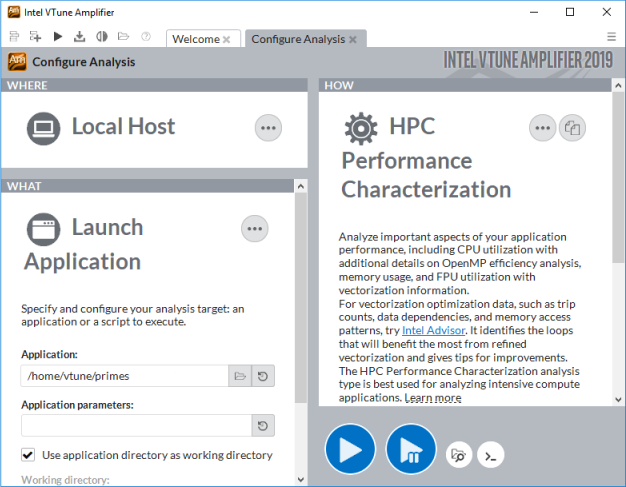
- [HOW (どのように)] ペインで、[…] ボタンをクリックして [Parallelism (並列処理)] グループから [HPC Performance Characterization (HPC パフォーマンス特性)] 解析を選択します。
 [Start (開始)] ボタンをクリックします。
[Start (開始)] ボタンをクリックします。
インテル® VTune™ Amplifier は、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
OpenMP* のインバランスを特定する
HPC パフォーマンス特性解析は、CPU 使用率 (並列性)、メモリーアクセス効率、ベクトル化などのパフォーマンス・ボトルネックの理解に役立つ重要な HPC メトリックを収集して表示します。このレシピのようにインテルの OpenMP* ランタイムを使用するアプリケーションでは、スレッド並列処理の問題の特定を支援する特別な OpenMP* 効率メトリックが役立ちます。
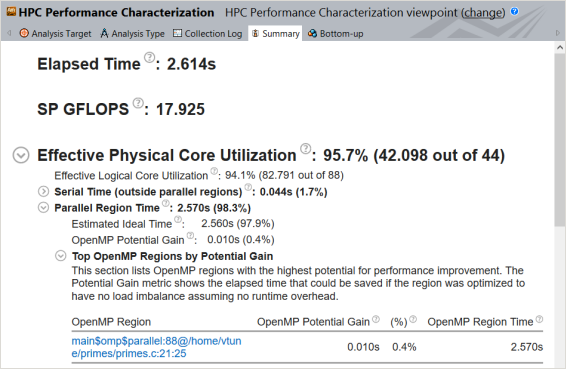
アプリケーション・レベルの統計が表示される [Summary (サマリー)] ビューから解析を始めます。フラグが付いた [Effective Physical Core Utilization (効率的な物理コア利用率)] メトリック (一部のシステムでは [CPU Utilization (CPU 使用率)]) は、調査すべきパフォーマンスの問題を示しています。
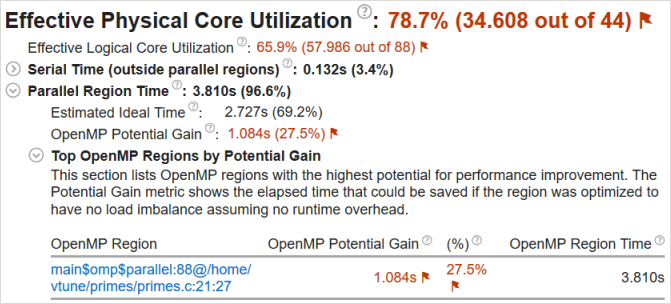
[Parallel Region Time (並列領域時間)] > [OpenMP Potential Gain (OpenMP* 潜在的なゲイン)] メトリックに移動して、非効率な並列処理を改善することで得られる最大ゲインを予測します。このサンプルでは、1.084 秒 (アプリケーションの実行時間の 27.5%) にフラグが付いているため、parallel 構文を詳しく調べる価値があります。
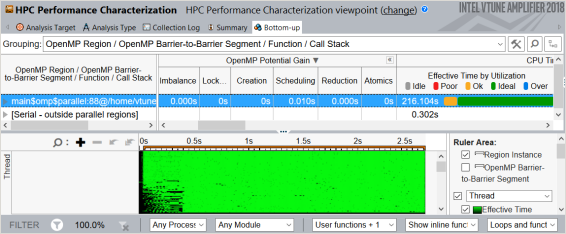
このサンプル・アプリケーションでは、[Top OpenMP Regions by Potential Gain (潜在的なゲインによる上位 OpenMP* 領域)] セクションに 1 つの parallel 構文があります。テーブルで領域名をクリックして、[Bottom-up (ボトムアップ)] ビューで詳細を確認します。[Bottom-up (ボトムアップ)] グリッドの [OpenMP Potential Gain (OpenMP* 潜在的なゲイン)] カラムを展開して非効率の詳細を表示します。このデータは、アプリケーションではなく OpenMP* で CPU 時間が費やされている原因と、それによる経過時間への影響を理解するのに役立ちます。
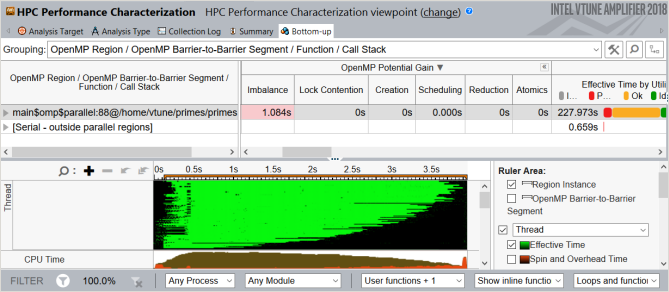
グリッド行のホットな領域で [Imbalance (インバランス)] メトリックの値がハイライトされています。マウスでこの値をポイントすると、動的スケジューリングによりインバランスを排除することを推奨するヒントが表示されます。領域内に複数のバリアがある場合は、領域ノードをバリアごとのセグメントに展開して、パフォーマンス・クリティカルなバリアを特定する必要があります。
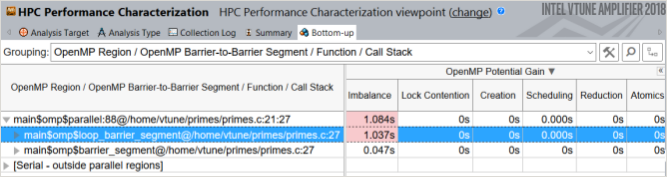
このサンプルには、インテル® VTune™ Amplifier によって分類されない重大なインバランスを持つループバリアと並列領域のジョインバリアがあります。
注
アプリケーションの実行中にインバランスを視覚化するには、[Timeline (タイムライン)] ビューを調査します。有効な作業を実行している時間は緑色で示され、浪費時間は黒色で示されます。
動的スケジューリングを適用する
このインバランスは、静的な作業分散により、特定のスレッドに大きな数字を割り当てる一方で、一部のスレッドは小さな数字のチャンクを短時間で処理しバリアで時間を無駄にしていることが原因です。このインバランスを解消するには、デフォルトのパラメーターで動的スケジューリングを適用します。
int sum = 0;
#pragma omp parallel for schedule(dynamic) reduction (+:sum)
for( int i = 2; i <= NUM ; i++ )
{
sum += isprime ( i );
}
アプリケーションを再コンパイルして、その実行時間とオリジナルのパフォーマンス・ベースラインを比較して、最適化を検証します。
OpenMP* スケジュール・オーバーヘッドを特定する
変更したサンプル・アプリケーションを実行すると、スピードアップせずに実行時間が 5.3 秒に増えます。これは、細粒度の作業チャンクで動的スケジューリングを適用した場合に起こる副作用です。潜在的なボトルネックの詳細を把握するには、HPC パフォーマンス特定解析を再度実行して、パフォーマンス低下の原因を確認することを検討してください。
- メニューから [New (新規)] > [HPC Performance Characterization Analysis (HPC パフォーマンス特性解析)] を選択して、既存の primes プロジェクトの解析設定を開きます。
- [Start (開始)] をクリックします。
[Summary (サマリー)] ビューでは、パフォーマンス・クリティカルとして [Effective Physical Core Utilization (効率的な物理コア利用率)] メトリックにフラグが付けられており、[OpenMP Potential Gain (OpenMP* 潜在的なゲイン)] の値がオリジナルの値の 1.084 秒よりも増えています。
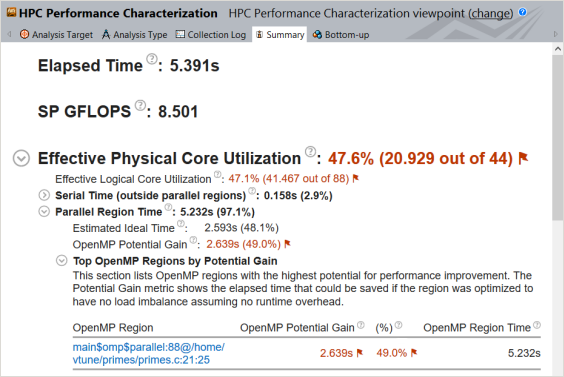
このデータは、コードの並列効率が低下したことを裏付けています。原因を理解するため、[Bottom-up (ボトムアップ)] ビューに切り替えます。
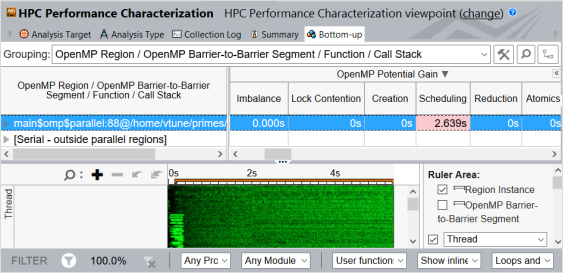
以前の解析結果と比較すると、[Scheduling (スケジューリング)] オーバーヘッドはインバランスよりもさらに深刻な状況にあります。これは、ワーカースレッドごとに 1 ループ反復を割り当てるスケジューラーのデフォルトの動作が原因です。スレッドがすぐにスケジューラーに戻るため、コンカレンシーが高すぎてボトルネックとなります。タイムラインの [Effective Time (有効な時間)] メトリックの分布 (緑色) は、スレッドによる通常の作業を示していますが、密度が低くなっています。グリッドでハイライトされている [Scheduling (スケジューリング)] メトリックの値にマウスホバーするとパフォーマンスに関するアドバイスが表示され、OpenMP* parallel for プラグマでチャンクを使用して並列処理を粗粒度にし、スケジュール・オーバーヘッドを排除するように推奨されます。
チャンク・パラメーターを使用して動的スケジューリングを適用する
次のように、schedule 節のチャンク・パラメーターを 20 にします。
#pragma omp parallel for schedule(dynamic,20) reduction (+:sum)
for( int i = 2; i <= NUM ; i++ )
{
sum += isprime ( i );
}
再コンパイルすると、アプリケーションの実行時間は 2.6 秒になりました (ベースラインと比較して 30% の向上)。[Summary (サマリー)] ビューは、理想に近い [Parallel Region Time (並列領域時間)] (98.3%) を示しています。
動的スケジューリングは、頻繁に新しい作業チャンクをスレッドへ割り当てるため、キャッシュの再利用が妨げられ、コード実行のキャッシュ効率が低下する可能性があります。つまり、CPU を効率良く使用しバランス良く最適化されたアプリケーションのほうが、静的スケジューリングを使用するバランスの悪いアプリケーションよりも低速になることがあります。この場合、[HPC Performance Characterization (HPC パフォーマンス特性)] ビューの [Memory Bound (メモリー依存)] セクションを調査します。
注
このレシピの情報は、デベロッパー・フォーラム (英語) を参照してください。
関連情報
- OpenMP* コード解析 (英語)
- HPC パフォーマンス特性解析 (英語)
- 潜在的なゲイン
(https://software.intel.com/en-us/vtune-amplifier-help-openmp-potential-gain) - チュートリアル: MPI/OpenMP* ハイブリッド・アプリケーションの解析 (英語)
- 低いプロセッサー・コア利用率: OpenMP* シリアル時間
