
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Measuring Performance Impact of NUMA in Multi-Processor Systems」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2022
更新日: 2022 年 2 月 28 日
このレシピは、インテル® VTune™ プロファイラーのプラットフォーム・プロファイラー解析タイプを使用して、マルチプロセッサー・システムにおける NUMA (Non-Uniform Memory Access) のパフォーマンスへの影響を測定します。
コンテンツ・エキスパート: Jeffrey Reinemann、Asaf Yaffe
NUMA (Non-Uniform Memory Access) は、メモリーアクセス時間がメモリー位置からプロセッサーへの距離に依存するコンピューター・メモリー設計です。NUMA では、プロセッサー・コアはローカルメモリー (プロセッサーに接続されているメモリー) のほうがリモートメモリー (ほかのプロセッサーのローカルメモリーや複数のプロセッサー間で共有されるメモリー) よりも高速にアクセスできます。
以下は、2 つのプロセッサーで構成される NUMA システムの設計を図解したものです。
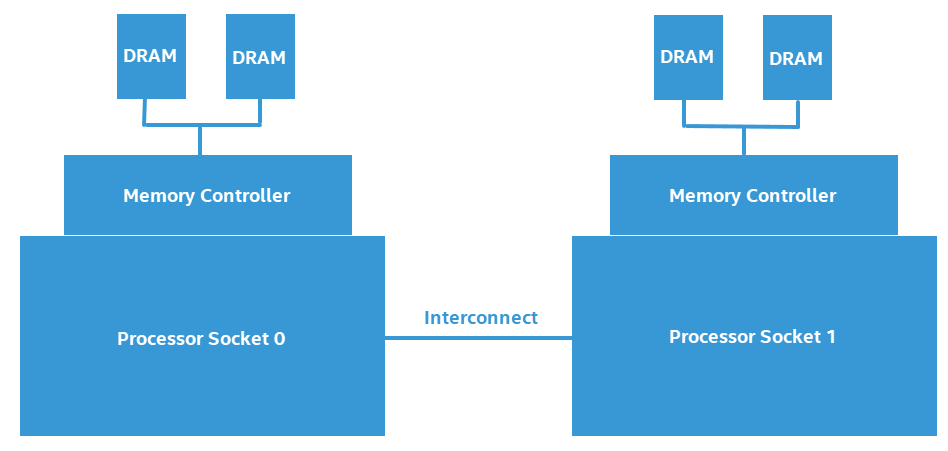
リモート (非ローカル) メモリーに頻繁にアクセスするソフトウェアは、主にローカルメモリーにアクセスするソフトウェアと比較すると、パフォーマンスが大幅に低下する可能性があります。このレシピでは、NUMA システムのパフォーマンス低下を測定します。
使用するもの
以下は、このシナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: このレシピで使用するサンプル・アプリケーションはダウンロードできません。
- ツール: インテル® VTune™ プロファイラー 2021.5.0 以降
プラットフォーム・プロファイラー解析を実行する
- プロジェクトを作成 (英語) します。
- インテル® VTune™ プロファイラーの [Welcome (ようこそ)] 画面で [Configure Analysis (解析の設定)] をクリックします。
- 解析ツリーで [Platform Analyses (プラットフォーム解析)] グループの [Platform Profiler (プラットフォーム・プロファイラー)] 解析タイプ (英語) を選択します。
- [WHAT (何を)] ペインでは、[Profile System (システムをプロファイル)] を選択します。必要に応じて、[Advanced (詳細)] セクションでデータ収集のサイズと時間の制限を設定します。
- [Start (開始)] ボタンをクリックして、解析を実行します。収集が完了する前であれば、いつでも [Stop (停止)] ボタンをクリックしてデータ収集を終了し、結果を確認できます。
データ収集が完了すると、インテル® VTune™ プロファイラーはデータをファイナライズして、結果を [Platform Profiler (プラットフォーム・プロファイラー)] タブに表示します。このタブの情報は、 3 つのセクションで構成されています。
- プラットフォーム図
- インタラクティブなタイムライン
- パフォーマンス・データ・グラフ
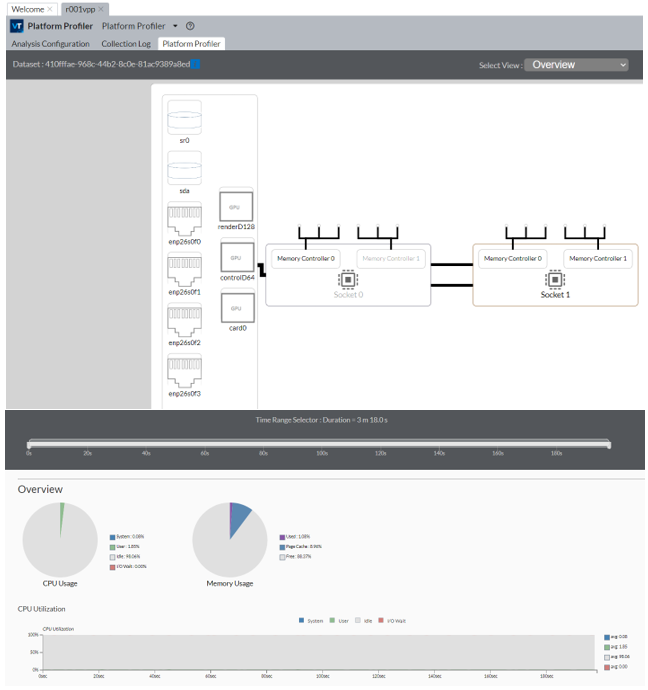
NUMA 問題を特定する
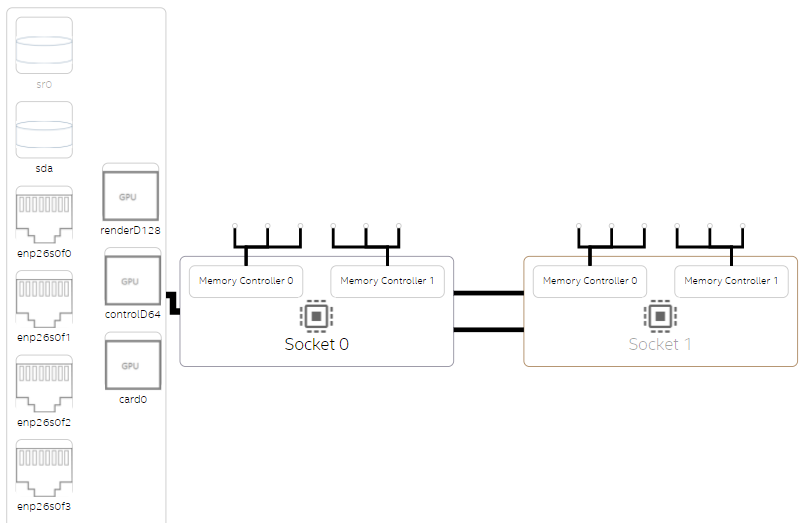
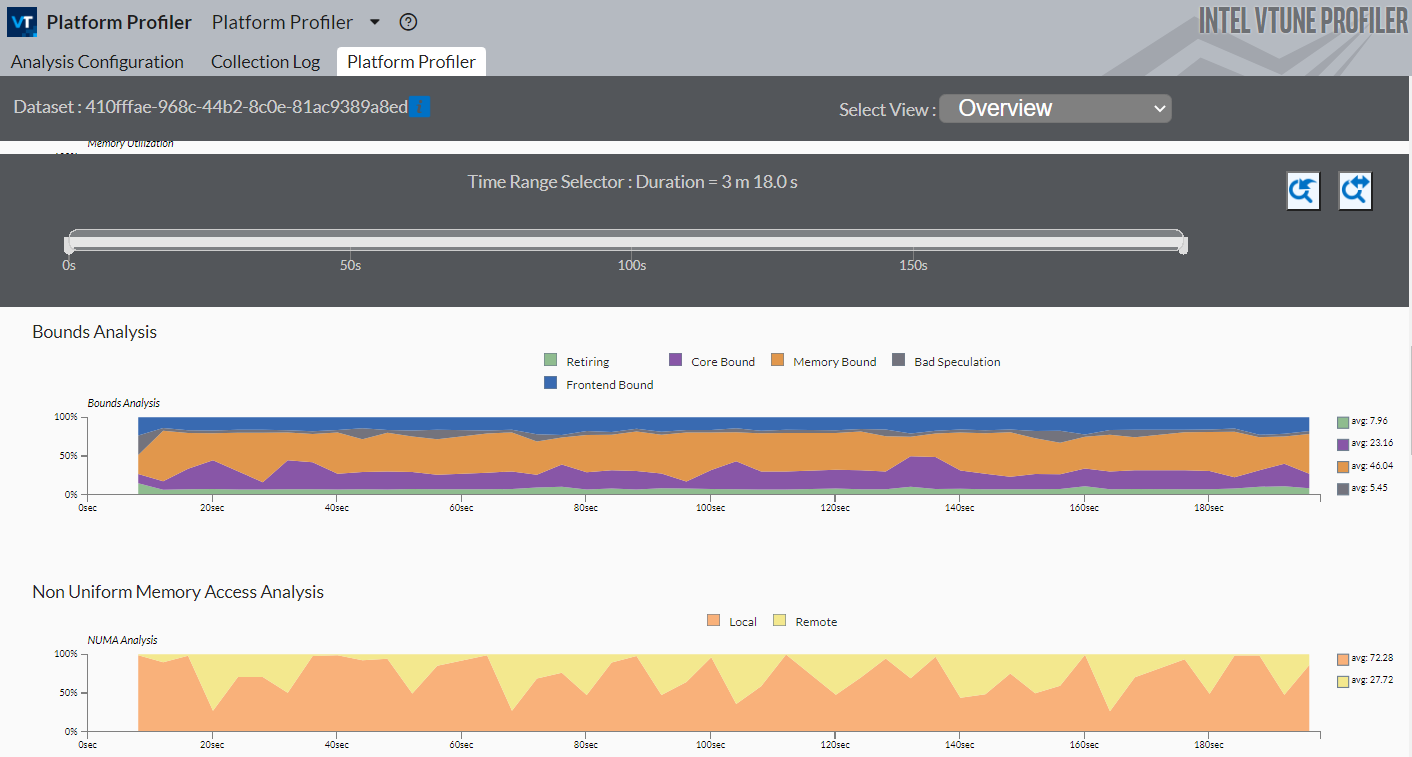
- [Select View (ビューの選択)] ドロップダウン・メニューから [Overview (概要)] を選択して、NUMA 問題の調査を開始します。システム構成の概要から、NUMA システムは通常、複数のプロセッサー・ソケットを持ち、それぞれにメモリー・コントローラーが搭載されていることが分かります。以下は、2 ソケットのシステムのプラットフォーム図の例です。
このサンプル・アプリケーションでは、パフォーマンスはほとんどメモリーアクセスによって制限されており、リモートメモリーを対象としたメモリーアクセスが多いことが分かります。
- [Non-Uniform Memory Access Analysis (NUMA 解析)] グラフで、経時的なローカルとリモートのメモリーアクセスを比較します。リモートアクセスの割合が高い場合、NUMA に関連するパフォーマンスの問題があることを示しています。
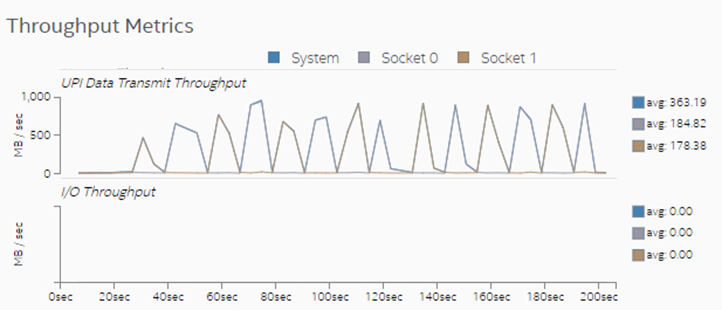
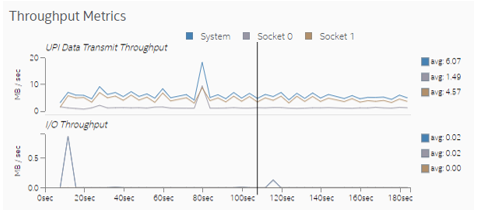
- [Throughput Metrics (スループット・メトリック)] セクションを確認します。このサンプル・アプリケーションでは、ソケット間 (UPI) 通信で頻繁にスパイクが発生しています。これらのスパイクはリモート・メモリー・アクセスに対応しています。
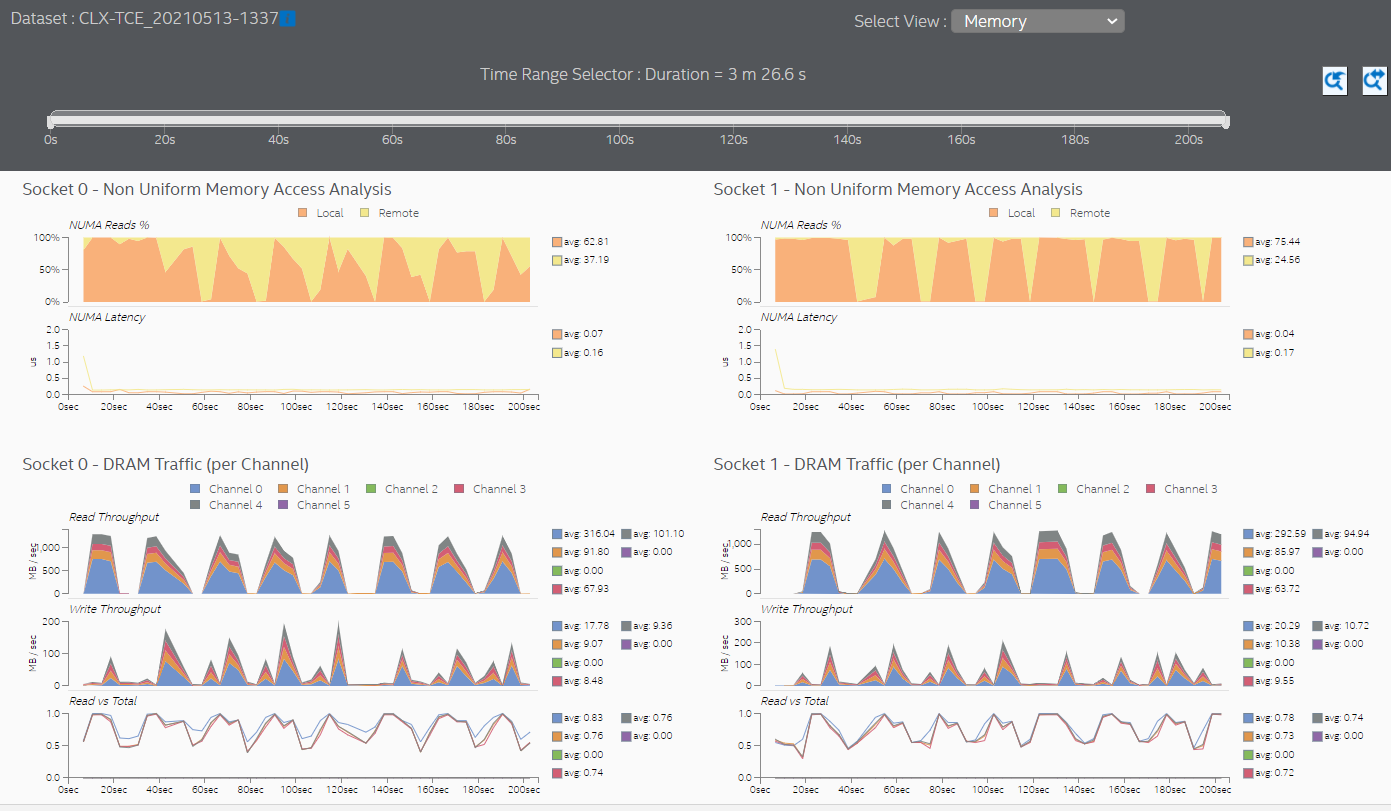
- [Memory (メモリー)] ビューに切り替えて、プロセッサー・ソケットごとのメモリーアクセスに関する詳細情報を確認します。このサンプル・アプリケーションでは、両方のソケットがリモート・メモリー・アクセスを行っています。
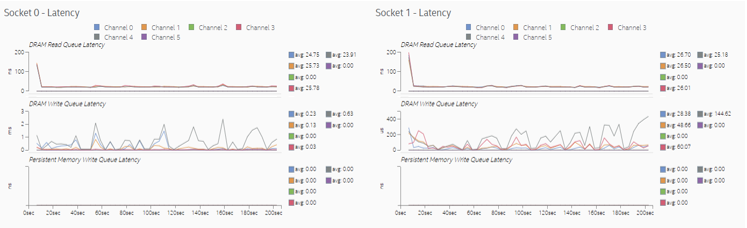
リモートメモリーにアクセスしたときに、メモリーアクセスのレイテンシーでスパイクが発生しています。これらのスパイクは、パフォーマンス向上の可能性を示しています。
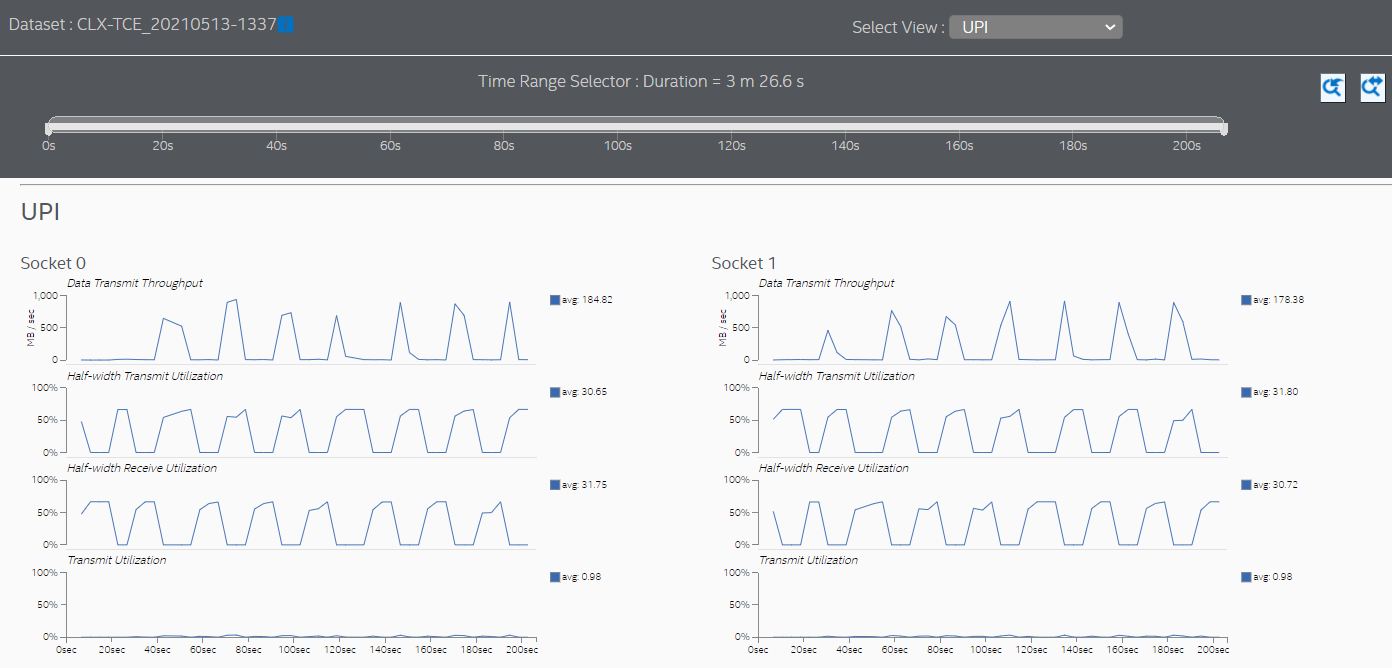
- [UPI] ビューに切り替えて、ソケットごとのソケット間通信を確認します。
スレッド CPU アフィニティーを設定して NUMA 問題を解決する
このレシピで使用するサンプル・アプリケーションは、ソフトウェア・スレッドを特定のソケットとコアに割り当て (ピン) ません。この割り当てがないため、オペレーティング・システムは、異なるソケットにあるプロセッサー・コアにスレッドを定期的にスケジュールすることになります。つまり、アプリケーションは「NUMA を意識」していません。この状態では、リモート・メモリー・アクセスが頻繁に発生し、その結果、ソケット間通信が増加し、メモリー・アクセス・レイテンシーが高くなります。
リモート・メモリー・アクセスやソケット間通信を減らす方法の 1 つは、同じメモリー範囲で実行するプロセスのアフィニティーを、同じソケット内のプロセッサー・コアに割り当てることです。この割り当てにより、メモリーアクセスの局所性を維持できます。オペレーティング・システムのプログラミング・ガイドでは、NUMA システムでソケット間通信を削減する別の方法を推奨している場合があります。
NUMA の最適化を確認する
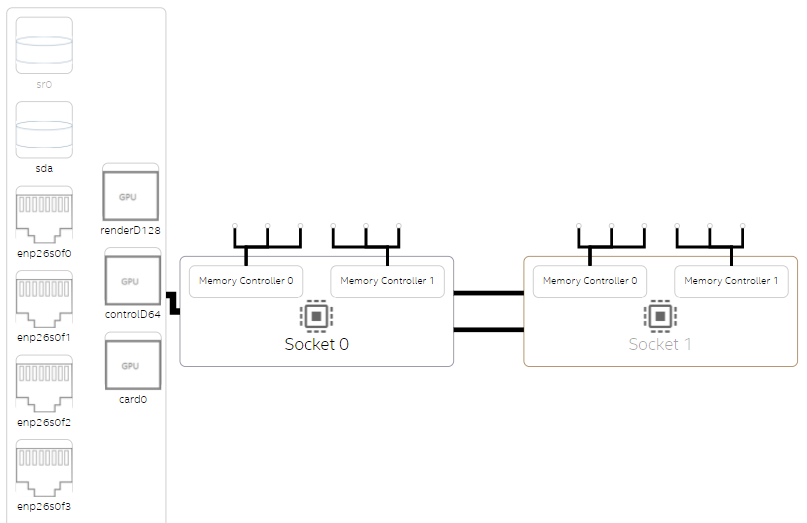
NUMA の最適化が完了したら、プラットフォーム・プロファイラー解析を再度実行します。次のグラフは、ソケット 0 のコアにアフィニティーを割り当てた後のメモリーアクセスを示しています。
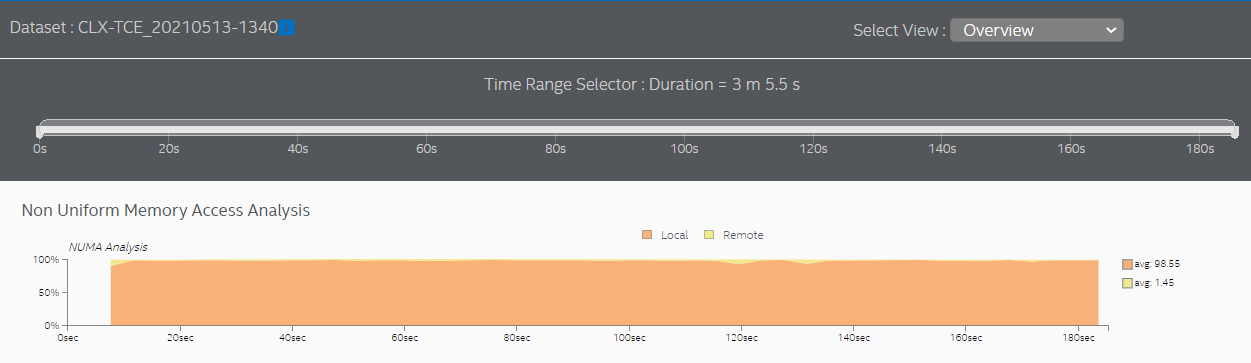
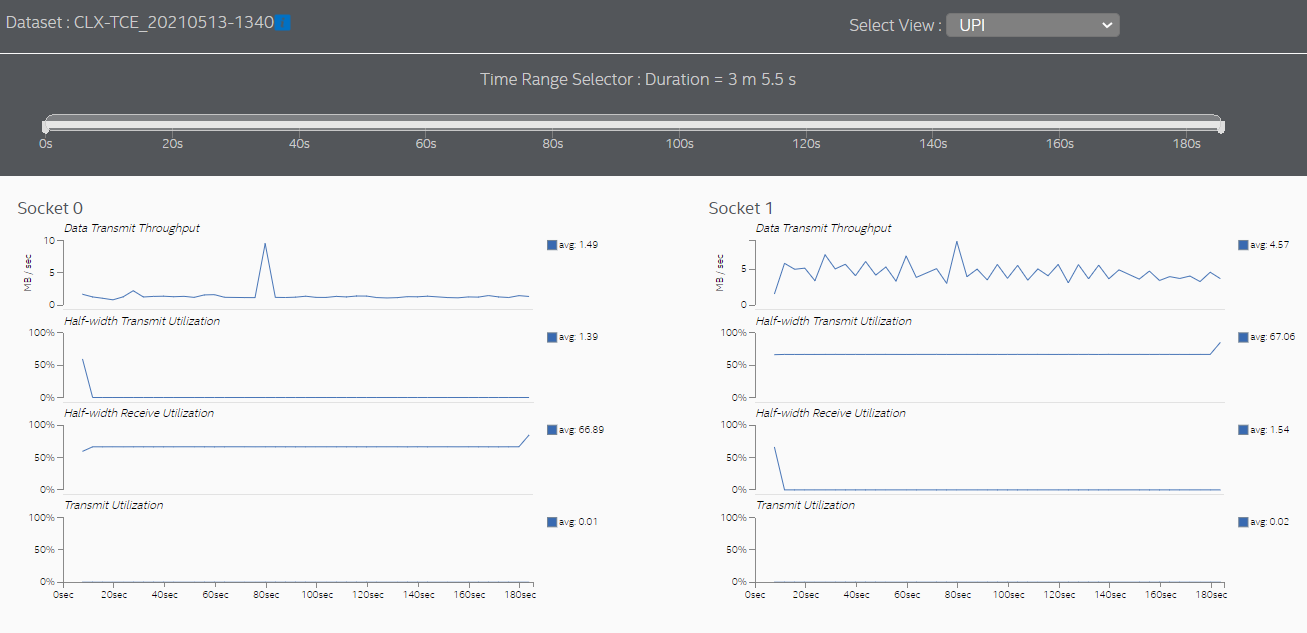
ここで使用したサンプルでは、ほぼすべてのメモリーアクセスがローカルアクセスになりました。ソケット間通信のスパイクはほとんどなくなりました。
[Memory (メモリー)] ビューは、両方のソケットがほとんどローカルメモリーにアクセスしていることを示しています。
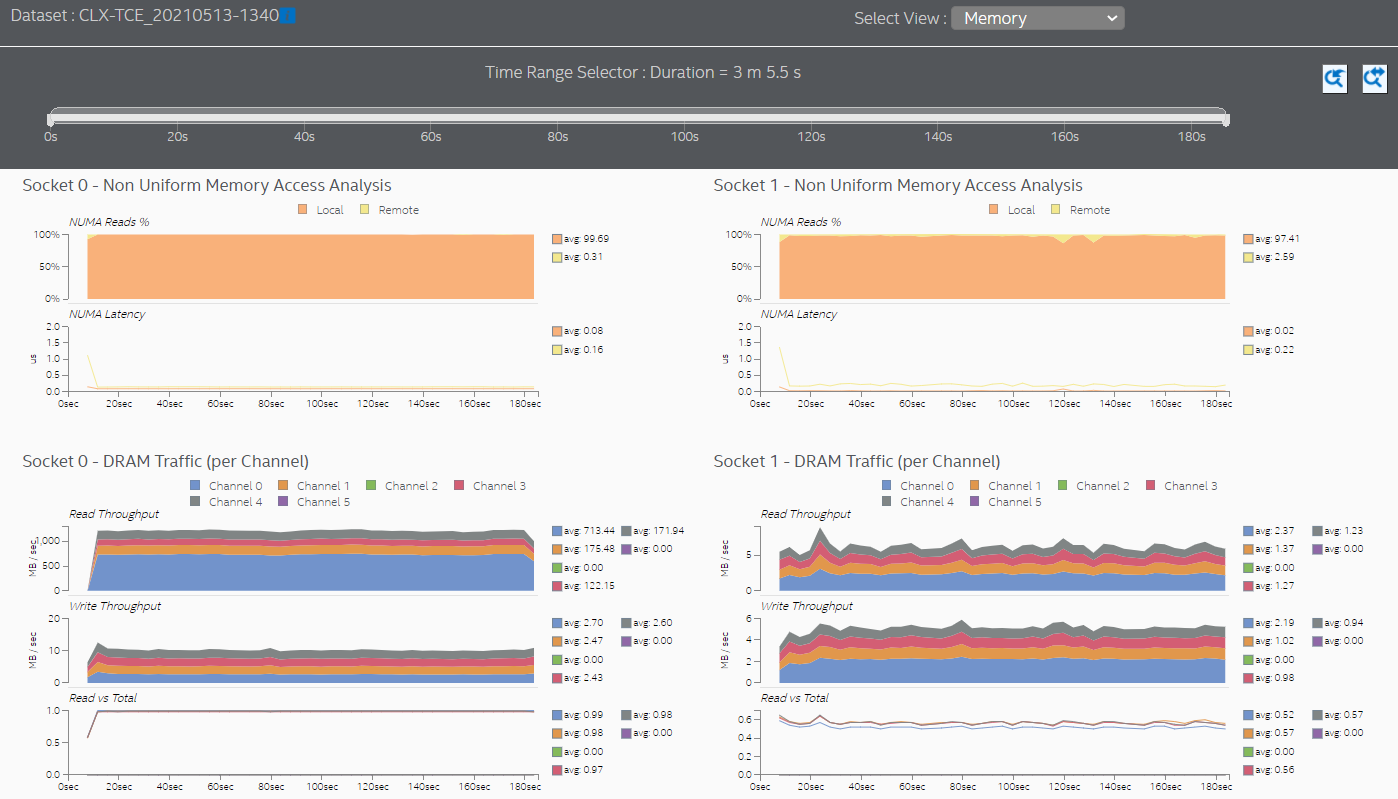
スレッド CPU アフィニティーの設定と最適化により、より多くのメモリー要求がローカルメモリーで満たされるようになり、メモリーアクセスのレイテンシーが大幅に短縮されました。[Memory (メモリー)] ビューでは、[DRAM Write Queue Latency (DRAM 書き込みキュー・レイテンシー)] グラフの単位がマイクロ秒からナノ秒に変わっています。
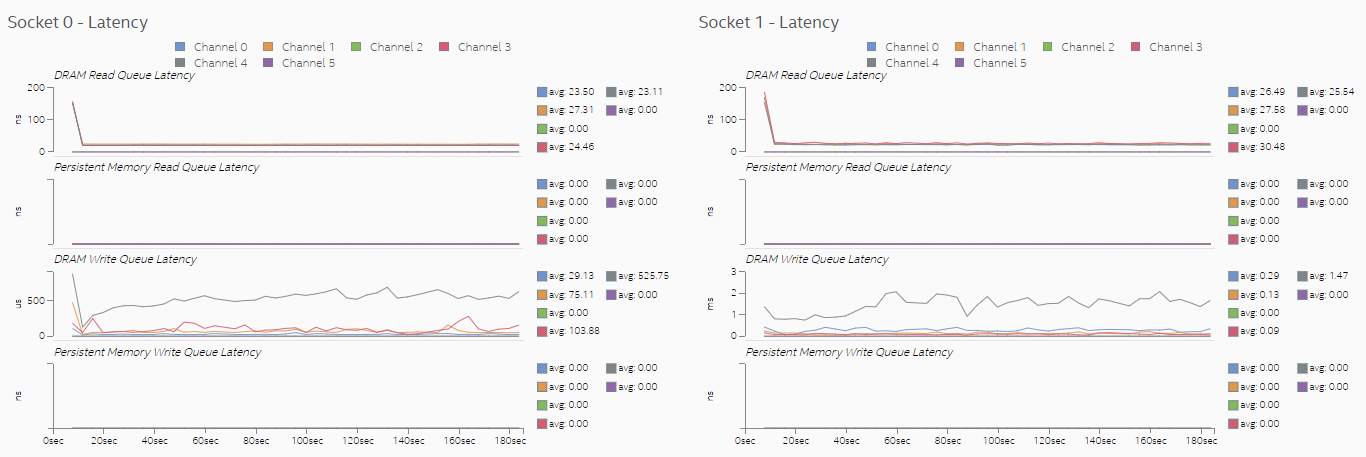
また、[UPI] ビューではソケット間通信が大幅に減少しています。
注
このレシピの情報は、アナライザー・デベロッパー・フォーラム (英語) を参照してください。
関連情報
プラットフォーム・プロファイラー解析 (英語)
プラットフォーム・プロファイラー・ビュー (英語)
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
