この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Instruction Cache Misses」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、インテル® VTune™ Amplifier の全般解析を使用してフロントエンド依存のアプリケーションをプロファイルし、PGO オプションを指定して ICache ミスを減らします。
コンテンツ・エキスパート: Dmitry Ryabtsev (英語)
注
全般解析は、インテル® VTune™ Amplifier 2019 でマイクロアーキテクチャー全般解析に改名されました。
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: sqlite データベース・ベースのテストサンプル。このアプリケーションはデモ用であり、ダウンロードすることはできません。
- ツール:
- インテル® VTune™ Amplifier 2018: 全般解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- インテル® C++ コンパイラー
- インテル® VTune™ Amplifier 2018: 全般解析
- オペレーティング・システム: Microsoft* Windows* 7
- CPU: インテル® プロセッサー (開発コード名 Skylake)
全般解析を実行する
サンプル・アプリケーションの潜在的なパフォーマンス・ボトルネックを理解するため、まず、インテル® VTune™ Amplifier の全般解析を実行します。
- ツールバーの
 [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: sqlite) を指定します。
[New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: sqlite) を指定します。
- [Analysis Target (解析ターゲット)] ウィンドウで、ホストベースの解析として [local host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、右ペインで解析するアプリケーションを指定します。
- 右の [Choose Analysis (解析の選択)] ボタンをクリックし、[Microarchitecture Analysis (マイクロアーキテクチャー解析)] > [General Exploration (全般)] を選択して、[Start (開始)] をクリックします。
インテル® VTune™ Amplifier は、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
ハードウェアの hotspot を特定する
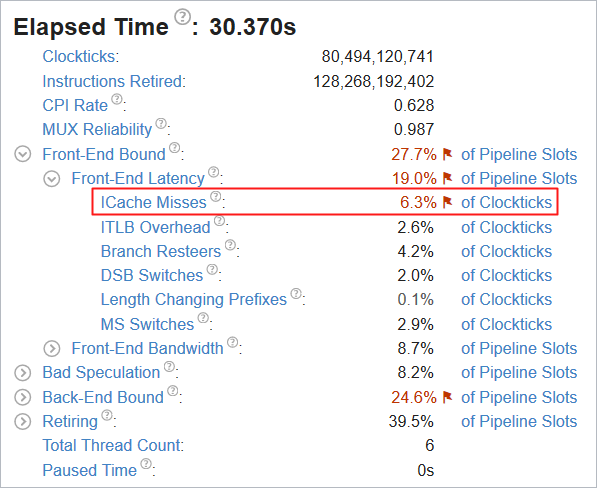
全般解析を実行すると、コードの主要なボトルネックを確認できます。ハードウェア・メトリックごとのアプリケーション・レベルの統計が表示される [Summary (サマリー)] ビューから解析を始めます。フラグの付いているパフォーマンス問題に注目します。
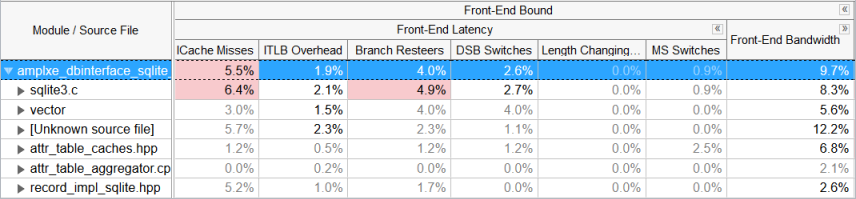
サンプル・アプリケーションは、フロントエンド依存 (パイプライン・スロットの 29.3%) で、命令キャッシュミスが主要なボトルネック (クロック数の 7.1%) です。
[Bottom-up (ボトムアップ)] タブに切り替えてコードの問題を調べます。[Grouping (グループ)] ツールバーの横の ![]() [Customize Grouping (グループのカスタマイズ)] ボタンをクリックして、新しいカスタムグループ [Module/Source File (モジュール/ソースファイル)] を作成します。
[Customize Grouping (グループのカスタマイズ)] ボタンをクリックして、新しいカスタムグループ [Module/Source File (モジュール/ソースファイル)] を作成します。
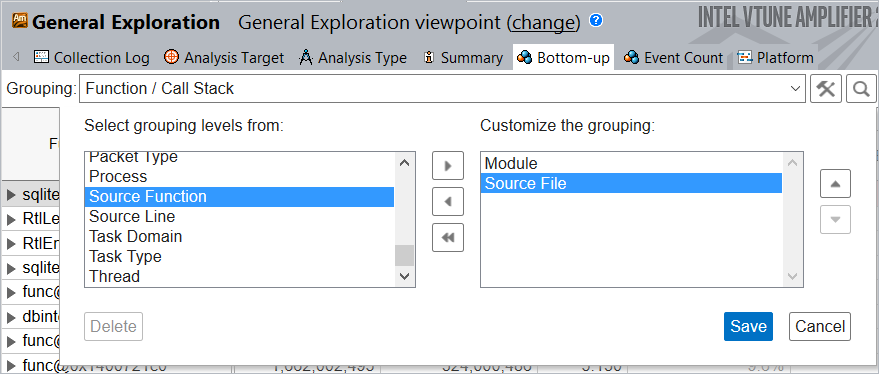
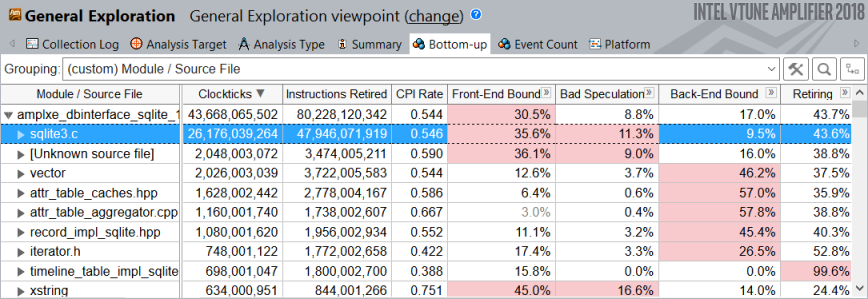
新しいグループを収集した結果に適用すると、sqlite3.c ファイルがほとんどの CPU サイクルを費やしているメインの hotspot であると表示されます。
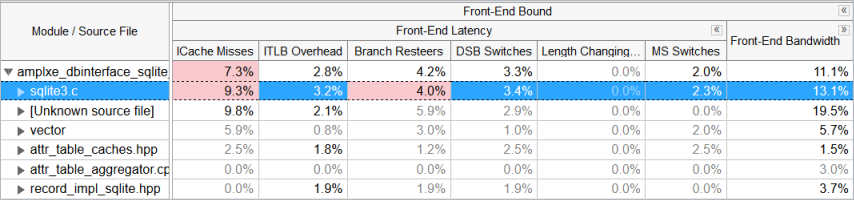
ICache Misses (ICache ミス) メトリックに移動すると、sqlite3.c ファイルの値も高いことが分かります。
PGO オプションを指定してコードを再コンパイルする
インテル® C++ コンパイラーを使用して、プロファイルに基づく最適化 (PGO) を sqlite ライブラリーに適用します。
- /Qprof-gen オプションを指定してコードを再コンパイルします。
- ベンチマークを実行します。
- /Qprof-use オプションを指定してコードを再コンパイルします。
詳細は、「プロファイルに基づく最適化の概要」 (https://software.intel.com/en-us/node/522721) を参照してください。
最適化を確認する
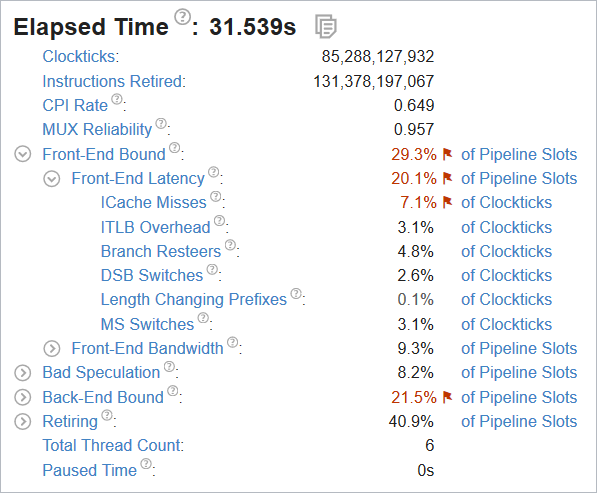
最適化したコードで全般解析を再度実行します。新しい結果では、Elapsed Time (経過時間) は 30.3 秒になり、オリジナルの 31.5 秒からパフォーマンスが約 4% 向上しました。
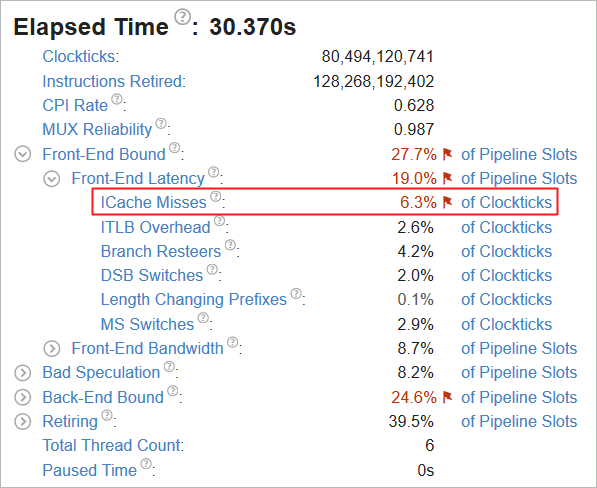
sqlite ライブラリーで ICache ミスによりストールしていたクロック数は 9.3% から 6.4% に減りました。