この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Inefficient TCP/IP Synchronization」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、タスク収集を有効にしてインテル® VTune™ Amplifier のロックと待機解析を実行し、コードの非効率な TCP/IP 同期を特定する方法を説明します。
コンテンツ・エキスパート: Kirill Uhanov (英語)
- 使用するもの
- 手順:
注
ロックと待機解析は、インテル® VTune™ Amplifier 2019 でスレッド解析に改名されました。
使用するもの
- アプリケーション: TCP ソケット通信を使用するクライアント/サーバー・アプリケーション
- パフォーマンス解析ツール: インテル® VTune™ Amplifier 2018: ロックと待機解析
- サーバー・オペレーティング・システム: Microsoft* Windows Server* 2016
- クライアント・オペレーティング・システム: Linux*
ロックと待機解析を実行する
クライアント・アプリケーションのウォームアップに時間がかかる場合、ロックと待機解析を実行して、同期オブジェクトごとの待機統計を調査することを検討してください。
- ツールバーの [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクト (例: tcpip_delays) を作成します。
- [Analysis Target (解析ターゲット)] ウィンドウで、ホストベースの解析として [local host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、右ペインで解析するアプリケーションを指定します。
- 右の [Choose Analysis (解析の選択)] ボタンをクリックし、[Algorithm Analysis (アルゴリズム解析)] > [Locks and Waits (ロックと待機)] を選択します。
- [Start (開始)] をクリックします。
インテル® VTune™ Amplifier は、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
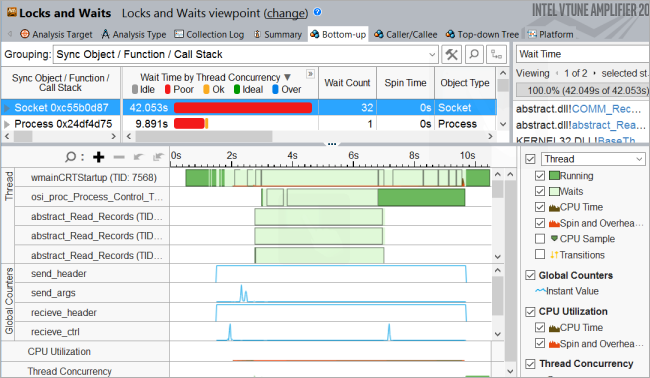
タイムラインで同期の遅延を見つける
収集結果を開いて [Bottom-up (ボトムアップ)] タブをクリックし、同期オブジェクトごとのパフォーマンスの詳細を表示します。[Timeline (タイムライン)] ペインでは、テスト・アプリケーションが実行を開始すると、複数の同期の遅延が表示されます。これらの起動時の遅延を引き起こす同期オブジェクトを特定するには、ドラッグアンドドロップで最初の 9 秒間を選択し、コンテキスト・メニューから [Filter In by Selection (選択してフィルターイン)] を使用します。
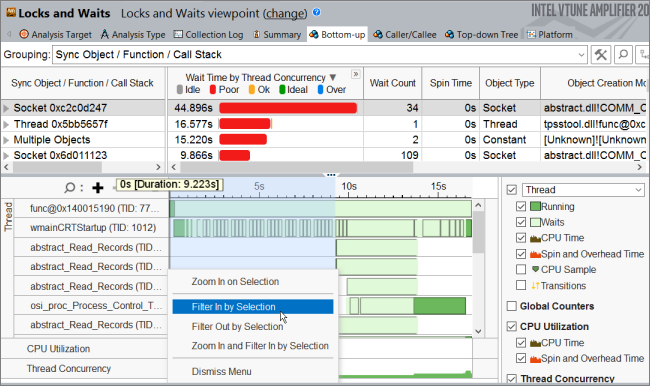
フィルターバーの [Process (プロセス)] メニューで、ホストの通信プロセス別にフィルターインします。
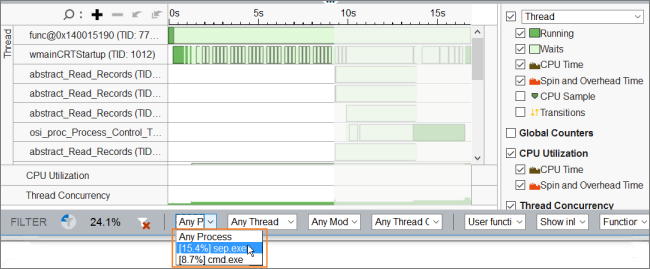
そして、選択した期間内で待機時間が最も大きい Socket 同期オブジェクトを選択し、[Filter In by Selection (選択してフィルターイン)] メニューを使用してデータをフィルターインします。
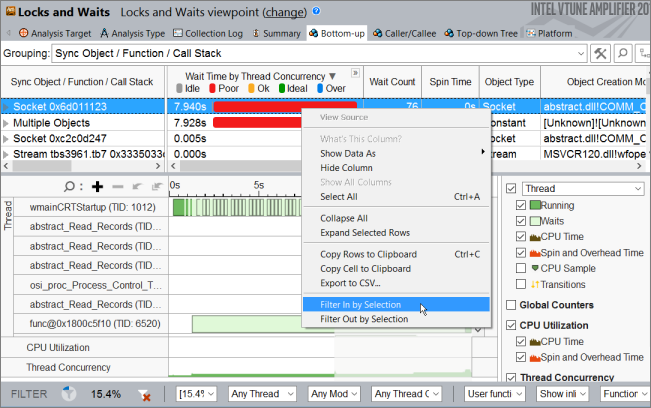
Socket 同期オブジェクトの待機時間を調査するには、タイムラインに注目します。
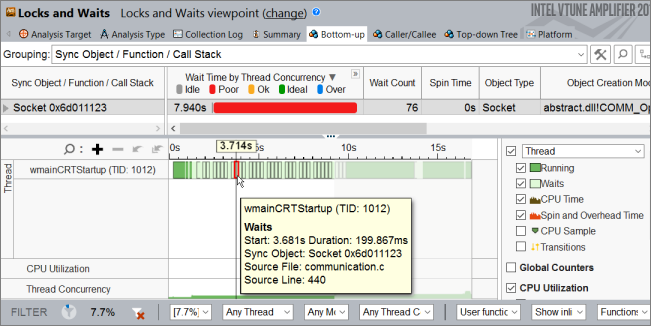
![]() [Zoom In (ズームイン)] ボタンをクリックすると、高速と低速の 2 種類のソケット待機が表示されます。低速の (長い) ソケット待機は約 200 ミリ秒で、高速の (短い) ソケット待機は約 937 マイクロ秒です。
[Zoom In (ズームイン)] ボタンをクリックすると、高速と低速の 2 種類のソケット待機が表示されます。低速の (長い) ソケット待機は約 200 ミリ秒で、高速の (短い) ソケット待機は約 937 マイクロ秒です。
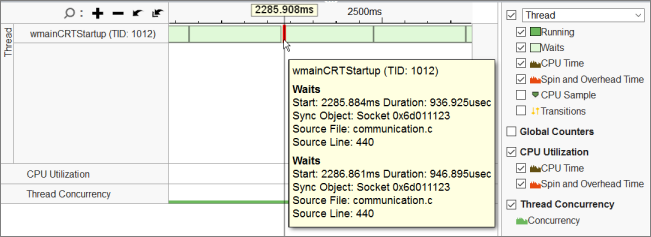
高速な待機と低速な待機の原因を理解するには、ITT カウンターですべての send/receive 呼び出しをラップして、send/receive バイトを計算します。
ITT API カウンターを使用して send/receive バッファーサイズを検出する
インストルメンテーションとトレース・テクノロジー (ITT) API を使用して send/receive 呼び出しをトレースするには、次の操作を行います。
- API ヘッダーとライブラリーにアクセスできるようにシステムを設定 (英語) します。
- ITT API ヘッダーをソースファイルにインクルードして、<vtune-install-dir>\[lib64 or lib32]\libittnotify.lib スタティック・ライブラリーをアプリケーションにリンクします。
- ITT カウンターを使用して send/receive 呼び出しをラップします。
#include <ittnotify.h>
__itt_domain* g_domain =__itt_domain_createA("com.intel.vtune.tests.userapi_counters");
__itt_counter g_sendCounter = __itt_counter_create_typedA("send_header", g_domain->nameA, __itt_metadata_s32);
__itt_counter g_sendCounterArgs = __itt_counter_create_typedA("send_args", g_domain->nameA, __itt_metadata_s32);
__itt_counter g_recieveCounter = __itt_counter_create_typedA("recieve_header", g_domain->nameA, __itt_metadata_s32);
__itt_counter g_recieveCounterCtrl = __itt_counter_create_typedA("recieve_ctrl", g_domain->nameA, __itt_metadata_s32);
__itt_counter g_incDecCounter = __itt_counter_createA("inc_dec_counter", g_domain->nameA);
.....
sent_bytes = send(...);
__itt_counter_set_value(g_sendCounter, &sent_bytes);
.....
sent_bytes = send(...);
__itt_counter_set_value(g_sendCounterArgs, &sent_bytes);
.....
while(data_transferred < header_size)) {
if ((data_size = recv(...) < 0) {
.....
}
__itt_counter_set_value(g_recieveCounter, &data_transferred);
.....
while(data_transferred < data_size) {
if ((data_size = recv(...) < 0) {
....
}
}
}
__itt_counter_set_value(g_recieveCounterCtrl, &data_transferred);
アプリケーションを再コンパイルして、[Analyze user tasks, events, and counters (ユーザータスク、イベント、およびカウンターを解析)] オプションを有効にしてロックと待機解析を再度実行します。
非効率な TCP/IP 同期の原因を特定する
新しい結果では、[Timeline (タイムライン)] ペインに ITT API を介して収集された send/receive 呼び出しの分布を表示する [Global Counters (グローバルカウンター)] が追加されます。マウスでスレッドの待機やカウンター値をポイントすると、対応するカウンターのインスタント値が表示されます。この値は、長い (低速な) 待機では小さくなります。
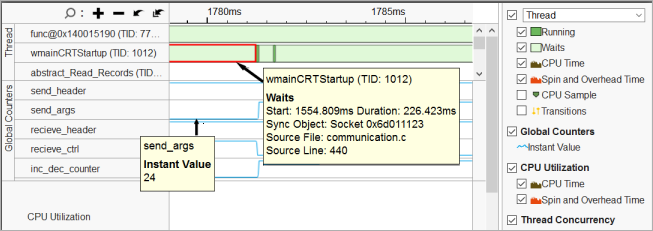
そして、短い (高速な) 待機では大きくなります。
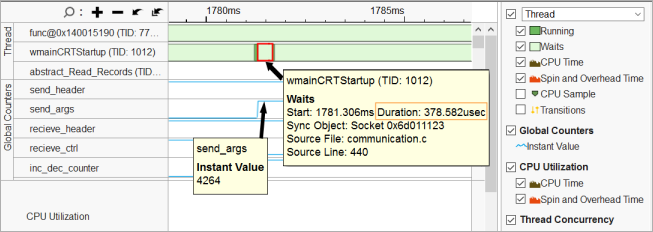
リモートターゲットの通信待機のプロファイルでは、対称的な結果となります。小さなサイズのバッファーでは待機時間が長くなり、十分なサイズのバッファーでは待機時間が短くなります。
このレシピでは、通信コマンドチャネルが分ります。ほとんどのコマンドはサイズが小さく、結果的に長い待機時間が発生します。
問題の原因は、小さなバッファーの待機時間を増やす tcp ack 遅延メカニズムにあります。
サーバー側の入力 (setsockopt (…, SO_RCVBUF, ..,)) バッファーを小さくすると、起動時間が 5 倍以上 (数十秒から数秒へ) 高速になります。