
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Inefficient Synchronization」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、スタック収集を有効にしてインテル® VTune™ Amplifier の高度な hotspot 解析を実行し、コードの非効率な同期を特定する方法を説明します。
注
高度な hotspot 解析は、インテル® VTune™ Amplifier 2019 で汎用の hotspot 解析に統合されました。ハードウェア・イベントベース・サンプリング収集モードで利用できます。
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: sample.exe (OpenMP* ランタイムを使用)。このアプリケーションはデモ用であり、ダウンロードすることはできません。
- パフォーマンス解析ツール: インテル® VTune™ Amplifier 2017: 高度な hotspot 解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- オペレーティング・システム: Microsoft* Windows* 8
- CPU: インテル® プロセッサー (開発コード名 Skylake)
スタック収集を有効にして高度な hotspot 解析を実行する
インテル® VTune™ Amplifier を起動して解析するプロジェクトを設定します。
- ツールバーの
 [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: sqlite) を指定します。
[New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: sqlite) を指定します。
- [Analysis Target (解析ターゲット)] ウィンドウで、ホストベースの解析として [local host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、右ペインで解析するアプリケーションを指定します。
- 右の [Choose Analysis (解析の選択)] ボタンをクリックし、[Algorithm Analysis (アルゴリズム解析)] > [Advanced Hotspots (高度な hotspot)] を選択して、[Hotspots and stacks (hotspot とスタック)] オプションを選択します。
- [Start (開始)] をクリックします。
インテル® VTune™ Amplifier は、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
タイムラインの同期を見つける
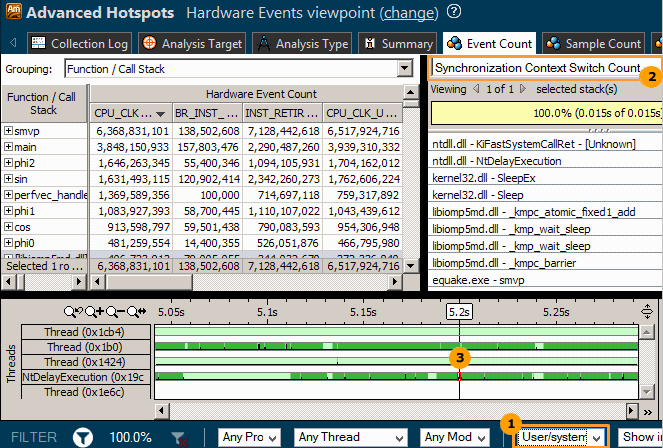
[Hardware Event (ハードウェア・イベント)] ビューポイントで、解析中に収集されたデータを開きます。
| [User/system functions (ユーザー/システム関数)] コールスタック・モードを選択して、[Call Stack (コールスタック)] ペインにユーザー関数とシステム関数の両方を表示します。 | |
| [Call Stack (コールスタック)] ペインで、ドロップダウン・メニューから [Synchronization Context Switch Count (同期コンテキスト・スイッチ・カウント)] タイプを選択して、[Timeline (タイムライン)] ペインで選択した同期コンテキスト・スイッチのコールスタックを確認します。 | |
| タイムラインの頻繁な同期を見つけて、コンテキスト・スイッチの上にカーソルを移動します。ツールヒントに詳細が表示されます。例えば、上記の高度な hotspot 解析の結果では、NtDelayExecution スレッドに同期が原因の大量のコンテキスト・スイッチが含まれています。タイムラインのコンテキスト・スイッチを選択すると、[Call Stack (コールスタック)] ペインが更新され、スレッド実行が中断された呼び出しシーケンスが表示されます。 |
平均待機メトリックを解析する
(change) リンクをクリックして [Hotspots (hotspot)] ビューポイントを開きます。
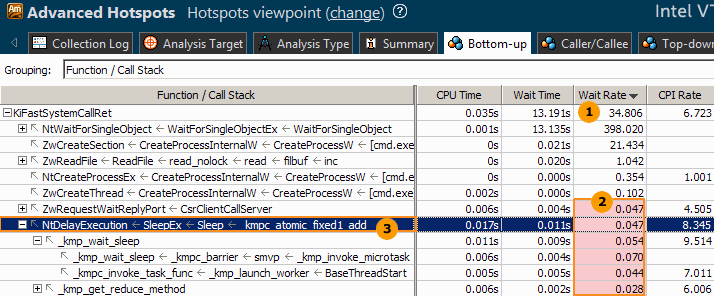
| 同期コンテキスト・スイッチあたりの平均待機時間 (秒単位) である、[Wait Rate (待機レート)] メトリックデータを解析します。このメトリックは、非効率で頻繁な同期および消費電力問題を特定するのに役立ちます。 | |
| インテル® VTune™ プロファイラーは、低い待機レートメトリック値 (1 ミリ秒未満) をパフォーマンス問題として判断し、ピンクでハイライトします。これらの値は、スレッド間の競合およびシステム API の非効率な使用を示すことがあるためです。 | |
| 待機時間が短く CPU 時間が長い (すべてのシステムコール時間の約半分の) 同期スタックを特定し、ダブルクリックして hotspot 関数のソースコードを調べます。 |
同期コンテキスト・スイッチを解析する
(change) リンクをクリックして [Hardware Event (ハードウェア・イベント)] ビューポイントを開きます。デフォルトでは、[Event Count (イベントカウント)] グリッドはクロック数イベントでソートされます。最も CPU 時間 (クロック数) がかかっていて、最も頻繁に同期を行っているホットな関数を特定します。
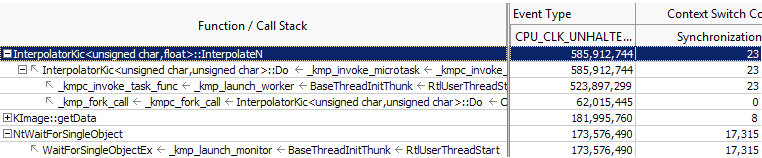
このサンプル OpenMP* アプリケーションでは、インテル® VTune™ Amplifier は InterpolateN 関数を OpenMP* 領域から呼び出された計算 hotspot として表示しています。OpenMP* ランタイム内部の WaitForSingleObject で競合が発生し、約 30% のパフォーマンス損失 (待機関数のクロック数/hotspot 関数のクロック数) が発生していることも分かります。
InterpolateN 関数をダブルクリックしてソースコードを表示し、非効率な同期の原因を特定します。
for(i = 0; i < block_no; i++)
{
#pragma omp parallel for
for(j = 0; j < lines_in_block; j++)
{
/// do processing
} /// implicit barrier causing contention and overhead
}
サンプル・アプリケーションのコード解析により、ブロック行でピクチャーを処理して各ブロックを個別に並列化するために過度の OpenMP* バリアが追加されていることが判明しました。この問題を解決するには、nowait 節を使用するか、ピクチャー全体に parallel_for を適用して、動的ワーク・スケジューリングを使用します。
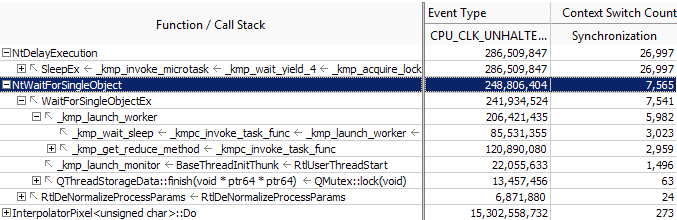
最適化した結果では、Sleep() の競合の相対的なコストが低くなりました (26,997)。
1 つの parallel_for と動的ワーク・スケジューリングを WaitForSingleObject 関数に使用することで、競合とパフォーマンスへの悪影響を 1% 未満に減らすことができました。
2 つ目の最適化した結果では、Sleep() 関数でも多くの競合が発生していることが分かります (同期コンテキスト・スイッチ・メトリックが 26,997)。しかし、その実行時間を確認すると、実行時間は最上位の hotspot (表示されていません) の 2% 以内であり、それほど重要ではありません。ただし、多くのプロセッサー上でアプリケーションを実行した場合、この関数が問題になる可能性があります。
注
最初の (最適化前の) サンプルデータ収集セッションは一定の時間間隔で行われたものです。最適化バージョンでは、アプリケーションが制限なしで実行されています。
関連情報
- スタックを含むハードウェア・イベントベースのサンプリング収集
(https://software.intel.com/en-us/vtune-amplifier-help-hardware-event-based-sampling-collection-with-stacks)
