
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Effective Utilization of Intel® Data Direct I/O Technology」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2020 (最終更新日: 2021 年 3 月 26 日)
このレシピは、インテル® VTune™ プロファイラーを使用して、インテル® Xeon® プロセッサーのハードウェア機能であるインテル® データ・ダイレクト I/O テクノロジー (インテル® DDIO) の利用効率を明らかにする方法を示します。
コンテンツ・エキスパート: Ilia Kurakin (英語)、Perry Taylor (英語)
従来、インバウンドの PCIe* トランザクションはメインメモリーをターゲットにしており、I/O デバイスから消費コアへのデータ移動には複数の DRAM アクセスを必要とします。ソフトウェア・データ・プレーンのような I/O を多用するユースケースでは、この方式は適用できません。
例えば、100G ビットの NIC が 64B のパケットと 20B のイーサネット・オーバーヘッドでフル稼働している場合、新しいパケットは平均して 6.72 ナノ秒ごとに到着します。パケットパス上のいずれかのコンポーネントが、このわずかな時間を上回って個々のパケットを処理すると、パケットロスが発生します。3GHz で動作するコアの場合、6.72 ナノ秒は 20 クロックサイクルにしかなりませんが、DRAM のレイテンシーは平均して 5 ~ 10 倍になります。これは従来の DMA アプローチの主なボトルネックとなっています。
インテル® Xeon® プロセッサーのハードウェア機能であるインテル® DDIO テクノロジー (英語) は、PCIe* デバイスが L3 キャッシュ (LLC-ラストレベルキャッシュ) との間で直接リード/ライト操作を行うことにより、このボトルネックを解消します。これにより、受信データをできるだけコアの近くに配置できます。インテル® DDIO テクノロジーを適切に活用することで、L3 キャッシュのみでコアと I/O デバイス間の相互作用に対応して、DRAM へのアクセスを完全に排除することができ、以下の利点が得られます。
- 高いスループットを可能にする、低レイテンシーのインバウンド・リード/ライト。
- DRAM 帯域幅と消費電力の軽減。
インテル® DDIO は、常に有効でソフトウェアに対して透過的なハードウェア機能ですが、最適なパフォーマンスが得られない場合があります。
インテル® DDIO の利用率を最適化する主なソフトウェア・チューニング手法は 2 つあります。
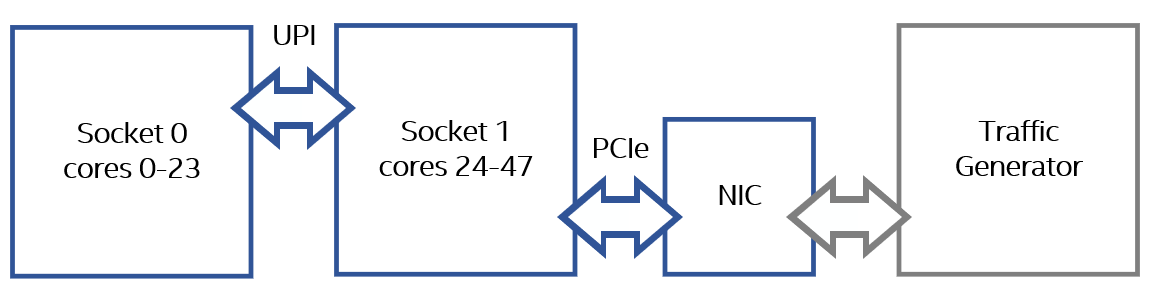
- トポロジー設定: 複数のソケットを持つシステムでは、I/O デバイス、I/O デバイスと相互作用するコア、およびメモリーが同じ NUMA モードであることが重要です。
- L3 キャッシュ管理: 高度なチューニングは、必要なデータを適切なタイミングで L3 キャッシュに保持することで、L3 キャッシュの使用を最適化します。
このレシピは、インテル® VTune™ プロファイラーの入力および出力解析を使用して、インテル® DDIO テクノロジーの非効率な利用を検出する方法を紹介します。
手順:
使用するもの
- システム: 2 ソケットの第 2 世代インテル® Xeon® スケーラブル・プロセッサー・ベースのシステム。
- アプリケーション: DPDK testpmd (英語) アプリケーション。シングルコアで動作し、ソケット 1 に装着された 40G ネットワーク・インターフェイス・カードの 1 ポートを使ってパケット転送を行うように構成されています。
- パフォーマンス解析ツール: インテル® VTune™ プロファイラー 2020 Update 2: 入力および出力解析
https://software.intel.com/content/www/us/en/develop/documentation/vtune-help/top/analyze-performance/disk-input-and-output-analysis.html。注
- バージョン 2020 から、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。
- インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのほとんどのレシピは、異なるバージョンのインテル® VTune™ プロファイラーにも適用できます。バージョンにより、わずかな調整が必要になる場合があります。
- 最新バージョンのインテル® VTune™ プロファイラーは以下から入手できます。
アーキテクチャーを理解する
インテル® Xeon® スケーラブル・プロセッサー (英語) では、L3 キャッシュは 1 つのソケット内のすべてのコアとすべてのインテグレーテッド I/O コントローラー (IIO) (英語) で共有されるリソースです。L3 キャッシュとコア間のデータ転送は、キャッシュライン単位 (64B) で行われます。PCIe* デバイスがシステムメモリーに要求を送ると、IIO はこの要求を 1 つまたは複数のキャッシュライン要求に変換し、ローカルソケット上の L3 キャッシュに発行します。ローカル L3 キャッシュへの要求は、次の方法で行うことができます。
- インバウンド PCIe* ライト要求
- インバウンド PCIe* ライト L3 ヒット — 理想的なシナリオ — ライト要求の対象となるアドレスが、すでにローカルの L3 キャッシュにある場合に発生します。L3 のキャッシュラインに新しいデータが上書きされます。
- インバウンド PCIe* ライト L3 ミス — 理想的ではないシナリオ — ライト要求の対象となるアドレスがローカルの L3 キャッシュにない場合に発生します。この場合、まず I/O データ専用の L3 ウェイからキャッシュラインを退避させます。退避したラインがダーティな状態の場合、DRAM へのライトバックが発生します。そして、退避したラインの代りに、新しいキャッシュラインが割り当てられます。対象となるキャッシュラインがリモートにキャッシュされている場合、コヒーレンシーのルールを適用して、キャッシュラインの割り当てを完了するため、インテル® ウルトラ・パス・インターコネクト (インテル® UPI) を介したクロスソケット・アクセスが必要になります。最後に、キャッシュラインが新しいデータで更新されます。
- インバウンド PCIe* リード要求
- インバウンド PCIe* リード L3 ヒット — 理想的なシナリオ — リード要求の対象となるアドレスがローカルの L3 キャッシュにある場合に発生します。データが読み取られ、PCIe* デバイスに送信されます。
- インバウンド PCIe* リード L3 ミス — 理想的ではないシナリオ — リード要求の対象となるアドレスがローカル L3 キャッシュにない場合に発生します。この場合、データはローカル DRAM またはリモートソケットのメモリー・サブシステムから読み取られます。ローカル L3 割り当ては行われません。
第 1 世代および第 2 世代インテル® Xeon® スケーラブル・プロセッサーの場合、インテル® VTune™ プロファイラーの入力および出力解析では、インバウンドの PCIe* リードおよびライトの L3 ヒット/ミスメトリックや平均レイテンシーが提供され、PCIe* デバイスグループごとにデータの内訳が示されます。これらのグループは、IIO コントローラーとメッシュ間のインターフェイスである M2PCIe ユニットによって定義されます。
インテル® DDIO トラフィックを解析する
インテル® VTune™ プロファイラーの入力および出力解析を使用して、インテル® DDIO 利用効率メトリックを収集します。
注
解析を実行するには、第 1 世代または第 2 世代インテル® Xeon® スケーラブル・プロセッサーを使用しており、サンプリング・ドライバーをロード済み (英語) でなければなりません。推奨される最小収集時間は 20 秒です。
解析を実行するには、次の操作を行います。
- [WHAT (何を)] ペインで、[Launch Application (アプリケーションを起動)] を選択してアプリケーションのパスと引数を指定するか、[Attach to Process (プロセスにアタッチ)] を選択して PID を指定します。さらに、[Automatically stop collection after (sec) (指定時間後に収集を自動停止 (秒))] を使用すると、収集時間を自動制御できます。
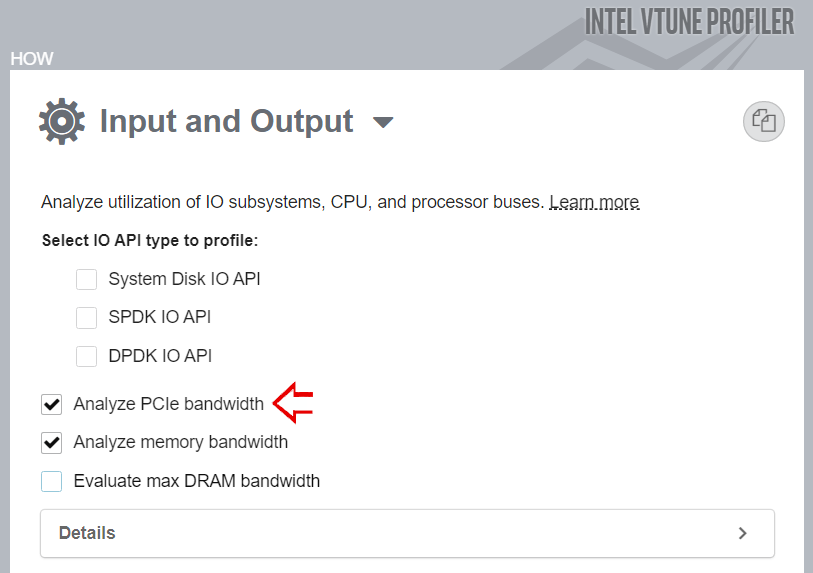
- [HOW (どのように)] ペインで [Input and Output (入力および出力)] 解析を選択します。[Analyze PCIe traffic (PCIe* トラフィックを解析)] チェックボックスをオンにして、インテル® DDIO 利用効率メトリックを収集します。
 [Start (開始)] ボタンをクリックして、解析を実行します。
[Start (開始)] ボタンをクリックして、解析を実行します。
典型的な例を理解する
典型的なインテル® DDIO テクノロジーの非効率な利用例とその検出に役立つインテル® VTune™ プロファイラーの機能を理解するため、2 ソケットの第 2 世代インテル® Xeon® スケーラブル・プロセッサーを搭載したシステムで DPDK testpmd アプリケーションを実行します。このアプリケーションは、シングルコアで動作し、ソケット 1 に装着された 40G の NIC の 1 ポートを使ってパケット転送を行うように構成されています。
トラフィック・ジェネレーターは、1 つのコアが処理できる範囲をはるかに超えるパケットレートで 64B パケットをシステムに供給します。最適化の基準はシステムのスループットであり、スループットは高いほうが良いです。この構成で、シングルコアのアプリケーションのスループットを特定します。
注
ここに示すデータは、パフォーマンス・レポートとして扱われるべきではありません。
以下の 2 つの例では、ソケット 1 のコアがパケット転送を行う構成をベースラインとして使用しています。この構成は、コアと PCIe* デバイスが同じソケット上に存在するため、ローカルと呼ばれます。
1 2 3 | # ./testpmd -n 4 -l 24,25 -- -itestpmd> set fwd mac retrytestpmd> start |
mac 転送モードを使用します。このモードでは、コアがパケットの送信元と送信先のイーサネット・アドレスを変更するため、送信コアはパケット記述子にアクセスし、各パケットにタッチします。
インテル® VTune™ プロファイラーの入力および出力解析を実行して、[Summary (サマリー)] ウィンドウの [Platform Diagram (プラットフォーム・ダイアグラム)] セクションを使用して結果の調査を開始します。
プラットフォーム・ダイアグラムにはシステムのトポロジーが表示され、物理コア (解析するワークロードの計算ごと)、DRAM、インテル® UPI、PCIe*リンクなどのハードウェア・リソースの平均利用率が示されます。PCIe* デバイスのメトリックは、ペイロードの転送に消費される物理帯域幅の割合として計算される有効リンク利用率を示し、オーバーヘッドは考慮されません。詳細は、ユーザーガイドの「入力および出力解析」 (https://software.intel.com/content/www/us/en/develop/documentation/vtune-help/top/analyze-performance/disk-input-and-output-analysis.html) を参照してください。
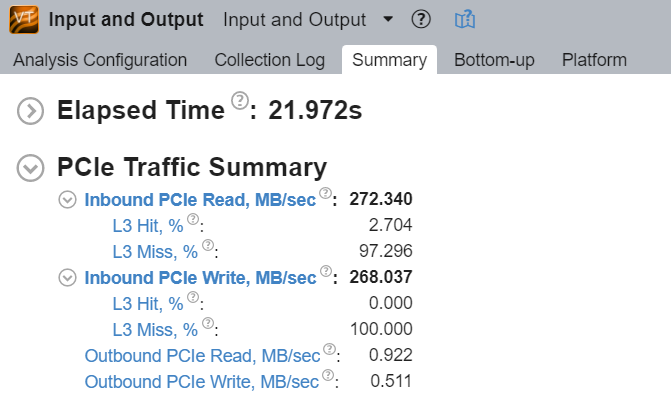
[Summary (サマリー)] タブの [PCIe Traffic Summary (PCIe* トラフィックのサマリー)] セクションで、第 1 レベルのメトリックであるインバウンドとアウトバウンドの PCIe* リードおよびライト・トラフィックの合計と、第 2 レベルのメトリックであるインテル® DDIO の利用効率を確認します。
- L3 ヒット/ミス率は、L3 キャッシュにヒット/ミスしたインバウンド要求の割合を示します。
- 平均レイテンシーは、キャッシュラインに対するインバウンド要求の処理にプラットフォームが費やした平均時間を示します。
- コア/I/O 競合メトリックは、キャッシュライン競合が発生したインバウンド・ライト比率を示します。検出されると、インテル® VTune™ プロファイラーは可能なチューニングの方向性を提案します。
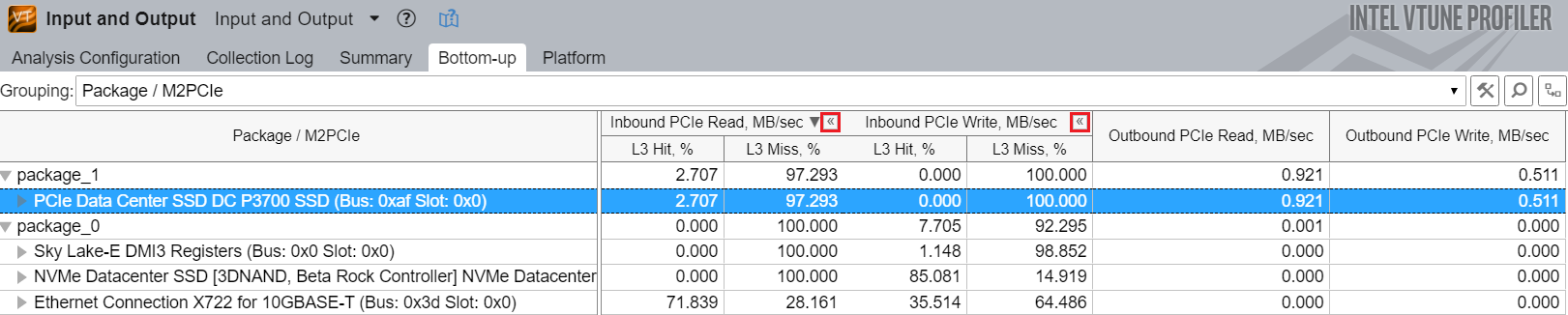
詳細な I/O メトリックを表示するには、[Bottom-up (ボトムアップ)] ペインの [PCIe Traffic Summary (PCIe* トラフィックのサマリー)] セクションでメトリックをクリックします。

PCIe* メトリックを表示するには、[Grouping (グループ化)] ドロップダウン・メニューから [Package/M2PCIe (パッケージ/M2PCIe)] グループを選択します。このグループは、サービスを提供する PCIe* デバイスによって名前が付けられたソケットと M2PCIe ブロックごとにメトリックを分類します。M2PCIe が複数のデバイスを管理している場合、デバイス名はカンマ区切りのリストで示されます。セルにホバーするとすべてのデバイスが表示されます。
インテル® DDIO 利用効率メトリックを表示するには、各カラムの [Expand (展開)] ボタンをクリックして第 2 レベルを展開します。
[Platform (プラットフォーム)] タブで DRAM とインテル® UPI 帯域幅の詳細を確認します。
リモート・ソケット・アクセス
最初の例は、インテル® DDIO ミス率とインテル® DDIO レイテンシーが高く、DRAM とインテル® UPI トラフィックを発生させる、最適でないアプリケーション・トポロジーを示します。これらの要因が重なると、パフォーマンスが低下します。
これは、送信コアと NIC が別々のソケットに存在するリモート構成を使用した、最適でないトポロジーの例です。
1 2 3 | # ./testpmd -n 4 -l 0,1 -- -itestpmd> set fwd mac retrytestpmd> start |
GUI またはコマンドラインから [Attach to Process (プロセスにアタッチ)] モードで解析を再度実行します。
1 | # vtune -collect io --duration 20 --target-process testpmd |
[Platform Diagram (プラットフォーム・ダイアグラム)] を確認すると、トポロジーの問題がすぐに分かります。
- 別のソケットの NIC に関連したコア利用率
- 非ゼロの DRAM およびインテル® UPI 利用率
結果を調査します。
| 送信コア ID |
スループット (Mpps) |
インバウンド PCIe* リード L3 ミス (%) |
平均 インバウンド PCIe* リード・ レイテンシー (ナノ秒) |
インバウンド PCIe* ライト L3 ミス (%) |
平均 インバウンド PCIe* ライト・ レイテンシー (ナノ秒) |
|---|---|---|---|---|---|
| 25 | 21.1 | 0 | 112 | 0 | 135 |
| 1 | 17.1 | 100 | 320 | 100 | 240 |
送信コアと NIC が別々のソケットに存在する構成では、L3 ミスが 100% となり、インバウンド PCIe* 要求レイテンシーが高くなり、パフォーマンスが低下します。
リモートケースでの高いミス率の原因を理解するために、解析結果の [Platform (プラットフォーム)] ペインに移動します。
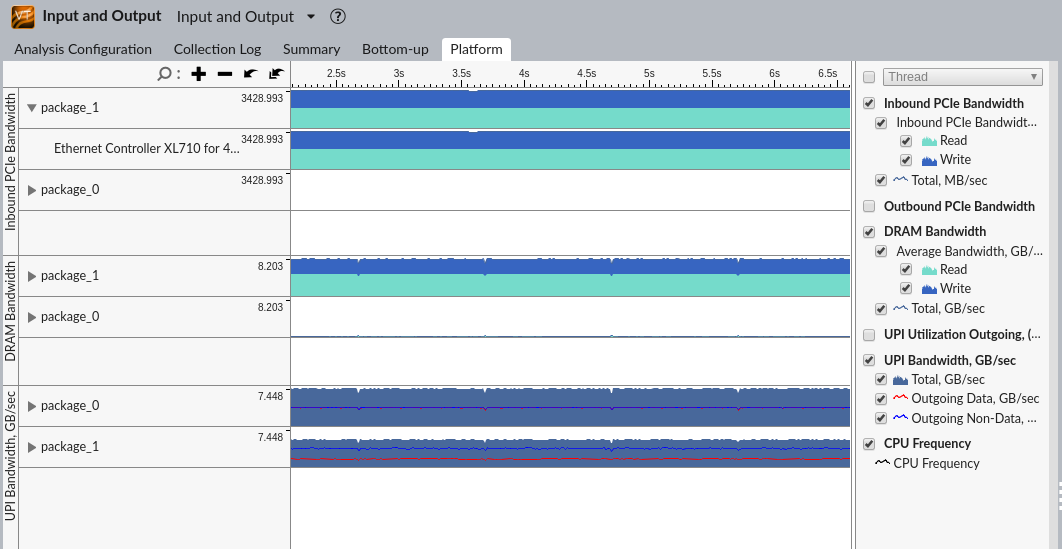
インテル® UPI および DRAM 帯域幅が高いことが分かります。システム上で起こっていることを全体的に把握するには、メモリーアクセス解析を使用してコアの観点から構成を解析します。
1 | # vtune -collect memory-access -knob dram-bandwidth-limits=false --duration 20 --target-process testpmd |
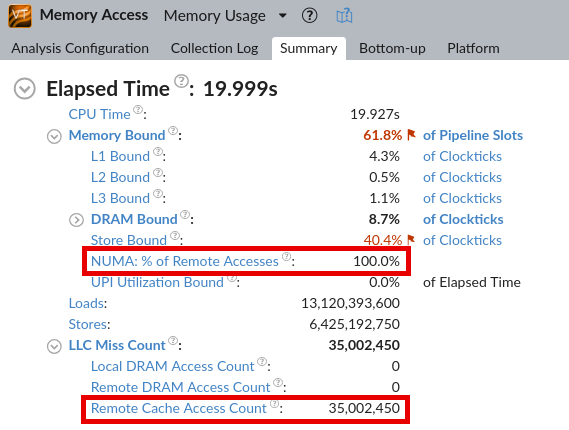
インテル® VTune™ プロファイラーのレポートから、リモート構成では、リモート L3 キャッシュで解決される LLC ミスが原因で生じるリモートアクセスによって CPU コア利用率が制限されていることが分かります。[Bottom-up (ボトムアップ)] ペインに移動して、リモート LLC にアクセスするコア、プロセス、スレッド、関数を特定します。

すべての LLC アクセスは、ソケット 0 のコア 1 で実行している testpmd アプリケーションで発生していることが分かります。
これで、リモート構成で起こっていることを再現できます。ソケット 0 の DRAM 帯域幅はゼロであるため、記述子やパケットリングに使用されるアプリケーションの消費メモリーはすべてソケット 1 で NIC にローカルに割り当てられます。ソケット 0 の送信コアが記述子とパケットにアクセスすると、ソケット 0 の LLC ミスが発生し、ソケット 1 からデータを取得するためスヌープ要求が送信され、インテル® UPI トラフィックが発生します。これらの要求がソケット 1 の LLC に変更済みデータを見つけると、DRAM ライトバックが発生して DRAM 帯域幅に影響を与えます。
デバイスが同じ場所に再度アクセスすると、データは最後に使用されたソケット 0 のコアにあるため、ソケット 1 で L3 キャッシュミスが発生します。そして、メモリー・ディレクトリーにアクセスしてアドレスがキャッシュされているソケット特定するため、DRAM 帯域幅が発生します。この場合、スヌープ要求はソケット 1 からソケット 0 へ送信され、コヒーレンシー・ルールを適用して I/O 要求を完了します。
その結果、インテル® VTune™ プロファイラーの入力および出力解析とメモリーアクセス解析で次の値が得られました。
| 送信 コア ID |
スループット (Mpps) |
インバウンド PCIe* リード L3 ミス (%) |
平均 インバウンド PCIe* リード・ レイテンシー (ナノ秒) |
インバウンド PCIe* ライト L3 ミス (%) |
平均 インバウンド PCIe* ライト・ レイテンシー (ナノ秒) |
testpmd: LLC ミス数 |
testpmd: リモート・ キャッシュ・ アクセス数 |
合計 DRAM 帯域幅 (ソケット 1) (GB/秒) |
合計 インテル® UPI 帯域幅 (GB/秒) |
|---|---|---|---|---|---|---|---|---|---|
| 25 | 21.1 | 0 | 112 | 0 | 135 | 0 | 0 | 0 | 0 |
| 1 | 17.1 | 100 | 320 | 100 | 240 | 35M | 35M | 8 | 12.6 |
要求レイテンシーが高くなることによるスループットの低下に加えて、最適でないアプリケーションのトポロジーは、システムの DRAM 帯域幅、インテル® UPI 帯域幅、プラットフォームの電力を無駄にします。
最適でない L3 キャッシュ管理
2 つ目の例は、さまざまなパフォーマンスの問題を含んでいます。リモート・ソケット・アクセスがない場合でも、DDIO ミスに見られるように、LLC の I/O データ管理が最適でないためにパフォーマンスが制限されます。
DPDK testpmd を使用した例を示すため、パケットリングとして使用されるメモリープールのソフトウェアレベルのキャッシュ (DPDK メモリープール・ライブラリー (英語)) を無効にします。このデフォルトのキャッシュメカニズムを使用すると、コアは新しいパケットを受信し、データのデスティネーションとして、ほとんどの場合ハードウェア・キャッシュに存在する (英語) 「warm」メモリープール要素を使用します。そのため、パケット・リング・サイズが L3 容量を超える場合であっても、インバウンド PCIe* リードおよびライトで L3 ミスが発生することはありません。
メモリープールのソフトウェア・キャッシュを無効にする –mbcache=0 を使用して testpmd を実行します。
1 2 3 | # ./testpmd -n 4 -l 24,25 -- -i --mbcache=0testpmd> set fwd mac retrytestpmd> start |
最初のローカル構成と、同じ構成でメモリープールのソフトウェア・キャッシュを無効にした場合の testpmd のパフォーマンスを比較します。
| メモリープール・ キャッシュ |
スループット (Mpps) |
インバウンド PCIe* リード L3 ミス (%) |
平均 インバウンド PCIe* リード・ レイテンシー (ナノ秒) |
インバウンド PCIe* ライト L3 ミス (%) |
平均 インバウンド PCIe* ライト・ レイテンシー (ナノ秒) |
合計 DRAM 帯域幅 (ソケット 1) (GB/秒) |
|---|---|---|---|---|---|---|
| 有効 | 21.1 | 0 | 112 | 0 | 135 | 0 |
| 無効 | 20.2 | 0 | 115 | 54 | 178 | 4.7 |
メモリープール・キャッシュの最適化なしでアプリケーションを実行すると、インバウンド PCIe* ライト要求の大部分で L3 ミスが発生します。
1 パケットを転送するため、NIC とコアはパケット記述子とパケットリングを介して通信します。データパスで NIC はインバウンド PCIe* ライトを使用してパケットを書き込み、パケット記述子を更新します (詳細は「DPDK アプリケーションの PCIe* トラフィック」を参照)。
記述子リングは常に I/O の前にコアによってアクセスされるため、記述子アクセスで I/O L3 ミスが発生する確率は低いです。しかし、パケットリングは最初に NIC によってアクセスされるため、すべてのインバウンド PCIe* ライト L3 ミスは、NIC が Rx ステージでパケットリングへパケットを書き込むことで発生します。同時に、DPDK はネットワーク・データのゼロコピーポリシーに従っているため、インバウンド PCIe* リード L3 ミスは発生しません。NIC がパケットを取得して Tx を実行しようとすると、パケットはすでにキャッシュされています。
この結論は、パケットリングのソフトウェア・キャッシュを無効にした場合、パケットリングのアクセスはハードウェア・キャッシュ・ミスになるということから容易に導き出されます。このレシピは、実際のシナリオで、どのデータが I/O でアクセスされ、結果的にインテル® DDIO ミスになったかを理解する方法を示しています。
この場合、インバウンド PCIe* 要求の L3 ミスは、L3 からのライトバック、L3 割り当て、メモリー・ディレクトリー・アクセスによって生じる DRAM 帯域幅を意味します。
要約
インテル® DDIO テクノロジーは、ソフトウェアが高速 I/O デバイスを完全に活用できるようにします。しかし、NUMA システムでアプリケーションのトポロジーが最適でない場合や、L3 キャッシュのデータ管理が最適でない場合、L3 アクセス・レイテンシーが高くなり、不要な DRAM トラフィックが発生して、ソフトウェアがインテル® DDIO の恩恵を十分に受けられません。インテル® VTune™ プロファイラーの各種解析タイプ (入力および出力、メモリーアクセス、マイクロアーキテクチャー全般) はこのような非効率性を検出して、コアと I/O の両方の観点から全体像を提供します。
アプリケーションのトポロジーが最適でないという問題には明らかな解決策がありますが、効率的な L3 利用スキームの開発は容易ではないかもしれません。このようなスキームを設計して、パフォーマンスを向上するいくつかのアプローチがあります。
- LLC 容量よりも小さいバッファーサイズを選択する
- バッファー要素を再利用する
- デバイスが使用する場所をソフトウェア・プリフェッチする
- キャッシュ・アロケーション・テクノロジー (CAT) (英語) を使用して L3 をパーティショニングする
注
このレシピの情報は、インテル® VTune™ プロファイラー・デベロッパー・フォーラムを参照してください。
関連情報
ユーザーガイドの「入力および出力解析」セクション
https://software.intel.com/content/www/us/en/develop/documentation/vtune-help/top/analyze-performance/disk-input-and-output-analysis.html
インテル® データ・ダイレクト I/O テクノロジーの概要 (英語)
DPDK アプリケーションの PCIe* トラフィック
インテル® Xeon® スケーラブル・プロセッサー・ファミリーの技術概要 (英語)
第 2 世代インテル® Xeon® スケーラブル・プロセッサー・ファミリーの技術概要
インテル® Xeon® スケーラブル・プロセッサー・ファミリーの IIO パフォーマンス・モニタリング・イベントの活用 (英語)
インテル® Xeon® スケーラブル・プロセッサー・ファミリーのアンコア・リファレンス・マニュアル (英語)
マルチスレッド Data Plane Development Kit (DPDK) アプリケーションのメモリー使用の最適化 (英語)
ソフトウェア・データ・プレーンのベンチマークと解析ホワイトペーパー (英語)
What Every Programmer Should Know About Memory by Ulrich Drepper of Red Hat, Inc. の Ulrich Drepper 氏によるメモリーについてすべてのプログラマーが知っておくべきこと (英語)
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのトップに戻る
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
