
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「DPDK Event Device Profiling」(https://software.intel.com/content/www/us/en/develop/documentation/vtune-cookbook/top/methodologies/dpdk-event-device-profiling.html) の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2020 (最終更新日: 2021 年 3 月 26 日)
インテル® VTune™ プロファイラーを使用して、DPDK ベースのアプリケーションの DPDK イベント・デバイス・パイプラインの利用効率を解析して、不均衡な負荷分散やワーカーコアが十分に利用されていない問題を特定します。
コンテンツ・エキスパート: Eugeny Parshutin、Kurakin Ilia
Data Plane Development Kit (DPDK) は、さまざまな CPU アーキテクチャー上で動作するパケット処理ワークロードを高速化する、複数のライブラリーで構成されるフレームワークです。その 1 つが、アプリケーションでイベントベースのモデルを使用することでシステムの負荷分散を向上させる eventdev ライブラリーです。イベントベースのアプローチでは、システムが行うべき作業をイベントと呼ばれる個別のユニットで示します。DPDK でイベントベースのプログラミング・モデルを使用する一般的な例として、ネットワーク・パケット処理パイプラインがあり、各パケットがイベントの役割を果たします。
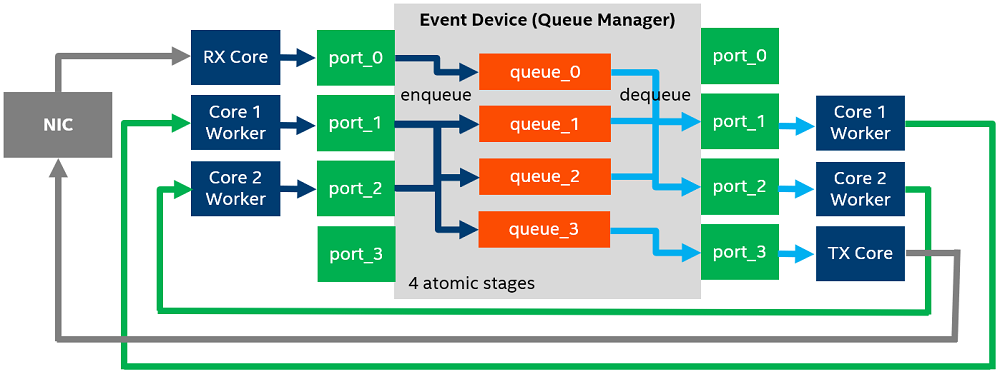
次の図は、eventdev パイプラインの構成例です。
ここでは、各ブロックが次のユニットを表しています。
- Event Device (イベントデバイス) – ハードウェアまたはソフトウェアで実装されたイベント・スケジュール機能を備えたデバイス。
- Queue (キュー) – スケジュール・タイプ (アトミック、順序付き、または並列) に関連付けられた異なるフローのイベントを含む処理パイプラインの論理ステージ。
- Ports (ポート) – eventdev キューにイベントをエンキュー/デキューする、コアと eventdev ライブラリーの接点。
- Worker Cores (ワーカーコア) – アプリケーションが作業を実行するのに利用可能な CPU コア。
- Rx Core (Rx コア) – NIC からパケットを受信する CPU コア。
- Tx Core (Tx コア) – NIC にパケットを送信する CPU コア。
- NIC – ネットワーク・インターフェイス・カード。
この例は、4 つのイベントキューを表す 4 つのアトミックステージを管理するイベントデバイスを示しています。
- queue_0 は新たに受信したパケットを保持するために使用されます。Rx コアのみがこのキューにパケット (イベント) をエンキューします。
- queue_1 と queue_2 は、送信先アドレスの設定、暗号処理、圧縮など、特定のイベント処理ステージに使用されます。ワーカーコアはこれらのタスクを実行して、キュー 0、1、2、3 の間でパケットを転送します。
- queue_3 は、送信準備が整ったパケットを保持するために使用されます。Tx コアのみがこのキューからパケットをデキューします。
デキュー操作は、rte_event_dequeue_burst() ルーチンを使用して無限ループで行われます。そのため、ワーカーコアはイベント・デバイス・ポートを継続的にポーリングして、処理すべきイベントのバッチを探します。バッチサイズは、全体の負荷と各ステージのパフォーマンスに依存します。最大バッチサイズは、ワークロードによって定義されます。
インテル® VTune™ プロファイラーが提供するワーカーごとのデキュー統計を利用して、負荷分散の詳細を明らかにし、パイプライン構成の効率を解析し、パイプラインのボトルネックを特定できます。
このレシピは、次の手順に従って、DPDK ベースのアプリケーションのパイプライン処理モデルの効率を解析します。
使用するもの
以下は、このパフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: DPDK eventdev_pipeline アプリケーション。eventdev API の使用法を示し、パイプラインを設定し、イベント処理を実行するワーカーコアを割り当てる方法を示します。インテル® VTune™ プロファイラーのサポートが有効な DPDK でコンパイルされています。
- ツール:
- DPDK。インテル® VTune™ プロファイラーのサポートを有効にしてコンパイルされています。DPDK 側で eventdev プロファイルを有効にするには、パッチ dpdk_eventdev_vtune_profiling.patch を適用して DPDK とターゲット DPDK アプリケーションを再コンパイルする必要があります。DPDK イベントデバイスのプロファイル・パッチは https://software.intel.com/content/www/us/en/develop/download/dpdk-event-device-profiling-patch.html からダウンロードしてください。
- インテル® VTune™ プロファイラー 2020: 入力および出力解析
注
- バージョン 2020 から、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。
- インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのほとんどのレシピは、異なるバージョンのインテル® VTune™ プロファイラーにも適用できます。バージョンにより、わずかな調整が必要になる場合があります。
- 最新バージョンのインテル® VTune™ プロファイラーは以下から入手できます。
- システムの設定:
- トラフィック・ジェネレーター: テストするシステムのトラフィックを生成するシステム。
- テスト対象のシステム: パケット処理用の eventdev_pipeline アプリケーションと、パフォーマンス・データを収集するインテル® VTune™ プロファイラーが動作しているシステム。
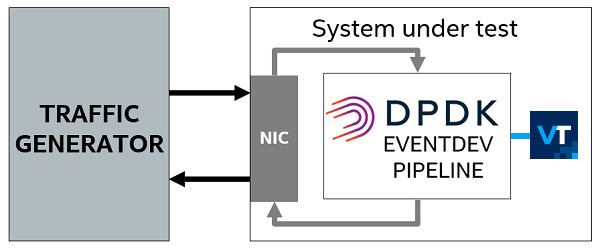
- CPU: インテル® Xeon® Platinum 8168 プロセッサー (開発コード名: Skylake)。
- オペレーティング・システム: Linux*。
入力と出力解析を実行する
DPDK eventdev デキュー統計を収集するには、インテル® VTune™ プロファイラーの入力および出力解析を使用します。
GUI から解析を実行するには、次の操作を行います。
- インテル® VTune™ プロファイラー GUI を起動して、新しいプロジェクトを作成します。
- [HOW (どのように)] ペインで [Input and Output (入力および出力)] 解析を選択します。
- [Select IO API type to profile (プロファイルする I/O API タイプを選択)] で [DPDK IO API (DPDK I/O API)] を選択します。
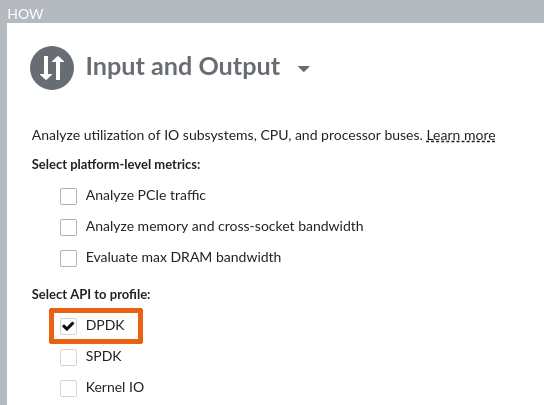
- [Start (開始)] ボタンをクリックします。
コマンドラインから DPDK プロファイルを使用した入力および出力解析を実行するには、次のコマンドを使用します。
vtune -collect io -knob kernel-stack=false -knob dpdk=true --target-process=eventdev_pipeline
ステージごとの負荷を解析する
DPDK eventdev パイプライン利用の全体的な特徴を取得するには、[Summary (サマリー)] タブから開始して [DPDK Events Dequeue Statistics (DPDK イベントデキュー統計)] ヒストグラムを調査します。
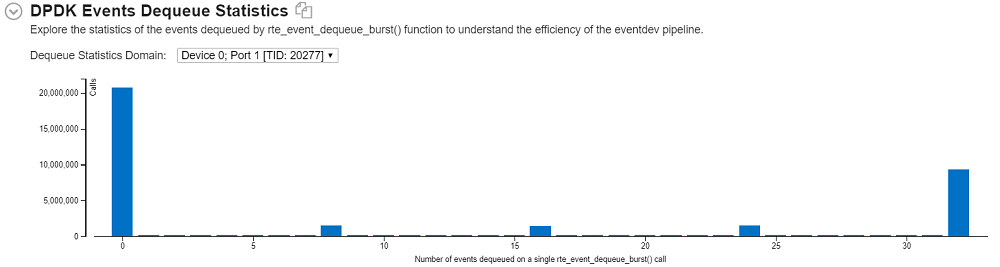
このヒストグラムは、eventdev ポートごと、つまりイベントデバイスをポーリングするワーカースレッドごとに、デキューイベント数の統計を表します。ヒストグラムのそれぞれの領域を調べることで、不均衡な負荷分散、オーバーサブスクリプション、十分に利用されていないワーカーを特定できます。
ワーカースレッドの負荷分散に不均衡が見られる場合は、これを避けるようにパイプラインを再構成し、解析を再度実行してください。
CPU 利用を解析する
イベントデキュー操作を実行するワーカーの CPU 利用状況を理解するには、[Platform (プラットフォーム)] タブに移動して、ワーカースレッドに関連付けられている [DPDK Event Dequeue Spin Time (DPDK イベント・デキュー・スピン時間)] メトリックを調べます。
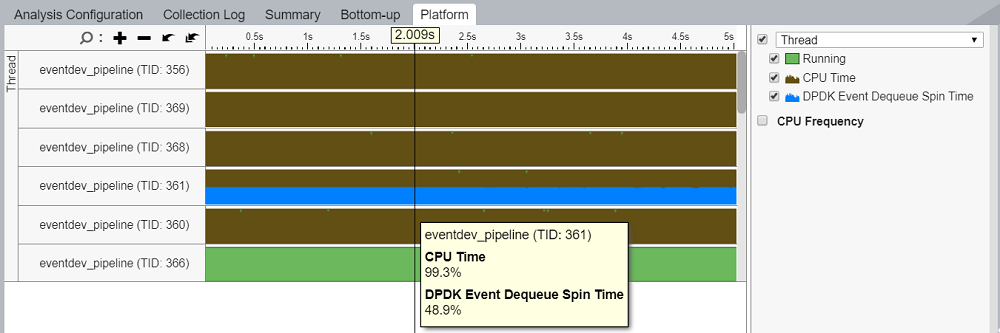
スレッドごとの [DPDK Event Dequeue Spin Time (DPDK イベント・デキュー・スピン時間)] メトリックは、空のデキューサイクルの比率を示しています。これは、デキュー呼び出しの総数に対して、ゼロイベントを返した rte_event_dequeue_burst() 呼び出しの比率です。このメトリックを使用してワーカースレッドの負荷を推定し、アプリケーションのコアが十分に活用されていないか、リソースを増やす必要があるかを判断します。
関連情報
クックブック: DPDK アプリケーションのコア使用率
クックブック: DPDK アプリケーションの PCIe* トラフィック
DPDK イベント・デバイス・ライブラリー (https://doc.dpdk.org/guides/prog_guide/eventdev.html)
Data Plane Development Kit (DPDK) Eventdev ライブラリーの概要 (英語)
ソフトウェア・ネットワーク・データ・プレーンのベンチマークと解析 (英語)
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのトップに戻る
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
