
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Compile a Portable Optimized Binary With the Latest Instruction Set」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2020 (最終更新日: 2021 年 4 月 16 日)
このレシピでは、移植性を維持しながら最新の命令セットを使用してバイナリーをコンパイルするさまざまな方法を学びます。
コンテンツ・エキスパート: Roman Khatko
最近のインテル® プロセッサーは、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512)、インテル® AVX2、およびインテル® AVX など、異なるバージョンの命令セット拡張をサポートしています。
アプリケーションをコンパイルするとき、アプリケーションの使用目的に基づいて 3 つのオプションを検討します。
- 汎用バイナリー: 汎用 x86 命令セット向けにアプリケーションをコンパイルします。アプリケーションはすべての x86 プロセッサーで動作しますが、新しいプロセッサーの能力を最大限に活用できません。
- ネイティブバイナリー: 特定のプロセッサー向けにアプリケーションをコンパイルします。アプリケーションはターゲット・プロセッサーのすべての機能を活用できますが、古いプロセッサーでは動作しません。
- ポータブルバイナリー: コンパイラー・オプションや関数の属性を使用して、異なるプロセッサーをターゲットとする関数の複数のバージョンを含む、最適化されたポータブルなバイナリーをコンパイルします。生成されるバイナリーは、特定のプロセッサー向けにコンパイルされたアプリケーション (ネイティブバイナリー) のパフォーマンス特性を備えつつ、古いプロセッサーでも動作します。
このレシピは、汎用バイナリーの移植性を維持しながら、ネイティブバイナリーのパフォーマンス特性を備えたポータブルバイナリーをコンパイルする方法を示します。このレシピでは、最初に汎用バイナリーとネイティブバイナリーの両方をコンパイルして、パフォーマンスの向上がバイナリーサイズの増加に見合うものかどうかを判断します。
このレシピでは、インテル® C++ コンパイラー・クラシックと GNU* コンパイラー・コレクション (GCC) を取り上げます。
このレシピでは、CPUID プロセッサー命令を使用した手動ディスパッチ、プロセッサー・ターゲット・コンパイラー・オプション (https://software.intel.com/content/www/us/en/develop/documentation/cpp-compiler-developer-guide-and-reference/top/optimization-and-programming-guide/processor-targeting.html)、およびターゲットの関数属性 (英語) は取り上げていません。
使用するもの
以下は、このレシピで使用するシステムとツールのリストです。
- プロセッサー: インテル® Xeon® プロセッサー (開発コード名 Cascade Lake)
- オペレーティング・システム: Fedora* 32
- コンパイラー:
- インテル® C++ コンパイラー・クラシック 2021.1.2
- GCC 10.1.1
- 解析ツール: インテル® VTune™ プロファイラー 2021.1.2
サンプル・アプリケーション
次のコードをソースファイル fma.c に保存します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | // fma.c#include <stdio.h>#include <stdlib.h>void init(float *a, float *b, float *c, int size){ for (int i = 0; i < size; i++) { a[i] = (float) (i % 10); b[i] = a[i] * 1.1f; c[i] = a[i] * 1.2f; }}void my_fma(float *a, float *b, float *c, int size){ for (int i = 0; i < size; i++) { c[i] += a[i]*b[i]; }}#define ITERATIONS 10000000#define SIZE 2048int main(){ float *a = malloc(SIZE*sizeof(float)); float *b = malloc(SIZE*sizeof(float)); float *c = malloc(SIZE*sizeof(float)); for (int i = 0; i < ITERATIONS; i++) { init(a, b, c, SIZE); my_fma(a, b, c, SIZE); } printf("%f", c[5]); // use the data free(a); free(b); free(c); return 0;} |
汎用の最適化されたバイナリーのコンパイル
『インテル® VTune™ プロファイラー・ユーザーガイド』の説明 (Linux* および Windows* に従ってバイナリーをコンパイルします。
インテル® C++ コンパイラー・クラシック
デバッグ情報を含め、-O3 最適化レベルを指定してバイナリーをコンパイルします。
1 | icc -g -O3 -debug inline-debug-info fma.c -o fma_generic |
GNU* コンパイラー・コレクション
デバッグ情報を含め、-O2 最適化レベルを指定してバイナリーをコンパイルします。
1 | gcc -g -O2 fma.c -o fma_generic_O2 |
コードがインテル® VTune™ プロファイラーの HPC パフォーマンス特性解析タイプを使用してベクトル化されているか確認します。
確認するには、次の解析を実行します。
1 | vtune -c hpc-performance -r fma_generic_O2_hpc ./fma_generic_O2 |
インテル® VTune™ プロファイラー GUI で結果を開きます。
1 | vtune-gui fma_generic_O2_hpc |
解析結果を開き、[Summary (サマリー)] タブの [Top Loops/Functions with FPU Usage by CPU Time (CPU 時間による FPU を使用する上位のループ/関数)] セクションを確認します。

[FP Ops: Scalar (FP 操作: スカラー)] 値が 100% で [Vector Instruction Set (ベクトル命令セット)] カラムが空の場合、GCC は -O2 最適化レベルでコードをベクトル化していません。-O2 -ftree-vectorize または -O3 オプションを使用してベクトル化を有効にします。
-O3 最適化レベルを指定して fma_generic バイナリーをコンパイルします。
1 | gcc -g -O3 fma.c -o fma_generic |
ネイティブバイナリーのコンパイル
インテル® C++ コンパイラー・クラシックを使用してネイティブバイナリーをコンパイルする
-xHost オプションは、コンパイルを行うプロセッサーで利用可能な最上位の命令セットを使用したコードを生成するようにコンパイラーに指示します。-x{Arch} オプション ({Arch} はアーキテクチャーの開発コード名) を使用すると、特定のアーキテクチャーのプロセッサー機能をターゲットにするようにコンパイラーに指示できます。
-xHost オプションを使用して fma_native バイナリーをコンパイルします。
1 | icc -g -O3 -debug inline-debug-info -xHost fma.c -o fma_native |
GNU* コンパイラー・コレクションを使用してネイティブバイナリーをコンパイルする
-march=native オプションを使用して fma_native バイナリーをコンパイルします。
1 | gcc -g -O3 -march=native fma.c -o fma_native |
プロセッサーがインテル® AVX-512 命令セットをサポートしている場合、mprefer-vector-width=512 オプションを使用することを検討してください。
汎用バイナリーとネイティブバイナリーの比較
両方のバイナリーの HPC パフォーマンス・スナップショット解析データを収集します。
1 | vtune -c hpc-performance -r fma_generic_hpc ./fma_generic |
1 | vtune -c hpc-performance -r fma_native_hpc ./fma_native |
次のコマンドを使用して結果を比較します。
1 | vtune-gui fma_generic_hpc fma_native_hpc |
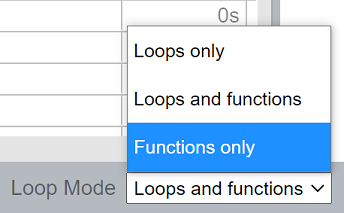
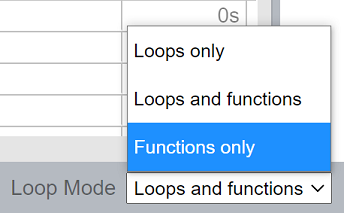
インテル® VTune™ プロファイラー GUI で、[Bottom-up (ボトムアップ)] タブに切り替えて [Loop Mode (ループモード)] を [Functions only (関数のみ)] に設定します。
[Summary (サマリー)] タブに切り替えて [Top Loops/Functions with FPU Usage by CPU Time (CPU 時間による FPU を使用する上位のループ/関数)] セクションまでスクロールします。

[CPU Time (CPU 時間)] および [Vector Instruction Set (ベクトル命令セット)] カラムを確認します。
汎用バイナリーとネイティブバイナリーのパフォーマンスの差を考慮します。複数のコードパスを使用してポータブルバイナリーをコンパイルすることが適切かどうかを判断します。
このサンプル・アプリケーションは、コンパイラーにより自動ベクトル化されました。アプリケーションのベクトル化の可能性を詳しく調べるには、インテル® Advisor を使用します。
ポータブルバイナリーのコンパイル
汎用バイナリーとネイティブバイナリーを比較してパフォーマンスが向上した場合 (例えば、[CPU Time (CPU 時間)] が向上した場合)、ポータブルバイナリーをコンパイルします。
インテル® C++ コンパイラー・クラシックを使用してポータブルバイナリーをコンパイルする
-ax (Windows* の場合は /Qax) オプションを使用して、インテル® プロセッサー向けに複数の機能固有の自動ディスパッチ・コードを生成するようにコンパイラーに指示します。
-ax オプションを使用して fma_portable バイナリーをコンパイルします。
1 | icc -g -O3 -debug inline-debug-info -axCOMMON-AVX512,CORE-AVX2,AVX,SSE4.2,TREMONT fma.c -o fma_portable |
GNU* コンパイラー・コレクションを使用してポータブルバイナリーをコンパイルする
汎用バイナリーとネイティブバイナリーの結果を比較します。[CPU Time (CPU 時間)] が向上し、ネイティブバイナリーの結果で特定の関数に追加の [Vector Instruction Set (ベクトル命令セット)] が使用された場合、この関数に target_clones 属性を追加します。
関数がほかの関数を呼び出している場合、target_clones 属性は再帰的でないため、flatten 属性を追加してインライン展開を行います。
fma.c ソースファイルのコンテンツを新しいファイル fma_portable.c にコピーして、TARGET_CLONE プリプロセッサー・マクロを追加します。
1 2 3 | #define TARGET_CLONES __attribute__((flatten,target_clones("default,sse4.2,avx,"\ "avx2,avx512f,arch=skylake,arch=tremont,arch=skylake-avx512,"\ "arch=cascadelake,arch=cooperlake,arch=tigerlake,arch=icelake-server"))) |
サポートされているアーキテクチャーの一覧は、GCC マニュアルの x86 オプション (英語) を参照してください。
複数のバージョンの関数を作成すると、バイナリーのサイズは増加します。各ターゲットのパフォーマンス向上とコードサイズのトレードオフを考慮してください。インテル® VTune™ プロファイラーを使用してデータを収集して結果を比較することにより、データ駆動型の決定を行い、新しい命令で高速に実行される関数にのみ TARGET_CLONES マクロを適用できます。
my_fma 関数定義と init 関数の前に TARGET_CLONES マクロを追加し、fma_portable.c を保存します。
1 2 | TARGET_CLONESvoid my_fma(float *a, float *b, float *c, const int size) |
fma_portable バイナリーをコンパイルします。
1 | gcc -g -O3 fma_portable.c -o fma_portable |
ポータブルバイナリーとネイティブバイナリーの比較
ポータブルバイナリーとネイティブバイナリーのパフォーマンスを比較するため、fma_portable バイナリーの HPC パフォーマンス特性データを収集します。
1 | vtune -c hpc-performance -r fma_portable_hpc ./fma_portable |
インテル® VTune™ プロファイラー GUI で比較を開きます。
1 | vtune-gui fma_portable_hpc fma_native_hpc |

ポータブルバイナリーは利用可能な最上位の命令セットを使用し、ターゲットシステムで最適なパフォーマンスを得ることができました。
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのトップに戻る
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
