
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Cache-Related Latency Issues in Segmented Cache Environment」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2020 (最終更新日: 2021 年 4 月 16 日)
このレシピでは、キャッシュ・アロケーション・テクノロジー (CAT) を使用して、コア間のキャッシュを分割する際にキャッシュ関連のレイテンシー問題 (キャッシュミス) を制御する方法を示します。
コンテンツ・エキスパート: Kirill Uhanov
使用するもの
以下は、このパフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション:
ラストレベルキャッシュ (LLC) に収まるバッファーが割り当てられたリアルタイム・アプリケーション (RTA)。RTA は、このバッファーから継続的に読み取りを行います。
RTA は、ユーザーが即時または現在として指定した時間内で機能するプログラムです。リアルタイム・プログラムは、指定された時間内 (「デッドライン」とも呼ばれます) での応答を保証する必要があります。デッドラインをミスする理由はいくつかあります。
- プリエンプション
- 割り込み
- クリティカル・コード実行中の予期しないレイテンシー
リアルタイム・オペレーティング・システム (RTOS) は、アプリケーションを分離してプリエンプションや割り込みを回避する効率的なソリューションを提供します。しかし、CPU キャッシュミスのペナルティーなど、CPU マイクロアーキテクチャーの問題によりレイテンシーが生じる場合があります。次に RTA の例を示します。
struct timespec sleep_timeout = (struct timespec) { .tv_sec = 0, .tv_nsec = 10000000 }; ... buffer=malloc(128*1024); ... run_workload(buffer,128*1024); void run_workload(void *start_addr,size_t size) { unsigned long long i,j; for (i=0;i<1000;i++) { nanosleep(&sleep_timeout,NULL); for (j=0;j<size;j+=32) { asm volatile("mov(%0,%1,1),%%eax" : :"r" (start_addr),"r"(i) :"%eax","memory"); } } } - 「ノイズ」アプリケーション: stress-ng は、キャッシュをロードしてストレスをかけます。
- ツール: インテル® VTune™ プロファイラー – メモリーアクセス解析。AMPLXE_EXPERIMENTAL=cat を設定して、Cache Availability (preview) (キャッシュ利用率 (プレビュー)) 機能を有効にします。
注
- バージョン 2020 から、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。
- インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのほとんどのレシピは、異なるバージョンのインテル® VTune™ プロファイラーにも適用できます。バージョンにより、わずかな調整が必要になる場合があります。
- 最新バージョンのインテル® VTune™ プロファイラーは以下から入手できます。
- オペレーティング・システム: Linux*。
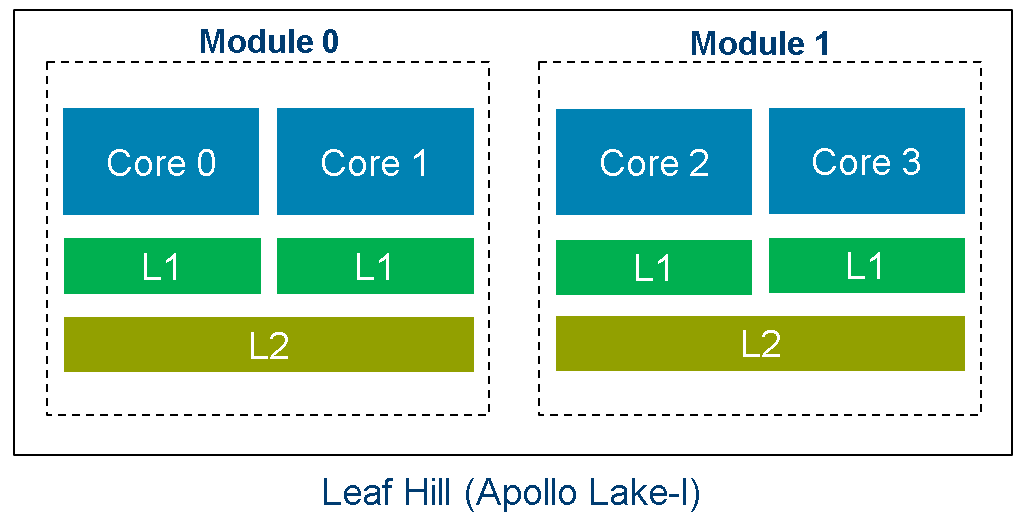
- ハードウェア: Intel Atom® プロセッサー E3900 シリーズ (開発コード名 Apollo Lake) Leaf Hill、L2 CAT 機能有効。
メモリーアクセス解析を実行する
「ノイズ」環境で RTA を実行してパフォーマンスの低下に気付いたときは、メモリーアクセス解析を実行して CPU キャッシュミスのペナルティーなどのマイクロアーキテクチャーの問題を詳しく調べます。
次の例では、RTA はコア 3 にピニングされ、stress-ng はコア 2 にピニングされます。
stress-ng -C 10 --cache-level 2 --taskset 2 --aggressive -v --metrics-brief
両方のコアはモジュール 1 に属していて、L2 LLC を共有します。
- AMPLXE_EXPERIMENTAL=cat を設定して、Cache Availability (preview) (キャッシュ利用率 (プレビュー)) 機能を有効にします。
- インテル® VTune™ プロファイラー GUI を開きます。
- 新しいプロジェクトを作成します。[Create a Project (プロジェクトの作成)] ダイアログボックスが表示されます。
- プロジェクトの名前と場所を指定したら、[Create Project (プロジェクトの作成)] ボタンをクリックします。[Configure Analysis (解析の設定)] ダイアログボックスが開きます。
- [WHERE (どこを)] ペインで、解析のターゲットシステムとして [Remote Linux (SSH) (リモート Linux* (SSH))] を選択します。
- Linux ターゲットへのパスワードなしの SSH アクセスを有効にします (英語)。
- [WHAT (何を)] ペインで、[Launch Application (アプリケーションを起動)] を選択して、解析するターゲット・アプリケーションを指定します。
- [HOW (どのように)] ペインで、解析ヘッダーをクリックして解析ツリーから [Memory Access (メモリーアクセス)] 解析を選択します。
- [Analyze cache allocation (キャッシュ割り当ての解析)] を設定して、コアごとのキャッシュセグメントの使用状況を解析します。
- [Start (開始)] ボタンをクリックして、解析を実行します。
キャッシュミスを特定する
インテル® VTune™ プロファイラーが解析を完了したら、[Summary (サマリー)] ペインの [Collection and Platform Info (収集とプラットフォーム情報)] セクションを確認します。このセクションで、キャッシュ・アロケーション・テクノロジー (CAT) の L2 機能と L3 機能の情報を確認します。この例では、ハードウェアは LLC (L2 キャッシュ) の分割操作をサポートしています。

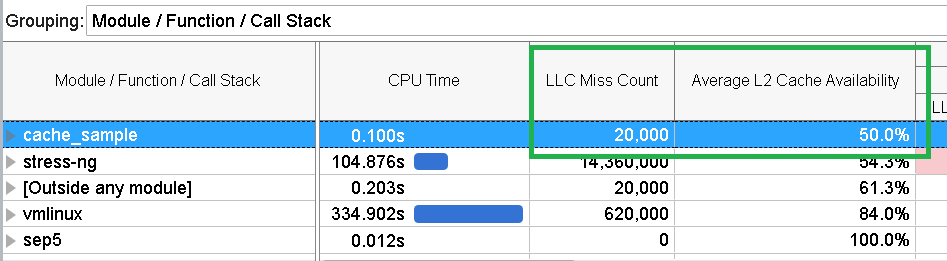
次に、[Bottom-up (ボトムアップ)] ペインに切り替えます。[Module / Function / Call Stack (モジュール / 関数 / コールスタック)] グループ化を選択して、cache_sample モジュールの LLC Miss Count (LLC ミスカウント) の値を確認します。
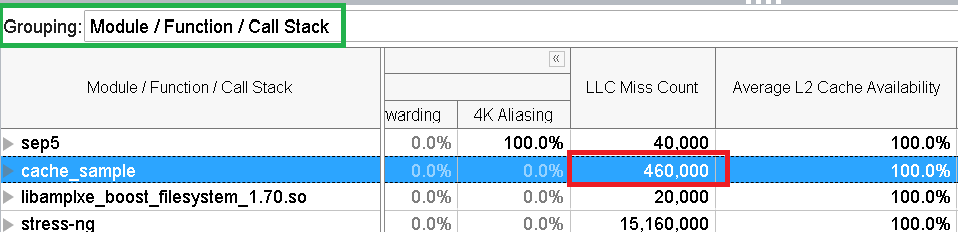
キャッシュミスの数が多くなっています。しかし、stress-ng がない場合、キャッシュミスはゼロです。

次に、[Platform (プラットフォーム)] ペインを開きます。結果を [Logical Core/Thread (論理コア/スレッド)] でグループ化して、[L2 Cache Availability (L2 キャッシュ利用率)] チェックボックスをオンにします。
![[プラットフォーム] ペインの論理コア/スレッド](https://www.isus.jp/wp-content/uploads/image/835_figure5.png)
タイムラインは、L2 キャッシュ利用率が 100% であることを示しています。これは、cpu_2 上でターゲット・アプリケーションが存在する間、L2 キャッシュのすべてのセグメントが利用可能だったことを意味します。しかし、cpu_3 の stress-ng も、存在する間 L2 キャッシュを共有していて、L2 キャッシュ利用率が 100% になっています。これは、cache_sample モジュール内で膨大な量のキャッシュミスが発生する原因となります。
そこで、CAT を使用してコア間のキャッシュセグメントを分割して、各コアがセグメントを排他的に使用できるようにします。
CAT を使用してコア間のキャッシュセグメントを再構成する
キャッシュセグメントを分割して、RTA と stress-ng に割り当てます。CAT を使用して、スレッド、アプリケーション、仮想マシン、コンテナーで使用されるキャッシュの量を制御するようにソフトウェアをプログラムできます。キャッシュセグメントを分離して、リソースの共有問題に対処できます。次の 2 つの方法があります。
- MSR を直接設定します。詳細は、『Intel® 64 and IA-32 Architectures Software Developer’s Manual、Volume 3 (3A, 3B, 3C & 3D): System Programming Guide』 (英語) のセクション 17.19 を参照してください。
- CPU リソース割り当てのカーネル・インターフェイス、Resource Control (resctrl) (英語) を使用します。
この例では、resctrl を使用して次のように割り当てます。
- 1 つのキャッシュセグメントを cpu_3 に割り当てます。
- 7 つのキャッシュセグメントを cpu_2 に割り当てます。
#set '00000001' Capacity Bit Mask for CORE 3 mkdir /sys/fs/resctrl/clos0 echo 8 > /sys/fs/resctrl/clos0/cpus echo 'L2:1=1' > /sys/fs/resctrl/clos0/schemata #set '11111110' CBM for rest CORE echo 'L2:1=fe' > /sys/fs/resctrl/schemata
メモリーアクセス解析を再度実行する収集が完了したら、[Bottom-up (ボトムアップ)] ペインを確認します。
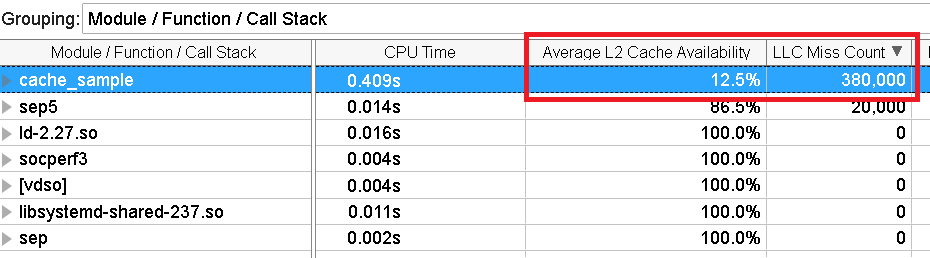
キャッシュの一部 (12.5%) が排他的に利用できるようになりました。しかし、キャッシュミスの数にはまだ改善の余地があります。
アプリケーションに割り当てるキャッシュを増やして、再度解析を実行してみましょう。キャッシュ割り当てを 50% または 4 セグメントに増やします。
#set '00001111' Capacity Bit Mask for CORE 3 mkdir /sys/fs/resctrl/clos0 echo 8 > /sys/fs/resctrl/clos0/cpus echo 'L2:1=f' > /sys/fs/resctrl/clos0/schemata #set '11110000' CBM for rest CORE echo 'L2:1=f0' > /sys/fs/resctrl/schemata
[Bottom-up (ボトムアップ)] ペインを確認すると、キャッシュ割り当てを増やしたことでキャッシュミスの数が大幅に低下していることが分かります。しかし、この結果は、利用可能なキャッシュ全体の半分をアプリケーションに排他的に割り当てるという大きな代償を払うことにより得られたものです。
別の解決策として、「擬似ロック」を使用する方法があります。擬似ロックは、同じキャッシュを使用しようとするほかのプロセスによるキャッシュデータの退避を防ぐのに役立ちます。RTA は、重要なデータをキャッシュの特別なセグメントに割り当てて、別のスレッド、プロセス、コアによる使用からデータを保護することができます。セグメントが非表示の間も、セグメントのデータにアクセスできます。
#Create the pseudo-locked region with 1 cache segment mkdir /sys/fs/resctrl/demolock echo pseudo-locksetup > /sys/fs/resctrl/demolock/mode echo 'L2:1=0X1' > /sys/fs/resctrl/demolock/schemata cat /sys/fs/resctrl/demolock/mode pseudo-locked
struct timespec sleep_timeout =
(struct timespec) { .tv_sec = 0, .tv_nsec = 10000000 };
...
/* buffer=malloc(128*1024); */
open("/dev/pseudo_lock/demolock",0_RDWR);
buffer=mmap(0,128*1024,PROT_READ|PROT_WRITE,MAP_SHARED,dev_fd,0);
...
run_workload(buffer,128*1024);
void run_workload(void *start_addr,size_t size) {
unsigned long long i,j;
for (i=0;i<1000;i++)
{
nanosleep(&sleep_timeout,NULL);
for (j=0;j<size;j+=32)
{
asm volatile("mov(%0,%1,1),%%eax"
:
:"r" (start_addr),"r"(i)
:"%eax","memory");
}
}
}
解析を再度実行します。[Bottom-up (ボトムアップ)] ペインを開いて結果を確認します。

システムの 1 つのセグメントをロックするだけで、「すべての」キャッシュミスを解決するのに役立ちました。
キャッシュ・アロケーション・テクノロジーは、サイズに関係なく、(メモリーアクセスにより引き起こされる) 小さなレイテンシーが重要なリアルタイム環境やワークロードで非常に役立ちます。このレシピで説明したように、キャッシュミスがゼロになるまで、段階的にキャッシュセグメントを割り当ててください。
注
このレシピの情報は、アナライザー・デベロッパー・フォーラム (英語) を参照してください。
関連情報
マイクロアーキテクチャー全般解析
メモリーアクセス解析
キャッシュ・アロケーション・テクノロジー (CAT) の概要 (英語)
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのトップに戻る
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
