

この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Analyzing Hot Code Paths Using Flame Graphs」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2021 (最終更新日: 2021 年 12 月 27 日)
このレシピでは、フレームグラフを使用して、Java* ワークロードのホットスポットとホットなコードパスを特定する方法を説明します。
コンテンツ・エキスパート: Dmitry Kolosov (英語)、Roman Khatko (英語)、Elena Nuzhnova (英語)
フレームグラフは、アプリケーションのスタックとスタックフレームを視覚的に表現したものです。このグラフは、X 軸にアプリケーションのすべての関数をプロットし、Y 軸にスタックの深さを表示します。関数は古い順にスタックに追加され、親関数は子関数の直下に配置されます。グラフに表示される関数の幅は、その関数が CPU を使用した時間の長さを示しています。そのため、アプリケーションで最もホットな関数は、フレームグラフで最も幅の広い部分を占めます。
フレームグラフは、以下のワークロードでスタックを含むホットスポット解析を実行する際に使用できます。
- C++
- FORTRAN
- Java*
- .NET
- Python*
このレシピでは、Java* を使用して説明します。一般的に、Java* 仮想マシン (JVM) のパラメーターの選択が不適切な場合 (最適でないか、間違っている)、アプリケーションのパフォーマンスが低下することがあります。このパフォーマンスの低下は、解析で明確にならなかったり、原因が明らかでないことがあります。フレームグラフでアプリケーション・スタックを可視化することで、アプリケーションとスタックが混在 (Java* と組込み) したホットパスの特定が容易になる場合があります。
使用するもの
以下は、このレシピで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: SPECjbb2015* (英語) ベンチマーク。このベンチマークは、Java* サーバーのパフォーマンスに関心がある、以下のような方を対象としています。
- JVM ベンダー
- ハードウェア開発者
- Java* アプリケーション開発者
- 研究者、学術関係者
- OpenJDK11 (英語)。Java Community Process の JSR384 (英語) で定義されている Java* SE バージョン 11 のオープンソースのリファレンス実装です。
- パフォーマンス解析ツール: インテル® VTune™ プロファイラー 2021.7 以降の hotspots 解析
注:
- バージョン 2020 から、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。
- インテル® VTune™ プロファイラー・パフォーマンス解析クックブックの大部分のレシピは、異なるバージョンのインテル® VTune™ プロファイラーにも適用できます。バージョンにより、わずかな調整が必要になる場合があります。
- 最新バージョンのインテル® VTune™ プロファイラーは以下から入手できます。
- オペレーティング・システム: Ubuntu* 18.04.1 LTS
- CPU: インテル® Xeon® Gold 6252 プロセッサー (開発コード名 Cascade Lake)
ベースラインの作成
- 最初に、このレシピの目的に合わせて SPECjbb2015 の実行時間を短くします。config/specjbb2015.props ファイルで以下のプロパティーを変更します。
specjbb.input.number_customers=1 specjbb.input.number_products=1
- 一般的な最適化の手法とガイダンスに従って、JVM オプションの -XX:+UseParallelOldGC と -XX:-UseAdaptiveSizePolicy でアプリケーションの最適化を開始します。
- Java* アプリケーションのパフォーマンスを最適化するため、以下のパラメーターをチューニングします。
- ガベージ・コレクション (GC) アルゴリズム – UseParallelOldGC オプションを有効にすると、古い世代のコレクションと若い世代のコレクションを並列に収集できます。これにより、全体的に GC 一時停止が減少し、ガベージ・コレクションが効率良く動作します。スループットが重要な場合は -XX:+UseParallelOldGC を指定します。
- ヒープ・チューニング – デフォルトでは、JVM は実行時のヒューリスティックに基づいてヒープを適応させます。一時停止、スループット、フットプリントの目標を達成するため、GC は GC 統計に基づいてヒープ世代のサイズを変更できます。場合によっては、スループットを向上するため、このオプションを無効にして、ヒープサイズを手動で設定するとよいでしょう。ヒープをパフォーマンス・メトリックとして、さらなる最適化に役立てることができます。
java -XX:-UseAdaptiveSizePolicy -XX:+UseParallelOldGC -jar specjbb2015.jar –m COMPOSITE
hotspots 解析の実行
- インテル® VTune™ プロファイラー 2021.7 以降を実行します。
- [Welcome (ようこそ)] 画面で [Configure Analysis (解析の設定)] をクリックします。
- [WHERE (どこを)] ペインでは、[Local Host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [WHAT (何を)] ペインでは、以下の値を入力します。
- [Application (アプリケーション)]: java
- [Application parameters (アプリケーション・パラメーター)]: -XX:-UseAdaptiveSizePolicy -XX:+UseParallelOldGC -jar specjbb2015.jar -m COMPOSITE
- [HOW (どのように)] ペインでは、解析ツリーを開き、[Algorithm (アルゴリズム)] グループの [Hotspots] 解析を選択します。
- [Hardware Event-Based Sampling (ハードウェア・イベントベース・サンプリング)] モードを選択して、[Collect stacks (スタックの収集)] オプションをオンにします。
- [Start (開始)] ボタンをクリックして、解析を実行します。
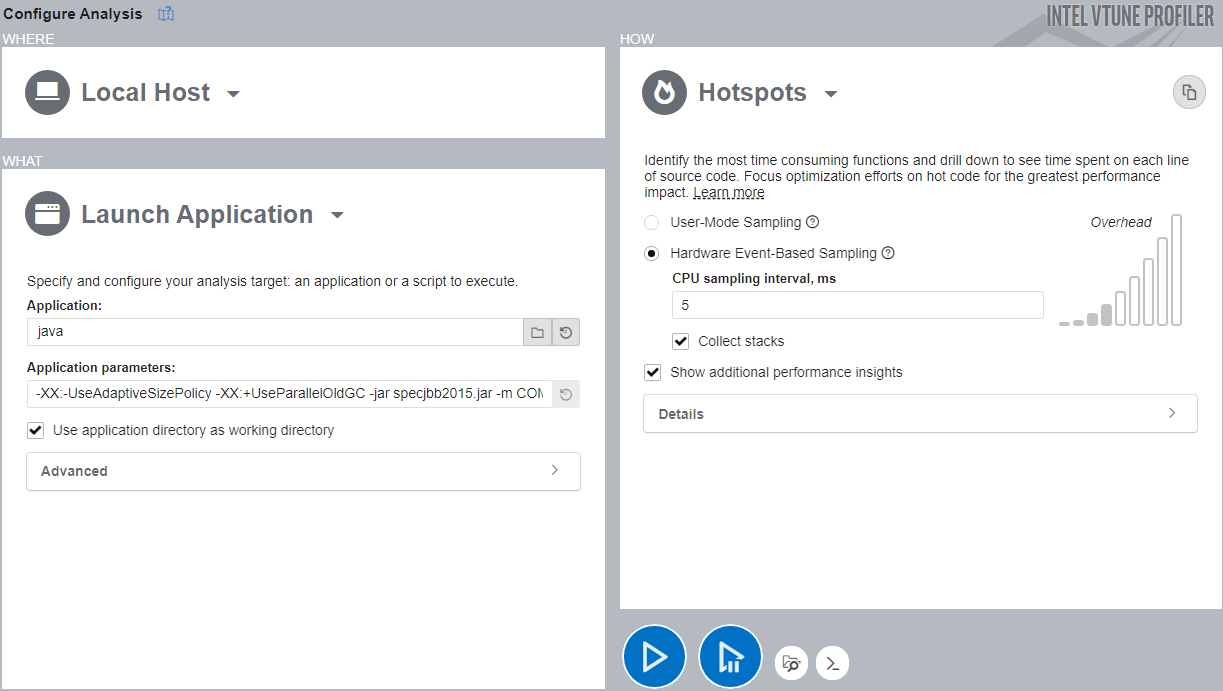
インテル® VTune™ プロファイラーは、Java* アプリケーションをプロファイルしてデータを収集します。処理が完了すると、インテル® VTune™ プロファイラーは収集データをファイナライズしてシンボル情報を解決します。
hotspots 情報の解析
アプリケーションの実行に関する高レベルの統計を確認できる [Summary (サマリー)] ウィンドウから解析を開始します。[Elapsed Time (経過時間)] と [Top Hotspots (上位のホットスポット)] セクションに注目します。
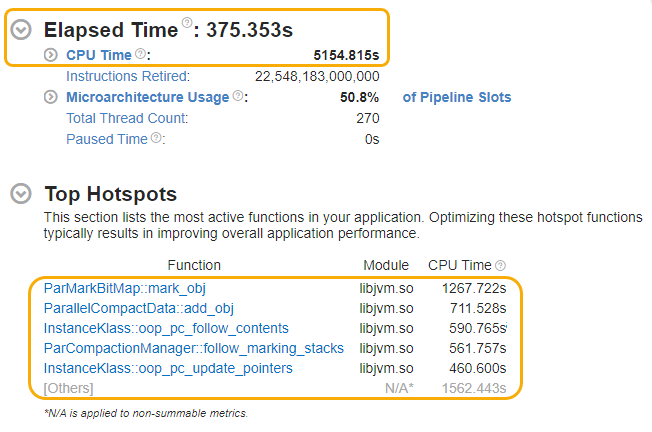
この例では、SPECjbb2015 の経過時間は約 375 秒です。
上位 5 つの hotspots は JVM 関数内にあり、Java*/アプリケーション関数は見当たりません。
次に、[Bottom-up (ボトムアップ)] ウィンドウを確認して、hotspots の調査を継続します。
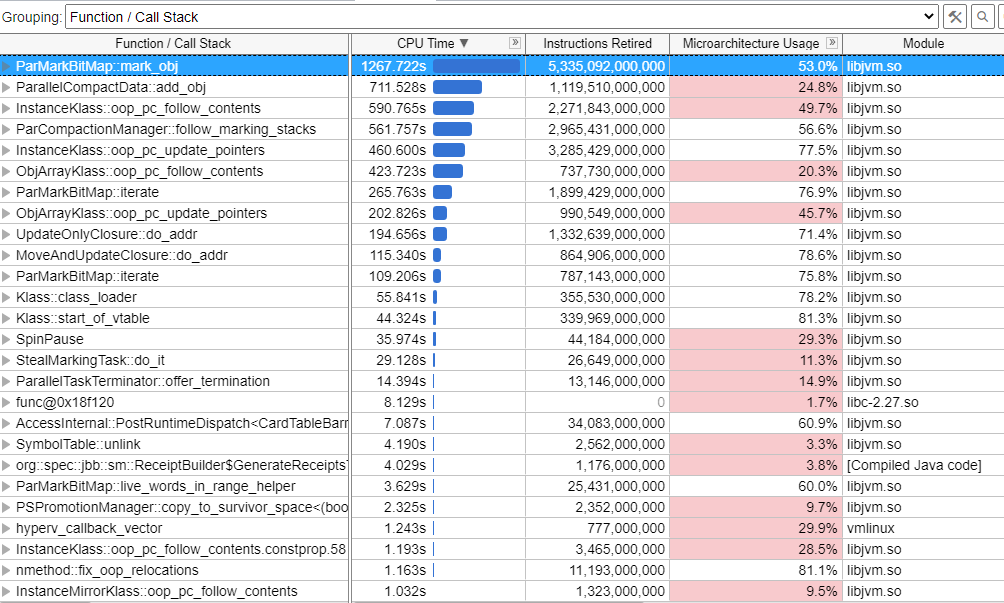
このデータのフレームグラフを見てみましょう。すべてのアプリケーション・スタックを一度に確認し、ホットなコードパスを特定できるかもしれません。
フレームグラフでのホットなコードパスの特定
[Flame Graph (フレームグラフ)] ウィンドウに切り替えます。
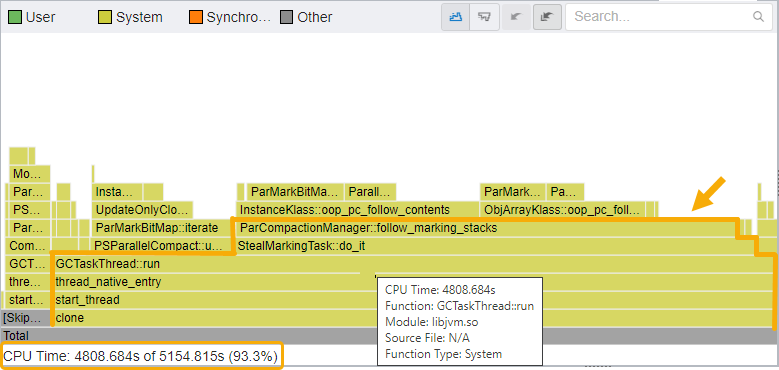
フレームグラフ (英語) は、アプリケーションのスタックとスタックフレームを視覚的に表現します。グラフ中の各ボックスは、スタックフレームを表しており、関数の完全な名前が表示されています。横軸はスタックのプロファイルを示し、アルファベット順にソートされています。縦軸はスタックの深さを示し、1 番下の 0 から始まります。フレームグラフでは、タイムライン・データは表示されません。グラフ中の各ボックスの幅は、合計 CPU 時間に対する関数の CPU 時間の割合を示します。関数の総時間には、関数とそのすべての子 (呼び出し先) の処理時間が含まれます。
[Flame Graph (フレームグラフ)] ウィンドウには [Call Stacks (コールスタック)] ビュー (英語) があり、フレームグラフで選択すると最もホットなスタックが表示されます。また、関数を選択することでほかのスタックを観察したり、ソースコードにドリルダウンできます。
フレームグラフに表示される関数の種類
フレームグラフでは、これらの関数を色分けして表示しています。
| 関数の種類 | 説明 |
|---|---|
| ユーザー | ユーザーのアプリケーション・モジュールの関数 |
| システム | システムまたはカーネルモジュールの関数 |
| 同期 | スレッド・ライブラリー (OpenMP* のバリアなど) の同期関数 |
| オーバーヘッド | スレッド・ライブラリー (OpenMP* のフォークやディスパッチャーなど) のオーバーヘッド関数 |
以下の手法に従って、フレームグラフに表示される情報を調査します。
- 最下部から開始し、上へ進みます。フレームグラフの幅が広いホットな関数に注目します。
- この例では、JVM のスタックと関数のみがフレームグラフに表示されます。そのため、CPU 時間のほとんどが JVM に費やされています。
- その結果、アプリケーションに費やされた CPU 時間は非常に少なく、フレームグラフでアプリケーションのスタックやフレームを確認することはできません。
- 最もホットなコードパスは、clone –> start_thread –> thread_native_entry –> GCTaskThread::run –> StealMarkingTask::do_it –> です。
- Java* ガベージコレクターのタスクを実行する GCTaskThread::run 関数/フレームに注目します。
- GCTaskThread::run 関数/フレームにホバーすると、下部に表示される詳細から、CPU 時間の 93.3% がこの関数とその呼び出し先に費やされていることが分かります。
つまり、多くの CPU 時間が Java* ガベージコレクターに費やされています。
JVM オプションの変更
JVM オプションの -XX:-UseAdaptiveSizePolicy では、アプリケーションが JVM ヒープのサイズに適応できないことがあります。実行に使用されるデフォルト値が十分ではない場合もあります。JVM ヒープのサイズを変更して、ガベージコレクター (GC) の実行時間を短くします。
-Xms オプションと -Xmx オプションを使用して、JVM がヒープサイズを変更できる動作範囲を設定します。2 つの値が同じ場合、ヒープサイズは一定に保たれます。これらのオプションに値を設定する前に、JVM ログを参照すると良いでしょう。
アプリケーションの -Xms オプションと -Xmx オプションをそれぞれ 2GB と 4GB に変更して、新しいプロファイルを収集します。
- インテル® VTune™ プロファイラーの [Welcome (用こそ)] 画面で [Configure Analysis (解析の設定)] ボタンをクリックします。
- [WHERE (どこを)] ペインでは、[Local Host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [WHAT (何を)] ペインでは、[Application (アプリケーション)] を java に設定します。
- アプリケーション・パラメーターを変更します。-Xms2g -Xmx4g -XX:-UseAdaptiveSizePolicy -XX:+UseParallelOldGC -jar specjbb2015.jar -m COMPOSITE を使用します。
- [Start (開始)] をクリックして、解析を開始します。
データ収集が完了したら、[Summary (サマリー)] ウィンドウで [Elapsed Time (経過時間)] と [Top Hotspots (上位のホットスポット)] を確認します。
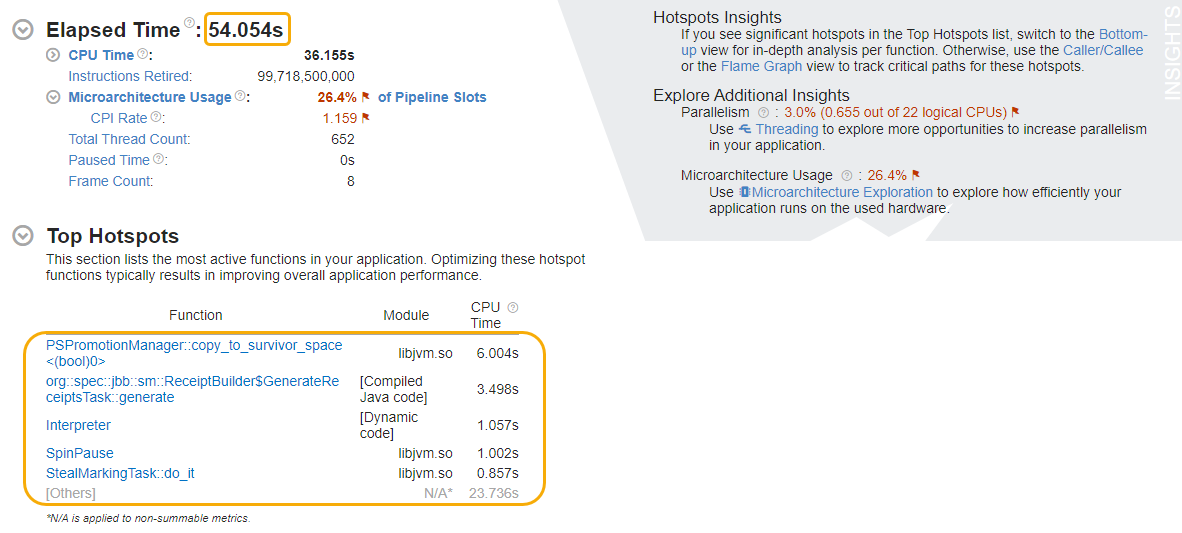
- [Elapsed Time (経過時間)] が 1/6 になり、375 秒から 54 秒に短縮されたことが分かります。
- [Top Hotspots (上位のホットスポット)] セクションには、CPU 時間が短くなった関数 (GenerateReceipts タスクを含む) の新しいリストも表示されています。
[Flame Graph] ウィンドウに切り替えて、新しいホットなコードパスを特定します。
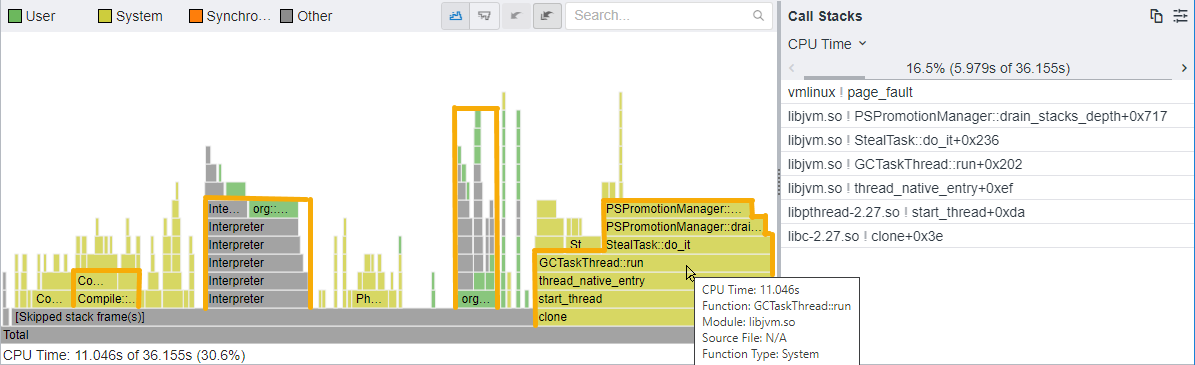
フレームグラフでは、JVM GCTaskThread を含むホットなコードパスを確認できます。
しかし、このホットなコードパスは [CPU Time (CPU 時間)] の 30.6% しか使用していません (以前は 93.3% でした)。
次のステップ
- 以下の新しいホットなコードパスに注目すると良いでしょう。
- JVM Compile::Compile —> …
- JVM Interpreter —> org::spec::jbb::sm::ReceiptBuilder
- org::spec::jbb::sm::ReceiptBuilder —> …
- より多くの最適化の機会を特定できるように、JVM オプションを見直します。
- 次に JVM を最適化する場合は、開始点として [Microarchitecture Usage (マイクロアーキテクチャー利用率)] メトリックに注目して、[Summary (サマリー)] ウィンドウの [Insights (詳細)] セクションにある推奨事項に従います。
- スレッド化によりアプリケーションの並列性を高めます。
- [Microarchitecture Exploration (マイクロアーキテクチャー全般)] 解析を実行して、使用するハードウェア上でのアプリケーション実行の効率を調査します。
関連情報
ウィンドウ: フレームグラフ (英語)
hotspots ビュー (英語)
フレームグラフの説明 (英語)
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのトップに戻る
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
