
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Improving Hotspot Observability in a C++ Application Using Flame Graphs」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2022
更新日: 2022 年 2 月 28 日
テンプレート関数や長い関数名に隠れて真の hotspot が観測できないシナリオで、インテル® VTune™ プロファイラーのフレームグラフ機能がどのように役立つかを紹介します。
コンテンツ・エキスパート: Dmitry Kolosov (英語)、Roman Khatko (英語)
フレームグラフは、インテル® VTune™ プロファイラーの Hotspots 解析の機能で、アプリケーションの実行パスを直感的なグラフ形式で表示します。
[Summary (サマリー)] タブの [Top Hotspots (上位のホットスポット)] セクションや [Bottom-up (ボトムアップ)] ウィンドウで hotspot を見つけるのが困難なことがあります。以下にいくつかの例を示します。
- hotspot が均一の場合や、複数の hotspot があり CPU 時間がそれらの hotspot に均等に分散している場合
- アクション可能な hotspot がない場合
- スタック上にライブラリー関数呼び出し (STL、Boost、MKL など) があり、その呼び出し元が簡単に見つからない場合
- テンプレート関数名が長く複雑な場合
このような場合、フレームグラフは、すべてのアプリケーション・スタックの観測性を高めることで、真の hotspot やホットなコードパスの特定を支援します。この観測性の向上により、複雑なスタックを持つアプリケーションを解析する時間と労力を軽減できます。
この機能は、以下に示す Hotspots 解析でサポートされている言語で記述されたワークロードをサポートします (ただし、これらに限定されるものではありません)。
- C++
- FORTRAN
- Java*
- .NET
- Python*
このレシピでは、特に実際の hotspot が不明瞭な場合や複数の hotspot がある場合に、フレームグラフを使用してコード内のホットなパスをより簡単に特定する方法を説明します。
注
Java* の最適化に興味がある方は、「フレームグラフを使用してホットなコードパスを解析する」レシピを参照してください。このレシピでは、フレームグラフを使用して、パフォーマンスを低下させる最適でない JVM 構成を検出する方法を紹介しています。
- 使用するもの
- 手順
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアです。
- アプリケーション: C++ STL/Boost ベースのサンプル。
Boost は、線形代数、疑似乱数生成、マルチスレッドなどのタスクや構造をサポートする C++ ライブラリー群です。
この例では、Windows* 向けの Boost 1.77.0 を使用しています (ソース (英語) またはバイナリー (英語) をダウンロード)。
- パフォーマンス解析ツール: インテル® VTune™ プロファイラー 2021.9 — Hotspots 解析
- オペレーティング・システム: Microsoft* Windows Server* 2016
- IDE: Microsoft* Visual Studio* 2017
- CPU: インテル® Xeon® プロセッサー E5-2695 v3 (開発コード名 Haswell)
プロジェクトを設定してサンプルをビルドする
最初に、パフォーマンスのベースラインを測定するため、以下のサンプル・アプリケーションをビルドして解析します。
以下のサンプルコードは、サービススレッドでランダムに生成された長文テキスト (1 億語) を単語単位に分割します。このコードには、異なる方法で処理する 4 つのタスクの実装が含まれています。
| 実装 | ユーザー関数 | ベース |
|---|---|---|
| 1 | splitByWordsBoost | boost::split |
| 2 | splitByWordsStdString | std::string::find と std::string::substr |
| 3 | splitByWordsStdStringView | std::string_view::find、std::string_view::substr、および string_view の std::vector |
| 4 | splitByWordsStdStringView | 事前に割り当てられた出力ベクトル |
各実装は実行時にコマンドライン・パラメーターで選択できます。このレシピでは、異なる実装を切り替えて、パフォーマンスがどのように変化するかを解析します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 | #include <iostream>#include <vector>#include <chrono>#include <thread>#include <string_view>#include <boost/algorithm/string.hpp>using namespace std::chrono;void generateRandomText(std::string& text, const size_t words, const size_t symbolsInWord){ for (size_t i = 0; i < words; i++) { for (size_t j = 0; j < symbolsInWord; j++) { text += 'a' + i % 26; } text += ' '; }}void splitByWordsBoost(const std::string& text, std::vector<std::string>& splitWords){ boost::split(splitWords, text, boost::is_any_of(" "));}void splitByWordsStdString(const std::string& text, std::vector<std::string>& splitWords){ const char delimiter = ' '; size_t start, end = 0; while ((start = text.find_first_not_of(delimiter, end)) != std::string::npos) { end = text.find(delimiter, start); splitWords.push_back(text.substr(start, end - start)); }}void splitByWordsStdStringView(const std::string& text, std::vector<std::string_view>& splitWords){ const char delimiter = ' '; size_t start, end = 0; std::string_view textView(text); while ((start = textView.find_first_not_of(delimiter, end)) != std::string::npos) { end = textView.find(delimiter, start); splitWords.emplace_back(textView.substr(start, end - start)); }}int main(int argc, char** argv){ int splitMode = 0; const char* msg = "splitByWordsBoost"; if (argc > 1) { switch (*argv[1]) { case '2': splitMode = 1; msg = "splitByWordsStdString"; break; case '3': splitMode = 2; msg = "splitByWordsStdStringView"; break; case '4': splitMode = 3; msg = "splitByWordsStdStringView(pre-allocated vector)"; break; } } const size_t numOfWords = 100000000, symbolsInWord = 10; std::string text; text.reserve(numOfWords * (symbolsInWord+1)); std::cout << "Generating random text: "; auto start = high_resolution_clock::now(); generateRandomText(text, numOfWords, symbolsInWord); auto stop = high_resolution_clock::now(); std::cout << duration_cast<duration<float>>(stop - start).count() << " seconds" << std::endl; std::vector<std::string> splitWords; std::vector<std::string_view> splitWordsView; if (splitMode == 3) splitWordsView.reserve(numOfWords); std::cout << msg << " function: "; std::thread thread; start = high_resolution_clock::now(); switch (splitMode) { case 0: thread = std::thread(splitByWordsBoost, std::ref(text), std::ref(splitWords)); break; case 1: thread = std::thread(splitByWordsStdString, std::ref(text), std::ref(splitWords)); break; case 2: case 3: thread = std::thread(splitByWordsStdStringView, std::ref(text), std::ref(splitWordsView)); break; } thread.join(); stop = high_resolution_clock::now(); std::cout << duration_cast<duration<float>>(stop - start).count() << " seconds" << std::endl; auto splitWordsSize = splitMode >= 2 ? splitWordsView.size() : splitWords.size(); std::cout << "Split words: " << splitWordsSize << std::endl;} |
コードは、[コンソール アプリ] や [空のプロジェクト] など、Visual Studio* 2017 で新しく作成した C++ プロジェクト、または C++17 をサポートする新しいバージョンの Visual Studio* にコピーして使用することができます。
このサンプルは Boost ライブラリーを使用するため、追加の設定が必要です。
注
プロジェクトのプロパティーを編集したり、アプリケーションをコンパイルするには、[構成] が [Release] に設定され、[プラットフォーム] が [x64] に設定されていることを確認します。
以下の手順に従って、Visual Studio* でプロジェクトを設定します。
- [ソリューション エクスプローラー] でプロジェクトを右クリックして、[プロパティ] を選択します。
- [プロジェクト プロパティ ページ] ウィンドウで、[構成] ドロップダウンが [Release] に設定され、[プラットフォーム] が [x64] に設定されていることを確認します。
- [VC++ ディレクトリ] ページで、[インクルード ディレクトリ] に Boost のルート・ディレクトリーを追加します。
- [VC++ ディレクトリ] ページで、[ライブラリ ディレクトリ] に Boost ライブラリーのディレクトリーを追加します。
デフォルトでは以下にあります。
<boost-root-directory>\libs
- [C/C++] > [言語] ページで、[C++ 言語標準] オプションが [ISO C++17 標準 (/std:c++17)] に設定されていることを確認します。
これで、設定は完了です。
注
Boost ライブラリーがインストールされており、C++17 をサポートするコンパイラーがあれば、Linux* 上でもサンプルコードのビルドとチューニングが可能です。Linux* 上でサンプルコードをビルドするには、次のコマンドを使用します。
1 | g++ -Wall -O2 -g -pthread -std=c++17 -l <path-to-boost-dir> ConsoleApplication1.cpp -o ConsoleApplication1 |
Release x64 構成でプロジェクトをビルドします。コンパイル後は、<option> パラメーターで異なるアルゴリズムの実装を選択できます。
>ConsoleApplication1.exe <option>
<option> に設定可能な値は、1、2、3、または 4 です。
パラメーターを指定しない場合、デフォルトで 1 が選択されます。そのため、最初のステップでは、次のようにパラメーターを指定せずにアプリケーションを実行します。
>ConsoleApplication1.exe
パフォーマンスのベースラインを測定する
次のステップでは、boost::split 関数ベースの最初の実装を使用したアプリケーションでインテル® VTune™ プロファイラーの Hotspots 解析を実行します。この解析結果をパフォーマンスのベースラインとし、以降の最適化と比較します。
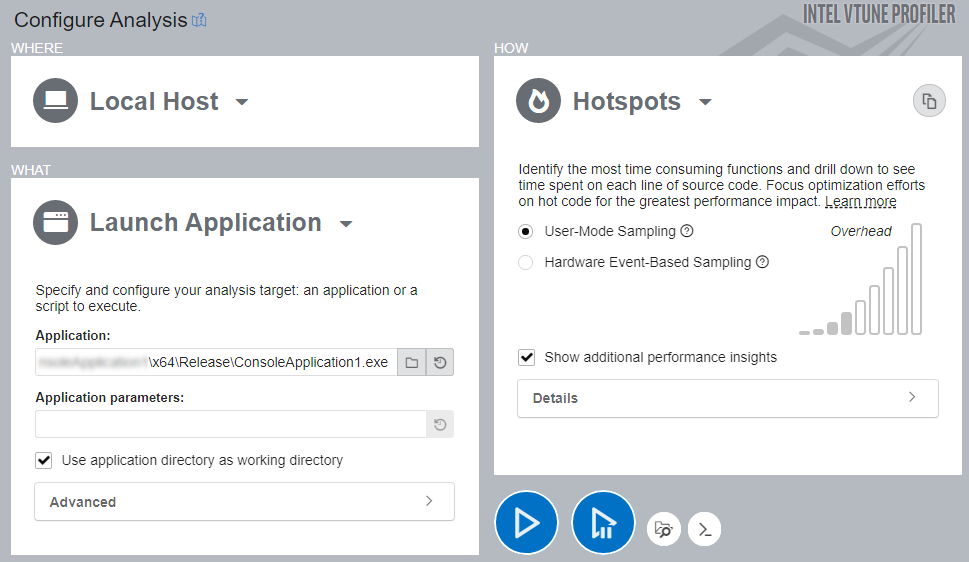
インテル® VTune™ プロファイラーを実行して、解析を開始します。
- ツールバーの [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクト名 (例: split_string) を指定します。
- [Create Project (プロジェクトの作成)] をクリックします。
[Configure Analysis (解析の設定)] ウィンドウが表示されます。
- [WHERE (どこを)] ペインで、[Local Host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [WHAT (何を)] ペインで、[Launch Application (アプリケーションを起動)] モードを選択します。
- [Application (アプリケーション)] テキストボックスで、ビルドしたアプリケーション・バイナリーのパスを指定します。
- [HOW (どのように)] ペインで、[Hotspots] 解析を選択します。
- [Start (開始)] をクリックして、解析を開始します。
インテル® VTune™ プロファイラーはアプリケーションを起動して、結果をファイナライズする前に必要なすべてのデータを収集します。
ここで使用するシステムでは、アプリケーションの合計実行時間は 17 秒です。
[Summary (サマリー)] ウィンドウと [Bottom-up (ボトムアップ)] ウィンドウで hotspot 結果を解析する
アプリケーション・パフォーマンスに関する高レベルの情報を確認できる [Summary (サマリー)] ウィンドウから調査を開始します。
[Elapsed Time (経過時間)] と、ホットな関数の降順リストを含む [Top Hotspots (上位の hotspot)] セクションに注目します。
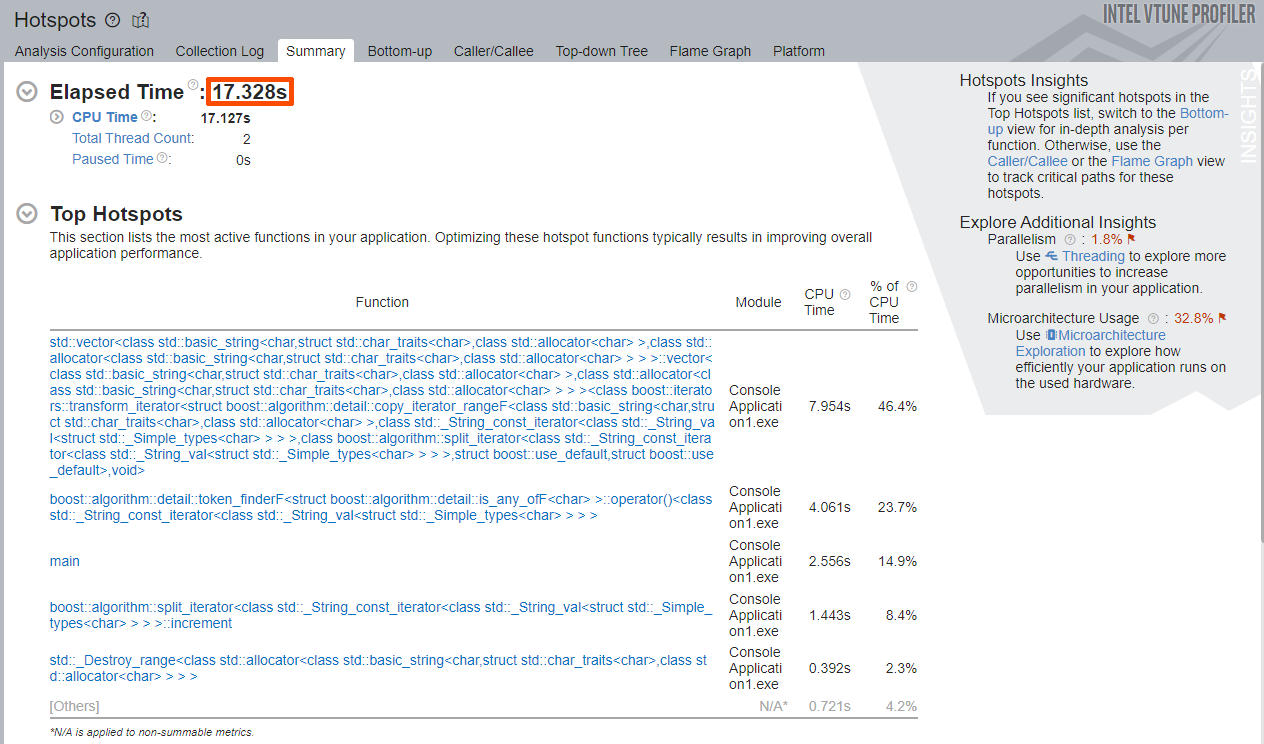
サンプル・アプリケーションの [Elapsed Time (経過時間)] は約 17 秒です。
[Top Hotspots (上位の hotspot)] は、以下のとおりです。
| std::vector テンプレート | CPU 時間の 46.4% |
| boost::algorithm::detail::token_finderF テンプレート | CPU 時間の 23.7% |
| main 関数 | CPU 時間の 14.9% |
| boost::algorithm::split_iterator テンプレート | CPU 時間の 8.4% |
splitByWordsBoost 関数や boost::split 関数がリストにありません。[Top Hotspots (上位の hotspot)] リストにはテンプレート関数と main 関数しかないため、これらの関数を最適化しても意味がありません。真の hotspot は、テンプレート関数によって隠されている可能性があります。
[Bottom-up (ボトムアップ)] ウィンドウで hotspot を探してみましょう。[Bottom-up (ボトムアップ)] ウィンドウに切り替えて、注目する splitByWordsBoost 関数と boost::split 関数に関連する hotspots を調査します。
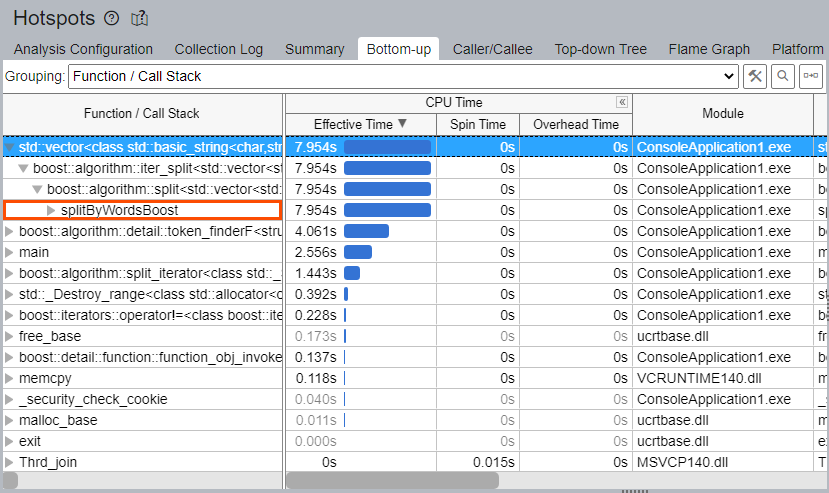
[Bottom-up (ボトムアップ)] ウィンドウには、より多くの関数や hotspot が表示されていますが、splitByWordsBoost 関数と boost::split 関数はリストの上位にはありません。対象の関数と特定された hotspot の関係は明らかではありません。
std::vector と boost::algorithm::split の呼び出し元を展開すると、splitByWordsBoost 関数は 3 ~ 4 階層目にあり、[Elapsed Time (経過時間)] の合計である 17.328 秒のうち、7.954 秒 (CPU 時間の 46.4%) であることが分かります。
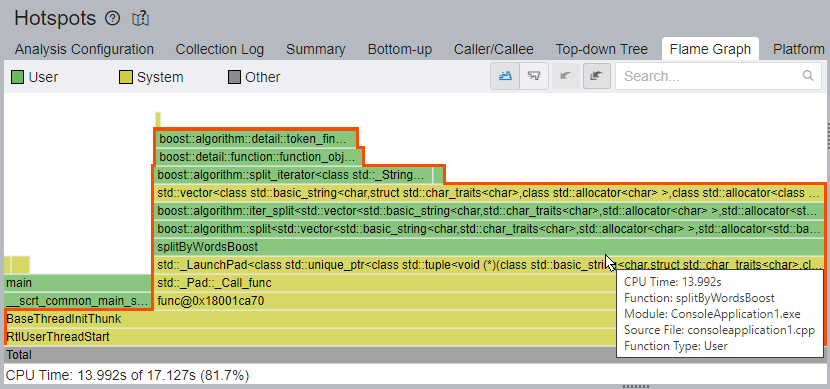
このように hotspot が呼び出し先のテンプレート関数によって見えなくなっている場合、[Flame Graph (フレームグラフ)] を使用することで、不要な推測や労力を排除して、ホットな関数間の関係を把握できる可能性があります。
[Flame Graph] ウィンドウを開いて、すべてのアプリケーション・スタック、フレーム、およびホットなコードパスを調査します。
フレームグラフでホットなコードパスを特定する
フレームグラフ (英語) は、アプリケーションのスタックとスタックフレームを視覚的に表現します。グラフ中の各ボックスは、スタックフレームを表しており、完全な関数名が表示されています。横軸はスタックのプロファイルを示し、アルファベット順にソートされています。縦軸はスタックの深さを示し、1 番下の 0 から始まります。
フレームグラフでは、タイムライン・データは表示されません。グラフ中の各ボックスの幅は、合計 CPU 時間に対する関数の CPU 時間の割合を示します。関数の総時間には、関数とそのすべての子 (呼び出し先) の処理時間が含まれます。
注
フレームグラフ全般の詳細や背景については、フレームグラフの開発者である Brendan Gregg の記事 (https://www.brendangregg.com/flamegraphs.html) を参照してください。
最下部から開始し、上へ進みます。最初に、ホットな (幅の広い) 関数に注目します。
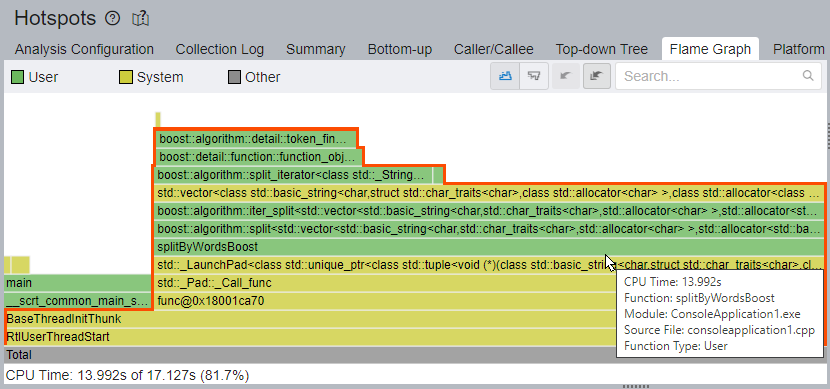
このアプリケーションでは、フレームグラフは splitByWordsBoost 関数と boost::algorigthm::split 関数を経由して、std::vector フレームと boost テンプレート・フレームに到達するホットなコードパスを明確に示しています。splitByWordsBoost 関数とその呼び出し先は、全 CPU 時間のうち 13.992 秒 (81.7%) を費やしています。
フレームグラフは、[Timeline (タイムライン)] ペインや [Filter (フィルター)] ツールバーと連動しており、時間領域、プロセス、スレッドなどでデータをフィルター処理できます。[Timeline (タイムライン)] ペインには、メインとサービスという 2 つのアプリケーション・スレッドが表示されます。splitByWordsBoost 関数はサービススレッドで動作するため、[Filter By Thread (スレッドでフィルター)] ドロップダウンを使用してサービススレッドでデータをフィルター処理すると、フレームグラフの表示が見やすくなります。この例では、func@0x18001ca70 (TID:22200) がサービススレッドです。
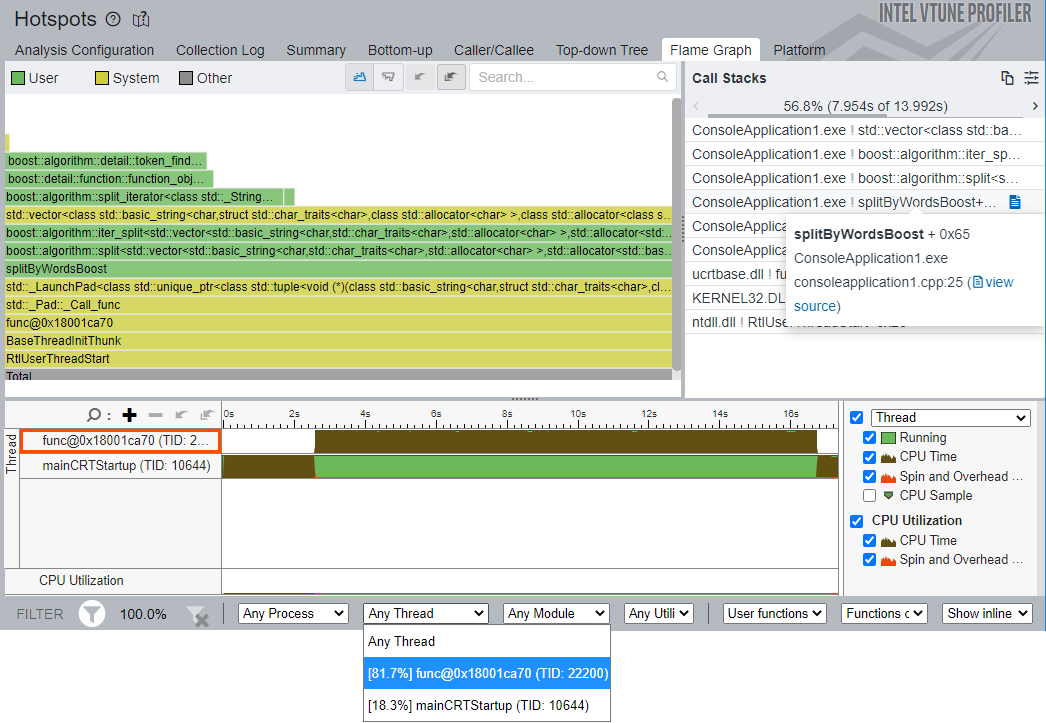
右側の [Call Stacks (コールスタック)] ペインは、フレームグラフ上の選択/ズームに応じて、選択されている関数を通過するフレームを含むスタックを表示します。[Call Stacks (コールスタック)] ペインで splitByWordsBoost 関数をクリックすると、[Source (ソース)]/[Assembly (アセンブリー)] ビューにドリルダウンできます。[Source (ソース)] ビューでは、boost::split 関数に明らかな hotspot があります。
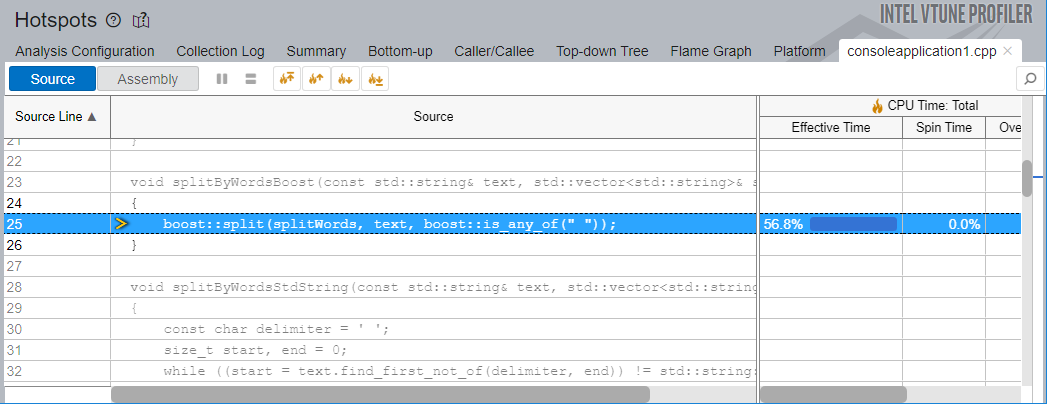
この実装には最適化が必要です。しかし、ライブラリー関数である boost::algorithm::split を最適化することはできません。そのため、std::string::find をベースにした独自の split 関数の実装を試してみましょう。
2 つ目の実装を解析する
split 関数の 2 つ目の実装のコードを解析するには、[Configure Analysis (解析の設定)] ダイアログを開き、[Application Parameters (アプリケーション・パラメーター)] フィールドに 2 を追加します。これにより、アプリケーションの 2 つ目の実装が実行されます。
[Start (開始)] をクリックして、解析を開始します。
解析が完了したら、[Summary (サマリー)] ウィンドウで [Elapsed Time (経過時間)] と [Top Hotspots (上位のホットスポット)] を確認します。
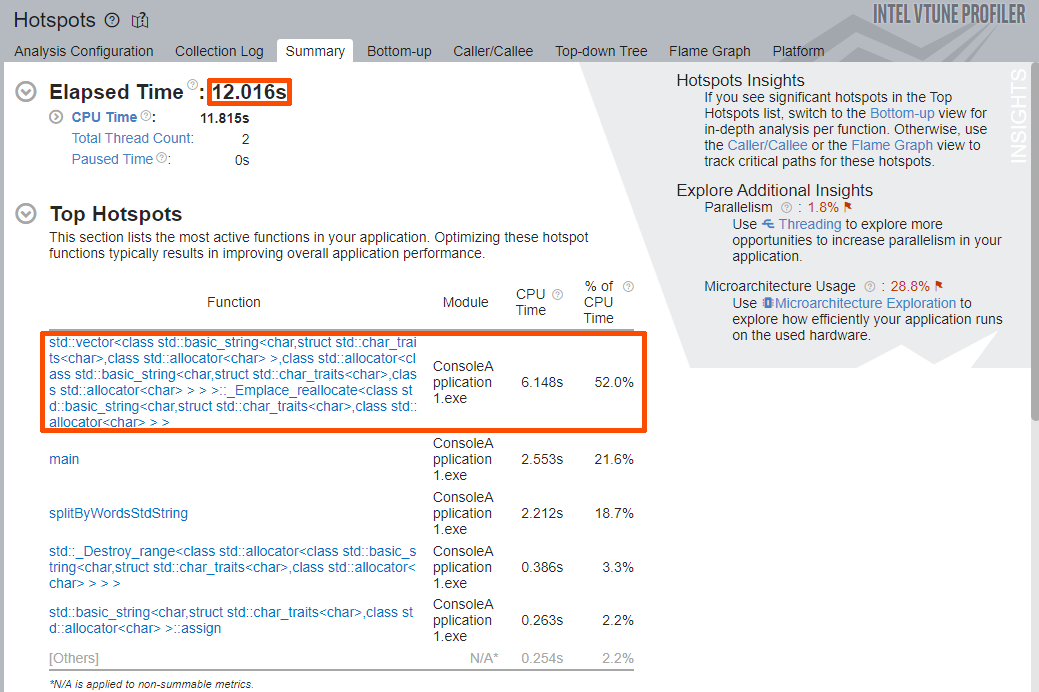
[Elapsed Time (経過時間)] は約 17 秒から約 12 秒に減りました。[Top Hotspots (上位のホットスポット)] セクションには、splitByWordsStdString アプリケーション関数を含む新しい関数リストが表示されています。
最上位の hotspot は、ベクトルの再割り当て (_Emplace_reallocate) を行う std::vector<> テンプレートと std::string オブジェクト・コンストラクターです。splitByWordsStdString 関数は、新しい std::string オブジェクトを構築したり、出力ベクトルのバッファーを再割り当てするなど、オーバーヘッドの大きい操作を行うため、これらのテンプレート関数が hotspot として表示されています。
アプリケーション・スタックの全体像を把握するため、[Flame Graph] ウィンドウに切り替えます。
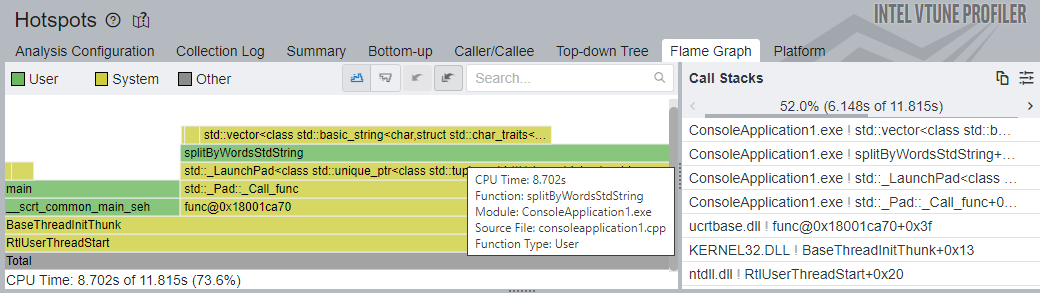
std::vector テンプレート・フレームを頂点とする、明らかなホットパスが splitByWordsStdString 関数を通過しています。splitByWordsBoost 関数とその呼び出し先は、以前の実装では全 CPU 時間のうち 13.992 秒 (81.7%) を費やしていましたが、8.702 秒 (73.6%) になりました。CPU 時間の大部分は、引き続きベクトルの再割り当てと文字列の生成に費やされています。
そのため、C++17 標準の std::string_view をベースにしたもう 1 つの実装を試してみましょう。この実装は、std::string オブジェクトの構築コストなしで std::string インターフェイスの利点を得られます。出力ベクトルには std::string_view オブジェクトが含まれます。
3 つ目の実装を解析する
split 関数の 3 つ目の実装のコードを解析するには、[Configure Analysis (解析の設定)] ダイアログを開き、[Application Parameters (アプリケーション・パラメーター)] フィールドに 3 を追加します。これにより、3 つ目の実装が実行されます。
[Start (開始)] をクリックして、解析を開始します。
解析が完了したら、[Summary (サマリー)] ウィンドウで [Elapsed Time (経過時間)] と [Top Hotspots (上位のホットスポット)] を確認します。
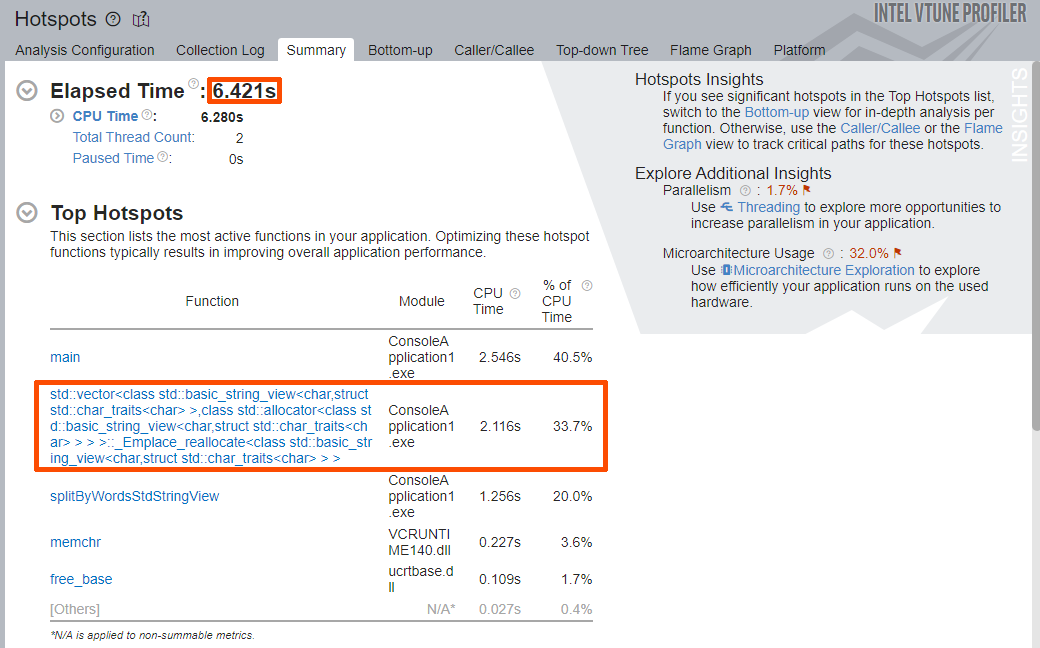
アプリケーションの [Elapsed Time (経過時間)] は約 12 秒から約 6.5 秒に減りました。
[Top Hotspots (上位のホットスポット)] セクションには、splitByWordsStdStringView アプリケーション関数を含む関数リストが表示されています。最上位の hotspot は、最適化の対象とはならない main 関数です。2 つ目の hotspot は、ベクトルの再割り当て (_Emplace_reallocate) を行う std::vector<> テンプレートです。
splitByWordsStdStingView 関数は、多くの std::string オブジェクト生成をバイパスして、string_view オブジェクトのベクトルに分割された単語を追加します。これにより、split 関数のパフォーマンスが大幅に向上しました。
アプリケーション・スタックの全体像を把握するため、[Flame Graph] ウィンドウに切り替えます。
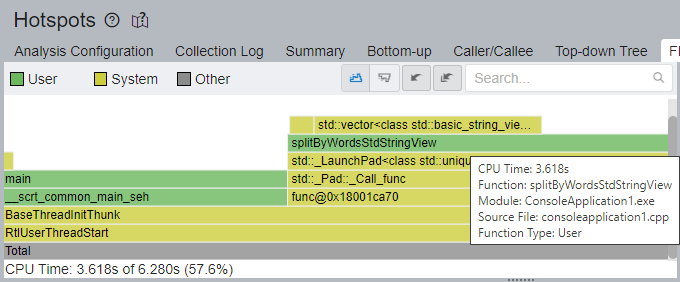
std::vector テンプレート・フレームを頂点とする、明らかなホットパスが splitByWordsStdStringView 関数を通過しています。splitByWordsStdStringView 関数とその呼び出し先は、以前の実装では全 CPU 時間のうち 8.702 秒 (73.6%) を費やしていましたが、3.618 秒 (57.6%) になりました。
std::string_view をベースにした split 関数の最後の実装を試してみましょう。この実装では、std::vector<>::reserve メソッドを使用して、事前に割り当てられた出力ベクトルを使用します。ベクトルに格納されるデータ量が予想できれば、バッファー領域をあらかじめ確保しておくことで、再割り当てを回避できます。
4 つ目の実装を解析する
split 関数の 4 つ目の実装のコードを解析するには、[Configure Analysis (解析の設定)] ダイアログを開き、[Application Parameters (アプリケーション・パラメーター)] フィールドに 4 を追加します。
[Start (開始)] をクリックして、解析を開始します。
解析が完了したら、[Summary (サマリー)] ウィンドウで [Elapsed Time (経過時間)] と [Top Hotspots (上位のホットスポット)] を確認します。
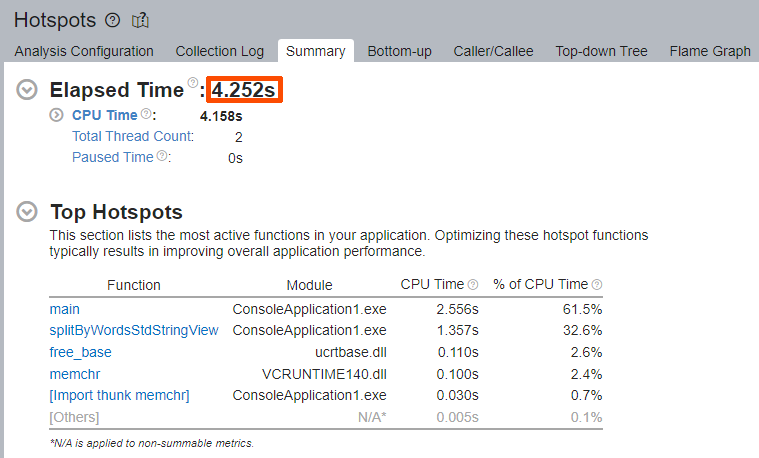
アプリケーションの [Elapsed Time (経過時間)] は約 6.421 秒から約 4.252 秒に減りました。[Top Hotspots (上位の hotspot)] に STL テンプレート関数はありません。
アプリケーション・スタックの全体像を把握するため、[Flame Graph] ウィンドウに切り替えます。
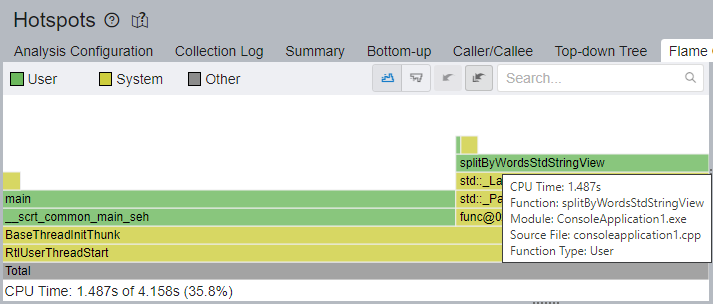
最もホットなコードパスは main 関数を通過しています。splitByWordsStdStringView 関数とその呼び出し先は、以前の実装では全 CPU 時間のうち 3.618 秒 (57.6%) を費やしていましたが、1.487 秒 (35.8%) になりました。
まとめ
ここで紹介した最適化は、十分なパフォーマンス・ゲインをもたらしました。
最適化の各ステップにおいて、フレームグラフはアプリケーション・スタックを視覚的に観察するのに役立ちました。実際のプロジェクトでは、[Top Hotspots (上位の hotspot)] セクションを確認しただけでは hotspot を見つけられないかもしれませんが、フレームグラフを使用することで、より少ない時間と労力で最適化する必要があるホットなパスを見つけることができます。
以下は、各最適化ステップの結果をまとめたものです。
| ステップ | 経過時間 (秒) | split 関数の CPU 時間 (秒) |
|---|---|---|
| 1 | 17.328 | 13.992 |
| 2 | 12.016 | 8.702 |
| 3 | 6.421 | 3.618 |
| 4 | 4.252 | 1.484 |
| 合計 | – 13.076 | – 12.508 |
ここでは、Boost ライブラリーの boost::split 関数を使用した実装から開始しました。しかし、パフォーマンスに満足できず、ライブラリー関数を変更することができなかったため、std::string を使用する独自の実装に切り替えました。
2 つ目の実装では、std::string 実装を改善できることが分かりました。3 つ目の実装では、std::string_view を使用して、std::string オブジェクトの生成と文字列バッファーのコピーを軽減してパフォーマンスを向上しました。そして、最後の実装では、出力ベクトルを事前に割り当てることで、頻繁な再割り当てを回避しました。
これらの最適化により、アプリケーションは同じ作業の実行時間を約 17 秒から約 4 秒に短縮できました。
関連情報
- フレームグラフを使用してホットなコードパスを解析する
- ウィンドウ: フレームグラフ (英語)
- ユーザーガイド: Hotspots 解析 (英語)
- Brendan Gregg 氏によるフレームグラフの記事 (https://www.brendangregg.com/flamegraphs.html)
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのトップに戻る
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
