
この記事は、インテルのウェブサイトに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Analyzing Uncore Perfmon Events for Use of Intel® Data Direct I/O Technology in Intel® Xeon® Processors」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
インテル® VTune™ プロファイラーを使用して、インテル® Xeon® プロセッサーのハードウェア機能であるインテル® データ・ダイレクト I/O テクノロジー (インテル® DDIO) の利用効率を理解する方法を示します。
コンテンツ・エキスパート: Alexander Kurylev、Yu Zhang
ソフトウェア・アプリケーションのパフォーマンスをプロファイルする場合、アンコアイベントはコアの外部で動作する CPU 機能を指します。これらの機能は、次の操作に関係します。
- メモリー・コントローラー
- UPI ブロック
- I/O スタック
インテル® VTune™ プロファイラーを使用して、アンコア・ハードウェア・パフォーマンス・イベント数を監視できます。この情報を解析によって得られる他のパフォーマンス・メトリックと合わせて使用すると、PCIe* トラフィックと動作を詳しく調査できます。
このレシピでは、PCIe* に関連するアンコアイベントを使用して、インテル® DDIO とダイレクト I/O 向けインテル® バーチャライゼーション・テクノロジー (インテル® VT-d) の効率を解析する方法を示します。解析には、入力および出力解析タイプを使用します。
ここで説明する I/O メトリックとイベントは、インテル® Xeon® スケーラブル・プラットフォーム (開発コード名 Ice Lake) を使用した場合のものです。アンコアイベントはプラットフォームにより異なるため、同じメトリックでも計算に違いが生じる可能性があります。
使用するもの
- アプリケーション: DPDK testpmd アプリケーション (英語)
- 解析ツール: インテル® VTune™ プロファイラー 2023.2 以降 (入力および出力解析)
- プラットフォーム: イーサネット・ケーブルで接続された 2 基のインテル® Xeon® Platinum 8358 CPU @ 2.60GHz ベースのプラットフォーム
- ネットワーク・インターフェイス・カード: インテル® イーサネット・コントローラー X710 (10GBASE-T)
- オペレーティング・システム: Ubuntu* 22.04.3 LTS
入力と出力解析を実行する
- 第 1 世代インテル® Xeon® スケーラブル・プロセッサー以降を使用します。
- サンプリング・ドライバーがロードされていることを確認します。
- 少なくとも 20 秒間のデータ収集を行います。
インテル® VTune™ プロファイラーの入力および出力解析を使用して、インテル® DDIO 利用効率メトリックを収集します。ドライバーレス・モードで解析を実行する場合、いくつかの制限があります。
インテル® VTune™ プロファイラーの解析ツールから、[Input and Output (入力および出力)] 解析タイプを開きます。
[WHAT (何を)] ペインで以下の操作を行います。
- [Launch Application (アプリケーションを起動)] を選択して、アプリケーションのパスとパラメーターを指定します。
- [Attach to Process (プロセスにアタッチ)] を選択して、PID を指定します。
[HOW (どのように)] ペインで [Analyze PCIe traffic (PCIe* トラフィックを解析)] チェックボックスをオンにして、インテル® DDIO 利用効率メトリックを収集します。
[Start (開始)] ボタンをクリックして、解析を実行します。
コマンドラインから dpdk-testpmd ベンチマークの入力および出力解析を実行するには、次のコマンドを使用します。
# vtune -collect io -knob iommu=true -- dpdk-testpmd -l 32-35 -n 8 -- --mbcache=0 –mbuf-size=65535 –total-num-mbufs=8192
利用可能なシステムの 1 つでこの解析を実行し、別のシステムで PCIe* トラフィックを生成します。
# dpdk-testpmd -l 0-3 -- --forward-mode=txonly
結果を確認する
データ収集が完了したら、結果をワークステーションにダウンロードします。その後、インテル® VTune™ プロファイラーの GUI またはウェブサーバーで結果を開くことができます。
このレシピでは、ウェブサーバーを使用します。
[Summary (サマリー)] ウィンドウ
ここから結果の調査を開始し、アプリケーションの実行の概要を確認します。
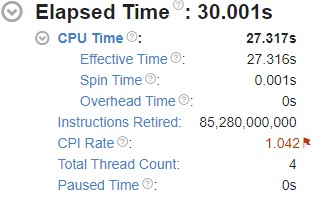
プラットフォーム図
次に、[Platform Diagram (プラットフォーム図)] で以下の情報を確認します。
- システムトポロジーと物理コア利用率
- 各 CPU ソケットパッケージの平均 DRAM 帯域幅
- 各 PCIe* デバイスの既知のデバイス機能の平均 PCIe* 利用率 (機能が不明な場合は、ダイアグラムに PCIe* 平均帯域幅が表示されます)
- インテル® ウルトラ・パス・インターコネクト (インテル® UPI) のクロスソケット・リンクの利用率
PCIe* トラフィック
[PCIe Traffic Summary (PCIe* トラフィックのサマリー)] セクションのメトリックを確認します。
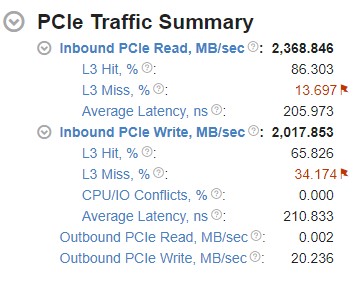
インバウンドとアウトバウンドの PCIe* 帯域幅
プラットフォーム上で I/O トラフィックがどのように処理されるかを理解するため、PCIe* 帯域幅メトリックの最初のレベルを確認します。
PCIe* トラフィックには、インバウンド・トラフィックとアウトバンド・トラフィックが含まれます。
インバウンド・トラフィック: このトラフィックは、システムメモリーの読み取りや書き込みを行う外部または内部の PCIe* デバイスなどの I/O デバイスによって開始されます。インバウンド・トラフィックは、インテル® データ・ダイレクト I/O テクノロジー (インテル® DDIO) (英語) によって処理されます。
このテクノロジーは、I/O デバイスとの間の I/O データ処理の効率を向上させるのに役立ちます。インテル® DDIO は、DRAM の代わりに、 L3 キャッシュを I/O データの主なデスティネーションおよびソースとして使用します。DRAM への複数の読み取りと書き込み操作を回避することで、インテル® DDIO は次の利点をもたらします。
- インバウンド読み取り/書き込みレイテンシーの軽減
- I/O 帯域幅の向上
- DRAM アクセスの軽減
- 電力消費の軽減
インバウンド読み取り操作では、I/O デバイスがシステムメモリーから読み取ります。
インバウンド書き込み操作では、I/O デバイスがシステムメモリーに書き込みます。
アウトバウンド・トラフィック: このトラフィックは I/O デバイスによって開始されます。I/O デバイスのメモリーまたはレジスターからの読み取りや書き込みが含まれます。通常、CPU はメモリーマップ I/O (MMIO) 空間を介してデバイスメモリーにアクセスします。
アウトバウンドの読み取り操作では、CPU が I/O デバイスレジスターから読み取ります。
アウトバウンドの書き込み操作では、CPU が I/O デバイスレジスターに書き込みます。
統合 I/O (IIO) パフォーマンス・モニタリング・イベントは、PCIe* 帯域幅の計算に使用されます。IIO スタックは、PCIe* ドメインとメッシュドメイン間のトラフィックを管理します。以下の表は、I/O スタックのチャネル (部分) 別 PCIe* 帯域幅のカウントに使用されるアンコアイベントのセットを示します。アンコアイベントは、カウントするトラフィックの方向にマップされます。
| 方向 | 読み取りアンコアイベント | 説明 |
|---|---|---|
| インバウンド | UNC_IIO_DATA_REQ_OF_CPU.MEM_READ.PART[0-7] |
システムメモリーからの 4 バイト・データ要求 |
| アウトバウンド | UNC_IIO_DATA_REQ_OF_CPU.CMPD.PART[0-7] |
I/O から CPU へ 4 バイトの要求の完了を送信 |
| 方向 | 書き込みアンコアイベント | 説明 |
|---|---|---|
| インバウンド | UNC_IIO_DATA_REQ_OF_CPU.MEM_WRITE.PART[0-7] |
システムメモリーへの 4 バイト・データ要求 |
| アウトバウンド | UNC_IIO_DATA_REQ_BY_CPU.MEM_WRITE.PART[0-7] |
CPU により要求された 4 バイト・データ |
I/O スタックのチャネル上の IIO パフォーマンス・イベントのマッピングを詳しく理解するには、「アンコア・パフォーマンス・モニタリングのリファレンス・ガイド」 (英語) を参照してください。
上の表で説明されているイベントは、4 バイトのデータごとに 1 カウント増加します。平均 PCIe* 帯域幅を計算するには、イベント数を 4 倍にして、サンプリング時間で割ります。
平均 PCIe* 帯域幅 (MB/秒) = (イベント数 * 4 バイト / 10^6) / サンプリングされた秒数
デバイスの機能が既知であり、最大物理帯域幅を計算できる場合、デバイスリンクには PCIe Effective Link Utilization (PCIe* 有効リンク利用率) メトリックが割り当てられます。このメトリックは、利用可能な物理帯域幅に対するデータ転送で消費される帯域幅の比率です。
このメトリックは、プロトコルのオーバーヘッド (TLP ヘッダー、DLLP、または物理エンコーディング) を考慮せず、ペイロードの観点からリンク利用率を反映します。したがって、PCIe* Effective Link Utilization (PCIe* 有効リンク利用率) メトリックは 100% に達することはありませんが、リンクが飽和状態からどの程度離れているかが分かります。PCIe* Effective Link Utilization (PCIe* 有効リンク利用率) メトリックは次のように計算できます。
PCIe* 有効利用率 (%) = (平均 PCIe*合計帯域幅 (MB/秒) / PCIe* 最大帯域幅 (MB/秒)) * 100%
平均 PCIe* 合計帯域幅 (MB/秒) = (平均インバウンド PCIe* 帯域幅 (MB/秒) + 平均アウトバウンド PCIe* 帯域幅 (MB/秒))
平均インバウンド/アウトバウンド PCIe* 帯域幅 (MB/秒) = (平均読み取り帯域幅 (MB/秒) + 平均書き込み帯域幅 (MS/秒))
PCIe* 最大帯域幅の計算は、OS によって提供される max_link_width および max_link_speed sysfs 属性に基づいています。
PCIe* 最大帯域幅 (MB/秒) = 最大リンク速度 (x1 リンクあたり GT/秒) * 1000 / 8 * 最大リンク幅 * 2
インバウンド要求の L3 ヒット/ミス率
I/O デバイスがシステムメモリーに対して行った要求のうち、L3 キャッシュにヒットまたはミスした要求の比率です。インテル® DDIO を効率良く使用する方法については、インテル® VTune™ プロファイラー・パフォーマンス解析クックブックの「インテル® データ・ダイレクト I/O テクノロジーの効果的な利用」を参照してください。
L3 ヒット/ミス率の計算には、キャッシュ/ホーム・エージェント (CHA) と統合 I/O リングポート (IRP) パフォーマンス・モニタリング・イベントを使用します。
CHA は、コアキャッシュ、IIO スタック、およびソケット間のメモリーの一貫性を維持する分散エージェントです。
IIO リングポート (IRP) は、コヒーレント・メモリーをターゲットとする IIO トラフィックの一貫性を維持します。
以下の表は、これらのメトリックの計算に使用されるイベントについて説明しています。
| トラフィック | アンコアイベント | エイリアス | 説明 |
|---|---|---|---|
| 読み取り | UNC_CHA_TOR_INSERTS.IO_MISS_PCIRDCUR | X | I/O デバイスによって発行された PCI Read Current (PCIRdCurs) 要求のうち LLC をミスしたものです。この要求は、最新のデータを取得するため、キャッシュライン全体を読み取ります。 |
| UNC_I_FAF_INSERTS | Y | コヒーレント・メモリーへのインバウンド読み取り要求です。IRP によって受信され、Fire and Forget (FAF) キューに挿入されます。 |
|
| 書き込み | UNC_CHA_TOR_INSERTS.IO_MISS_ITOM | A | I/O デバイスによって発行された Invalid to Modified (ItoM) 要求のうち LLC をミスしたものです。ItoM はキャッシュライン全体に書き込む、データのない所有権要求です。 |
| UNC_CHA_TOR_INSERTS.IO_MISS_ITOMCACHENEAR | B | ItoMCacheNears は、I/O デバイスからの部分書き込み要求のうち LLC をミスしたものを示します。 |
|
| UNC_I_TRANSACTIONS.WR_PREF | C | IRP によって受信されるコヒーレント・メモリーへのインバウンド書き込み (高速パス) 要求です。この要求により、IRP によってメッシュに書き込み所有権要求が発行されます。 |
|
| UNC_I_MISC1.LOST_FWD | D | 書き込みがコミットされる前に、スヌープフィルターによって所有権が剥奪されたものです。 |
上の表のエイリアスは、以下の式の対応するトラフィックを表しています。
| インバウンド PCIe* 読み取り帯域幅の L3 ヒット/ミス率 | インバウンド PCIe* 書き込み帯域幅の L3 ヒット/ミス率 |
|---|---|
| インバウンド PCIe* 読み取り L3 ミス (%) = (X) / (Y)* 100% | インバウンド PCIe* 書き込み L3 ミス (%) = ((A) + (B)) / ((C) + (D)) * 100% |
| インバウンド PCIe* 読み取り L3 ヒット (%) = 100% – ミス率 (%) | インバウンド PCIe* 書き込み L3 ヒット (%) = 100% – ミス率 (%) |
インバウンド要求の平均レイテンシー
インバウンド読み取り/書き込み要求の Average Latency (平均レイテンシー) メトリックは、単一のキャッシュラインのインバウンド読み取り/書き込み要求の処理にプラットフォームが費やす平均時間を示します。このメトリックの計算は、リトルの法則に基づいています。
レイテンシー = 占有率 / 挿入数
要求が処理されると、完了バッファーにアイテムが保持されます。このバッファーの占有率と要求到着率 (挿入数) に関する情報により、平均要求処理時間を計算できます。
以下の表は、これらのメトリックの計算に使用される非コア・パフォーマンス・イベントについて説明しています。
| トラフィック | アンコアイベント | エイリアス | 説明 |
|---|---|---|---|
| 読み取り | UNC_IIO_COMP_BUF_OCCUPANCY.CMPD | X | PCIe* 完了バッファーの占有率 |
| UNC_IIO_COMP_BUF_INSERTS.CMPD | Y | PCIe* 完了バッファーのデータを含む完了の挿入数 |
|
| 書き込み | UNC_I_CACHE_TOTAL_OCCUPANCY.MEM | A | コヒーレント・メモリーへのインバウンド読み取り/書き込み要求の合計 IRP 占有率 |
| UNC_I_FAF_OCCUPANCY | B | IRP FAF キューの占有率 |
|
| UNC_I_TRANSACTIONS.WR_PREF | C | コヒーレント・メモリーへのインバウンド書き込み (高速パス) 要求が IRP によって受信され、IRP によってメッシュに書き込み所有権要求が発行されます。 |
上の表のエイリアスは、以下の式の対応するトラフィックを表しています。
| インバウンド PCIe* 読み取りレイテンシー (Ns) | インバウンド PCIe* 書き込みレイテンシー (Ns) |
|---|---|
| (X) / (Y) / IIO 周波数 (GHz) | ((A) – (B)) / (C) / IRP 周波数 (GHz) |
インバウンド書き込み要求の CPU/IO 競合
CPU/IO 競合メトリックは、I/O コントローラーと CPU 上の別のエージェント (コアまたは別の I/O コントローラーなど) の間でキャッシュラインの競合が発生したインバウンド I/O 書き込み要求の比率を示します。この競合は、同じキャッシュラインへの同時アクセスによって発生します。特定の条件下では、これらのアクセス試行によって I/O コントローラーがキャッシュラインの所有権を失う可能性があり、I/O コントローラーはこのキャッシュラインの所有権を再度取得する必要があります。この問題は、ポーリング通信モデルを使用するアプリケーションで発生する可能性があり、その結果、スループットとレイテンシーが最適ではなくなります。
以下の表は、これらのメトリックの計算に使用される非コア・パフォーマンス・イベントについて説明しています。
| アンコアイベント | エイリアス | 説明 |
|---|---|---|
| UNC_I_MISC1.LOST_FWD | A | 書き込みがコミットされる前に、スヌープによって所有権が剥奪されたものです。 |
| UNC_I_TRANSACTIONS.WR_PREF | B | IRP によって受信されるコヒーレント・メモリーへのインバウンド書き込み (高速パス) 要求です。この要求により、IRP によってメッシュに書き込み所有権要求が発行されます。 |
以下の式で CPU/IO 競合メトリックを計算します。
インバウンド PCIe* 書き込み CPU/IO 競合 (%) = (A) / (B) * 100%
ダイレクト I/O 向けインテル® バーチャライゼーション・テクノロジー (インテル® VT-d):
インテル® VT-d を使用すると、インバウンド I/O デバイス・メモリー・トランザクションのアドレスを別のホストアドレスに再マップできます。インテル® VT-d の詳細については、ダイレクト I/O 向けインテル® バーチャライゼーション・テクノロジー (インテル® VT-d) の仕様 (英語) を参照してください。
インテル® VT-d を使用すると、インバウンド I/O 要求のアドレスを再マップできます。インテル® VTune™ プロファイラーの入力および出力解析タイプは、インテル® VT-d を利用するワークロードの効率を解析するのに役立つインテル® VT-d 関連のメトリックを提供します。
インテル® VT-d メトリックとイベントを理解する
IIO PMON ブロックの IOMMU イベントは、インテル® VT-d メトリックの計算に使用されます。
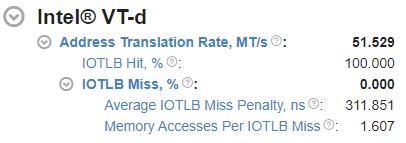
インテル® VT-d アドレス変換率: I/O 変換ルックアサイド・バッファー (IOTLB) の合計ルックアップ回数 (1 秒あたり百万回単位) を示す、インテル® VT-d の最上位メトリックです。IOTLB は、再マッピング・ハードウェア・ユニット内のアドレス変換キャッシュです。IOTLB は、デバイスで使用される仮想アドレスからホストの物理アドレスへの有効な変換をキャッシュします。IOTLB ルックアップは、アドレス変換要求時に発生します。UNC_IIO_IOMMU0.FIRST_LOOKUPS イベント (要求の初回 IOTLB ルックアップをカウント) は、次の式でアドレス変換率メトリックの計算に使用されます。
アドレス変換率 (MT/秒) = UNC_IIO_IOMMU0.FIRST_LOOKUPS / 10^6 / サンプリングされた秒数
IOTLB ヒット/ミスメトリック: IOTLB にヒットまたはミスしたアドレス変換要求の比率を反映します。UNC_IIO_IOMMU0.CTXT_CACHE_LOOKUPS アンコアイベントは、OTLB ミス率の計算に使用されます。このイベントは、トランザクションがルート・コンテキスト・キャッシュを検索するたびにカウントされます。ヒット/ミス率の計算式は次のとおりです。
IOTLB ミス (%) = UNC_IIO_IOMMU0.CTXT_CACHE_LOOKUPS / UNC_IIO_IOMMU0.FIRST_LOOKUPS * 100%
IOTLB ヒット (%) = 100% – IOTLB ミス
IOTLB ミスのグループには、関連する 2 つのメトリックがあります。
平均 IOTLB ミス・ペナルティー・メトリック: IOTLB ミスの処理に費やされた平均時間を示します。このメトリックには、コンテキスト・キャッシュ、中間ページ・テーブル・キャッシュ、およびメモリー読み取り要求に変換されるミス時のページテーブル読み取り (ページウォーク) のルックアップ時間が含まれます。以下の表は、これらのメトリックの計算に使用される非コア・パフォーマンス・イベントについて説明しています。
アンコアイベント エイリアス 説明 UNC_IIO_PWT_OCCUPANCY A 任意の時点で未処理のページウォークの数を示します。
UNC_IIO_IOMMU0.CTXT_CACHE_LOOKUPS B トランザクションがルート・コンテキスト・キャッシュを検索するたびにカウントされます。
このメトリックの計算式は次のとおりです。
平均 IOTLB ミス・ペナルティー (ns) = (A) / (B) / IIO 周波数 (GHz)
IOTLB ミスあたりのメモリー・アクセス・メトリック: IOTLB ミスあたりのメモリー読み取り要求 (ページウォーク) の平均数を示します。このメトリックを計算するには、追加のイベント (UNC_IIO_TXN_REQ_OF_CPU.MEM_READ.IOMMU1) を使用します。このイベントは、読み取りと書き込みを含む、I/O デバイスによって開始された 64B キャッシュライン要求の数をカウントします。
このメトリックの計算式は次のとおりです。
IOTLB ミスあたりのメモリーアクセス = UNC_IIO_TXN_REQ_OF_CPU.MEM_READ.IOMMU1 / UNC_IIO_IOMMU0.CTXT_CACHE_LOOKUPS
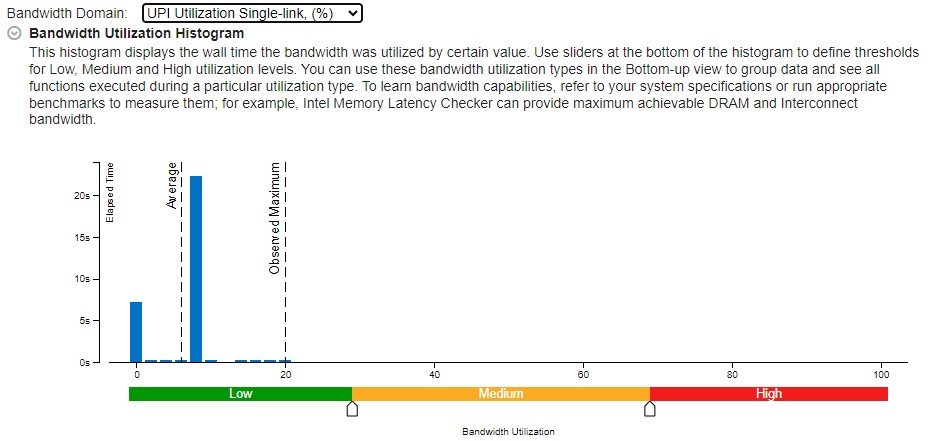
DRAM および UPI 帯域幅ヒストグラム
X 軸の特定の値によって使用されるシステム帯域幅 (この例では、DRAM と UPI) を、Y 軸の時間に対してプロットします。ヒストグラムには、帯域幅の利用率を高、中、低に分類するしきい値が用意されています。ヒストグラムの下部にあるスライダーを動かして、しきい値を調整します。DRAM と UPI 帯域幅の例を次に示します。

DRAM 帯域幅および UPI メトリックとイベントを理解する
DRAM 帯域幅と利用率:
UNC_M_CAS_COUNT.RD: チャネルごとに DRAM 読み取りカラム・アクセス・セレクト (CAS) 読み取りコマンドの総数をカウントします。CAS コマンドは、DRAM で読み取りまたは書き込みを行うアドレスを指定するために発行されます。このイベントは 64 バイトごとに増加します。次の式で DRAM 読み取りデータの合計を計算します。
データ読み取り (GB) = UNC_M_CAS_COUNT.RD * 64 (バイト) / 10^9
平均読み取り帯域幅は、サンプリング時間で割って計算することができます。
平均読み取り帯域幅 (GB/秒) = データ読み取り (GB) / グローバル経過時間 (秒)
UNC_M_CAS_COUNT.WR: DRAM 書き込み CAS コマンドの総数をカウントします。このイベントは 64 バイトごとに増加します。読み取りメトリックと同様に、次の式で DRAM 書き込みデータの合計を計算します。
データ書き込み (GB) = UNC_M_CAS_COUNT.WR * 64 (バイト) / 10^9
平均書き込み帯域幅は、次の式で計算します。
平均書き込み帯域幅 (GB/秒) = データ書き込み (GB) / グローバル経過時間 (秒)
DRAM 平均利用率は、平均 DRAM 帯域幅を最大 DRAM 帯域幅で割ることで計算できます。最大 DRAM 帯域幅を計算するには、収集を実行する前に、[Evaluate max DRAM bandwidth (最大 DRAM 帯域幅を評価する)] チェックボックスをオンにします。収集の前にマイクロベンチマークが開始され、帯域幅が計算されます。
DRAM 利用率 (%) = 平均 DRAM 帯域幅 (GB/秒) / 最大ローカル帯域幅 (GB/秒) * 100%
平均 DRAM 帯域幅 (GB/秒) = 平均書き込み帯域幅 (GB/秒) + 平均読み取り帯域幅 (GB/秒)
UPI 利用率:
UNC_UPI_TxL_FLITS.ALL_DATA イベントと UNC_UPI_TxL_FLITS.NON_DATA イベントはそれぞれ、すべてのデータと非データに対して有効なフリットが送信されたことを示します。
UPI 利用率 (%) = (UNC_UPI_TxL_FLITS.ALL_DATA + UNC_UPI_TxL_FLITS.NON_DATA) / 3 / (UPI アクティブクロック数 * (5/6)) * 100%
UPI アクティブクロック数 = UNC_UPI_CLOCKTICKS – UNC_UPI_L1_POWER_CYCLES
結果をビューにグループ化する
入力および出力解析の結果から、以下に関連した I/O メトリックの詳細な情報が得られます。
- PCIe* デバイスのグループ
- PCIe* メトリックとパフォーマンス・アンコア・イベント
- 経時的な I/O メトリック
これらの結果を、以下のウィンドウの複数のビューにグループ化できます。
- [Bottom-up (ボトムアップ)] ウィンドウ
- [Uncore event count (アンコア・イベント・カウント)] ウィンドウ
- [Platform (プラットフォーム)] ウィンドウ
[Bottom-up (ボトムアップ)] ウィンドウ:
[Package / IO Unit (パッケージ/IO ユニット)] グループを使用して、デバイスごとの以下の情報を確認できます。
- インバウンド/アウトバウンド・トラフィック
- インバウンド要求の L3 ヒットとミス
- 平均レイテンシー
- CPU/IO 競合
- インテル® VT-d メトリック

第 2 レベルのメトリックを表示/非表示にするには、Inbound PCIe Write (インバウンド PCIe* 書き込み) テーブルの表示オプションを調整します。
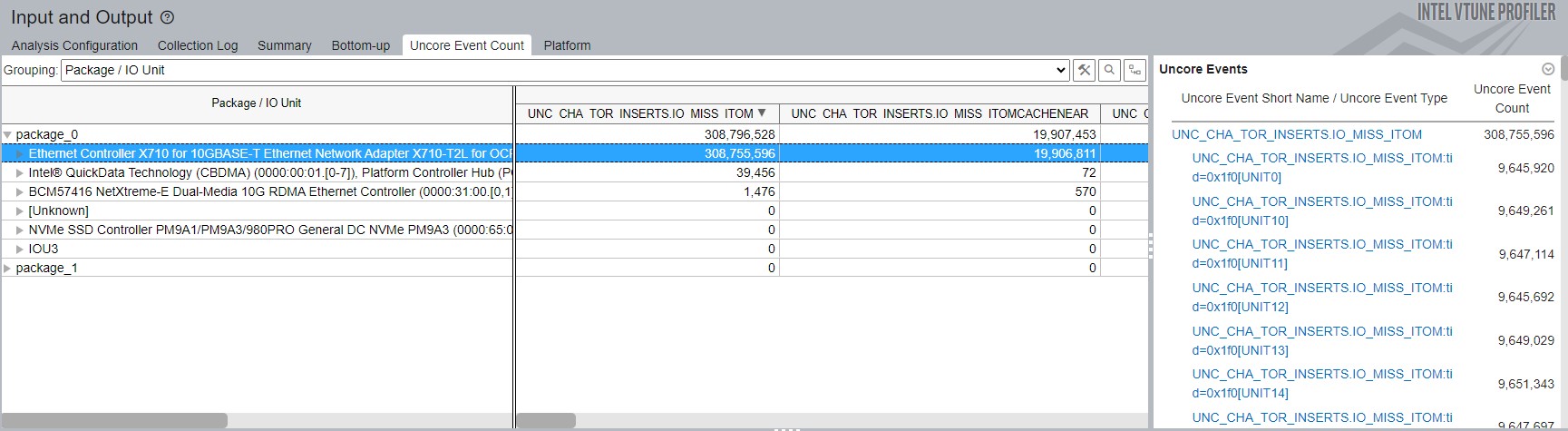
[Uncore event count (アンコア・イベント・カウント)] ウィンドウ:
[Package / IO Unit (パッケージ/IO ユニット)] グループを使用すると、I/O デバイスのグループごとにアンコアイベントの数を識別できます。
この例では、右側の [Uncore Events (アンコアイベント)] セクションに、[Package / IO Unit (パッケージ/IO ユニット)] グループで選択された唯一のデバイスである Ethernet Controller のパフォーマンス・イベントが表示されています。
タイムライン・セクションでは、すべてのアンコアイベントを視覚化できます。
各ソケットの PCIe* デバイスグループのアンコアイベントを表示するには、タイムライン セクションの右側で、[Package/IO Unit/Uncore Event Short Name/Uncore Event Type (パッケージ/IO ユニット/アンコアイベントの短縮名/アンコア・イベント・タイプ)] グループを選択します。
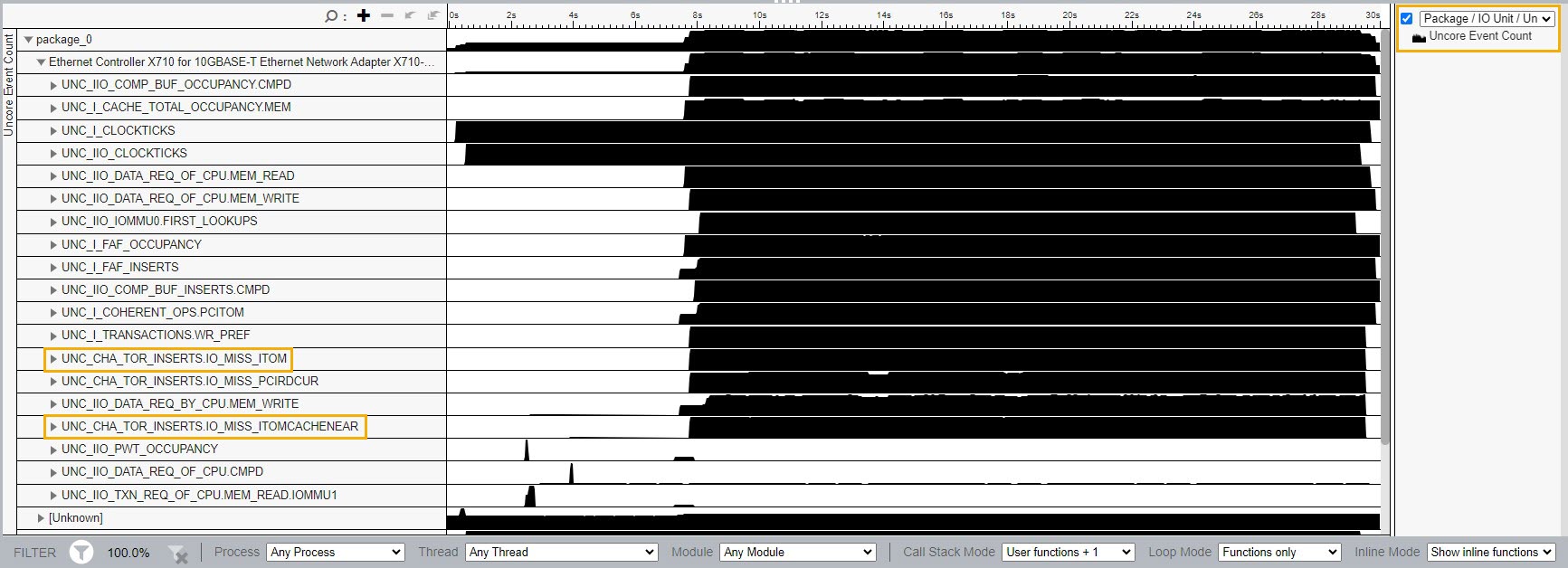
I/O デバイスの動作を理解するには、このレシピで前述した数式を使用します。
例えば、Inbound PCIe Write L3 Miss (インバウンド PCIe* 書き込み L3 ミス) メトリックは、L3 キャッシュをミスした ItoM 要求の数に依存します。上の図では、L3 キャッシュをミスした ItoM 要求が 2 つあります。
生データを使用して、時間の経過とともに視覚化できます。これらのイベントを増やすと、PCIe* のパフォーマンス全体に影響するタイミングをよく理解できます。
特定の瞬間のハードウェア・イベントの正確な数を確認するには、タイムラインにマウスを置きます。
疑わしい値を詳しく調べるには、領域を選択して右クリックし、ズームまたはフィルターします。
IMC や UPI イベントなどの I/O スタックに起因しない I/O イベントは、Unknown (不明) デバイスグループに表示されます。
カスタム・アンコア・イベントを使用するカスタム解析を実行する場合、[Uncore Event Count (アンコア・イベント・カウント)] ウィンドウを使用すると非常に便利です。
[Platform (プラットフォーム)] ウィンドウ:
このウィンドウを使用して、PCIe* トラフィックを DRAM および UPI 帯域幅と関連付けます。例えば、L3 ミスが発生すると、データは外部 DRAM から読み取られます。
[Platform (プラットフォーム)] ウィンドウの [Package/Physical Core (パッケージ/物理コア)] グループを使用して、コアまたはスレッドのワークロード分布を確認し、NUMA に関連する問題があるかどうかを調べます。
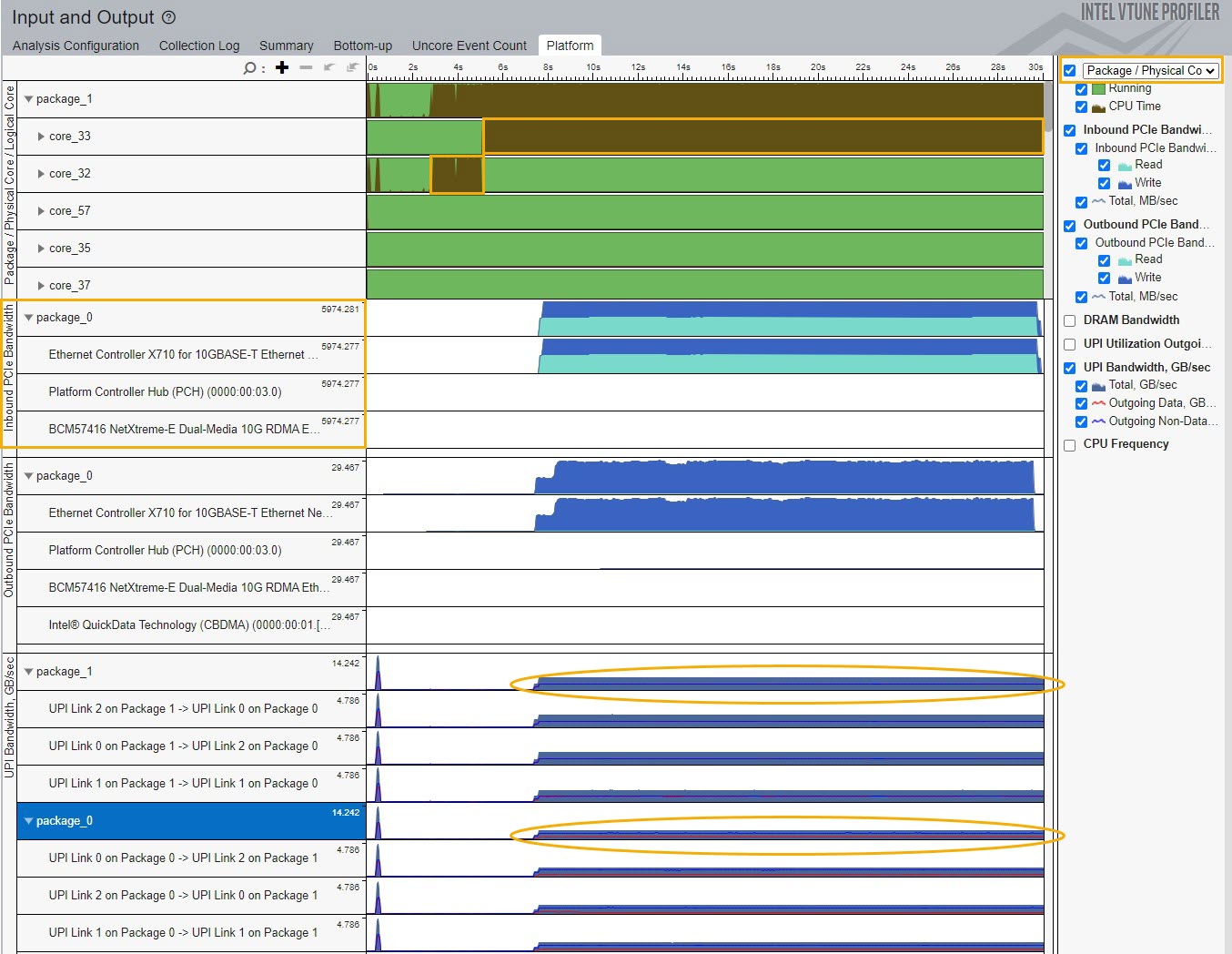
UPI リンクによって提供される UPI トラフィック情報を使用して、I/O パフォーマンスの問題が非効率的なリモート・ソケット・アクセスによって発生しているかどうかを識別します。
上記の例では、ワーカーコアはリモートソケットに設定されています。ワーカーコアを PCIe* デバイスと同じソケットに設定すると、UPI トラフィックと L3 ミス値を軽減できます。
その結果、PCIe* 全体のパフォーマンスが向上します。
このレシピについて、Analyzers フォーラム (英語) で意見交換することができます。
