
この記事は、インテル® デベロッパー・ゾーンに掲載されている「How to Install and Use Intel® VTune™ Amplifier Platform Profiler」(https://software.intel.com/en-us/articles/vtune-amplifier-platform-profiler) の日本語参考訳です。
プラットフォーム・プロファイラーを使ってみましょう
インテル® VTune™ Amplifier のプラットフォーム・プロファイラーは、すぐに利用できます。無料で、こちらからダウンロードできます。
概要
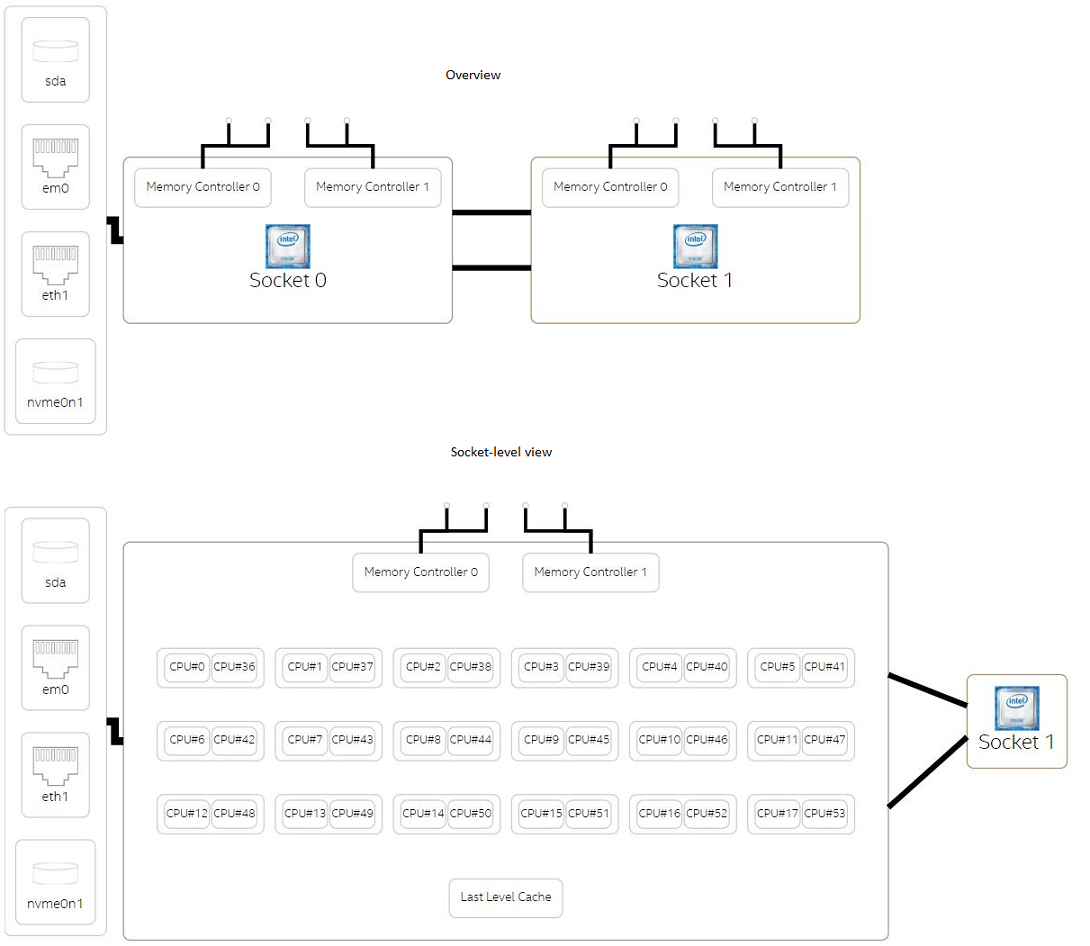
インテル® VTune™ Amplifier – プラットフォーム・プロファイラーは、アーキテクチャーをどのくらい効率良く活用しているか、そしてユーザーがシステムのハードウェア構成をどのように最適化できるか特定するのに役立つツールです。プロセッサー、メモリー、ストレージ配置、PCIe*、ネットワーク・インターフェイス (図 1 を参照) などの高レベルのシステム構成、および CPU とメモリーの使用状況、CPU 周波数、命令あたりのサイクル数 (CPI)、メモリーとディスク入出力 (I/O) スループット、消費電力、命令ごとのキャッシュミス率など、システムで観測されたパフォーマンス・メトリックを表示します。ツールによって収集されるパフォーマンス・メトリックは、より詳細な解析と最適化に利用されます。
プラットフォーム・プロファイラーは、次の利用者を想定しています。
- ソフトウェア開発者 – このツールが提供するパフォーマンス・メトリックを参照して、開発者は CPU、メモリー、ディスク、ネットワーク・デバイスなどのさまざまなプラットフォーム・コンポーネントにまたがるワークロードの動作を解析できます。
- インフラ・アーキテクト – 長時間にわたる実行の収集を解析し、システムのパフォーマンスが低下する時間/場所を見つけることでハードウェアを監視できます。さらに、ツールの検出結果を基にシステムのハードウェア構成を最適化できます。例えば、各種ワークロードを実行した後、プラットフォーム・プロファイラーが高いプロセッサー利用率、メモリー使用、または I/O がアプリケーションのパフォーマンスを制限していることを示す場合、コアやメモリーを追加したり、高速な I/O デバイスを使用します。

図 1. プラットフォーム・プロファイラーによる高レベルのシステム構成ビュー
プラットフォーム・プロファイラーとインテル® VTune™ Amplifier のほかの解析との主な違いは、プラットフォーム・プロファイラーはパフォーマンスに影響するオーバーヘッドをほとんど発生させずに少量のデータを収集しながら、長時間にわたってプラットフォームをプロファイルできることです。現在のプラットフォーム・プロファイラーは最大 13 時間まで動作し、インテル® VTune™ Amplifier を 13 時間実行するよりも少ないデータを生成します。例えば、単純にプラットフォーム・プロファイラーを起動して 13 時間実行し続け、この間に必要に応じてシステムを利用し、その後プラットフォーム・プロファイラーのプロファイルを停止できます。プラットフォーム・プロファイラーは、すべてのプロファイル・データを収集してシステム利用率のダイアグラムを表示します。一方、インテル® VTune™ Amplifier はギガバイト規模のプロファイル・データを数分で生成するため、長時間実行することは困難です。そのため、インテル® VTune™ Amplifier は、システムよりもアプリケーションの細かなチューニングや解析に適しています。プラットフォーム・プロファイラーは、アプリケーションがマシンを効率良く使用しているか、またはマシンが効率良く使用されているか、という問いに答えることができます。しかし、マシンを効率良く利用するためアプリケーションをどのように変更すべきか、という問いに対してはインテル® VTune™ Amplifier を使用します。
プラットフォーム・プロファイラーは、データコレクターとサーバーの 2 つのコンポーネントから構成されます。
- データコレクター – プロファイルされるシステム上にインストールされるスタンドアロン・パッケージです。システムレベルのハードウェアとオペレーティング・システムのパフォーマンス・カウンターを収集します。
- プラットフォーム・プロファイラー・サーバー – 収集したデータを後処理して時系列データベースに格納し、システムのトポロジー情報と関連付けて、Web ベースのインターフェイスを使用してトポロジー・ダイアグラムとパフォーマンス・グラフを表示します。
ツールのインストールと使い方
ツールのインストールと使用法に関する手順は、『インテル® VTune™ Amplifier 2019 ヘルプ』の「パフォーマンス解析」 > 「プラットフォーム解析グループ」 > 「プラットフォーム・プロファイラー解析 (プレビュー)」で説明されています。
ツールのドキュメント
ここからは、収集した結果データを参照しながら解析方法について説明します。ここでは、使用例として映画推奨システム・アプリケーションを使用します。映画推奨コードは、Spark* Training GitHub* (英語) ウェブサイトから入手できます。使用するプラットフォームは、Ubuntu* 14.04 オペレーティング・システムを実行する、インテル® ハイパースレッディング・テクノロジー対応の 2 ソケット Haswell✝ サーバー (インテル® Xeon® プロセッサー E5-2699 v3)、72 論理コア、64GB メモリーのシステムです。
Spark* で実行するコードは、単一ノードで次のように実行されます。
1 | spark-submit --driver-memory 2g --class MovieLensALS --master local[4] movielens-als_2.10-0.1.jar movies movies/test.dat |
上記のコマンドラインでは、Spark* は –master local[4] オプションで指定される 4 つのスレッドのローカルモードで実行されます。ローカルモードでは、executor として動作するドライバーは 1 つのみであり、executor はスレッドを生成してタスクを実行します。アプリケーションを起動する前に変更できる引数は、ドライバーメモリー (–driver-memory 2g) と実行するスレッド数 (local[4]) の 2 つがあります。ここでの目標は、これらの引数を変更することでシステムにどれぐらい負荷がかかるかを調査し、プラットフォーム・プロファイラーのプロファイル・データを参照して実行中に発生する注目すべきパターンを特定することです。
以下に実行した 4 つのテストケースと実行時間を示します。
- 1
spark-submit --driver-memory 2g --class MovieLensALS --masterlocal[4] movielens-als_2.10-0.1.jar movies movies/test.dat (16 分 11 秒) - 1
spark-submit --driver-memory 2g --class MovieLensALS --masterlocal[36] movielens-als_2.10-0.1.jar movies movies/test.dat (11 分 35 秒) - 1
spark-submit --driver-memory 8g --class MovieLensALS --masterlocal[36] movielens-als_2.10-0.1.jar movies movies/test.dat (7 分 40 秒) - 1
spark-submit --driver-memory 16g --class MovieLensALS --masterlocal[36] movielens-als_2.10-0.1.jar movies movies/test.dat (8 分 14 秒)
図 2 と図 3 は、それぞれ Test 1 と Test 2 で観測された CPU メトリックを示します。図 2 は、CPU が十分に活用されておらず、システムのほかのリソースも同様であれば、ユーザーがワークをさらに増やすことができることを示しています。CPU 周波数が頻繁に低下しており、これは CPU がパフォーマンスを制限するものではないことを示しています。図 3 は、スレッド数を増やすことでテストケースの CPU 利用率が高まることを示していますが、それでもまだ余裕があります。さらに、図 3 の CPI グラフに示されるように、スレッド数を増やすことで CPI 率が低下したことが分かります。
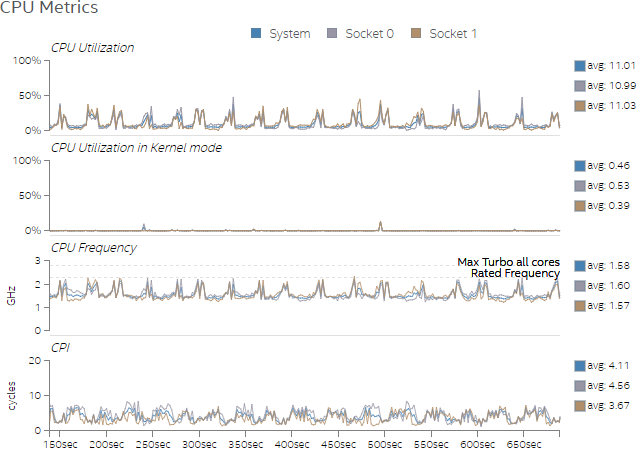
図 2. Test 1 の CPU の使用率
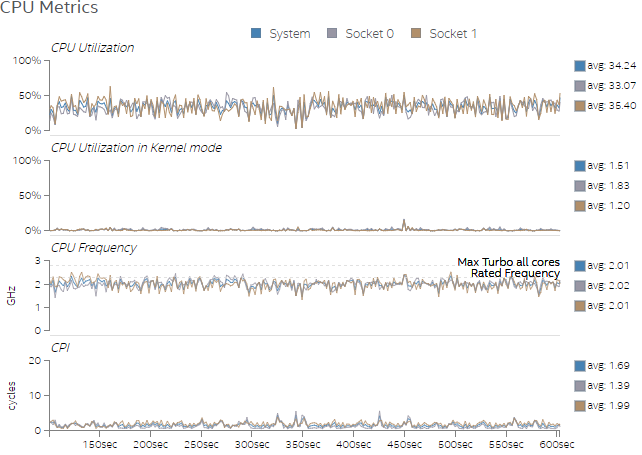
図 3. Test 2 の CPU の使用率
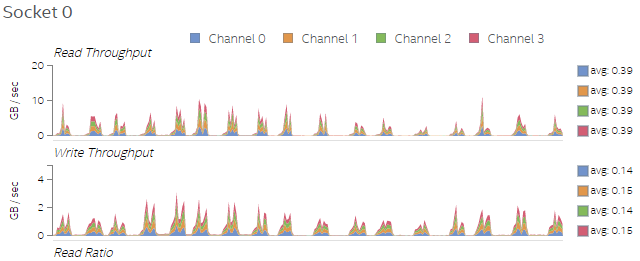
図 4. Test 1 のソケット 0 上のメモリーリード/ライトのスループット
図 4 と図 5 を比べると、スレッド数が増加したことでメモリーアクセス数も増えていることが分かります。これは予想されたことですが、プラットフォーム・プロファイラーで収集したデータで検証することができました。
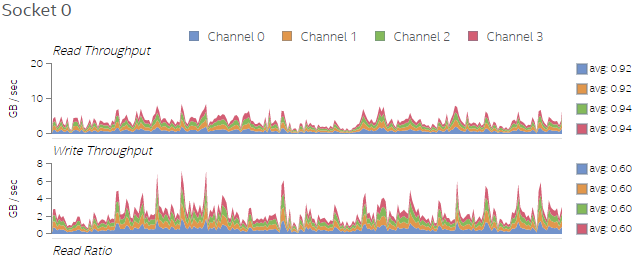
図 5. Test 2 のソケット 0 上のメモリーリード/ライトのスループット
図 6 と図 7 は、Test 1 と Test 2 の命令あたりの L1 および L2 ミス率を示しています。図 7 では、Test 2 でスレッド数を増やすと、L1 および L2 のミス率が大幅に低下していることが分かります。スレッド数を増やしてコードを実行すると、アプリケーションの CPI 率が低下し L1 と L2 のミス率も低くなることが分かりました。これは、データがメモリーからキャッシュにロードされると、かなりのデータが再利用されることで全体のパフォーマンスが向上することを意味します。
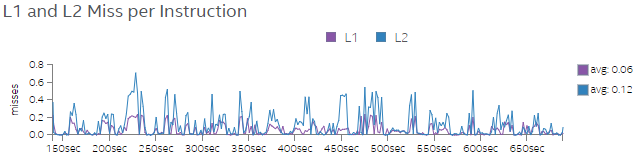
図 6. Test 1 の命令ごとの L1 および L2 ミス率
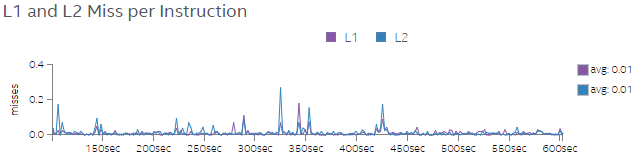
図 7. Test 2 の命令ごとの L1 および L2 ミス率
図 8 は Test 3 のメモリー使用グラフを示しています。ほかのテストでも同様のメモリー使用パターンが観察できます。メモリー使用は 15 ~ 25 パーセントで、キャッシュされたメモリーは 45 ~ 60 パーセントです。Spark* は、中間結果を後処理のためメモリーに格納するため、キャッシュされたメモリーの利用率が高いことが分かります。

図 8. Test 3 のメモリー利用率
最後に、図 9 から図 12 に、4 つのテストのディスク利用率を示します。4 つのテスト実行では、後のテストのほうがワーク量が多く、ディスク速度が速いほどテストのパフォーマンスが向上することが分かります。トランザクションのバイト数はそれほど多くありませんが、I/O 操作 (iops) は完了の待機にかなりの時間を費やしています。これは、キューの深さグラフで確認できます。ディスクを変更することが困難である場合、スレッド数をさらに増やすことでディスクのアクセス・レイテンシーを緩和するのに役立ちます。
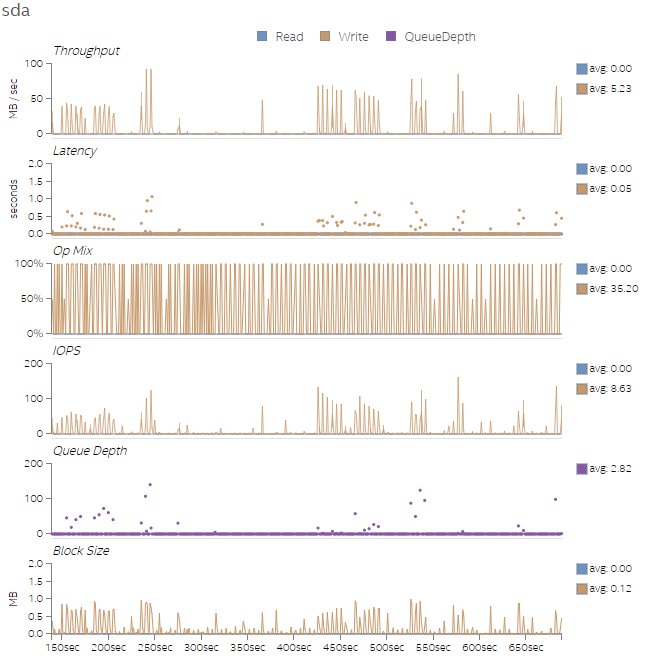
図 9. Test 1 のディスク利用率
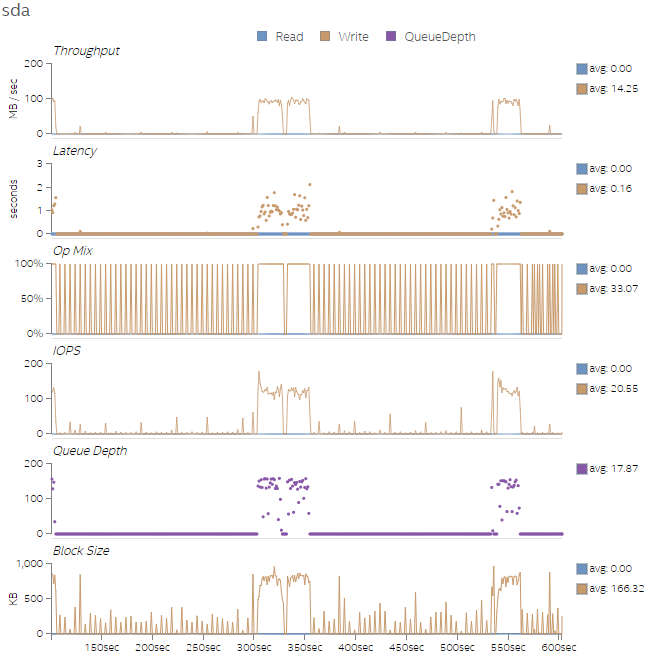
図 10. Test 2 のディスク利用率
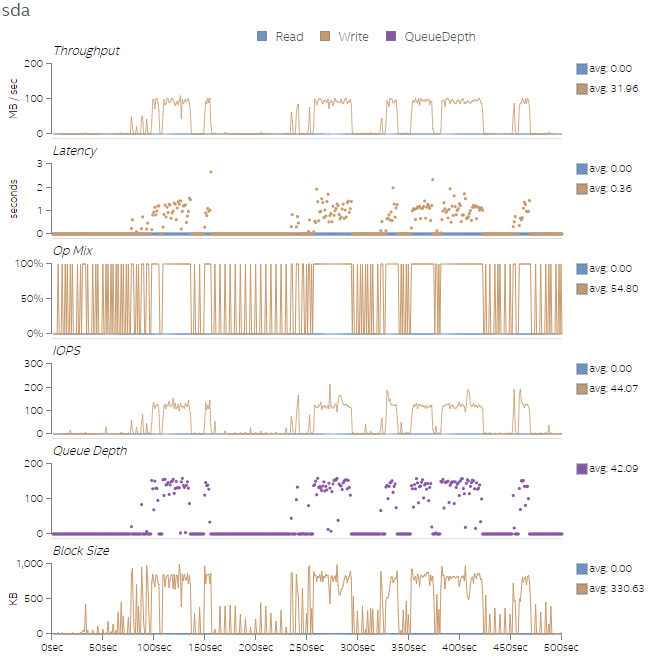
図 11. Test 3 のディスク利用率
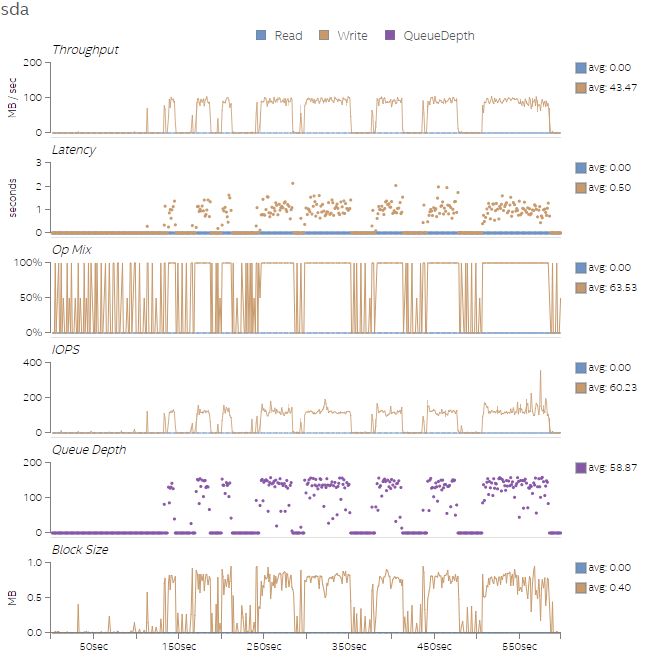
図 12. Test 4 のディスク利用率
まとめ
プラットフォーム・プロファイラーを使用して、映画推奨システムにおけるワークロードの実行を観察し、特定のパフォーマンス・メトリックが異なるスレッド数とドライバーのメモリー設定でどのように変化するか理解できました。さらに、Spark* アプリケーションはインメモリーで実行されるように設計されていることから、ワークロードの実行中に多数のディスク書き込みが行われることが分かりました。コードをさらに詳しく調査するため、インテル® VTune™ Amplifier のディスク I/O 解析を実行して、ディスクの I/O パフォーマンスを観察することを推奨します。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
