
この記事は、The Parallel Universe Magazine 47 号に掲載されている「Efficient Heterogeneous Parallel Programming Using OpenMP*」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

GPU などのアクセラレーターに計算をオフロードすると、オフロードした計算が終了するまでホスト CPU がアイドルになるケースがあります。しかし、CPU と GPU のリソースを同時に使用することで、アプリケーションのパフォーマンスを向上させることができます。ヘテロジニアス並列処理を利用する OpenMP* プログラムでは、master 節 (注: OpenMP* 5.1 仕様以降では masked に変更されています) を使用して CPU と GPU を同時に実行できます。この記事では、OpenMP* を使用して CPU と GPU で非同期計算を行う方法を紹介します。
SPEC ACCEL* 514.pomriq (英語) MRI 再構成ベンチマークは、C 言語で記述され、OpenMP* で並列化されています。このベンチマークは、一部の計算をアクセラレーターにオフロードしてヘテロジニアス並列処理を実行できます。この記事では、ホスト CPU とインテルのディスクリート GPU に計算を分割し、両方のプロセッサーがビジー状態になるようにします。また、インテル® VTune™ プロファイラーを使用して、CPU と GPU の利用率を測定し、パフォーマンスを解析します。
ここでは、ヘテロジニアス並列処理の開発とパフォーマンス・チューニングの 5 つのステージを紹介します。
- 並列化に適したコード領域を探します。
- CPU と GPU の両方がビジーになるように、これらの領域を並列化します。
- 最適な作業配分係数を見つけます。
- この配分係数でヘテロジニアス並列アプリケーションを起動します。
- パフォーマンスの向上を測定します。
最初は、並列領域は GPU でのみ実行され、CPU はアイドルになります (図 1)。ご覧の通り、CPU では「OMP Primary Thread」のみが実行され、GPU は ComputeQ オフロードカーネルでフル稼働 ([GPU Execution Units] > [EU Array] > [Active]) している状態です。
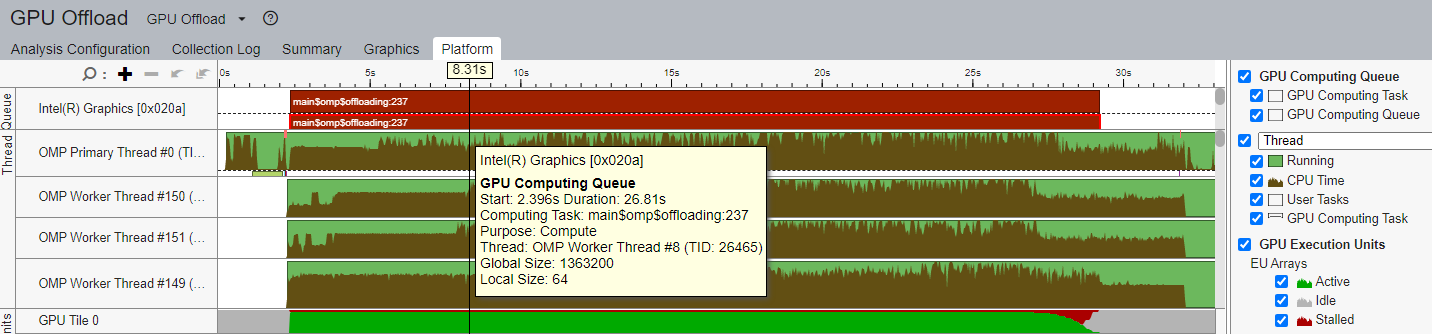
図 1. インテル® VTune™ プロファイラーで初期コードをプロファイルした結果
コードを調べた結果、各配列と各実行領域を複製し、1 つ目のコピーが GPU で実行され、2 つ目が CPU で実行されるようにしました。プライマリー・スレッドは OpenMP* target ディレクティブを使用して、GPU に作業をオフロードします。これを図式化したのが図 2 です。nowait ディレクティブは、CPU と GPU で実行されるスレッド間の不要な同期を回避し、スレッド間のロードバランスを向上します。
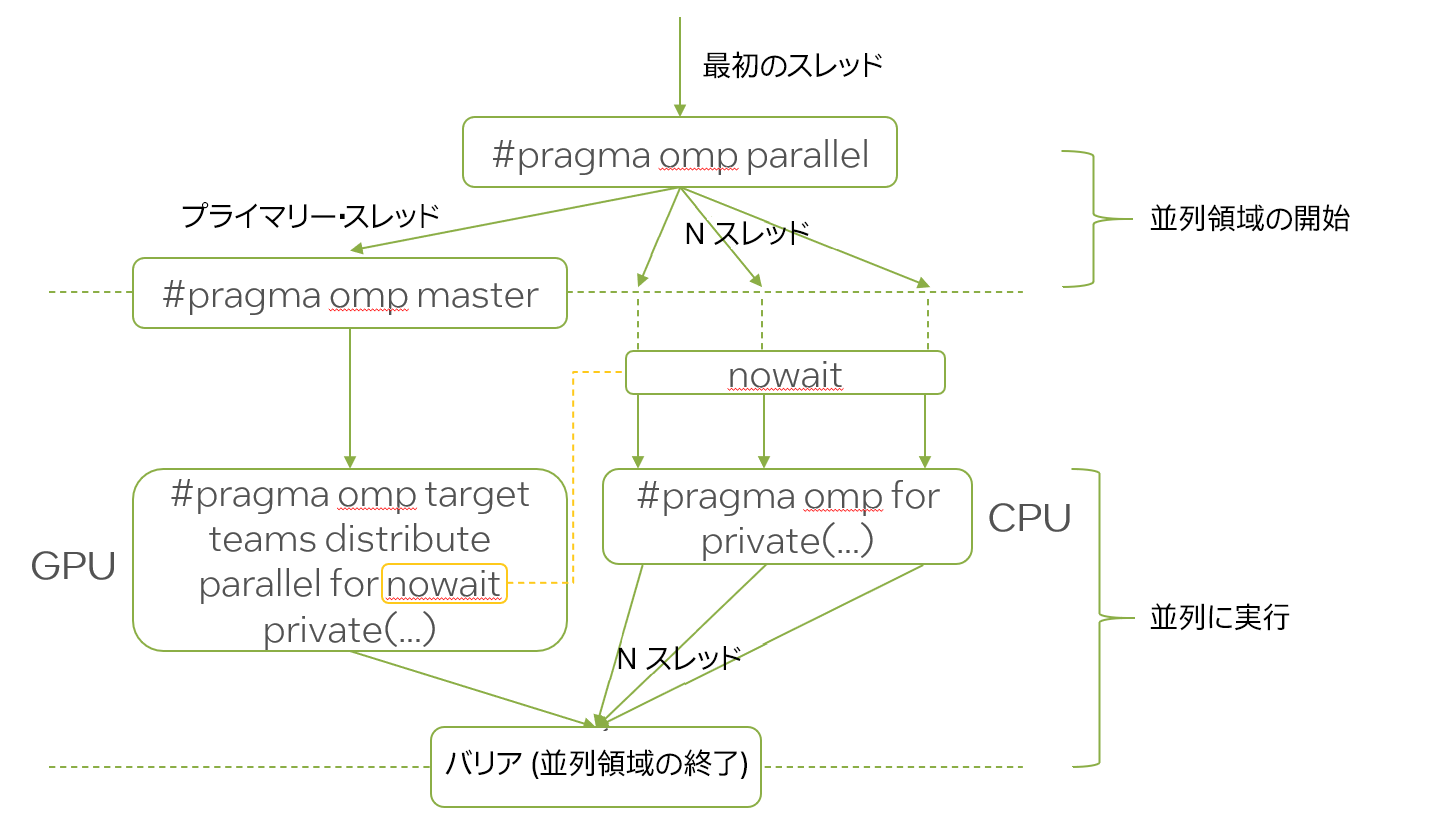
図 2. CPU と GPU をビジーに保つ OpenMP* 並列処理スキーム
CPU と GPU の作業配分のバランスは、stdin から読み込まれる part 変数で調節されます (図 3)。この変数は、GPU にオフロードされるワークロードの割合に numX を掛けた値になります。残りの作業は CPU で行われます。OpenMP* ヘテロジニアス並列処理の実装例を図 4 に示します。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
