
この記事は、『The Parallel Universe Magazine 45 号』に掲載されている「Reduction Operations in Data Parallel C++」の日本語参考訳です。

前号の記事「データ並列 C++ のリダクション操作」では、総和演算子を使用して 1,000 万要素の配列を単一の値にレデュースするカーネル数を調査しました。この記事では、マルチブロック・インターリーブ・リダクションと呼ばれる別のリダクション手法を紹介します。第 9 世代と第 12 世代のインテル GPU でインテル® VTune™ プロファイラーを使用してすべてのリダクション操作を比較し、カーネル間のパフォーマンスの違いの理由を説明します。
マルチブロック・インターリーブ・リダクション
データ並列 C++ (DPC++) では、ショートベクトルをロード/ストアや算術演算子の操作が定義された基本データ型として定義しています。これらのショートベクトルを使用して別のレベルのブロックを追加し、サポートするアーキテクチャー向けに非常に長いベクトル演算をコンパイラーに生成させることができます。vec<int, 8> データ型は、8 つの整数からなるベクトルです。このデータ型を使用して、図 1 に示すリダクション操作を実装します。図に示すように、アクセスパターンはベクトルサイズが 2、サブグループ・サイズが 4 で、ワーク項目ごとに入力ベクトルの 4 要素を処理します。
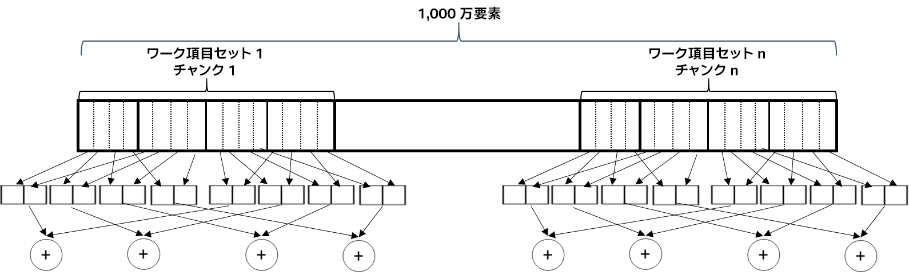
図 1. 要素のベクトルを読み込み、その要素に対してベクトル・リダクション操作を行い、最終結果のベクトルをレデュース
以下のコードは、ベクトルサイズ 8、サブグループ・サイズ 16 で、ワーク項目ごとに入力ベクトルの 256 要素を処理する、上記のメモリー・アクセス・パターンのリダクション操作を実装します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | void multiBlockInterleavedReduction(sycl::queue &q, sycl::buffer<int> inbuf, int &res) { const size_t data_size = inbuf.get_size()/sizeof(int); int work_group_size = q.get_device().get_info<sycl::info::device::max_work_group_size>(); int elements_per_work_item = 256; int num_work_items = data_size / elements_per_work_item; int num_work_groups = num_work_items / work_group_size; sycl::buffer<int> sum_buf(&res, 1); q.submit([&](auto &h) { const sycl::accessor buf_acc(inbuf, h); sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::noinit); sycl::accessor<sycl::vec<int, 8>, 1, sycl::access::mode::read_write, sycl::access::target::local> scratch(work_group_size, h); h.parallel_for(sycl::nd_range<1>{num_work_items, work_group_size}, [=](sycl::nd_item<1> item) [[intel::reqd_sub_group_size(16)]] { size_t glob_id = item.get_global_id(0); size_t group_id = item.get_group(0); size_t loc_id = item.get_local_id(0); sycl::ONEAPI::sub_group sg = item.get_sub_group(); size_t sg_size = sg.get_local_range()[0]; size_t sg_id = sg.get_group_id()[0]; sycl::vec<int, 8> sum{0, 0, 0, 0, 0, 0, 0, 0}; using global_ptr = sycl::multi_ptr<int,sycl::access::address_space::global_space>; int base = (group_id * work_group_size + sg_id * sg_size) * elements_per_work_item; for (size_t i = 0; i < elements_per_work_item / 8; i++) sum += sg.load<8>(global_ptr(&buf_acc[base + i * 8 * sg_size])); scratch[loc_id] = sum; for (int i = work_group_size / 2; i > 0; i >>= 1) { item.barrier(sycl::access::fence_space::local_space); if (loc_id < i) scratch[loc_id] += scratch[loc_id + i]; } if (loc_id == 0) { int sum=0; for (int i = 0; i < 8; i++) sum += scratch[0][i]; auto v = sycl::ONEAPI::atomic_ref<int, sycl::ONEAPI::memory_order::relaxed, sycl::ONEAPI::memory_scope::device, sycl::access::address_space::global_space>( sum_acc[0]); v.fetch_add(sum); } }); });} |
このカーネルは、明示的にアドレスを計算する代わりに、ベクトルロード操作を使用してエンコードすることもできます。また、各ワーク項目がロードしたベクトルを最初にローカルでレデュースするように変更することもできます(この実装のアクセスパターンを図 2 に示します)。
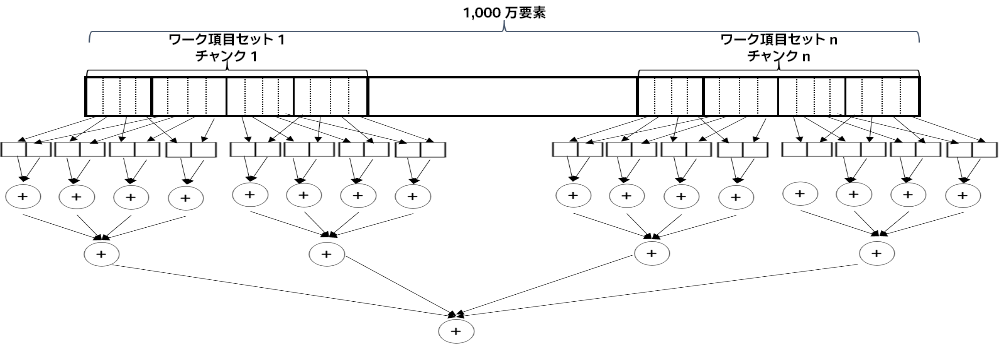
図 2. 要素のベクトルを読み込み、ベクトルを単一の結果にレデュースしてからリダクションを行う
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | void multiBlockInterleavedReductionVector(sycl::queue &q, sycl::buffer<int> inbuf, int &res) { const size_t data_size = inbuf.get_size()/sizeof(int); int work_group_size = q.get_device().get_info<sycl::info::device::max_work_group_size>(); int elements_per_work_item = 256; int num_work_items = data_size / 4; int num_work_groups = num_work_items / work_group_size; sycl::buffer<int> sum_buf(&res, 1); q.submit([&](auto &h) { const sycl::accessor buf_acc(inbuf, h); sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::noinit); sycl::accessor<int, 1, sycl::access::mode::read_write, sycl::access::target::local> scratch(1, h); h.parallel_for(sycl::nd_range<1>{num_work_items, work_group_size}, [=](sycl::nd_item<1> item) [[intel::reqd_sub_group_size(16)]] { size_t glob_id = item.get_global_id(0); size_t group_id = item.get_group(0); size_t loc_id = item.get_local_id(0); if (loc_id==0) scratch[0]=0; sycl::vec<int, 4> val; val.load(glob_id,buf_acc); int sum=val[0]+val[1]+val[2]+val[3]; item.barrier(sycl::access::fence_space::local_space); auto vl = sycl::ONEAPI::atomic_ref<int, sycl::ONEAPI::memory_order::relaxed, sycl::ONEAPI::memory_scope::work_group, sycl::access::address_space::local_space>( scratch[0]); vl.fetch_add(sum); item.barrier(sycl::access::fence_space::local_space); if (loc_id==0) { auto v = sycl::ONEAPI::atomic_ref<int, sycl::ONEAPI::memory_order::relaxed, sycl::ONEAPI::memory_scope::device, sycl::access::address_space::global_space>( sum_acc[0]); v.fetch_add(scratch[0]); } }); });} |
リダクション・カーネルのパフォーマンス解析
これらのカーネルのパフォーマンスを評価するため、2 つの異なるインテル GPU で実行します。
- インテル® HD グラフィックス 630(第 9 世代統合グラフィックス、略称 Gen9)。この GPU には 24 の実行ユニット(EU)が搭載されており、それぞれ 7 スレッドを利用できます。
- インテル® Iris® Xe グラフィックス(第 12 世代統合グラフィックス、略称 Gen12)。この GPU には 96 の実行ユニット(EU)が搭載されており、それぞれ 7 スレッドを利用できます。
インテル® VTune™ プロファイラーを使用してカーネルのパフォーマンスを解析します。また、カーネルの実行時間を長くして適切なプロファイル・データを収集できるように、大規模なリダクション(1,000 万要素の代わりに、5.12 億要素)を実行します。各カーネルのパフォーマンスを表 1 に示します。これは、各カーネルを 16 回実行して、平均パフォーマンスを記録したものです。データの収集には、インテル® oneAPI ベース・ツールキット(v2021.2.0)を使用しました。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
