

この記事は、The Parallel Universe Magazine 38 号に掲載されている「Detecting and Mitigating False Sharing in Multi-Processors」の日本語参考訳です。

現在、コアごとに複数のローカルキャッシュ階層を持つ、マルチコア、シングルノードのシステムが一般的になっています。平均的なラップトップには少なくとも 2 つ以上のコアが備わっており、サーバーシステムでは数十のコアに至ります。ソフトウェアは、マルチスレッドによってこれらのコアを利用します。スレッドは共通アドレス空間の共有データ構造で動作するため、異なるコアのローカルキャッシュに存在するデータのコピーを互いに調整する必要があります。例えば、2 つのスレッドが同じメモリー位置にアクセスする場合、メモリー・サブシステムはスレッドがローカルキャッシュに存在するデータのコピーを更新する際に、検証して更新する必要があります (これは、マルチスレッド・プログラムが共有メモリーのアトミック更新を保証するために使用する同期メカニズムとは関連性がありません)。メモリー・サブシステムは、複雑なキャッシュ一貫性プロトコルを実装することで、この一貫性を保証します。これは、複数のスレッドが共有メモリーにアクセスして更新を行う際に、パフォーマンスに影響します。
この記事では、キャッシュの一貫性プロトコルと、それらがマルチスレッド・プログラムのパフォーマンスに与える影響について説明します。
キャッシュとキャッシュの一貫性プロトコル
キャッシュは、メインメモリーの頻繁にアクセスされる場所のコピーを保持するため、CPU が備える少容量ですが高速なメモリーの一種です。マルチコアシステムでは、すべての CPU にメインメモリーのコピーを保持する個別のキャッシュが備わっています。プログラムの正当性を維持するため、CPU は実行中にこれらのキャッシュの内容を相互に同期および更新します。データは通常、64 バイトまたは 128 バイトのブロック単位でメモリーからキャッシュに転送されます。CPU がメモリーを読み書きする場合、最初にキャッシュラインのいずれかにそのアドレスが存在するか確認します。存在する場合、CPU はそのキャッシュラインをフェッチします。存在しない場合は、以降に使用することを想定し新しいキャッシュラインのエントリーが割り当てられます。
マルチコアマシンでは、CPU がメモリーからデータを取り込むかどうか決定する前に、ローカルキャッシュだけでなく他のコアのキャッシュをチェックする必要があります。すべてのコアのすべてのキャッシュにわたってメモリーアクセスごとに生じるチェックの回数を減らすため、すべてのキャッシュラインには特定の情報が保持されています。この情報は MESI (変更 (Modified)/排他 (Exclusive)/共有 (Shared)/無効 (Invalid)) として知られています。
キャッシュラインが最初にロードされると、CPU はそのキャッシュラインを「排他 (Exclusive)」アクセスとしてマークします。排他モードである限り、以降のロードはすべてこのデータにアクセスします。同じキャッシュラインが別の CPU によってロードされると、キャッシュラインはすべての CPU のキャッシュで「共有 (Shared)」としてマークされます。CPU が「共有 (Shared)」 としてマークされたキャッシュラインに書き込みを行うと、キャッシュラインは「変更 (Modified)」としてマークされ、他のすべての CPU に「無効 (Invalid)」メッセージが送られます。「変更 (Modified)」としてマークされたキャッシュラインに別の CPU がアクセスすると、キャッシュラインはメモリーにストアされ「共有 (Shared)」としてマークされます。同じキャッシュラインにアクセスする他の CPU はキャッシュミスを引き起こし、メインメモリーから更新されたコピーをフェッチします。
別の CPU で「変更 (Modified)」状態のキャッシュであるメモリー位置に CPU がアクセスすると、以下が発生することが分かります。
- メモリーへの書き込み
- メモリーからの読み取り
異なるコアで実行される複数のスレッドがアクセスするメモリー位置では、これは最新の値を提供し、メモリーモデルの一貫性を保証するために必要です。
効率のため、キャッシュの一貫性プロトコルは、個別のバイト単位ではなくキャッシュライン単位で動作します。これにより、フォルス・シェアリング (偽共有) と呼ばれる現象が発生します (図 1)。フォルス・シェアリングでは、同じキャッシュラインに存在する異なるメモリー位置にアクセスするスレッドにもキャッシュ一貫性プロトコルのメカニズムが適用されるため、パフォーマンスが低下します。場合によっては、このパフォーマンス・ペナルティーは大きくなる可能性があります。
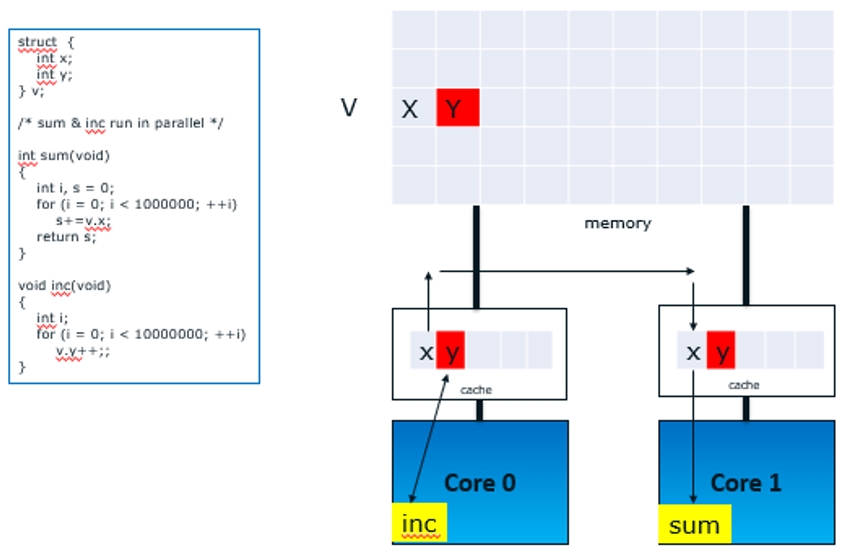
図 1 マルチコアシステムのフォルス ・ シェアリング
図 1 では、コア 0 とコア 1 で実行されるスレッド sum と inc は、同じキャッシュラインにある異なる 2 つのメモリー位置にアクセスします。キャッシュ一貫性プロトコルは、キャッシュライン単位で動作するため inc スレッドが y にアクセスした後に、sum スレッドが x にアクセスするたびに、2 つのスレッドが同じ変数にアクセスしているかのようにパフォーマンス・ペナルティーが生じます。
キャッシュ間の共有を検出
インテル® プロセッサーのパフォーマンス監視ユニット (PMU) には、プログラムの実行中にマイクロアーキテクチャーで発生する各種イベントを監視する機能があります。システム上の他の CPU キャッシュの「変更 (modified)」、「排他 (exclusive)」、または「共有 (shared)」状態のメモリー位置の参照に関連するいくつかのイベントがあります。これらのイベントは ‘HIT<M/E/S>’ という文字列が示されます。このイベントを監視することで、コア間のキャッシュライン相互参照があるか確認できます。例えば、開発コード名 Goldmont (英語) マイクロアーキテクチャー・ベースのプラットフォームでは、MEM_UOPS_RETIRED.HITM イベントを監視することで、他の CPU キャッシュの変更状態のキャッシュラインへの参照数を知ることができます。また、開発コード名 Skylake マイクロアーキテクチャー・ベースのプロセッサーでは、いくつかのイベントを調べそれらに数式を適用することで、フォルス・シェアリングを監視できます (インテル® VTune™ Amplifier は、必要なすべてのメトリックを自動的に計算します)。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
