

この記事は、インテルの The Parallel Universe Magazine 26 号に収録されている、さまざまなツールと手法によりマシンラーニングで Python* のパフォーマンスを向上する方法に関する章を抜粋翻訳したものです。
協調フィルタリングによるパフォーマンスの高速化
インテルは、革新的なツール、手法、最適化により、Python* パフォーマンスを高速化するため、マルチコアおよび SIMD 並列処理向けのハイパフォーマンス・ライブラリー、プロファイラー、拡張サポートを提供します。ここでは、協調フィルタリングを使用して、実際のマシンラーニング・アプリケーションのパフォーマンスを高速化します。
結果は、これらの最適化を利用することで Python* でネイティブコードに近いパフォーマンスを達成できることを示しています。つまり、パフォーマンスを向上するため、C/C++ でコードを書き直す必要はありません。
問題を理解する
Python* の人気
Python* は、その生産性の高さから、着実に採用が進んでいます。2016 年の CodeEval.com の投票では、Python* が開発者に最も人気のある言語に選ばれました。2 位は Java*、3 位は C++ でした (図 1)。1 Python* の表現力とコーディングの容易さは、開発者にとってプロトタイプ環境として魅力的です (図 2)。2,3
Python* を使用することで、クオンツアナリストによる取引アルゴリズムの開発、データ・サイエンティストによる解析モデルの構築、研究者による数値シミュレーションのプロトタイプ生成が可能になります。
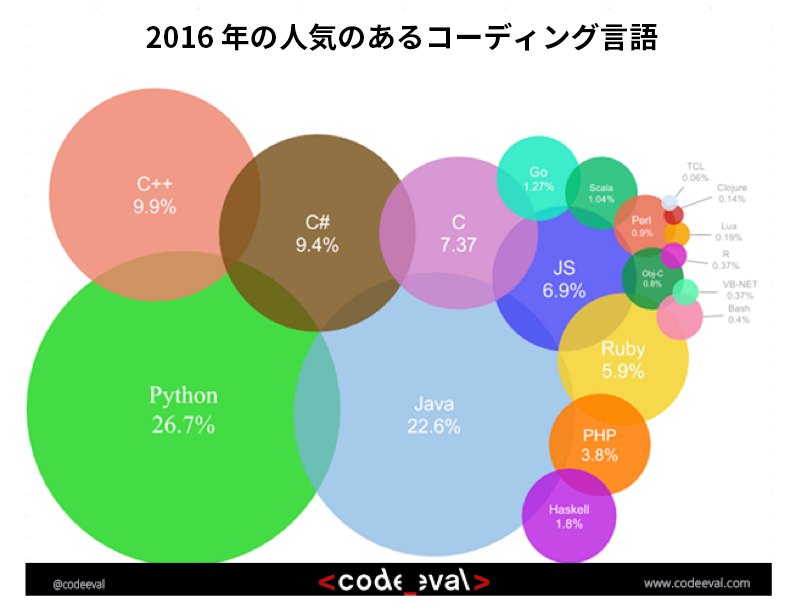
図 1. 2016 年 2 月現在、最も人気があるコーディング言語 (出典: www.codeeval.com (英語))
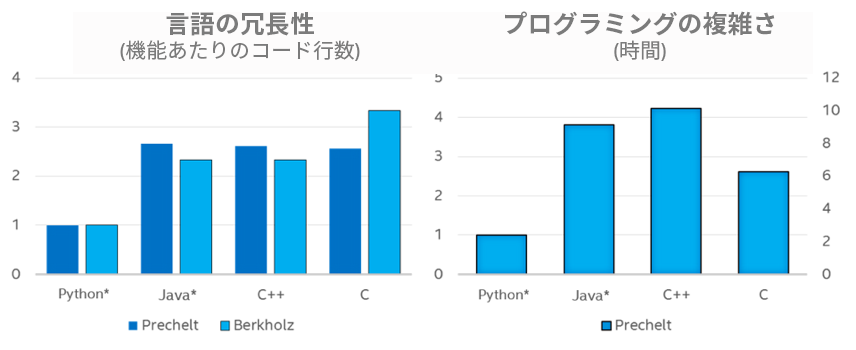
図 2. プログラミング言語の生産性
Python* パフォーマンスの問題
Python* のパフォーマンスとスケーラビリティーの問題により、通常プロトタイプ・コードをプロダクション・コードにスケーリングするため、開発者は C++ または Java* のような言語でアルゴリズムを書き直す必要があります。例えば、Python* では、評判が悪いグローバル・インタープリター・ロック (GIL) により、効率良い並列コードを記述することができません。アプリケーション・コードの書き直しは、労力と時間がかかるだけでなく、柔軟性を損ない、エラーにつながる可能性があります。
パフォーマンスの問題のほとんどは、Python* インタープリターの実装が現代のハードウェアに対応していないためです。インタープリターは、多種多様なハードウェア・プラットフォームで実行する必要があるため、多くの場合、インテル® ストリーミング SIMD 拡張命令 (インテル® SSE) やインテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) のような CPU 固有の機能を効率良く利用するようにチューニングされていません。
さらに、Python* は、キャッシュの局所性を考慮して実装されていません。そのため、連続するデータがシーケンシャルに格納されず、データアクセスには多くのポインターの逆参照などが必要になります。これらはすべて、Python* インタープリターが最近のハードウェア・プラットフォーム上で優れたパフォーマンスを達成する妨げとなります。
Python* の問題と制限に対する既知のソリューション
前述のパフォーマンスの問題は通常、Numba のような JIT コンパイラーを使用したり、NumPy*、SciPy*、scikit-learn パッケージの C 拡張を使用して対応できます。これらの Python* パッケージは、ハードウェアを最大限に利用できるように、スレッド対応で高度に最適化されており、パッケージを使用することで、Python* 開発者はアイデアを明確かつ簡潔に表現することができます。
ネイティブにコンパイルされるプログラミング言語を使用する場合、すべての CPU リソースを効率良く利用するのは、一般に開発者の責任です。しかし、多くの Python* 開発者は、アルゴリズムの最適化と並列化に多くの知識を持ち合わせていません (そして、それらの知識の習得は不要であるべきです)。そのため、ライブラリーを通してこれらの最適化を利用するのが簡単です。しかし、NumPy*、SciPy*、scikit-learn のようなライブラリーの標準実装は、汎用化されているため、通常対象とするハードウェアの機能を最大限に引き出せません。例えば、最近のベクトル命令をすべて使用することができません。4
Python* コミュニティーへのインテルの貢献
インテルは、Python* のパフォーマンスの課題への取り組みとして、多くのツールと手法を通じて、Python* アプリケーションのパフォーマンスを高速化する、強力で簡単に使えるソリューションを開発者に提供しています。インテル® マス・カーネル・ライブラリー (インテル® MKL)、インテル® スレッディング・ビルディング・ブロック (インテル® TBB)、OpenMP* 標準の実装、MPI 標準の実装、インテル® Data Analytics Acceleration Library (インテル® DAAL) を含む、ハイパフォーマンス・アプリケーションの開発を支援する数々のライブラリーに加えて、インテル® VTune™ Amplifer XE などのプロファイリング・ツールがあります。しかし、最近まで、これらの言語とツールのほとんどは、C/C++/Fortran でのみ利用することができました。
インテルは、インテル® MKL を利用して NumPy* のようなパッケージの数値計算を最適化した、インテル® Distribution for Python* で Python* 開発者にこれらの強力なツールと手法の提供を開始しました。また、効率良いタスク・スケジューラーによりスレッド処理の調整を行うマルチスレッド・アプリケーションを可能にする Python* 向けのインテル® TBB モジュール5 と、Python* でのビッグデータ解析を支援する Python* 向けのインテル® DAAL モジュール (pyDAAL) もリリースされました。人気のパフォーマンス・アナライザー インテル® VTune™ Amplifer XE では、Python*/C/C++/Fortran が混在するアプリケーションのプロファイルがサポートされ、アプリケーションのパフォーマンスを検証し、自明/非自明の対応可能なボトルネックを特定できるようになりました。
