

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「The hidden performance cost of accessing thread-local variables」(http://software.intel.com/en-us/blogs/2011/05/02/the-hidden-performance-cost-of-accessing-thread-local-variables/) の日本語参考訳です。
コードを並列化した後に期待していたパフォーマンスが得られなかったことはありませんか? これは、誰もが経験のあることだと思います。最近、私が学んだコツは、最初にインテル® VTune™ Amplifier XE の Lightweight Hotspot (ライト Hotspot) 解析を実行してコードのパフォーマンス情報を取得することです。そうすることで、クロック数とリタイアした命令数が表示され、アプリケーションで時間のかかっている関数 (hotspot) が分かります。厳密なコールグラフ解析とは違い、インテル® VTune™ Amplifier XE の Lightweight Hotspot 解析は非常に高速で、アプリケーションをインストルメントしません。アプリケーションのことをよく分かっているつもりでも、この解析からアプリケーション の動作について思いがけない発見があるかもしれません。
実際に、私は DreamWorks Animation* のファーシェーダー (毛などのふさふさした質感を表す手法) の並列化を行ったときに思いがけない発見をしました。ファーシェーダーは、数百万以上の毛を生成し、テッセレーション処理とラスタライズ処理を行います。さらに、形状評価ライブラリーを使用して、毛の形状を評価し、基準値や微分係数などを計算します。この形状評価ライブラリーは長年に渡って開発されたものでした。
このコードをインテル® VTune™ Amplifier XE でプロファイルしたところ、最も時間のかかる関数 “__tls_get_addr” であっても合計 CPU 使用率の 5% を占めるのみという結果になりました。しかしながら、ほとんどのシーンでファーを使用しており、数百万以上の毛の生成はレンダリング時間の大半を占めるため、わずかな最適化でもレンダリング時間に大きく影響します。“__tls_get_addr” 関数とはどのような関数なのでしょうか? これは、スレッドローカル変数のアドレスを取得する Linux* カーネル関数です。この関数のコストは小さくあるべきです。いったい何が起こったのでしょうか?
“__tls_get_addr” の呼び出し位置を特定するため、次にスタックとコールツリー情報を取得するインテル® VTune™ Amplifier XE の Hotspot 機能を使用しました。コールツリーから、“__tls_get_addr” の呼び出しのほとんどが DreamWorks Animation* の形状評価ライブラリーで発生していることが分かりました。このライブラリーのグローバル変数へアクセスしていたのです。これらのグローバル変数は、最近このライブラリーをスレッドセーフにしたときに、スレッドローカル変数に変更されました。
グローバル変数からスレッドローカル変数への変更は簡単です。変数宣言の前にキーワード “__thread” を追加するだけです。例えば、”__thread int count” のようにします。これは、レガシー・ライブラリーを使用する並列コードを記述しており、スレッドセーフに対応するためレガシー・ライブラリーを再設計する時間がない開発者にとって非常に魅力的です。
スレッドローカル変数を使用するコスト
通常、スレッドローカル変数を使用するコストはわずかで、開発者が気にすることはないでしょう。しかし、スレッドローカル変数に頻繁にアクセスする場合は問題になります。
スレッドローカル変数へのアクセスコストがどこで発生しているのかを理解するためには、コンパイラーがスレッドローカル変数をどのように実装するのかを理解する必要があります。コンパイラーは、各スレッドローカル変数に一意のグローバル ID を割り当て (この ID は各スレッドで同じ)、スレッドごとにスレッド・ローカル・ストレージ (TLS) のルックアップ・テーブルを保持します。このグローバル ID は、スレッドローカル変数のアドレスを検索するのに使用されます。つまり、スレッドローカル変数を使用する場合、関数呼び出しとインデックス・テーブルの検索のコストも発生します。
スレッドローカル変数へのアクセスコストを示す簡単な例
次の例 (tlb.cpp) について考えてみましょう。
#include "stdio.h"
#include "math.h"
__thread double tlvar;
//コンパイラーにより get_value() がインライン展開されないようにするためには次の行が必要
double get_value() __attribute__ ((noinline));
double get_value()
{
return tlvar;
}
int test()
{
double f=0.0;
tlvar = 1.0;
for(int i=0; i < 1000000000; i++)
{
f += sqrt(get_value());
}
printf("f = %f\n", f);
return 1;
}
DreamWorks Animation* の開発環境を模倣するため、次のインテル® コンパイラー (ICC) コマンドを使用して共有ライブラリーを作成します:
icpc tlb.cpp -c -o tlb.o -fPIC -g
icpc -shared -o tlb.so tlb.o
main.cpp は関数 test を module tlb.so で呼び出します。
void test();
int main()
{
test();
return 1;
}
次のコマンドで実行ファイルをビルドします:
"icpc main.cpp tlb.so -o tlb-no-inline"
インテル® VTune™ Amplifier XE でこのプログラムを調べたところ、”__tls_get_addr” が合計 CPU 時間の 25% を占める 2 番目に時間のかかる関数として報告されました (以下の表を参照)。
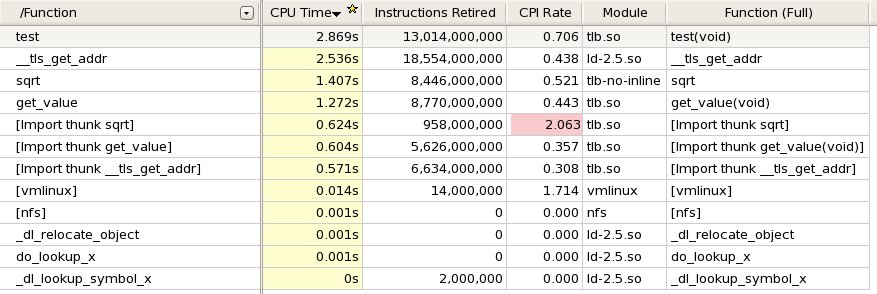
スレッドローカル変数へのアクセスコストを最小限に抑える
ファイル tlb.cpp を注意して見てみると、関数 “get_value” に属性 "noinline" が指定されていることに気付きます。これは、DreamWorks Animation* のアプリケーションにおける特定の関数のスレッドローカル変数へのアクセスを模倣するために私が追加したものです。この関数は、インテル® C++ コンパイラーによって自動でインライン展開されません。上記の例で関数 “get_value” はインライン展開されないため、この関数がスレッドローカル変数 "tlvar" にアクセスするたびに関数 “__tls_get_addr” が呼び出されます。
関数 “__tls_get_addr” のコストを軽減するのはそれほど難しくありません。キーワード “__forceinline” を使用して、コンパイラーに関数 “get_value” をインライン展開するように指示します。新しいコードは次のようになります。
#include "stdio.h"
#include "math.h"
__thread double tlvar;
__forceinline double get_value()
{
return tlvar;
}
int test()
{
double f=0.0;
tlvar = 1.0;
for(int i=0; i < 1000000000; i++)
{
f += sqrt(get_value());
}
printf("f = %f\n", f);
return 1;
}
関数 “get_value” がインライン展開されるため、インテル® C++ コンパイラーは “for” ループ内にスレッドローカル変数へアクセスする呼び出しがあり、それが常に同じ値を返すことを把握します。その結果、コンパイラーはこの呼び出しを “for” ループの外側に移動します。これで、関数 “__tls_get_addr” への呼び出しだけになります。
次の表に、コード変更後のインテル® VTune™ Amplifier XE の Lightweight Hotspot のデータを示します。関数 “__tls_get_addr” と関数 “get_value” が hotspot リストに表示されなくなりました。
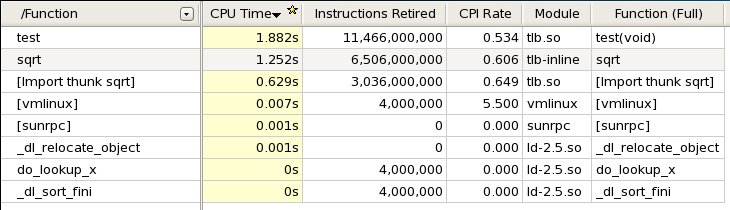
何らかの理由により関数 “get_value” をインライン展開できない場合でも、スレッドローカル変数へのアクセスコストを減らすことはできるのでしょうか? もちろんできます。この例では、スレッドローカル変数は読み取り専用ですが、次のように、“for” ループの外でスレッドローカル変数をローカル変数に割り当て、ループ内でそのローカル変数を使用することができます。
__thread double tlvar;
double get_value() __attribute__ ((noinline));
double get_value()
{
return tlvar;
}
int test()
{
double tmp, f=0.0;
tlvar = 1.0;
tmp = get_value();
for(int i=0; i < 1000000000; i++)
{
f += sqrt(tmp);
}
printf("f = %f\n", f);
return 1;
}
まとめ
上記の簡単な例を通して、スレッドローカル変数に頻繁にアクセスする場合の隠されたコストがお分かりいただけたかと思います。場合によっては、このコストは大きなものになります。このコストを減らすためには、前述のように、コンパイラーによる “__tls_get_addr” の呼び出し回数を最小限に抑えるべきです。インテル® VTune™ Amplifier XE のプロファイルで “__tls_get_addr” 関数に時間がかかっている場合は、スレッドローカル変数に頻繁にアクセスしている関数を確認し、ここで説明した手法を試してみてください。
