

この記事は、インテル® デベロッパー・ゾーンに掲載されている「Combiner/Aggregator Synchronization Primitive」(http://software.intel.com/en-us/blogs/2013/02/22/combineraggregator-synchronization-primitive) の日本語参考訳です。
2012 年 5 月に Terry Wilmarth が「Aggregators in TBB (TBB の aggregator)」(http://software.intel.com/en-us/blogs/2012/05/02/aggregator-a-new-community-preview-feature-in-intel-threading-building-blocks) という記事を投稿しました。ここでは、aggregator パターンの設計について述べます。この記事では多数のコードを示し、また combiner という用語を使います。
combiner は、mutex に似た排他制御プリミティブですが、これを利用することで、クリティカル・セクション関数を明示的に渡して、より柔軟に実行することができます。つまり、スレッドは、別のスレッドの代わりにクリティカル・セクションを実行することができます。次の簡単な使用例について考えてみます。
1 2 3 4 5 | combiner_t* c = combiner_create(&my_critical_section);...combiner_execute(c, &arg);// この時点で my_critical_section(&arg) 関数は実行済みですが // 必ずしも現在のスレッドで実行されたとは限りません。 |
これは、次のコードに似ています。
1 2 3 4 5 | mutex_t *m = mutex_create();…mutex_lock(m);my_critical_section(&arg);mutex_unlock(m); |
果たして、combiner は mutex よりも優れているのでしょうか? 異なるスレッドの複数のクリティカル・セクションを 1 つに結合/まとめて (これが combiner/aggregator という名前の由来です)、1 つのスレッドに実行させるとキャッシュのパフォーマンスが大幅に向上します。結合可能なクリティカル・セクションがない場合、このプリミティブは mutex と同じ動作になります。つまり、ロックを取得し、現在のスレッドがクリティカル・セクションを実行して、結合操作があるかどうかをチェックしてからロックを解除し、リターンします。
単純な実装を作成してどのように改善できるか、そしてどのようなアレンジが可能かを見てみましょう。最初に、次のインターフェイスを作成します。
1 2 3 4 5 6 7 8 9 10 | typedef struct combiner combiner_t;typedef struct combiner_arg combiner_arg_t;struct combiner_arg { combiner_arg_t* next;};combiner_t* combiner_create(void (*fn)(combiner_arg_t*));void combiner_destroy(combiner_t* c);void combiner_execute(combiner_t* c, combiner_arg_t* arg); |
関数の作成と破棄は不可欠です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | struct combiner { void (*fn)(combiner_arg_t* arg); combiner_arg_t* head;};combiner_t* combiner_create(void (*fn)(combiner_arg_t*)) { combiner_t* c = (combiner_t*)malloc(sizeof(combiner_t)); c->head = 0; c->fn = fn; return c;}void combiner_destroy(combiner_t* c) { free(c);} |
今回のメイントピックである combiner_execute() を作成します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | #define LOCKED ((combiner_arg_t*)1)void combiner_execute(combiner_t* c, combiner_arg_t* arg) { // c->head には 3 つの状態があります。 // c->head == 0: 実行中の操作なし、初期状態。 // c->head == LOCKED: 1 つの操作を実行中、結合可能な操作なし。 // c->head == 結合対象の combiner_arg_t へのポインター // arg は 'next' フィールドによりロックフリー・リストに繋がれます。 // arg->next にも 3 つの状態があります。 // arg->next == 別の arg へのポインター。 // arg->next == LOCKED: リストの最後の arg // arg->next == 0: 操作完了 // 関数は 3 ステップからなります。 // 1. c->head == 0 の場合、LOCKED にして combiner になります。 // そうでない場合、arg を c->head ロックフリー・リストに追加します。 combiner_arg_t* cmp = __atomic_load_n(&c->head, __ATOMIC_ACQUIRE); for (;;) { combiner_arg_t* xchg = LOCKED; if (cmp) { // すでに combiner がある場合は自身を追加します。 xchg = arg; arg->next = cmp; } if (__atomic_compare_exchange_n(&c->head, &cmp, xchg, 1, __ATOMIC_ACQ_REL, __ATOMIC_ACQUIRE)) break; } // 2.combiner でない場合は arg->next が 0 になるまで待機します。 // (つまり、操作が完了するまで) if (cmp) { while (__atomic_load_n(&arg->next, __ATOMIC_ACQUIRE) != 0) { } // 3.combiner ではありません。 } else { // 最初に、自身の操作を実行します。 c->fn(arg); // 次に、結合可能な操作を探します。 for (;;) { cmp = __atomic_load_n(&c->head, __ATOMIC_ACQUIRE); for (;;) { // リストに操作がある場合は、 // リストを取得して LOCKED にします。 // そうでない場合は 0 にします。 combiner_arg_t* xchg = 0; if (cmp != LOCKED) xchg = LOCKED; if (__atomic_compare_exchange_n(&c->head, &cmp, xchg, 1, __ATOMIC_ACQ_REL, __ATOMIC_ACQUIRE)) break; } // 結合する操作がない場合はリターンします。 if (cmp == LOCKED) break; arg = cmp; // 操作のリストを実行します。 while (arg != LOCKED) { combiner_arg_t* next = arg->next; c->fn(arg); // Mark completion. __atomic_store_n(&arg->next, 0, __ATOMIC_RELEASE); arg = next; } } }} |
この単純な実装は、計算アプリケーションには適していますが、1 つの combiner が無制限の操作数を実行する可能性があるため、その他のアプリケーションには適していません。実際、同時実行中の 31 個のスレッドから要求が殺到し、1 つのスレッドが数百万もの操作を実行したケースもあります。
上限の設定
1 つのスレッドで実行される操作数の上限はいくつに設定すべきでしょうか? 例えば、32 に設定した場合でも、オーバーヘッドをある程度相殺できます。上限を設定するには、combiner パラメーター limit を追加します。
1 2 3 4 5 6 7 8 9 10 11 12 13 | struct combiner { void (*fn)(combiner_arg_t* arg); combiner_arg_t* head; int limit;};combiner_t* combiner_create(void (*fn)(combiner_arg_t*), int limit) { combiner_t* c = (combiner_t*)malloc(sizeof(combiner_t)); c->head = 0; c->fn = fn; c->limit = limit; return c;} |
そして、limit に達したら結合を停止するように、結合アルゴリズムを変更します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | #define LOCKED ((combiner_arg_t*)1)#define HANDOFF 2 // 以下のコメントを参照void combiner_execute(combiner_t* c, combiner_arg_t* arg) { // この部分は同じです。 combiner_arg_t* cmp = __atomic_load_n(&c->head, __ATOMIC_ACQUIRE); for (;;) { combiner_arg_t* xchg = LOCKED; if (cmp) { xchg = arg; arg->next = cmp; } if (__atomic_compare_exchange_n(&c->head, &cmp, xchg, 1, __ATOMIC_ACQ_REL, __ATOMIC_ACQUIRE)) break; } int count = 0; if (cmp) { for (;;) { combiner_arg_t* next = __atomic_load_n(&arg->next, __ATOMIC_ACQUIRE); if (next == 0) break; // 次のポインターの HANDOFF ビットがセットされている場合、 // combiner になります。 if ((unsigned long)next & HANDOFF) { // HANDOFF ビットをリセットして // 正しいポインターを取得できるようにします。 arg->next = (combiner_arg_t*)((unsigned long)arg->next & ~HANDOFF); // リストの残りを結合します。 goto combine; } } } else { c->fn(arg); count++; for (;;) { // この部分は同じです。 cmp = __atomic_load_n(&c->head, __ATOMIC_ACQUIRE); for (;;) { combiner_arg_t* xchg = 0; if (cmp != LOCKED) xchg = LOCKED; if (__atomic_compare_exchange_n(&c->head, &cmp, xchg, 1, __ATOMIC_ACQ_REL, __ATOMIC_ACQUIRE)) break; } if (cmp == LOCKED) break; arg = cmp; combine: while (arg != LOCKED) { // limit に達した場合は // 現在のノードの HANDOFF ビットをセットしてリターンします。 // 残りはノードのオーナーが実行します。 if (count == c->limit) { __atomic_store_n(&arg->next, (combiner_arg_t*)((unsigned long)arg->next | HANDOFF), __ATOMIC_RELEASE); goto done; } combiner_arg_t* next = arg->next; c->fn(arg); count++; __atomic_store_n(&arg->next, 0, __ATOMIC_RELEASE); arg = next; } } done: }} |
インテル® スレッディング・ビルディング・ブロック (インテル® TBB) ライブラリーは、これとは異なる上限設定アプローチを使用します (「tbb/aggregator.h」を参照)。各 combiner スレッドは、操作のバッチを一度だけ取得し、それだけを実行して終了します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | struct combiner { void (*fn)(combiner_arg_t* arg); combiner_arg_t* head; int busy; // 新しいフィールド、以下を参照。};void combiner_execute(combiner_t* c, combiner_arg_t* arg) { // arg をリストに追加します (同じ)。 combiner_arg_t* cmp = __atomic_load_n(&c->head, __ATOMIC_ACQUIRE); for (;;) { arg->next = cmp; if (__atomic_compare_exchange_n(&c->head, &cmp, arg, 1, __ATOMIC_ACQ_REL, __ATOMIC_ACQUIRE)) break; } if (cmp) { // 空でないリストに追加した場合 // combiner ではありません。完了を待機します (同じ)。 while (__atomic_load_n(&arg->next, __ATOMIC_ACQUIRE)) { } } else { // combiner アルゴリズムはやや異なります。 // 前の combiner の完了を待機します。 while (__atomic_load_n(&c->busy, __ATOMIC_ACQUIRE)) { } // 次の combiner が踏み込まないように busy にします。 __atomic_store_n(&c->busy, 1, __ATOMIC_RELAXED); // 操作のバッチを一度だけ取得します。 arg = __atomic_exchange_n(&c->head, 0, __ATOMIC_ACQ_REL); // 操作のセットを実行します。 while (arg) { combiner_arg_t* next = arg->next; c->fn(arg); __atomic_store_n(&arg->next, 0, __ATOMIC_RELEASE); arg = next; } // 次の combiner が先に進めるようにします。 __atomic_store_n(&c->busy, 0, __ATOMIC_RELEASE); }} |
インテル® TBB のアルゴリズムは、1 つのスレッドが無制限の操作数を実行しないようにしますが、(スレッド数のみによって制限されるため) 操作数が大きくなる可能性は残ります。また、同時に、多数の結合の可能性を見逃すことにもなります。まず、combiner は 1 つのスレッドから複数の操作を結合することはできません (複数の操作がある場合は、別々のバッチに含める必要があります)。次に、ほかのスレッドが結合処理中にスレッドが操作を追加しようとすると、(可能な場合であっても) そのバッチには結合されません。この欠点による影響については、「評価」セクションで説明します。
非同期操作
combiner は、ほかにも、操作の非同期実行という興味深い可能性をもたらします。つまり、スレッドは操作結果を必要としない場合 (例えば、コンテナーからノードを追加/削除するだけの場合)、操作をキューに追加して直ちにリターンすることができます。これにより、アルゴリズムが完全に非ブロッキングとなり、スレッドが互いに待機しません。
非同期操作は、アルゴリズムを少し変更するだけで使用できます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | void combiner_execute(combiner_t* c, combiner_arg_t* arg, int async) { // 操作を追加するか、combiner になります。 // 上記と同じため省略。 // ... if (cmp) { // 呼び出し元が結果を必要としない場合はリターンします。 if (async) return; while (__atomic_load_n(&arg->next, __ATOMIC_ACQUIRE) != 0) { } } else { // combiner アルゴリズムは同じです。 // ... }} |
ただし、どのスレッドが arg パラメーターのオーナーとなり、どのようにその割り当てと解放を行うかという問題があります。上記のアルゴリズムでは、呼び出し元のスレッドのスタックで arg を割り当てるのが自然です。しかし、非同期操作では、呼び出し元のスレッドがスタックフレームを破棄した後に arg が使用される可能性があるため、このアプローチは採用できません。
このソリューションはいくつかありますが、最も簡単なものは、arg を malloc() で割り当て、実行後に free() で解放することです。例えば、コンテナーにノードを挿入する場合、そのノードを arg にすることができます。ただし、ここでは、このソリューションではなく、効率良い一般的なソリューションを紹介します: 各スレッドに N 個のローカルな arg オブジェクトがあり、前の非同期操作が終了したら、それらを再利用します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #define N 4static __thread my_combiner_arg_t arg_cache[N];my_combiner_arg_t* get_thread_arg(void) { for (;;) { // 未使用の arg を探します。 for (int i = 0; i < N; i++) { if (__atomic_load_n(&arg_cache[i].base.next, __ATOMIC_ACQUIRE) == 0) return &arg_cache[i]; } }}// この関数は、thread が未処理の操作を待機するべく終了したときに実行します。void wait_for_pending(void) { for (int i = 0; i < N; i++) { while (__atomic_load_n(&arg_cache[i].base.next, __ATOMIC_ACQUIRE)) { } }}void* thread(void* p) { for (...) { my_combiner_arg_t* arg = get_thread_arg(); // ... combiner_execute(c, arg, 1); } wait_for_pending(); return 0;} |
「評価」セクションで詳しく説明しますが、非同期操作によりパフォーマンスが向上します。
スレッドが前の操作の結果を必要とする場合 (例えば、コンテナーにノードを挿入してから、そのノードを検索する場合)、操作のバッチを逆向きにして FIFO (先入れ先出し) 順にする必要があります。そうしないと、非同期操作で挿入の前に検索が行われてしまいます。
フラット結合
最近、2 つの興味深い研究論文が発表されました。1 つは「Flat Combining and the Synchronization-Parallelism Tradeoff (フラット結合と同期並列のトレードオフ)」(http://mcg.cs.tau.ac.il/papers/spaa2010-fc.pdf) です。この論文の趣旨は次のとおりです。上記のアルゴリズムでは、スレッドが CAS 操作を用いて中央のキューに操作を追加するため、必然的に操作ごとにコストが発生します。フラット結合では、各スレッドごとにリスト (配列) へ追加される不変の記述子があり、スレッドは (CAS の代わりに) アトミックなストア操作で操作を追加します。その結果、combiner はすべてのスレッド記述子をポーリングして、「該当する」スレッドを見つける必要があります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | __thread int thread_id = -1;void combiner_execute(combiner_t* c, combiner_arg_t* arg) { // スレッド ID を割り当てます。 int tid = thread_id; if (tid < 0) tid = thread_id = __atomic_fetch_add(&c->seq, 1, __ATOMIC_RELAXED); combiner_thr_t* thr = &c->thr[tid]; // 自身の操作を追加します。 __atomic_store_n(&thr->req, arg, __ATOMIC_RELEASE); for (;;) { // combiner になるための処理を行います。 if (__atomic_exchange_n(&c->lock, 1, __ATOMIC_ACQUIRE) == 0) { // combiner になりました。 // スレッド記述子をポーリングして該当するスレッドを見つけます。 for (int try = 0; try < 3; try++) { int cnt = __atomic_load_n(&c->seq, __ATOMIC_RELAXED); for (int i = 0; i < cnt; i++) { thr = &c->thr[i]; arg = __atomic_load_n(&thr->req, __ATOMIC_ACQUIRE); if (arg) { c->fn(arg); // 操作終了にします。 __atomic_store_n(&thr->req, 0, __ATOMIC_RELEASE); } } } // combiner にはなれません __atomic_store_n(&c->lock, 0, __ATOMIC_RELEASE); return; } else { // combiner ではありません。 // 操作が実行されるか、ロックが解除されるまで待機します。 while (__atomic_load_n(&thr->req, __ATOMIC_RELAXED) && __atomic_load_n(&c->lock, __ATOMIC_RELAXED)) { } if (__atomic_load_n(&thr->req, __ATOMIC_ACQUIRE) == 0) return; } }} |
このアルゴリズムの利点は、操作を追加するのに CAS を実行する必要がないことです。欠点は、combiner が記述子をポーリングしなければならないことです (これは、無駄な作業になる可能性があります)。このアルゴリズムは、書き込み共有のコストが低く、CAP 操作のコストが高い SPARC マシン向けの設計と言えます。著者も指摘しているとおり、このアルゴリズムは、競合状態が減少するにつれて急速に効率が低下します (未処理の操作がないのに combiner が記述子をポーリングすることになります)。そのため、このアルゴリズムは、スレッドローカルな作業を含まない合成ベンチマークに最適です。
専用の combiner スレッド
もう 1 つの研究論文は、「Remote Core Locking: Migrating Critical-Section Execution to Improve the Performance of Multithreaded Applications (リモート・コア・ロック: クリティカル・セクションの実行を移動してマルチスレッド・アプリケーションのパフォーマンスを向上する)」です。この論文の趣旨もフラット結合に似ています (各スレッドごとに記述子があります)。ただし、すべての操作は専用の combiner スレッドにより実行されます。combiner_execute() 関数は、ほぼ同じです。
1 2 3 4 5 6 7 8 9 10 11 12 13 | __thread int thread_id = -1;void combiner_execute(combiner_t* c, combiner_arg_t* arg) { // スレッド ID を割り当てます。 int tid = thread_id; if (tid < 0) tid = thread_id = __atomic_fetch_add(&c->seq, 1, __ATOMIC_RELAXED); combiner_thr_t* thr = &c->thr[tid]; // 自身の操作を追加します。 __atomic_store_n(&thr->req, arg, __ATOMIC_RELEASE); // 実行を待機します。 while (__atomic_load_n(&thr->req, __ATOMIC_ACQUIRE)) { }} |
ただし、操作を実行する専用のスレッドがあります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | void* combiner_thread(void* p) { combiner_t* c = (combiner_t*)p; // シャットダウンのチェックを行います。 while (__atomic_load_n(&c->done, __ATOMIC_RELAXED) == 0) { int cnt = __atomic_load_n(&c->seq, __ATOMIC_RELAXED); // スレッド記述子をポーリングします。 for (int i = 0; i < cnt; i++) { combiner_thr_t* thr = &c->thr[i]; combiner_arg_t* arg = __atomic_load_n(&thr->req, __ATOMIC_ACQUIRE); if (arg) { c->fn(arg); // 操作完了にします。 __atomic_store_n(&thr->req, 0, __ATOMIC_RELEASE); } } } return 0;} |
ここでも、スレッドは (CAS ではなく) アトミックなストア操作を用いて操作を追加します。さらにもう 1 つの利点として、専用の combiner スレッドはキャッシュに (ほかのスレッドはアクセスすることができない) 保護されたデータ構造を保持します。欠点は、(ワーカースレッドは常に専用スレッドと通信する必要があるため) シングルスレッドのレイテンシーが増加し、専用スレッドが常に CPU を使用している状態になることです。このアルゴリズムは、レガシー・アプリケーションを高度な並列マシンで実行するための応急措置としては良いかもしれません。
実装について
評価に移る前に、実装に関していくつかの留意事項があります。
フォルス・シェアリングを回避するため、キャッシュラインには常にパディングを追加することが重要です。オリジナルのフラット結合アルゴリズムにはスレッド記述子間にパディングはありませんが、実際パディングを追加したところ、インテル® プロセッサー上で大幅なスピードアップが得られました。一般に、パディングがある場合とない場合の速度差は 2 倍でした。
一部の combiner アルゴリズムは、引数のリンクリストを使用しているため、ソフトウェア・プリフェッチにより (つまり、現在の操作を実行中に次の操作をプリフェッチすることで) 利点が得られます。ここで使用した実行ループは次のとおりです。
1 2 3 4 5 6 7 8 | while (arg != LOCKED) { combiner_arg_t* next = arg->next; if (next != LOCKED) __builtin_prefetch(next); c->fn(arg); __atomic_store_n(&arg->next, 0, __ATOMIC_RELEASE); arg = next;} |
プリフェッチを行った場合と行わない場合の速度差は最大で 15% でした。
操作終了の待機には、アクティブなスピンループを使いました。これは、ベンチマークでは問題ありませんが、実際の実装では、より複雑なものを使ったほうが良いかもしれません (例えば、少なくとも一定の反復回数の後に sched_yield() を実行するなど)。
添付ファイルに、すべてのアルゴリズムの完全なソースコードとベンチマーク・ドライバーが含まれています。
評価
ベンチマークで、すべてのスレッドは N 個の操作を実行し、スレッド数は 1、2、4、8、16、または 32 です。保護された操作は、長さ 30 のリンクリストをトラバースします。ベンチマークは、インテル® Xeon® プロセッサー E5-2600 2.90GHz (計 16 HT コア) を 2 つ搭載したマシンで行いました。
最初に、各スレッドがローカルで 100 個の除算を実行するケースを評価しました。
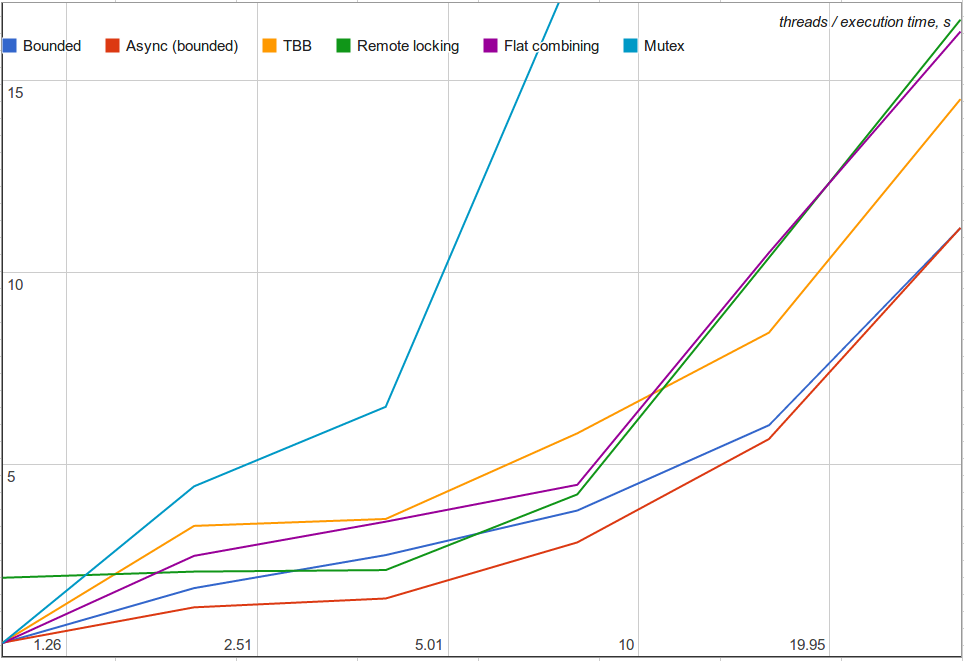
次に、各スレッドがローカルで 1,000 個の除算を実行する (結合の可能性が低い) ケースを評価しました。
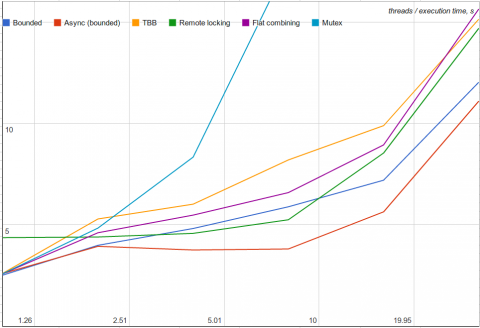
予想どおり、リモート・コア・ロックは、シングルスレッドのパフォーマンスが悪い (2 ~ 6 倍遅い) ものの、競合状態ではまあまあの効果が得られました。フラット結合は、ローカル作業が増えると効率が悪くなります (無駄なポーリングが増えるため)。インテル® TBB の結合アルゴリズムは、結合の可能性を見逃します。例えば、4 スレッドの場合、インテル® TBB のアルゴリズムは平均 1.75 操作を結合し、前述の「上限付き」アルゴリズムは平均 3.40 操作を結合するため、パフォーマンスの差は明らかです。非同期バージョンは、最良のパフォーマンスをもたらします。クリティカル・セクションとローカル作業を効率良くインターリーブできるため、これは当然と言えるでしょう。非同期操作は、ほかのアルゴリズム (例えば、フラット結合) にも適用できます。
