

この記事は、インテル® デベロッパー・ゾーンに掲載されている「Vectorization Gets Explicit with Intel’s Updated Parallel Tool」 (http://goparallel.sourceforge.net/vectorization-gets-explicit-intels-updated-parallel-tool/) の日本語参考訳です。
インテル® Parallel Studio XE 2015 の明示的なベクトル化機能により、分割し個別のノードで並列に実行する SIMD ループとその他のループを定義することができます。
インテルの最新の HPC アプリケーション開発スイートでは、さらに多くのハードウェアと開発言語がサポートされ、多数のプロセッサーで並列に実行するアプリケーション領域を定義しやすくなっています。
インテル® Parallel Studio XE 2015 は、さまざまなオペレーティングシステムとハードウェアで C、C++、FORTRAN での開発が可能な OpenMP* 4.0 API をサポートしています。
インテル コーポレーションの並列プログラミング・エバンジェリスト兼ディレクターの James Reinders によると、最新バージョンではパフォーマンス・モニタリング機能が更新され、対応プラットフォーム向けにコンパイルした際のコードの詳細、コードの最適化に関するアドバイス、アプリケーション・パフォーマンスに影響するさまざまな細かい設計の問題に関する情報を簡単に得られます。
しかし、最も注目すべき機能は明示的なベクトル化です。この機能を利用して、プログラマーはコードブロックの最初と最後にセパレーターを追加し、並列に実行する/しないアプリケーション領域を構成することができます。
インテル® デベロッパー・ゾーンで Martyn Corden は、ほとんどの HPC/スーパーコンピューティング・アプリケーションは、コンパイラーによる自動ベクトル化が適用されると述べています。コンパイラーは、1 つの命令セットを複数のデータセット (SIMD – Single Instruction Multiple Data – 命令) に変換できるループを探します。そして、それらを複数のプロセッサー/サーバー間で分配し、1 つずつ実行する代わりに同時に実行できるようにします。
これによりパフォーマンスは向上しますが、大幅な向上は見込めません。コンパイラーによる自動ベクトル化は、汎用的で保守的なコード変換を行うため、多くの細かいパフォーマンス向上の可能性が見逃されてしまうからです。各命令におけるスピードアップはわずかでも、これらの命令は多数のプロセッサーで何万回も実行されるため、全体では大幅なパフォーマンスの向上につながります。
インテル® Parallel Studio XE 2015 の明示的なベクトル化は、インテル® Cilk™ Plus (2009 年にインテルが買収した Cilk Arts の C/C++ 拡張) によって実現されます。
ほとんどの並列処理アプリケーションでは、あるプロセスが共有コードを使用している間そのコード領域をロックすることで、複数のプロセスが 1 つのデータセットまたは命令セットを使用できるようにしています。このアプローチは、プロセスがロックされたコードへのアクセスを互いに競い合うため、パフォーマンスが低下する可能性があります。
インテル® Cilk™ Plus はロックを使用しないアプローチを使用し、並列プロセスは、同じループのコピー以外のコードをスポーンして同時に実行したり、各反復の結果を待たずに次の反復を実行することで同じループの反復を別々のプロセスで同時に実行することができます。
インテル® Parallel Studio XE 2015 に含まれるバージョンでは、ループのコードブロックの最初と最後に 1 文ずつ追加するだけで、これまでコンパイラーによって自動ベクトル化されなかった領域もベクトル化できると、Reinders は HPCWire で述べています。
インテル® Cilk™ Plus のこの機能は (いくつかの OpenMP* 4.0 関数にも同様の機能があります)、アプリケーションのベクトル化を細かく制御し、インテル® Xeon Phi™ コプロセッサーを搭載した HPC やスーパーコンピューターで利用可能な多数のプロセッサー・コアを効率良く使用できるようにします。The Parallel Universe Issue 18 の「MIT から GCC* メインラインへと進化を遂げたインテル® Cilk™ Plus」で、インテル コーポレーション ソフトウェア開発エンジニアの Barry Tannenbaum は、インテル® Xeon Phi™ コプロセッサー (開発コード名: Knights Landing) ではプロセッサーあたり 61 コアが搭載されるとしています。
© Intel Corporation.
「現代のプロセッサーで利用可能なリソースを活用する、ベクトル化されたマルチスレッド・アプリケーションのプログラミングは複雑で面倒なものです。経験豊富な開発者でさえも、同時に起こり得るすべてのことを把握することは難しいでしょう。」と Barry Tannenbaum は述べています。
その結果、再現と修正が困難な問題を抱え、コア数の増加に伴ってスケーリングしないプログラムになりがちです。
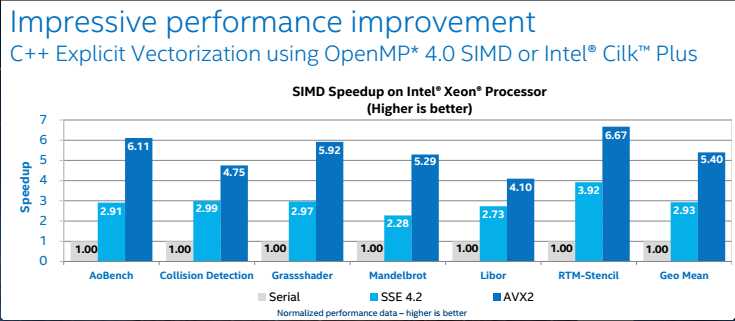
コンパイラーによる自動ベクトル化は便利ですが、2011 年にイリノイ大学アーバナ・シャンペーン校のコンピューター・サイエンス研究チームによって行われた調査では、コンパイラーは特定のアプリケーションでループの 45 ~71% のベクトル化に失敗すると報告されています (http://polaris.cs.uiuc.edu/~garzaran/doc/pact11.pdf)。Reinders は、ハイパフォーマンス・コンピューターやその他のコンピューターでコア数が増加するのに伴い、アプリケーションがハードウェアの性能を最大限に利用できるようにベクトル化の重要性が高まりつつあるとし、効率良くベクトル化されたアプリケーションは全くベクトル化されていないアプリケーションと比べて 16 倍も高速に実行できると予測しています。
さらに、ベクトル化されたアプリケーションはハードウェアを効率良く利用するため、ベクトル化されていないアプリケーションよりも消費電力も少なくて済むと述べています。
インテルの 2 つのテクノロジー、インテル® ストリーミング SIMD 拡張命令 (インテル® SSE) とインテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) は、並列処理のスピードを大幅に向上しました。x86 プロセッサーで 2 つの倍精度浮動小数点数を同時処理するところから始まり、その後 16 の倍精度浮動小数点を同時処理できるまでに進化しました。これにより、プロセスのパフォーマンスが大幅に向上したと、エネルギー省の National Energy Research Scientific Computing Center (NERSC) のスーパーコンピューター・ソフトウェアのベクトル化ガイドでは触れています。
NERSC は、7 台のスーパーコンピューターを運用しており、8 台目の導入が決まっています。アプリケーションは、プロセスを利用可能なすべてのスレッド、コア、ノードに効率良く分配することが重要です。NERSC はインテルおよび Cray と協力して、NERSC Exascale Science Application Program (http://goparallel.sourceforge.net/next-gen-code-worthy-worlds-powerful-supercomputers/) を立ち上げ、より多くのプロセッサーとインテル® Xeon Phi™ コプロセッサーを効率良く利用するためソフトウェアの再構成に同意した、スーパーコンピューターを使用している 20 の科学チームに資金面と技術面で支援する取り組みを始めました。
この取り組みと比べると、OpenMP* 4.0、インテル® Parallel Studio XE 2015、インテル® Cilk™ Plus の明示的なベクトル化関数による変更は、それほど大規模なものとは言えません。20 チームにそれぞれのアプリケーションのベクトル化の効率改善を求める一方で、NERSC はさまざまな問題を引き起こすボトルネックの排除に取り組んでいます。これには、スーパーコンピューターのアーキテクチャーに適していないメモリー管理や、データとプロセスを分割して並列に実行できるものの後でその再構成に時間がかかり過ぎるアプリケーションなどが含まれます。
来年 NERSC に導入される予定の 7 千万ドル、9,300 ノード、2,230,000 スレッドの Knights Landing ベースの Cray XC30 スーパーコンピューターよりも小規模で、簡単な構成のシステムで動作するアプリケーションでは、ベクトル化するループを制御し、パフォーマンスと消費電力の両方を大幅に向上できることが重要でしょうと Reinders は述べています。
