

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Using Intel® Parallel Inspector to Find Data Races in Multithreaded Code」の日本語参考訳です。
編集注記:
本記事は、2011 年 5 月 4 日に公開されたものを、加筆・修正したものです。
インテル® Parallel Studio XE に含まれるインテル® Inspector を使用すると、Win32*、インテル® スレッディング・ビルディング・ブロック (インテル® TBB) や OpenMP* スレッド化モデルを使用したアプリケーションのマルチスレッド化エラーをデバッグすることができます。インテル® Inspector は、データ競合、デッドロック (またはデッドロックが発生する可能性のある条件)、スレッドストールなどを自動的に検出します。ここでは、OpenMP* スレッド化アプリケーションのデバッグに関連する固有の問題についても説明します。
この記事は、「マルチスレッド・アプリケーションの開発のためのガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
はじめに
OpenMP* アプリケーション・プログラミング・インターフェイス (API) は、Linux* と Windows* プラットフォームを含むすべてのアーキテクチャーで C/C++ と Fortran のマルチプラットフォーム共有メモリー並列プログラミングをサポートしています。OpenMP* は、移植性とスケーラビリティーに優れたモデルで、デスクトップ・マシンからスーパーコンピューターまで、さまざまなプラットフォーム用の並列アプリケーションを開発するため、単純で柔軟性のあるインターフェイスを共有メモリー並列処理を行う開発者に提供します。
デバッガーによってランタイム時のパフォーマンスが左右され、競合状態が再現しないことがあるため、マルチスレッド・アプリケーションのデバッグは非常に複雑です。PRINT 文でさえも、問題を発見しにくくすることがあります。これは、PRINT 文が、同期およびオペレーティング・システム関数を使用するためです。OpenMP* を利用することでさらに複雑になります。OpenMP* は、プライベート変数、共有変数、および追加コードを挿入するため、OpenMP* をサポートする専用のデバッガーなしでは、検証しステップ実行することはできません。
次のコードは、単純な OpenMP* の使用例です。この単純な例でもデータ競合状態が発生します。
1 2 3 4 5 6 7 8 9 10 11 | double x, pi, sum = 0.0; int i; step = 1.0 / (double)num_steps;#pragma omp parallel for for (i = 0; i < num_steps; i++) { x = (i + 0.5) * step; sum = sum + 4.0 / (1.0 + x * x); } pi = sum * step; |
for ループに注目してください。この例では「ワークシェアリング」が使用されています。OpenMP* では、スレッド間でワークを分配することをワークシェアリングと呼びます。ワークシェアリングが for 構造で使用されると、ループの反復が複数のスレッドに分配されるため、各ループ反復は 1 つ以上のスレッドで正確に一度だけ並列に実行されます。OpenMP* は作成するスレッドの数と、スレッドの生成、同期、および破棄方法を決定します。
コンパイラーはこのループのスレッド化を試みますが、ループの少なくとも 1 つの反復が異なる反復に対してデータ依存しているため、スレッド化は失敗します。このような状態を競合状態と呼びます。競合状態は、共有リソース (メモリーなど) と並列実行を使用した場合にのみ発生します。この問題に対処するには、同期を使用してデータ競合状態を防ぎます。
インスタンスによっては、変数が偶然「競合状態に勝って」プログラムが正しく機能することがあるため、競合状態の検出は困難です。たとえプログラムが一度動作しても常に動作するとは限りません。インテル® ハイパースレッディング・テクノロジーをサポートするマシンや複数の物理プロセッサーを搭載しているマシンなど、さまざまなマシン上でプログラムをテストすると良いでしょう。
インテル® Inspector は、このような場合にも役立ちます。従来のデバッガーでは、1 つのスレッドが競合を停止してもその間、他のスレッドは継続的かつ著しくランタイム動作を変更するため、競合状態の検出には役立ちません。
アドバイス
インテル® Inspector を利用することで、OpenMP、インテル® TBB、Win32 マルチスレッド・アプリケーションのデバッグを効率的に行うことができます。インテル® Inspector は、非常に有益な並列実行情報とデバッグのヒントを提供します。
インテル® Inspector はコーディング・エラーを識別するため、動的なバイナリー・インストルメンテーションを使用して、OpenMP* ディレクティブ、Win32 スレッド化 API、およびすべてのメモリーアクセスをモニターします。特に、テスト中に発生しない可能性のある稀なエラーの検出に役立ちます。
ツールを使用するときは、データ収集プロセスを高速化するため、最小限のデータですべてのコードパスにアクセスすることが重要です。通常、アプリケーションで処理するデータ量を減らすためにソースコードやデータセットを少し変更する必要があるでしょう。
インテル® Inspector で分析を行うには、最適化を無効、デバッグシンボルを有効にしてプログラムをコンパイルする必要があります。インテル® Inspector は Microsoft* Visual Studio* のプラグインとして動作します。
インテル® Inspector を起動するツールバーまたはメニューコマンドを選択してから、分析タイプを選択するドロップダウン・メニューで [Inspect Threading Errors (スレッド化エラーの調査)] を選択します。メニューには、希望する深さと予測されるオーバーヘッドに応じて、いくつかのレベルの分析が用意されています。インテル®Inspector は Microsoft Visual Studio プロジェクトでコンパイルされたアプリケーションを開始します。
図 1 では、変数 x が変更されるソース行と変数 sum が変更される次のソース行のデータ競合エラーを識別しています。グローバルに定義されている変数 x と sum は異なるスレッドから読み書きのためにアクセスされていることから、これらのエラーは明白です。さらに、インテル® Inspector は、メインスレッドのスタックに割り当てられている変数がワーカースレッドからアクセスされたことを示す、「潜在的なプライバシーの侵害」に関する警告を出力しています。
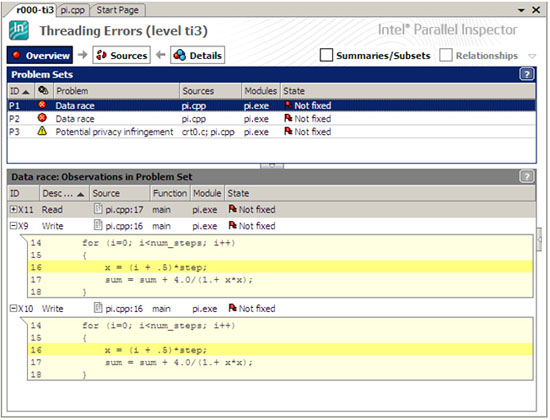
図 1. インテル® Inspector が検出した問題セットの概要
問題をより細かく調査できるように、インテル® Inspector は、関数のコールスタックを含む詳細なエラー情報を表示します。ソースコードのクイック・リファレンスは、エラーが検出されたときのコード範囲の確認に役立ちます。図 2 の「Sources (ソース)」タブには、詳細な情報を含む、異なるスレッドの共有変数へのアクセスを示す 2 つのソースコード・ウィンドウが表示されています。ダブルクリックしてソースコードに移動することもできます。
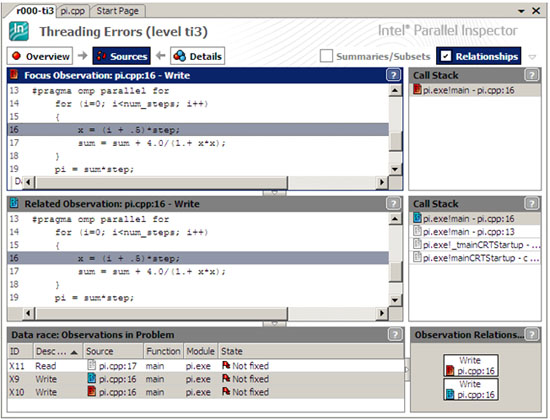
図 2. インテル® Inspector のソースビュー
インテル® Inspector でエラーレポートを取得して根本的な原因が判明したら、開発者は問題の解決方法を考えます。並列 OpenMP* ループのデータ競合状態を回避するための一般的な考慮事項と、検査したコードの問題を解決する方法についてのアドバイスを以下に説明します。
共有データとプライベート・データの管理
ほぼすべてのループはメモリーを読み書きします。開発者は、どのメモリーをスレッド間で共有し、どのメモリーをプライベートとして保持するのかをコンパイラーに通知する必要があります。メモリーが共有の場合、すべてのスレッドが同じメモリーの場所にアクセスします。メモリーがプライベートの場合、メモリーにアクセスするために、スレッドごとに個別の変数 (プライベート・コピー) が作成されます。
ループが終了すると、これらのプライベート・コピーは破棄されます。デフォルトでは、プライベートなループ変数を除き、すべての変数は共有されます。プライベートとしてメモリーを宣言するには、次の 2 つの方法があります。
- static キーワードを指定しないで、変数をループの内側 (OpenMP* parallel 構文の内側) で宣言します。
- OpenMP* 指示句に private 節を指定します。
上記の例のループには 2 つの問題があるために正しく機能しません。1 つめは、プライベートにする必要がある変数 x が共有されていることです。次のプラグマ式は、変数 x をプライベート・メモリーとして宣言しています。これで 1 つめの問題が解決します。
1 | #pragma omp parallel for private(x) |
クリティカル・セクション
例が正しく機能しなかった 2 つめの理由は、スレッド間のグローバル変数の共有です。変数 sum は各スレッドの各反復で計算したすべての部分和を収集するため、プライベートにできません。解決方法はクリティカル・セクションを使用することです。
クリティカル・セクションは、コードのブロックに対して複数のアクセスが行われることを防ぎます。スレッドがクリティカル・セクションに遭遇すると、ほかのスレッドがすべてのクリティカル・セクションに存在しない場合のみ、クリティカル・セクションに入ります。次の例は名前のないクリティカル・セクションを使用しています。
1 2 3 | #pragma omp criticalsum = sum + 4.0 / (1.0 + x * x); |
すべてのスレッドが同じグローバル・クリティカル・セクションを効率的に利用する必要があるため、グローバルまたは無名のクリティカル・セクションはパフォーマンスに影響を与えます。そのため、OpenMP* には名前付きのクリティカル・セクションが用意されています。名前付きのクリティカル・セクションを利用すると、より細粒度の同期が可能になるため、特定のセクションでブロックが必要なスレッドのみをブロックするだけでかまいません。次の例は、前の例よりもパフォーマンスが向上します。
1 2 3 | #pragma omp critical(sumvalue)sum = sum + 4.0 / (1.0 + x * x); |
名前付きのクリティカル・セクションを利用すると、アプリケーションで複数のクリティカル・セクションを使用できるため、複数のスレッドを同時に複数のクリティカル・セクションで処理することができます。ただし、入れ子のクリティカル・セクションに入ると、OpenMP* で検出できないデッドロックが発生する可能性があります。複数のクリティカル・セクションを使用する場合は、サブルーチンで隠れてしまう可能性があるクリティカル・セクションの調査に細心の注意を払うようにしてください。
アトミック操作
クリティカル・セクションの利用は、保護されたコード部分の高いスレッド化競合まではパフォーマンスに優れていることが知られています。クリティカル・セクションに入る前にスレッドが待つ必要がある場合、オペレーティング・システムはカーネルレベルの同期メカニズムによりスレッドをスリーピング・モードにして、リソースから合図があると復帰させます。この処理によりプログラム実行に追加のオーバーヘッドが発生します。オーバーヘッドに対処するには、アトミック操作のようなアプローチを使用します。
アトミック操作の定義としては、中断されないことが保証されており、競合状態を回避するために共有メモリー位置を更新するステートメントで役立ちます。下記のコード行で、開発者は変数がステートメントで一定であることが重要であると判断しました。
1 | a[i] += x; // ステートメントは中断される可能性があります |
個々のアセンブリー命令の実行は中断されませんが、C/C++ のような高水準言語のステートメントは中断可能な複数のアセンブリー命令に変換されます。上記の例では、a[i] の値は、値の読み取り、変数 x の追加、変数のメモリーへの書き込みのアセンブリー・ステートメントでそれぞれ変更されます。次の OpenMP* 構文は、ステートメントが中断されることなくアトミックに実行されます。
1 2 3 | #pragma omp atomica[i] += x; // 中断されることはありません |
OpenMP* は、使用されるオペレーティング・システムおよびハードウェアの機能から、ステートメントを実装する最も効率的な手法を選択します。ただし、アトミック操作はインクリメント/デクリメントや乗算/除算と演算子の組み合わせのように、単純な操作である必要があります。この場合、例の変数 sum を保護するアトミック操作が役に立たなくなります。
リダクション
値を累積するループは一般的ですが、OpenMP* ではこのようなループ専用の節を用意しています。倍の部分和の合計を計算するループについて考えてみます。変数 sum は正しい結果を生成するように共有する必要がありますが、複数のスレッドによるアクセスを許可するためにプライベートにする必要もあります。この問題を解決するため、OpenMP* は、ループの 1 つ以上の変数の演算リダクションを効率的に結合する reduction 節を提供します。次のループは正しい結果を生成するため、reduction 節を使用しています。
1 2 3 4 5 6 | #pragma omp parallel for private(x) reduction(+:sum) for (i = 0; i < num_steps; i++) { x = (i + 0.5) * step; sum = sum + 4.0 / (1.0 + x * x); } |
OpenMP* は各スレッドに変数 sum のプライベートなコピーを提供し、スレッドの終了時にすべてのコピーの値を合計して、その結果を変数 sum のグローバルコピーに格納します。
利用ガイド
インテル® Inspector は、OpenMP*、Win32 スレッド化 API、インテル® TBB スレッド化 API をサポートしています。OpenMP* のサポートにはインテル® コンパイラーが必要です。Microsoft の OpenMP* 実装を使用することも可能ですが、インテルの OpenMP* ランタイム・ライブラリーを互換モードでプロジェクトにリンクする必要があります。詳細な分析を行うには、インテル® コンパイラーから利用可能な最新の OpenMP* ランタイム・ライブラリーを使用してください。
インテル® Inspector は、静的分析ではなく動的分析を行うことに注意してください。分析は実行されるコードだけで行われます。このため、適切にコードをカバーするには、プログラムの異なる部分を実行する複数の分析を行う必要があります。
インテル® Inspector のインストルメンテーションによりアプリケーションの CPU とメモリー使用量が増加するため、小さく典型的なテストセットを選択することが非常に重要です。実行時間が数秒のワークロードが最適です。マルチスレッド・コードの適切なセクションをテストすることが目的なので、ワークロードが現実的である必要はありません。
