

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Parallelism in the Intel® Math Kernel Library」 (https://software.intel.com/en-us/articles/parallelism-in-the-intel-math-kernel-library) の日本語参考訳です。
編集注記:
本記事は、2011 年 5 月 4 日に公開されたものを、加筆・修正したものです。
ソフトウェア・ライブラリーを利用すると、マルチコア、マルチプロセッサー、クラスター・コンピューティング・システムで迅速にパフォーマンスの利点を得ることができます。インテル® マス・カーネル・ライブラリー (インテル® MKL) には、数学計算を多用するアプリケーションに役立つさまざまな関数のコレクションが含まれています。
ここでは、プログラマーが一般的なアプリケーションで優れたシリアルおよび並列パフォーマンスを達成するためにインテル® MKL がどのように役立つかを説明します。ここでは、Windows*、Linux*、macOS* オペレーティング・システムで IA-32 およびインテル® 64 対応プロセッサー用アプリケーションを開発するケースを対象としています。
この記事は、「マルチスレッド・アプリケーションの開発のためのガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
はじめに
最近のマルチコアやマルチプロセッサー・システムは、適切な並列処理を実装し、アーキテクチャーの基礎となるメモリー特性を正しく管理してはじめて、最適なパフォーマンスを得ることができます。
シリアルコードのパフォーマンスは、命令、レジスターレベルの SIMD 並列処理、およびキャッシュブロックに極度に依存します。マルチスレッド・プログラムは、複数のコアとプロセッサーが効率的に使用され、並列タスクが均等に分散されるように、高度なブロック化手法を利用する必要があります。メモリーに収まらない大規模な問題を処理する場合は、アウトオブコア実装を使用します。
アドバイス
数学計算を多用するアプリケーションに並列処理を導入する最も簡単な方法の 1 つは、スレッド化、および最適化されたライブラリーを使用することです。この方法は、プログラマーの膨大な開発時間を節約するだけでなく、テストや評価に必要な時間と労力も減らすことができます。標準化された API を利用することで、生成されるコードの移植性も高まります。
インテル® MKL は、最新のインテル® プロセッサーのすべての機能を活用する最適化およびスレッド化された数学関数の包括的なセットを提供します。はじめてライブラリー関数が呼び出されるときに、プログラムを実行しているハードウェアを認識するためにランタイムチェックが行われます。このチェックに基づいて、命令とレジスターレベルの SIMD 並列処理が最大限に利用され、最適なキャッシュブロック手法が選択するようにコードパスが決定されます。インテル® MKL はスレッドセーフな設計であるため、複数のアプリケーション・スレッドから同時に呼び出されても関数は正しく動作します。
インテル® MKL はインテル® C++ コンパイラーとインテル® Fortran コンパイラーを使用して構築され、OpenMP* を使用してスレッド化されています。そのアルゴリズムは、複数のコアやプロセッサーを効率良く使用するため、データとタスクをバランスよく処理するように構築されています。次の表は、マルチスレッド関数を含む演算ドメインを示しています (この情報はインテル® MKL 10.2 Update 3 のものです)。
| 線形代数 | 有限要素分析エンジニアリング・コードから現代のアニメーションまで、さまざまなアプリケーションで使用されています。 |
| BLAS (Basic Linear Algebra Subprograms) | すべての行列-行列演算 (レベル 3) は、密行列と疎行列の両方を対象とした BLAS 向けにスレッド化されています。多くのベクトル-ベクトル演算 (レベル 1) と行列-ベクトル演算 (レベル2) は、インテル® 64 アーキテクチャーで実行する 64 ビット・プログラムの密行列向けにスレッド化されています。疎行列については、スパース三角ソルバーを除くすべてのレベル 2 演算がスレッド化されています。 |
| LAPACK (Linear Algebra PACKage) | 線形方程式ソルバー、直交因数分解、特異値分解、対称固有値問題のいくつかの計算ルーチンがスレッド化されています。LAPACK は BLAS も呼び出すため、スレッド化されていない関数も並列で実行されます。 |
| ScaLAPACK (Scalable LAPACK) | LAPACK の分散メモリー並列バージョン。クラスター向けです。 |
| PARDISO | この並列直接法スパースソルバーは、順序の変更 (オプション)、因数分解、解を得る (複数の右辺を解く場合) 3 つのステージでスレッド化されています。 |
| 高速フーリエ変換 (FFT) | 石油探索から医療用画像まで、信号処理やアプリケーションで使用されています。 |
| スレッド化 FFT | 1D 実数と Split 複素数 FFT 以外をスレッド化したバージョンです。 |
| クラスター FFT | FFT の分散メモリー並列バージョン。クラスター向けです。 |
| ベクトル演算 | 多くの金融計算で使用されています。 |
| VML (ベクトル・マス・ライブラリー) | 算術演算、三角関数、指数/対数関数、丸めなど。 |
スレッドの生成と管理には多少のオーバーヘッドが生じるため、複数のスレッドを使用することが必ずしも有益であるとは限りません。このため、インテル® MKL はサイズの小さな問題ではスレッドを生成しません。小さいと考えられるサイズはドメインと関数によって異なります。レベル 3 BLAS 関数は 20 程度の小さな次元でスレッド化を行いますが、レベル 1 BLAS や VML 関数はベクトル数が 1000 未満の場合はスレッド化を行いません。
システムリソースのオーバーサブスクリプションを回避するため、アプリケーションのスレッド化された領域からインテル® MKLが呼び出されるとシングルスレッドで実行します。OpenMP* を使用してスレッド化されているアプリケーションでは、この処理は自動的に行われます。アプリケーションのスレッド化に他の手法を使用した場合、以下で説明するコントロールを使用してインテル® MKL の動作を設定してください。
ライブラリーが複数のスレッドから連続して呼び出される場合、インテル® MKL の機能が役立ちます。例えば、ベクトル・スタティスティカル・ライブラリー (VSL) は、ベクトル化された乱数ジェネレーターのセットを提供します。スレッド化は行われませんが、アプリケーション・スレッド間で乱数のストリームを分割する手段が提供されます。SkipAheadStream() 関数は、乱数ストリームを個別の (各スレッドにつき 1 つの) ブロックに分割します。LeapFrogStream() 関数は、スレッドがオリジナルストリームのサブシーケンスを得るように各スレッドを分割します。例えば、2 つのスレッドにストリームを分割するため、Leapfrog (蛙跳び) 法では 1 つのスレッドに奇数のインデックスを、別のスレッドに偶数のインデックスを割リ当てます。
パフォーマンス
図 1 は、インテル® MKL に含まれている倍精度汎用行列乗算関数である DGEMM を使用した場合のパフォーマンスの例を示しています。この BLAS 関数は、多くのアプリケーションでパフォーマンスに重要な役割を果たします。グラフは、さまざまな長方形サイズにおけるパフォーマンス (Gflops) を示しています。プロセッサー (スレッド) 数によってパフォーマンスがどのようにスケーリングしているか (2 スレッドで 1.9 倍、4 スレッドで 3.8 倍、8 スレッドで 7.9 倍) 分かります。8 スレッドで達成されている 96.5 Gflops はピーク・パフォーマンスの約 94.3% にあたります。
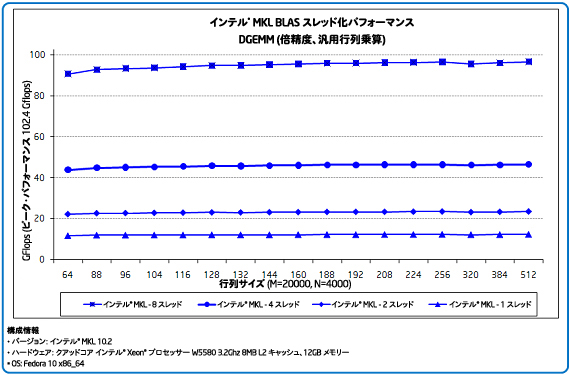
図 1. BLAS 行列-行列乗算関数のパフォーマンスとスケーラビリティー
利用ガイド
インテル® MKL は OpenMP* を使用してスレッド化を行っているため、その動作は OpenMP* コントロールの影響を受けます。スレッドの動作のために追加されたコントロール用には、インテル® MKL では、OpenMP* コントロールの派生であるさまざまなサービス関数が用意されています。これらの関数を使用すると、ユーザーはライブラリーが使用するスレッド数を全体またはドメインごとに (例えば、BLAS、LAPACK、その他で別に) 制御できます。これらを独立して制御できるアプリケーションでは、入れ子の並列処理を行うことができます。
例えば、OpenMP* を使用してスレッド化したアプリケーションの動作は OMP_NUM_THREADS 環境変数または omp_set_num_threads() 関数を使用して設定できますが、インテル® MKL スレッドの動作はインテル® MKL 固有のコントロール (MKL_NUM_THREADS または mkl_set_num_threads()) を使用して別に設定します。インテル® MKL 関数を常にシングルスレッドで実行する必要のある開発者向けに、スレッドランタイムと依存性がないシーケンシャル・ライブラリーも用意されています。
各スレッドが異なる種類の演算を行い、プロセッサー上のリソースが活用されていない場合は、インテル® ハイパースレッディング・テクノロジーが非常に有効です。ただし、インテル® MKL は、利用可能なほとんどのリソースを使用してライブラリーのスレッド化された領域を効率良く実行し、各スレッドで同じ演算を実行するため、これらの条件には合致しません。そのため、インテル® MKL は、デフォルトで物理コア数と同じ数のスレッドのみを使用します。
関連情報
- インテル® Modern Code (https://software.intel.com/en-us/performance)
- インテル® MKL
- Netlib: BLAS、LAPACK、および ScaLAPACK に関する情報 (英語)
