

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Load Balance and Parallel Performance」(https://software.intel.com/en-us/articles/load-balance-and-parallel-performance) の日本語参考訳です。
編集注記:
本記事は、2011 年 5 月 4 日に公開されたものを、加筆・修正したものです。
ロードバランス (アプリケーションのワークロードをスレッド間で均等に分散すること) は、優れたパフォーマンスの達成には欠かせません。ロードバランスの鍵はスレッドのアイドル時間を最小限に抑えることです。ワークシェアによるオーバーヘッドを最小限に抑えながら、スレッド間でワークロードを均等に分散することで、アイドルスレッドにより演算サイクルが無駄に消費されることが減り、パフォーマンスが向上します。
しかし、完璧なロードバランスを達成するのは容易なことではなく、アプリケーションの並列性やワークロード、スレッド数、ロードバランスの方針、スレッド化の実装などに左右されます。
この記事は、「マルチスレッド・アプリケーションの開発のためのガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
はじめに
計算中のアイドルコアは、プロセッサーのリソースを浪費します。そのアイドルコアで効果的な並列実行を行える場合は、スレッド化アプリケーションの実行時間全体が長くなります。このアイドル状態にはメモリーや I/O アクセス待機などのさまざまな原因があります。
コアのアイドル状態を完全になくすことはできないかもしれませんが、オーバーラップ I/O やメモリー・プリフェッチ、キャッシュの利用を考慮したデータのアクセスパターンの並べ替えなどによって、アイドル時間を短縮できる場合があります。
同様に、アイドルスレッドはマルチスレッド実行でのリソースも浪費します。スレッドに割り当てられた処理量が均等でない場合、「ロード・インバランス」という状態が生じます。インバランスが大きいと、アイドル状態のスレッドが増え、処理が完了するまでの時間が長くなります。計算タスクのスレッドへの分配が均等であればあるほど、実行時間全体が短縮されます。
例えば、実行時間が {10, 6, 4, 4, 2, 2, 2, 2, 1, 1, 1, 1} の 12 個の独立したタスクを考えてみましょう。タスクを処理するのに、4 つのスレッドを利用できると仮定します。単純にタスクを割り当てて、合計 3 つのタスクを各スレッドに順にスケジュールします。3 つのスレッドの合計時間単位はスレッド 0 が 20 (10+6+4)、スレッド 1 が 8 (4+2+2)、スレッド 2 が 5 (2+2+1) で、スレッド 3 では 3 (1+1+1) のみとなります。
図 1(a) は、この処理配分を示したもので、12 個のタスクの実行時間は全体で 20 (上から下までの実行時間) であることがわかります。
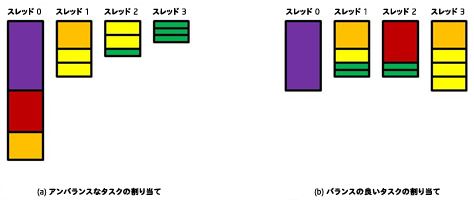
図 1. 4 スレッドでのタスクの配分例
図 1(b) のように、スレッド 0: {10}、スレッド 1: {4, 2, 1, 1}、スレッド 2: {6, 1, 1}、スレッド 3: {4, 2, 2, 2} のように処理を配分すると、完了までの実行時間は 10 で、アイドル状態のスレッドは 4 スレッドのうち 2 つのスレッド (それぞれ実行時間は 2) です。
アドバイス
すべてのタスクが同じ長さの場合、利用可能なスレッドで単純にタスクを静的に配分 (タスクの合計数を (ほぼ) 均等なサイズのグループに分けてスレッドに割り当てる) することができます。しかし多くの場合、すべてのタスクの長さが同じであることがわかっていても、バランスのとれた最適な形でタスクをスレッドに割り当てるのは困難です。個々のタスクの長さが同じでない場合は、動的にタスクを配分すると良いかもしれません。
概して OpenMP* の for ワークシェア構造では、スレッドへの反復割り当てはデフォルトで静的にスケジュール (そうでない場合は指定が可能) されています。ワークロードが反復処理ごとに異なり、パターンを予測できない場合は、動的スケジュールを行うことでロードバランスを保つことができます。
dynamic、guided、または auto を schedule 節に指定します。動的スケジュールでは、反復処理のチャンクがスレッドに割り当てられます。割り当てが完了すると、スレッドは新しいチャンクを要求します。schedule 節のオプションの引数は、動的スケジュールの反復チャンクの固定サイズです。
1 2 3 4 5 | #pragma omp parallel for schedule(dynamic, 5) for (i = 0; i < n; i++) { unknown_amount_of_work(i); } |
guided では、開始時スレッドに大きなチャンクが割り当てられます。割り当てされていない反復処理が減るにしたがって、要求スレッドに与えられる反復数が減ります。この割り当てパターンにより、guided は dynamic よりもオーバーヘッドが少ない傾向にあります。guided では、schedule 節のオプションのチャンク引数は、割り当てられる chunk の最小反復数です。また、auto を指定することでランタイム時に適切な dynamic と guided を組み合わせたチャンクサイズを選択することができます。
1 2 3 4 5 | #pragma omp parallel for schedule(guided, 8) for (i = 0; i < n; i++) { uneven_amount_of_work(i); } |
反復処理間のワークロードが単調増加 (または減少) する特殊な例があります。例えば、下三角行列で行ごとの要素数が一定の割合で増える場合です。このような場合、static スケジュールで比較的小さいサイズのチャンクを割り当てる (チャンク/タスクを多数作成する) ことで、dynamic、guided、または auto のスケジュールに伴うオーバーヘッドもなく、適切なロードバランス量になります。
1 2 3 4 5 | #pragma omp parallel for schedule(static, 4) for (i = 0; i < n; i++) { process_lower_triangular_row(i); } |
スケジュール方法が明白でない場合は、runtime スケジュールを使用すると、プログラムを再コンパイルしなくても環境変数を利用してチャンクサイズやスケジュール型を変更できます。
インテル® スレッディング・ビルディング・ブロック (インテル® TBB) の parallel_for アルゴリズムを使用すると、スケジューラーは反復空間をスレッドに割り当てられる小さなタスクに分割します。ある反復処理の計算時間がほかの反復処理よりも長い場合は、インテル®TBB のスケジューラーによって、スレッドから動的にタスクが「スチール」されて、スレッド間のロードバランスが保たれます。
明示的なスレッド化モデル (Windows* スレッド、Pthreads*、Java* スレッドなど) には、独立したタスクをスレッドに自動でスケジュールする方法はありません。必要に応じて、そのような機能をアプリケーションにプログラミングしなければなりません。タスクの静的スケジュールは単純です。
動的スケジュールの場合は、生産者/消費者とボス/ワーカーの 2 つの方法を簡単に実装できます。前者の場合、あるスレッド (生産者) がタスクを共有のキュー構造に置き、消費者スレッドが必要に応じて処理するタスクを消費していきます。必須ではありませんが、生産者/消費者モデルではタスクが消費者スレッドで使用できるようになる前に前処理を行います。
ボス/ワーカーモデルでは、ワーカースレッドは処理がある場合は常にボススレッドを待機し、直接処理の割り当てを受けます。処理データの配列の範囲といった、タスクの抽出が単純な場合は、独立したボススレッドにおいて適切な同期をともなうグローバルカウンターを使用できます。その場合は、ワーカースレッドは現在の値にアクセスし、追加の処理を要求している次のスレッドのために、そのカウンターを調節 (通常はインクリメント) します。
タスクのスケジューリング・モデルを使用する場合は、適切なスレッド数とスレッドの組み合わせを使用して、計算処理のタスクを実行するスレッドがアイドル状態にならないようにします。例えば、消費者スレッドが時々アイドル状態になる場合、消費者の数を減らすかまたは生産者スレッドを追加する必要があります。アルゴリズムの考慮と割り当てられるタスク数とタスクの長さによって適切なソリューションが決まります。
利用ガイド
動的なタスク・スケジュールでは、タスクの分配によりオーバヘッドが必然的に生じます。小さな独立したタスクを 1 つにまとめて処理を割り当てることで、このオーバーヘッドを軽減できます。したがって、OpenMP の schedule 節を使用する場合は、タスク内の最小反復数であるデフォルト以外のチャンクサイズを設定します。処理する計算とスレッド数と実行時に利用できるその他のリソースを考慮して、タスクを構成する計算量を適切に選択してください。
