

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Granularity and Parallel Performance」 (https://software.intel.com/content/www/us/en/develop/articles/granularity-and-parallel-performance.html) の日本語参考訳です。
編集注記:
本記事は、2011 年 5 月 4 日に公開されたものを、加筆・修正したものです。
優れた並列パフォーマンスを達成するには、アプリケーションが適切な粒度を持つことが重要です。粒度とは、並列タスクにおける実際の処理量を指します。粒度が細かすぎると通信オーバーヘッドによってパフォーマンスが損なわれ、粒度が粗すぎるとロード・インバランスによってパフォーマンスが損なわれます。ロード・インバランスと通信オーバーヘッドを回避しつつ、並列タスクに適切な粒度 (一般に大きいほど良い) を見極めて、優れたパフォーマンスを達成するようにします。
この記事は、「マルチスレッド・アプリケーションの開発のためのガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
はじめに
マルチスレッド・アプリケーションの並列タスクの処理サイズ (粒度) は、並列パフォーマンスを左右します。マルチスレッド用にアプリケーションを分解する際、理論的に処理をできるだけ多くの並列タスクに「分割 (partition) 」する方法があります。次にその並列タスクで、共有データと実行順の観点から必要な通信 (communication) を特定します。
タスクの分割、スレッドへのタスクの割り当て、タスク間での (共有) データの通信にはコストが発生するため、凝集化 (agglomerate) するか、パーティションを結合して、オーバーヘッドを軽減し、最も効率良い実装を選択する必要があります。凝集化のステップは、並列タスクに最適な粒度を決めるプロセスです。
粒度の選択は、スレッド間のワークロードをいかにバランスよく配分するかという点に関係します。小さなタスクが多数ある場合には容易にワークロードのバランスを保てますが、通信、同期などといった形でオーバーヘッドがかなり生じます。そのため、小さなタスクを 1 つのタスクにまとめて各タスクの粒度 (処理量) を大きくし、並列化のオーバーヘッドを抑えます。インテル® Parallel Amplifier (現在のインテル® VTune™ プロファイラー) などのツールを使用すると、アプリケーションに適切な粒度を見極めることができます。
下記は、通信オーバーヘッドを抑え、スレッドに適切な粒度を見極めることで並列プログラムのパフォーマンスが向上することを示した例です。この例は、素数を数えるアルゴリズムで、約数が見つかるか数字が素数になるまで素数を係数で割っていくという単純な総当たり方式を採用しています。正の奇数は、(4k+1) または (4k+3)、k ≧ 0 で計算できるため、コードによりそれぞれの式に当てはまる素数を数えられます。例では、3 から 100 万までの素数を数えます。
最初のコードは、OpenMP* を使用した並列バージョンです。
#pragma omp parallel
{ int j, limit, prime;
#pragma for schedule(dynamic, 1)
for(i = 3; i <= 1000000; i += 2) {
limit = (int) sqrt((float)i) + 1;
prime = 1; // 数が素数であると仮定
j = 3;
while (prime && (j <= limit)) {
if (i%j == 0) prime = 0;
j += 2;
}
if (prime) {
#pragma omp critical
{
numPrimes++;
if (i%4 == 1) numP41++; // 4k+1 primes
if (i%4 == 3) numP43++; // 4k-1 primes
}
}
}
}
このコードは、通信オーバーヘッド (同期) が高く、また個々のタスクサイズがスレッドに対して小さ過ぎます。ループの内側には、カウント変数のインクリメントを安全に行うことができるよう critical セクションがあります。インテル® Parallel Amplifier (現在のインテル® VTune™ プロファイラー) が示すように (図 1)、クリティカル領域によって、同期とロックのオーバーヘッドが並列ループに加わります。
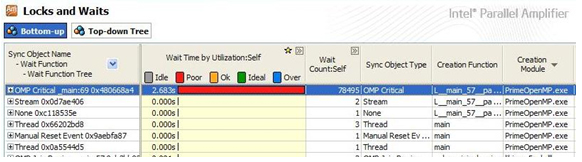
図 1. ロックと待機の分析結果により、OpenMP* のクリティカル領域が同期オーバーヘッドの原因であることがわかります。
大規模なデータセット内の値に基づいてカウンター変数をインクリメントすることは、リダクションと呼ばれる一般的な式です。クリティカル領域を少なくして、OpenMP の reduction 節を追加することでロックと同期のオーバーヘッドを取り除くことができます。
#pragma omp parallel
{
int j, limit, prime;</p>
<p> #pragma for schedule(dynamic, 1)
reduction(+:numPrimes,numP41,numP43)
for(i = 3; i <= 1000000; i += 2) {
limit = (int) sqrt((float)i) + 1;
prime = 1; // 数が素数であると仮定
j = 3;
while (prime && (j <= limit))
{
if (i%j == 0) prime = 0;
j += 2;
}
if (prime)
{
numPrimes++;
if (i%4 == 1) numP41++; // 4k+1 primes
if (i%4 == 3) numP43++; // 4k-1 primes
}
}
}
ループ本体のクリティカル領域が排除されることにより、ループの反復回数によっては大幅に実行速度を向上できることがあります。しかし、上記のコードにはまだ並列オーバーヘッドが存在し、その原因は、各タスクの処理サイズの小ささにあります。
schedule(dynamic, 1) 節では、スケジューラーが動的に各スレッドに対して同時に 1 回の反復 (またはチャンク) を分配するよう指定されています。各ワーカースレッドは、1 回の反復を処理し、それからスケジューラーに戻って、別の反復処理を取得するために同期します。チャンクサイズを大きくすることでスレッドに割り当てられる各タスクの処理サイズが大きくなり、各スレッドがスケジューラーと同期をとる回数が減ります。
この方法によってパフォーマンスを向上できますが、粒度を大きくし過ぎると、(前述したように) ロード・インバランスを引き起こします。たとえば、次のコードのようにチャンクサイズを 10,000 に増やしたとします。
#pragma omp parallel
{
int j, limit, prime;
#pragma for schedule(dynamic, 100000)
reduction(+:numPrimes, numP41, numP43)
for(i = 3; i <= 1000000; i += 2)
{
limit = (int) sqrt((float)i) + 1;
prime = 1; // 数が素数であると仮定
j = 3;
while (prime && (j <= limit))
{
if (i%j == 0) prime = 0;
j += 2;
}
if (prime)
{
numPrimes++;
if (i%4 == 1) numP41++; // 4k+1 primes
if (i%4 == 3) numP43++; // 4k-1 primes
}
}
}
このコードの実行をインテル® Parallel Amplifier (現在のインテル® VTune™ プロファイラー) で分析すると、4 つのスレッドで行われる処理量にインバランスが生じていることがわかります (図 2)。
この計算例の重要なポイントは、それぞれのチャンクの処理量が異なり、またタスクとして割り当てられているチャンクが少な過ぎる (4 つのスレッドに対して 10 個のチャンク) ためにロード・インバランスが生じていることです。(for ループからの) 素数の値が増えるにつれて、(while ループの) 素数の係数のテストのために必要な反復処理も増えます。このように、各チャンクの処理全体で前のチャンクよりも while ループの反復数が多くなります。
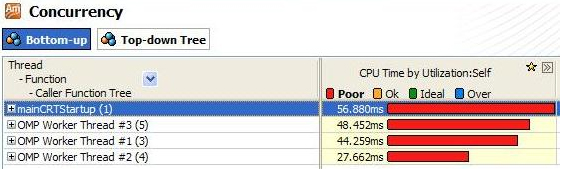
図 2. Concurrency (並列性) の分析結果により、各スレッドによって使用される実行回数のインバランスが示されています。
プログラムに最適な粒度を見つけるには、より適切な処理サイズ (100) を使用しなければなりません。また、連続したタスク間での処理量の差は前のチャンクサイズよりは深刻ではないため、動的なスケジュールではなく静的なスケジュールを使用して、さらに並列オーバーヘッドを取り除くことができます。下記のコードでは、schedule 節の変更によって、このコードセグメントのオーバーヘッドが芸限され、並列パフォーマンス全体で優れた実行速度を達成しています。
#pragma omp parallel
{
int j, limit, prime;
#pragma for schedule(static, 100)
reduction(+:numPrimes, numP41, numP43)
for(i = 3; i <= 1000000; i += 2)
{
limit = (int) sqrt((float)i) + 1;
prime = 1; // assume number is prime
j = 3;
while (prime && (j <= limit))
{
if (i%j == 0) prime = 0;
j += 2;
}
if (prime)
{
numPrimes++;
if (i%4 == 1) numP41++; // 4k+1 primes
if (i%4 == 3) numP43++; // 4k-1 primes
}
}
}
アドバイス
マルチスレッド・コードの並列パフォーマンスは粒度に左右されます。スレッド間でどのように処理が配分されているか、そしてスレッド間の通信がどのように行われているかが重要な鍵です。次に、粒度の調整によってパフォーマンスを向上するためのガイドラインを紹介します。
- アプリケーションの理解
- 並列実行されるあらゆる部分でどのくらいの処理量があるかを理解する。
- アプリケーションの通信要件を理解する。同期は通信の一般的な手法ですが、メモリー階層 (キャッシュ、メインメモリーなど) でのメッセージパッシングとデータ共有のオーバーヘッドも考慮します。
- プラットフォームとスレッド化モデルの理解
- ターゲット・プラットフォーム上のスレッド化モデルによる並列実行の起動と同期のコストを理解する。
- 並列タスクごとのアプリケーションの処理を、スレッド化した際のオーバーヘッドよりも大きくする。
- 可能な限り同期を少なくして、同期のコストを低くする。
- インテル® スレッディング・ビルディング・ブロックの並列アルゴリズムのパーティショナー・オブジェクトを使用して、タスク・スケジューラーがタスクごとの処理の粒度と実行スレッドのロードバランスを選べるようにする。また、OpenMP* では schedule 節に追加されたパラメーター auto の使用を検討する。
- ツールの理解
- インテル®Parallel Amplifier の「Locks and Waits (ロックと待機)」 (現在のインテル® VTune™ プロファイラーの「スレッド化」) 解析で、通信が多すぎることを示す目印となるロック、同期、並列オーバヘッドに注目する。
- インテル®Parallel Amplifier の「Concurrency (並列性)」 (現在のインテル® VTune™ プロファイラーの「スレッド化」) 解析で、粒度が大き過ぎたり、スレッドの配分の調整が必要であることを示すロード・インバランスに注目する。
利用ガイド
上記の例では OpenMP を利用していますが、ここで紹介したアドバイスや指針は、Windows スレッドや POSIX* スレッドなど、その他のスレッド化モデルにも適用できます。スレッド化モデルには、並列実行の起動、ロック、クリティカル領域、メッセージパッシングなどのさまざまな関数と関連したオーバーヘッドが伴います。
ロード・インバランスを増やすことなく、通信を抑えてスレッドごとの処理量を増やすというここで紹介したアドバイスはすべてのスレッド化モデルに当てはまることです。しかしながら、モデルごとにコストが異なるため、それぞれのモデルに適した粒度を選択するようにしてください。
(注) 記事で使用しているインテル® Parallel Amplifier は、インテル® VTune™ Amplifier およびインテル® VTune™ プロファイラーの古い名称です。最新のツールでも同様の情報を取得できます。
関連情報
- Clay Breshears, The Art of Concurrency, O’Reilly Media, Inc., 2009. (http://oreilly.com/catalog/9780596521547/)
- Barbara Chapman, Gabriele Jost, and Ruud van der Post, Using OpenMP: Portable Shared Memory Parallel Programming, The MIT Press, 2007.
- インテル® TBB オープンソース版 (英語)
- James Reinders, Intel Threading Building Blocks: Outfitting C++ for Multi-core Processor Parallelism. O’Reilly Media, Inc. Sebastopol, CA, 2007. (英語)
- Ding-Kai Chen, et al, “The Impact of Synchronization and Granularity on Parallel Systems“, Proceedings of the 17th Annual International Symposium on Computer Architecture 1990, Seattle, Washington, USA. (英語)
